- The paper demonstrates that prompt strategy selection significantly impacts energy consumption and execution time, with reasoning-heavy approaches incurring up to 3× higher costs.
- It employs a rigorously controlled experimental framework using three 4-bit quantized SLMs and the MBPP benchmark to isolate strategy effects.
- Results reveal Pareto-optimal trade-offs for Few-Shot, LtM, and Zero-Shot prompts, while self-consistency yields high costs with marginal coverage improvements.
Sustainability Analysis of Prompt Strategies for SLM-based Automated Test Generation
Introduction
This paper delivers a systematic, multi-metric analysis of prompt engineering strategies in the context of SLM-driven automated test generation, focusing not only on standard code coverage efficacy but also on direct, granular measures of computational and environmental sustainability. The investigation specifically targets seven prompt strategies—Zero-Shot, Few-Shot, Chain-of-Thought (CoT), Least-to-Most (LtM), Program-of-Thought (PoT), Self-Consistency (SC_CoT), and ReAct—executed over three 4-bit quantized, open-source SLMs (Meta-Llama-3-8B-Instruct, DeepSeek-Coder-7B-Instruct-v1.5, Mistral-7B-Instruct-v0.3). The evaluation pipeline employs the MBPP Python benchmark and explicitly accounts for energy (CPU/GPU/RAM), carbon emissions, per-token costs, and code coverage metrics, thus enabling a comprehensive assessment of prompt-driven trade-offs that extend far beyond task-level performance.
Experimental Framework
The experimental methodology is rigorously controlled. Each prompt strategy is evaluated on identical hardware (NVIDIA A100 GPU), under equivalent runtime parameters (4-bit quantization, batch size 10, max output 1024 tokens, controlled sampling), and using the same reference dataset (MBPP). The framework (Figure 1) incorporates both primary (execution time, energy, emissions, coverage) and derived metrics (cost/throughput per 1k tokens, coverage per kWh, coverage per kgCO₂, and an aggregate sustainability-quality SQScore), supporting detailed, prompt-centric efficiency analysis.
