- The paper introduces foundation models for sensor-based HAR, leveraging large-scale self-supervised pretraining to achieve robust, cross-modal representations.
- It categorizes techniques into unimodal, multimodal, and cross-modal approaches, highlighting their impact on transfer learning and zero-shot recognition.
- The study discusses challenges like privacy, temporal encoding, and lifecycle adaptation, offering a roadmap for advancing human-centered sensing.
Foundation Models in Sensor-based Human Activity Recognition: An Expert Review
Evolution of Sensor-based HAR and Motivation for Foundation Models
Sensor-based human activity recognition (HAR) underpins ubiquitous and wearable computing, yet is fundamentally challenged by heterogeneous data sources, limited annotated corpora, and persistent generalization gaps across users, devices, and contexts. Historically, HAR progressed from hand-crafted feature engineering and shallow classifiers through the adoption of deep sequential models (CNNs, RNNs), transfer learning, and self-supervised approaches, culminating in the recent surge toward large-scale foundation models.
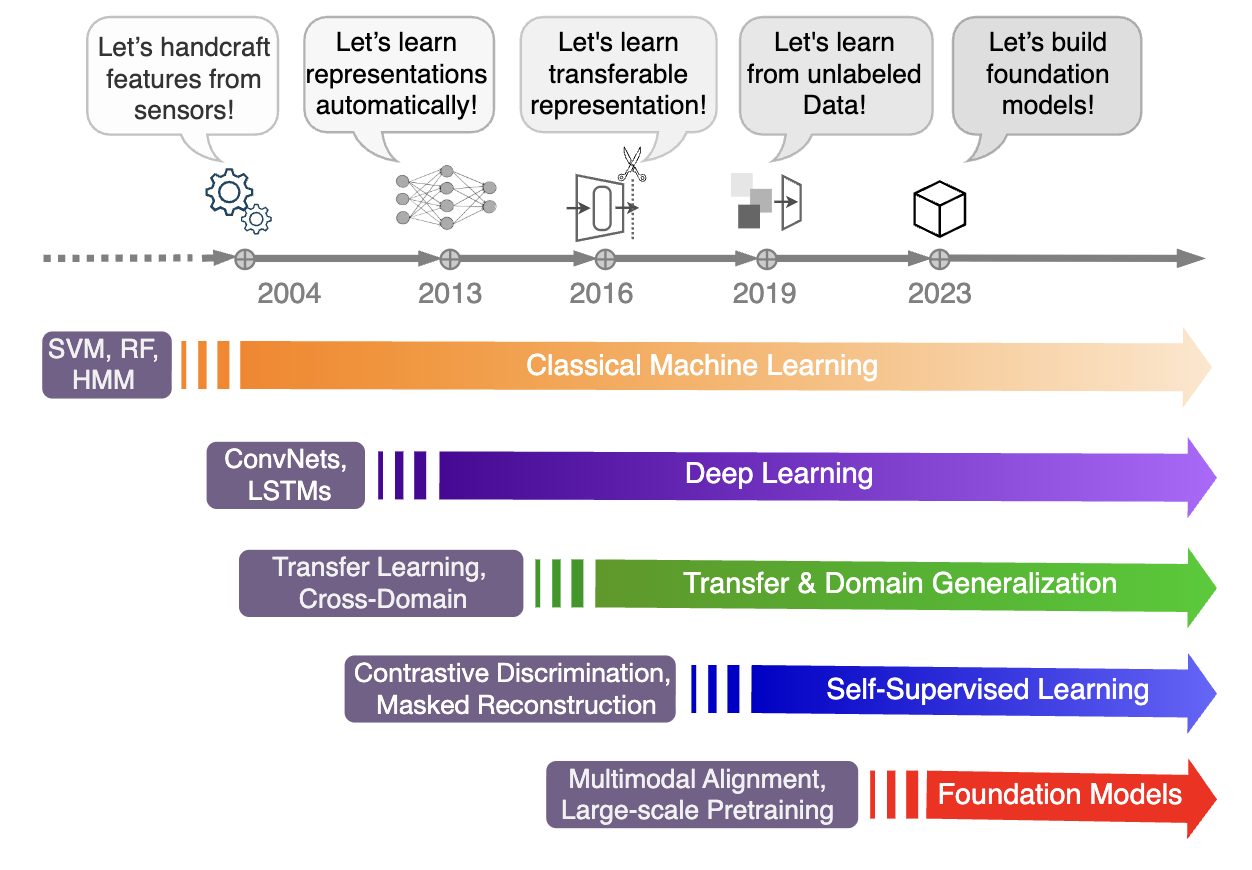
Figure 1: A timeline tracing the historical development of sensor-based HAR, highlighting the field’s evolution from classical ML to deep learning, self-supervision, and, currently, foundation models.
