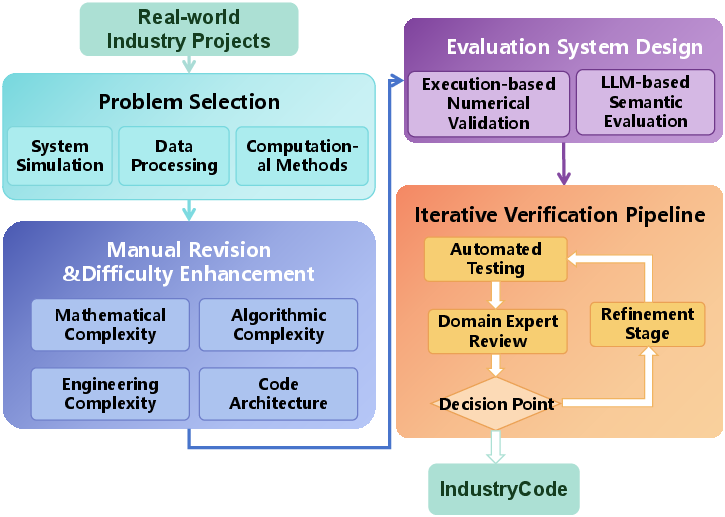
- The paper presents IndustryCode, a benchmark that decomposes 125 industrial problems into 579 sub-problems for robust code generation evaluation.
- It details a rigorous annotation pipeline combining manual revisions, hierarchical decomposition, and both automated and LLM-based validation.
- Performance analysis reveals a significant execution gap between isolated sub-problem accuracy and integrated industrial task synthesis.
IndustryCode: A Comprehensive Benchmark for Industrial-Scale Code Generation
Motivation and Benchmark Design Principles
IndustryCode introduces a multi-domain, multi-language benchmark explicitly designed to assess code generation capabilities in authentic industrial settings. The benchmark is motivated by the observed limitations of existing code generation benchmarks, which predominantly focus on single domains, mainstream programming languages (e.g., Python), and narrowly scoped software tasks. These benchmarks fail to capture the multifaceted requirements of industrial contexts—including domain specificity, cross-lingual generalization, and high-complexity engineering tasks that feature tightly coupled sub-components and stringent numerical precision.
IndustryCode addresses this gap by aggregating 125 main industrial problems, each hierarchically decomposed into 579 granular sub-problems. The dataset spans 20 subfields across four languages: Python, C++, MATLAB, and Stata. Main problems correspond to holistic industrial engineering tasks that require end-to-end synthesis, while sub-problems capture modular, functionally cohesive subcomponents amenable to focused evaluation.
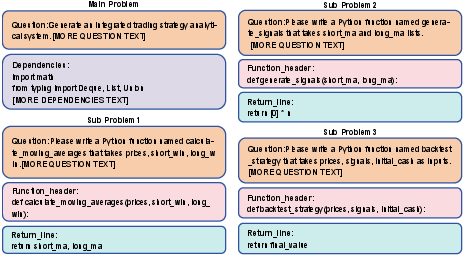
Figure 1: Hierarchical decomposition of an IndustryCode task. A complex Main Problem is factorized into modular Sub-problems, each with explicit specifications and dependencies.
A distinguishing attribute is the exclusivity of data sourcing from proprietary, high-fidelity industrial codebases, followed by manual decontamination and complexity enhancement to prevent artifact leakage and ensure the presence of authentic, production-grade idiosyncrasies. The curation includes numerical test cases for execution-based validation and a semantic LLM-Judge system for evaluating code quality beyond simple I/O matching.
Dataset Construction and Annotation Pipeline
The construction pipeline starts with the collection of domain-representative industrial problems, emphasizing physical sciences, quantitative finance, engineering optimization, and scientific computing verticals. The annotation process proceeds through the following phases:
The resulting benchmark exhibits broad coverage: Python dominates in engineering, AI, and finance, while C++ is targeted toward manufacturing and IT, MATLAB covers optimization and scientific modeling, and Stata supports statistical computing and domain-specific analytics.