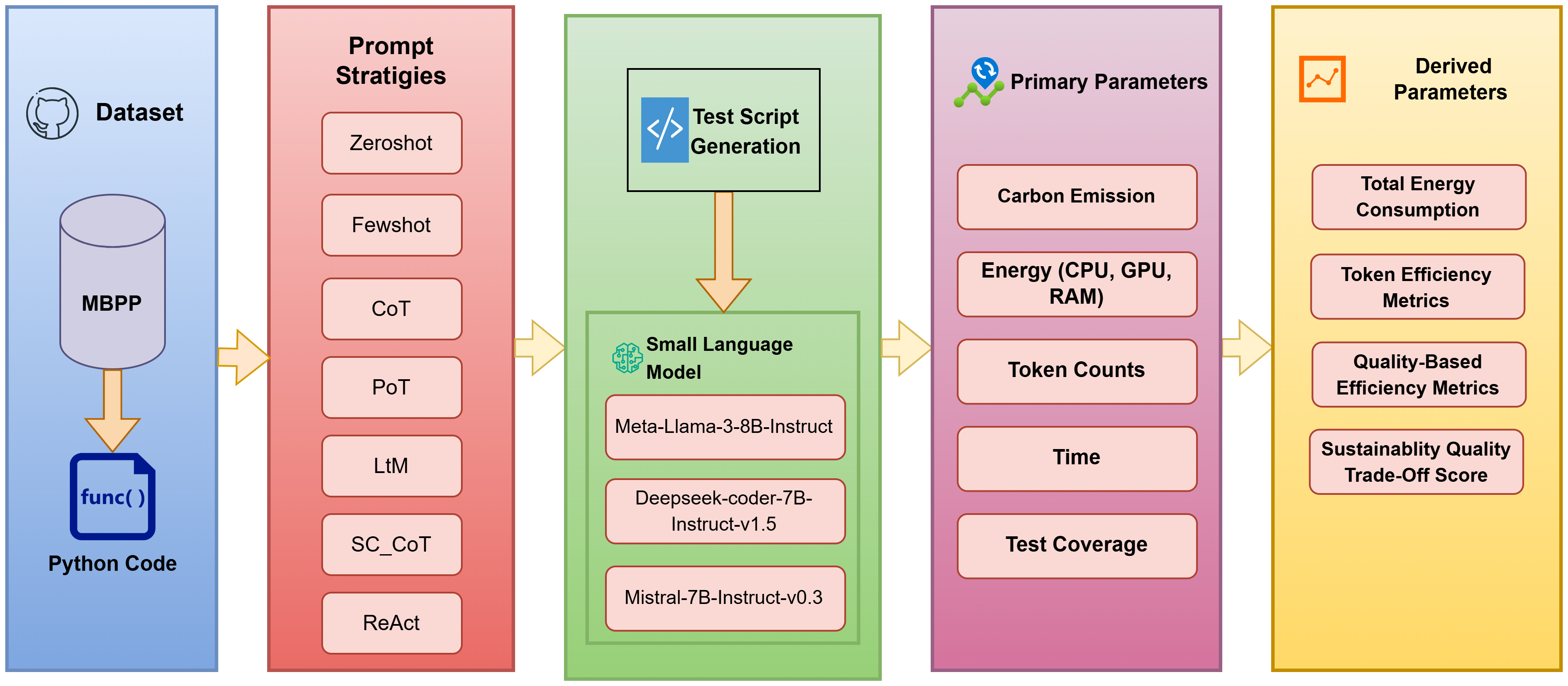
Figure 1: The experiment framework.
This structure ensures that observed variation can be attributed to prompt strategy and not systemic confounds, allowing for valid isolation of the sustainability impact of prompt engineering per se.
Prompt Strategies: Mechanistic and Experimental Characteristics
The seven analyzed strategies span from low-complexity (Zero-Shot, Few-Shot) to highly structured and reasoning-intensive (CoT, SC_CoT, PoT, ReAct). Each prompt type modulates the cognitive workload delegated to the SLM, and, correspondingly, the length and complexity of model completions—the latter being a primary driver of both computational/energy cost and cumulative token output.
Key experimental observations:
- Simple prompts (Zero-Shot, Few-Shot): Short and direct, optimized for minimal context and expedient generation.
- Reasoning-centric prompts (CoT, SC_CoT, PoT): Force step-wise elaboration, either requiring chains of logical deduction, modular solution proposals, or self-consistent validation. These increase output tokens and induce repetitive or exploratory computation.
- ReAct and LtM: Structure the reasoning but are less verbose than SC_CoT, encouraging selective knowledge retrieval or progressive decomposition.
Sustainability and Coverage: Quantitative Results
Execution-Level Behavior
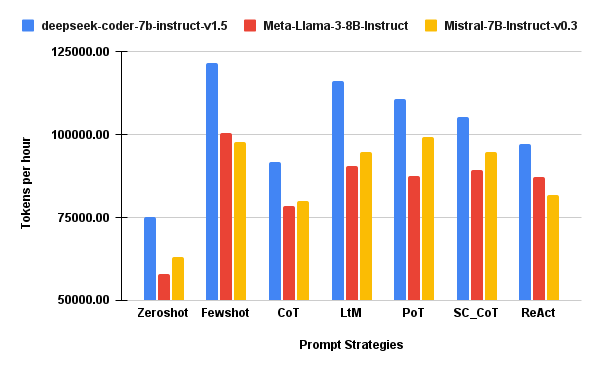
- Execution time and total energy usage are highly sensitive to prompt strategy (Figure 2), with SC_CoT requiring up to 3× the inference time and energy of lightweight prompts, independent of SLM architecture.
- Coverage, however, remains tightly distributed across most prompts, demonstrating that additional reasoning depth often yields diminishing or null coverage gains, especially when normalized by cost.