The motivation for foundation models in this domain arises from analogies to advances in computer vision and natural language processing, yet HAR introduces singular requirements. Unlike vision-language, activities unfold across time and embodiment, and sensor data are fragmented and non-IID. Foundation models address this by leveraging self-supervised pretraining at scale to generate robust, transferable representations across sensing modalities and contexts.
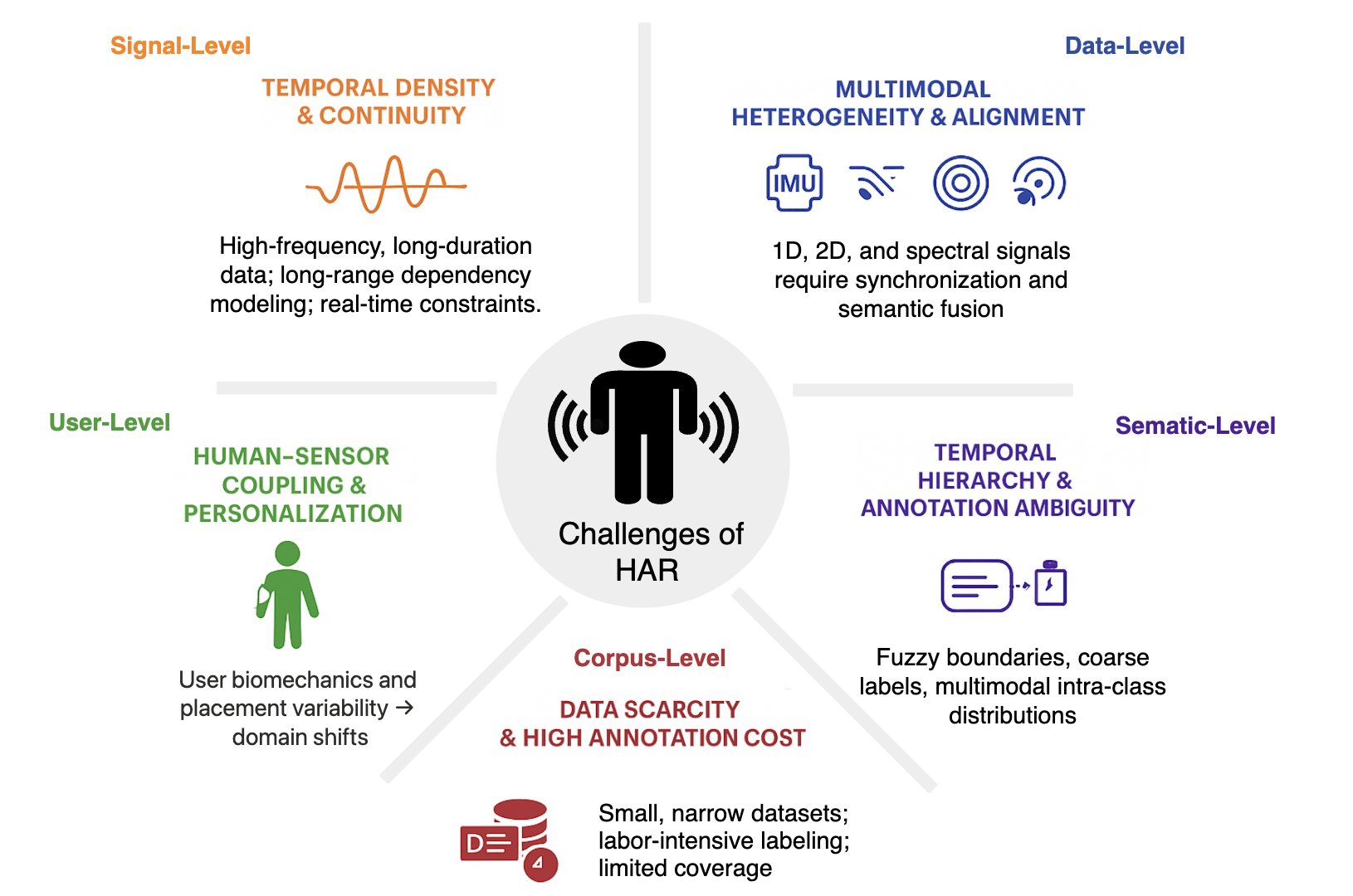
Figure 2: The multilevel abstraction of HAR challenges, showing how signal, data, user, semantic, and corpus factors determine learning complexity and the unique requirements for robust models.