Evaluation Methodology and Experimental Analysis
To assess model competency, IndustryCode adopts a unified zero-shot prompting strategy augmented with cumulative context windows simulating longitudinal development workflows. Each prompt includes a global description, current sub-problem specifics, and all prior code—probing models' abilities in incremental reasoning, long-range state maintenance, and adherence to complex interface contracts.
Pass@1 accuracy is measured both at the atomic sub-problem level and for holistic main problems. The LLM-Judge framework is deployed for cases where strict functional equivalence is not guaranteed by test cases alone, particularly addressing code style, control flow, and compliance with industrial design patterns.
Empirical evaluation comprises proprietary and open-weight models. Closed models include the Claude 4.5 suite, GPT-5 variants, and Google's Gemini, while open models encompass Qwen3, DeepSeek, and code-specialized variants. Both standard and reasoning-enhanced ("thinking mode") variants are extensively benchmarked.
Numerical Results and Failure Mode Stratification
On sub-problems, the highest overall Pass@1 accuracy is 68.1% (Claude 4.5 Opus), with subsequent tiered performance among Gemini, GPT-5, and leading open models. Main problems, representing integrated system tasks, see a clear performance drop, with Claude 4.5 Opus at 42.5%. The execution gap—defined as the accuracy differential between sub- and main-problems—remains significant for all models, suggesting persistent limitations in multi-step orchestration, error recovery, and long-horizon context retention.
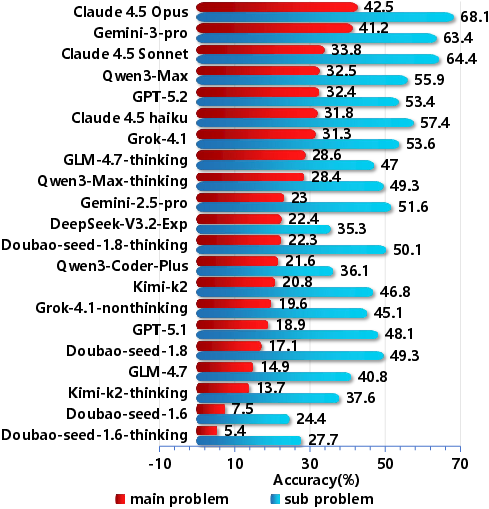
Figure 3: Performance comparison on main problems and sub-problems. Strong performance in sub-tasks correlates with improvements at the system level, but an execution gap persists.
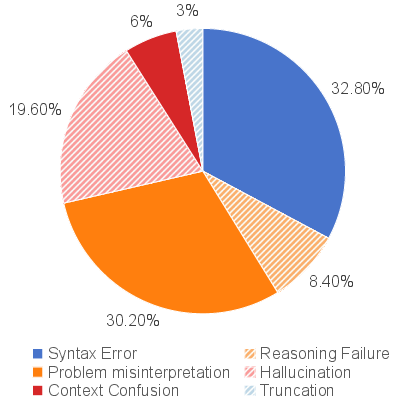
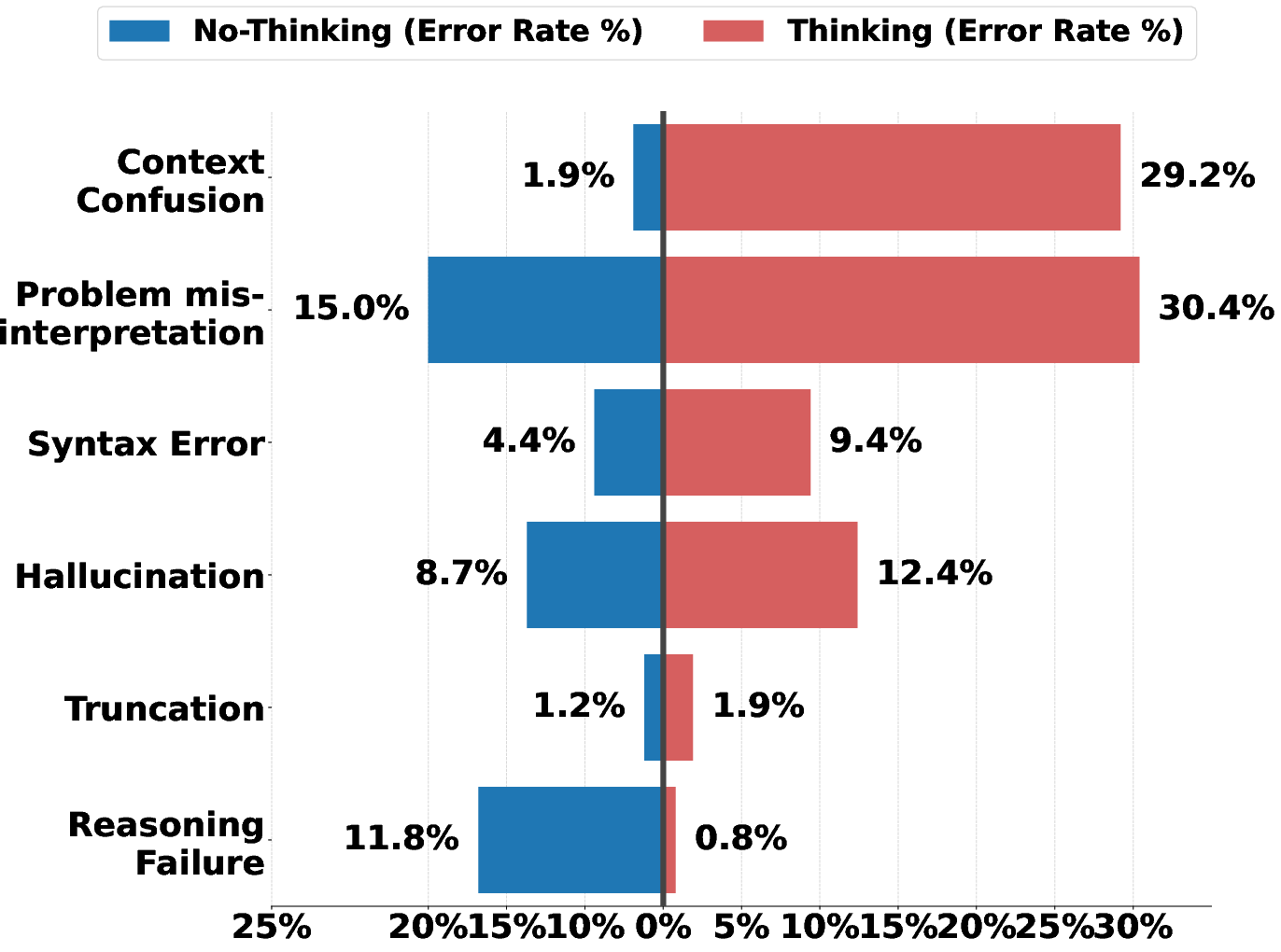
Figure 4: Distribution of failure cases in IndustryCode. Syntax errors and prompt misinterpretation dominate, while pure logical errors are a minority.
Detailed error analysis reveals that syntax errors (32.8%) and misunderstanding the problem statement (30.2%) account for the majority of failures, particularly in domain-specific and less-documented languages (e.g., MATLAB, Stata). Hallucinations—often manifesting as fabricated APIs—account for 19.6%. Notably, logical reasoning errors are rare, indicating LLMs' default propensity for pattern-matching and code synthesis over deep semantic abstraction.