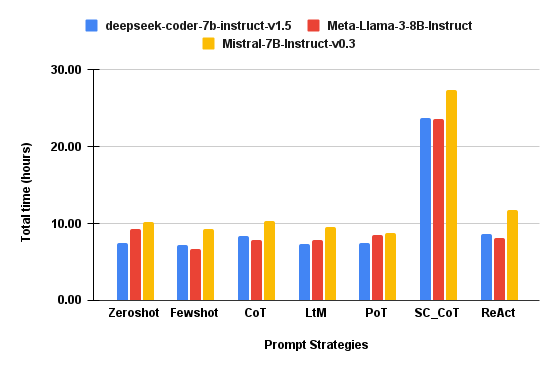
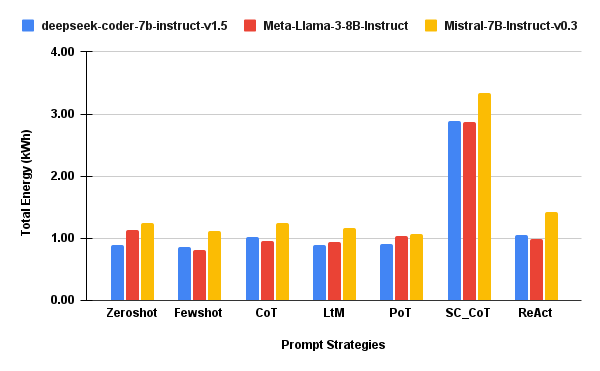
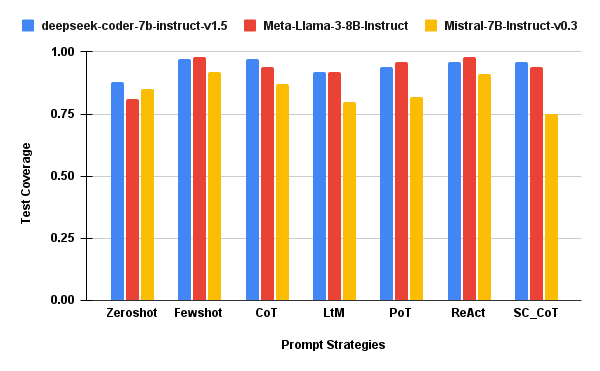
Figure 2: τhr: Execution time in hours for each prompt strategy and SLM.
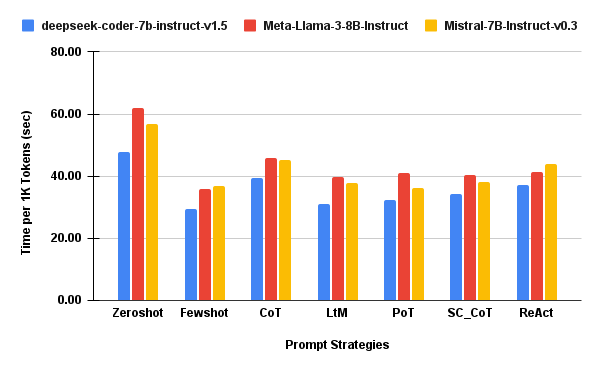
Token-Normalized and Coverage-Normalized Efficiency
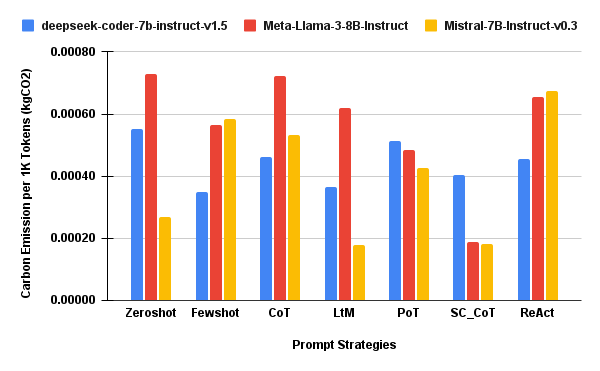
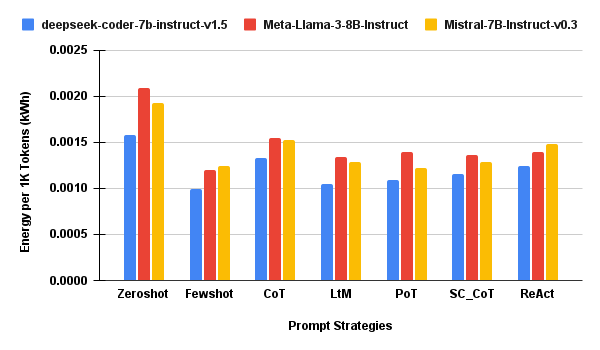
Figure 4: SecPer1KTok — Execution time per 1,000 tokens, lower is better for sustainability.