Defining Foundation Models for Sensor-based HAR
The concept of a "Foundation Model" in HAR is distinct from its usage in vision or language. A sensor-based HAR foundation model is a pretrained, sensor-grounded architecture—with adapters as needed—capable of solving diverse activity-understanding tasks across modal, temporal, and contextual axes, and supporting generalization across users, placements, and real-world deployments.
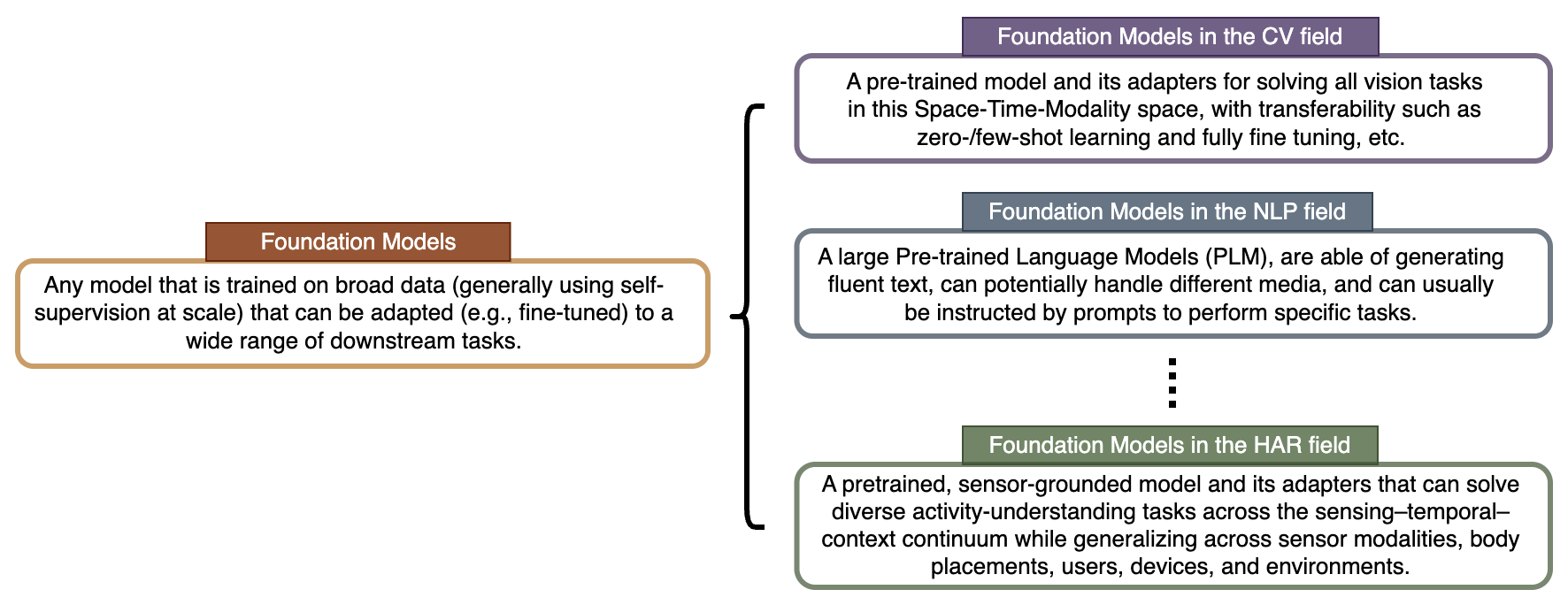
Figure 3: Comparative conceptions of Foundation Models in vision, language, and, as defined here, in sensor-based HAR.