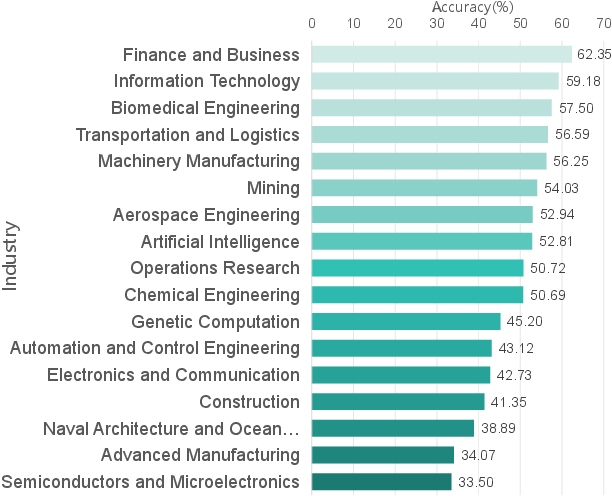
Figure 5: Performance distribution of sub-problem in IndustryCode. Domain-level stratification highlights clear disparities, with finance and IT outperforming hardware-constrained sectors.
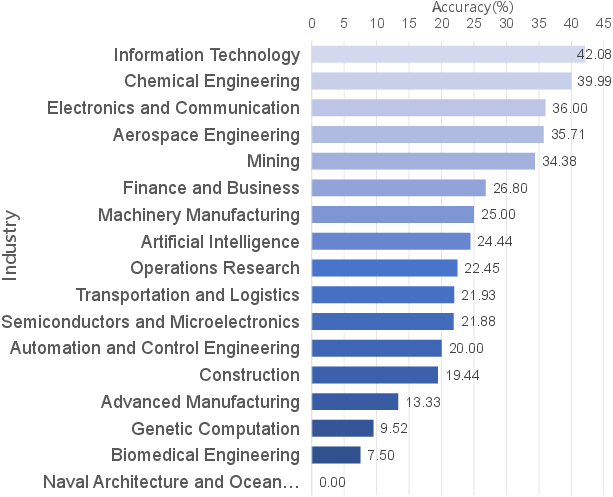
Figure 6: Performance distribution of mainproblem in IndustryCode. Pass@1 distributions by domain highlight critical bottlenecks in complex integration tasks.
Theoretical and Practical Implications
These findings strongly indicate bottlenecks rooted in architecture and pretraining data distribution:
Model Comparison and Architecture-Level Insights
The empirical landscape underscores architectural trade-offs:
- Mixture-of-Experts Advantage: Open models (Qwen3-Max) utilizing Mixture-of-Experts architectures excel in domains with standardized code, optimizing parameter utility and cross-domain adaptation.
- Long-context Fidelity: Claude's supremacy is not solely due to model scale, but superior segregation of reasoning and syntax layers and maintenance of extended KV cache integrity, minimizing cognitive over-correction and symbol table decay.
- Prompt Engineering Limits: Prompt modifications and explicit reasoning heuristics partially compensate for structural limitations but amplify risk of context leakage, hallucination, and overengineering.
Cross-Industry Generalization and Application Gap
Success rates for high-level integration tasks remain low; even when models achieve >60% accuracy on modular code generation, main problem integration is limited to 42%. This quantifies the execution gap and validates the need for specialized agentic architectures capable of robust multi-step planning, error correction, and symbol tracking.
Figures 19 and 20 further illustrate sector-specific adaptation and consistent accuracy gaps between atomic and holistic tasks, supporting a stratified approach to future research and deployment strategies for industrial AI.
Conclusion
IndustryCode represents a crucial advance in industrial code generation benchmarking, integrating hierarchical decomposition, cross-domain coverage, multi-lingual support, and real-world data curation. The observed performance plateau and failure mode taxonomy expose fundamental architectural, data, and reasoning limitations in current SOTA LLMs. While progress is manifest—especially in open MoE models and closed long-context architectures—genuine industrial AI deployment will require advances in data curation pipelines, domain-adaptive pretraining, and architectures engineered explicitly for stateful, multi-agent, and multi-language workflows.
Ongoing research must address the execution gap between atomic code proficiency and holistic system synthesis, with future benchmarks extending assessment to even more diverse, partially proprietary industrial environments, and closed-loop agentic workflows. IndustryCode provides the foundational scaffolding and analytic rigor necessary for the coming generation of industrial AI systems and serves as a template for verticalized, high-fidelity evaluation of code generation models.
Reference: "IndustryCode: A Benchmark for Industry Code Generation" (2604.02729)