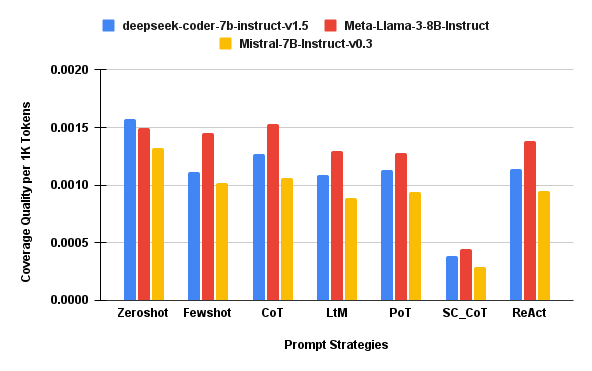
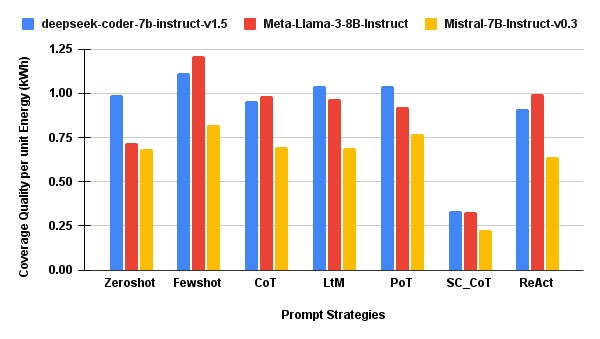
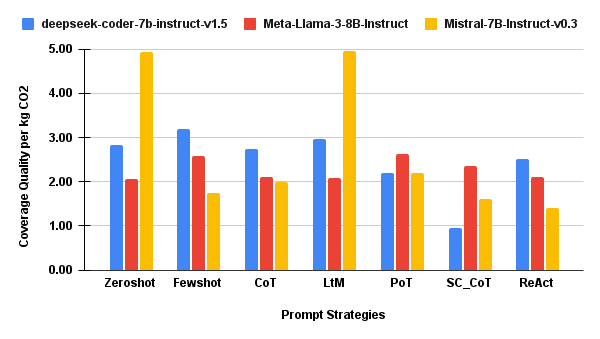
Figure 5: QPer1KTok — Coverage quality per 1,000 tokens, indicating prompt strategy efficiency.
- The SQScore composite (sustainability–coverage trade-off, Figure 6) robustly demonstrates that Few-Shot (DeepSeek, Llama-3), LtM (Mistral), and Zero-Shot constitute Pareto-optimal choices under both emission- and coverage-weighted policy regimes, while SC_CoT is strictly dominated for all SLMs.