Key criteria for such models include corpus-scale pretraining, cross-domain generalization, modality extensibility, label-efficient objectives, lightweight adaptation protocols, and emergent capabilities such as broad task transfer and semantic reasoning. Empirical synthesis across representative recent works reveals notable variance in coverage of these axes; for example, models like SensorLM and SelfHAR-700k excel in scale and cross-modality but lag in generative reasoning or on-device adaptation.
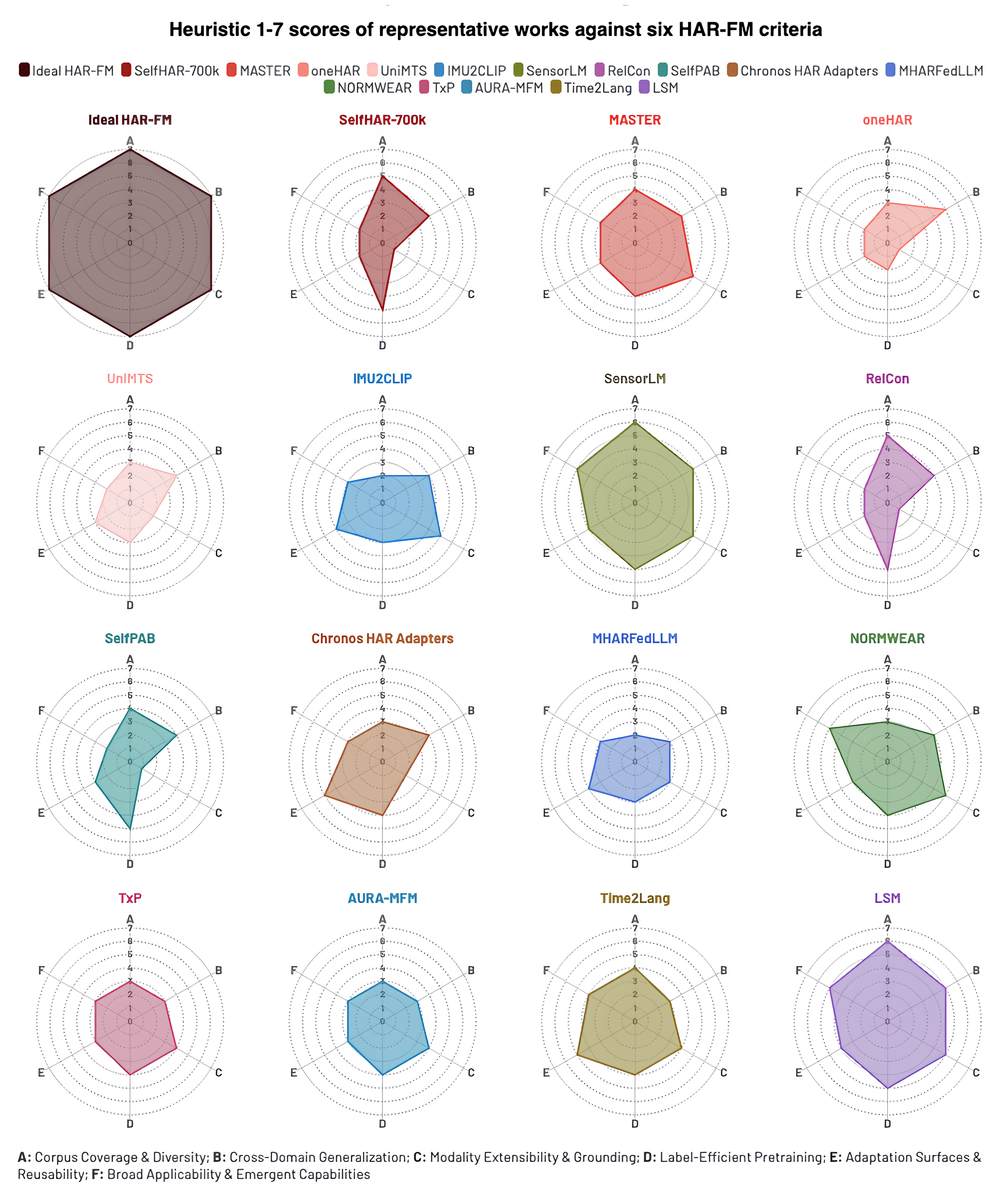
Figure 4: Radar chart depicting comparative heuristic scoring of recent foundation models on critical criteria, with an “ideal” HAR foundation model profile as aspirational reference.
Taxonomy: The Lifecycle and Technical Axes of HAR Foundation Models
A unifying lifecycle-oriented taxonomy is constructed with four primary phases: (i) input modeling and tokenization, (ii) large-scale pretraining, (iii) task/domain adaptation, (iv) downstream deployment and utilization. This structure emphasizes that design choices at one phase, e.g., modality tokenization or selection of self-supervised objective, substantially influence subsequent adaptation and application.
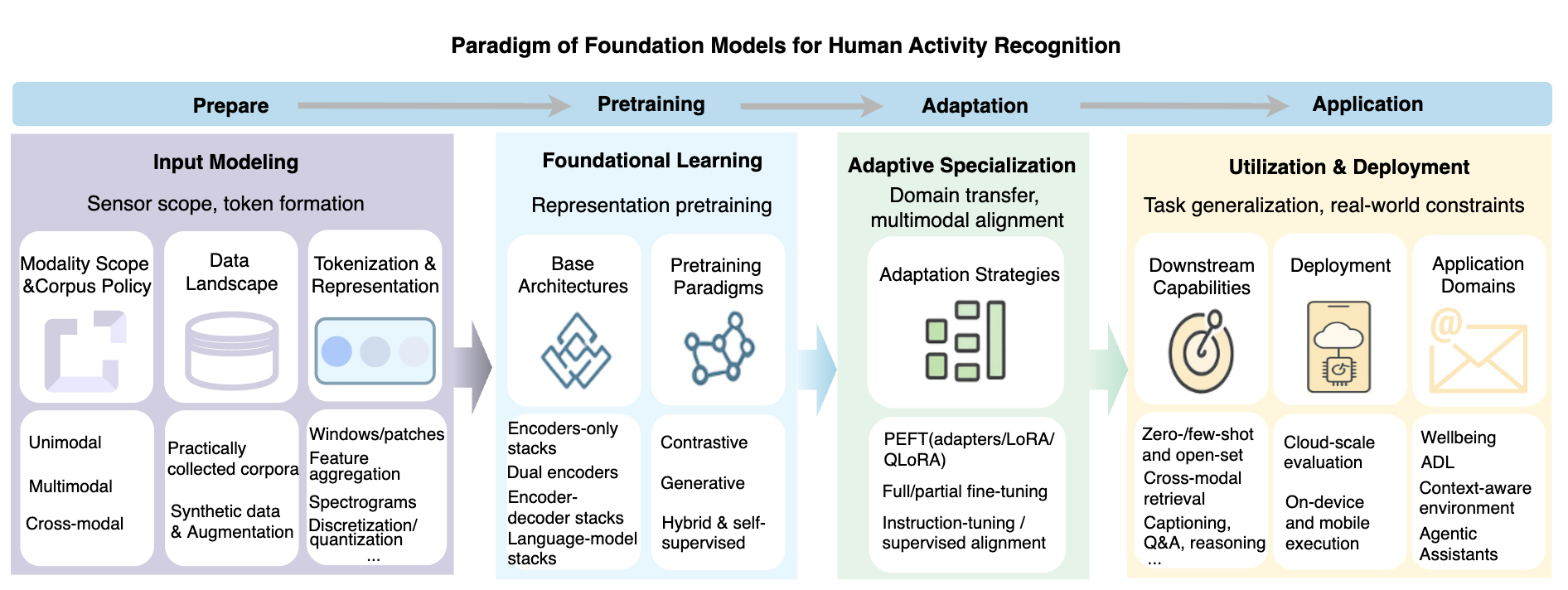
Figure 5: Lifecycle-oriented taxonomy of HAR foundation models, outlining the high-level development process from design and pretraining to adaptation and deployment.