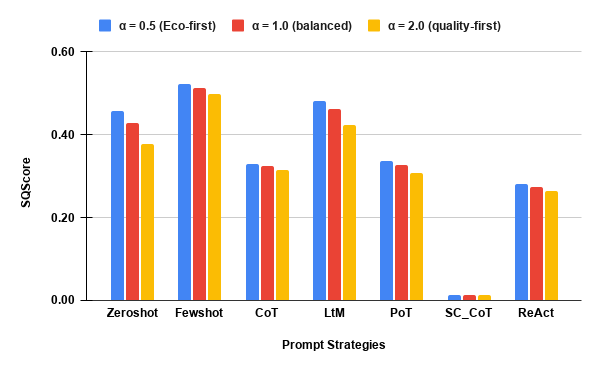
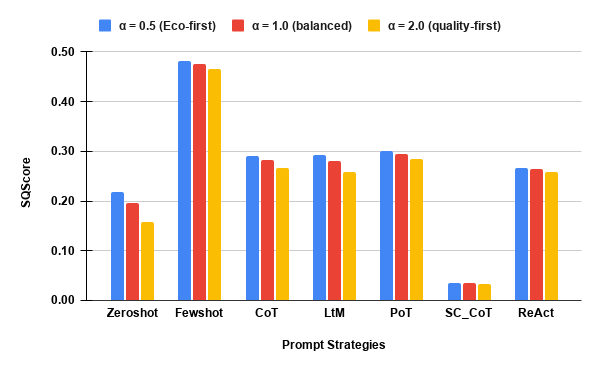
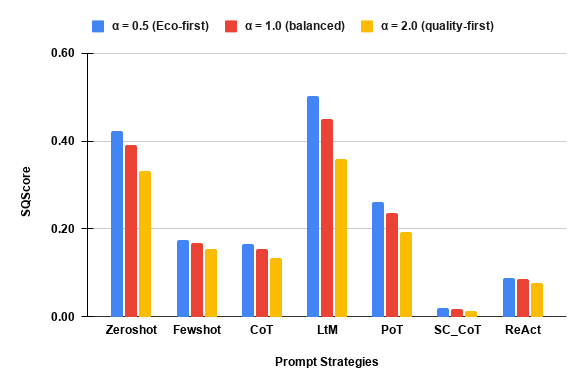
Figure 6: deepseek-coder-7b-instruct-v1.5: Composite sustainability–coverage trade-off per prompt strategy.
Strong or Contradictory Claims
- Across all three models and all prioritization regimes, prompt strategy impacts sustainability outcomes more than SLM model choice, subject to fixed architecture and quantization. This is a direct challenge to common intuitions that model class dominates inference efficiency.
- Self-Consistency incurs the highest cost with marginal or even negative returns in normalized coverage, supporting the clear recommendation to avoid such prompts in sustainability-constrained testing settings.
- There is no monotonic relationship between prompt reasoning complexity and coverage improvement; lightweight templates already achieve near-maximum coverage on realistic benchmarks.
Implications and Future Directions
This work provides conclusive evidence that prompt engineering is a first-class lever for optimizing sustainability in SLM-based automated test generation. Integrating sustainability metrics directly into prompt selection and test pipeline design should be considered in both academic and industrial AI-for-SE practice. Practically, prompt design affords rapid iteration and cost-control at the deployment level, without requiring retraining or model replacement. This is especially pertinent for carbon-aware or emissions-capped pipelines, and for organizations seeking to optimize QA at scale with minimal environmental overhead.
From a theoretical perspective, the findings suggest new research avenues in prompt strategy selection, including automated prompt synthesis driven by sustainability-coverage reward (meta-prompting), as well as adaptive strategies that dynamically tune prompt complexity based on real-time energy/emissions telemetry.
The authors acknowledge coverage as a partial measure of test quality; future research must incorporate semantic robustness, test oracle quality, and operational fault-detection. Expanding to more diverse benchmarks, runtime environments, languages, and multi-agent cooperative scenarios also constitutes logical next steps.
Conclusion
This paper establishes, with experimental rigor, that prompt strategy selection fundamentally determines the computational and environmental cost of SLM-based automated test generation. Lightweight prompting strategies such as Few-Shot and LtM produce superior sustainability–coverage trade-offs, while reasoning-heavy prompts introduce high overhead with limited quality gain. Prompt engineering must be explicitly addressed as part of sustainable AI-for-SE deployment. Further, the framework and methodology presented offer a template for integrated, sustainability-aware LLM/SLM evaluation across other software engineering tasks.