Modality Scope and Data
Foundation models are categorized as unimodal (e.g., universal IMU models), multimodal (joint IMU-physiology, IMU-RF), or cross-modal (sensor-language, sensor-vision). There is a clear trend from single-device/placement focus toward multimodal and semantically-grounded models, albeit hindered by limited large-scale, jointly labeled datasets.
Literal raw data and simulated or synthetically generated corpora jointly inform model generalization. Synthetic data is increasingly critical for rare classes, privacy preservation, and balancing domain sampling [leng2023benefit]. Augmented datasets, including virtual IMU traces generated from textual descriptions or simulations, are being used to provide broader coverage.
Tokenization and Representation
Tokenization strategies—window-based, statistical aggregation, spectral representation, quantization—mediate the mapping between continuous sensor streams and the sequential input requirements of modern foundation models. Cross-modal scaffolding is achieved via alignment tokens and cross-stream fusions, setting the foundation for shared latent spaces supporting downstream retrieval, recognition, and reasoning.
Pretraining Paradigms
Three dominant self-supervised paradigms arise:
- Contrastive Pretraining: Maximizes agreement between sensor pairs/augmentations/semantic teachers, promoting domain invariance and zero/few-shot recognition [weng2025fm, moon2023imu2clip].
- Generative Pretraining: Employs masked autoencoding, forecasting, or denoising objectives to capture temporal dependencies and prepare for reconstruction/imputation tasks [miao2024spatial].
- Hybrid Pretraining: Blends generative and contrastive objectives, often augmented with task-specific pretext tasks, to optimize for both discriminability and temporal structure, and is the default in recent large-scale HAR FMs [zhang2025sensorlm, qiu2025towards].
Adaptation Strategies
Parameter-efficient fine-tuning (PEFT), full/partial fine-tuning, and instruction- or prompt-driven alignment are the main mechanisms for model adaptation. Model updates range from lightweight add-ons (adapters, LoRA) for edge personalization to full stack retraining for major distribution shifts. Instruction- and prompt-based adaptation, especially with LLMs, now supports rapid zero/few-shot transfer across sensor platforms and tasks [pillai2025time2lang, xie2025physllm].
Downstream Capabilities
Foundation models support a spectrum of downstream use cases:
- Zero/few-shot and open-set recognition: Enabled by strong alignment priors and shared representations, these models demonstrate nontrivial performance on previously unseen activities or rare classes, often outperforming standard baselines under non-IID splits.
- Cross-modal retrieval/search: Embedding spaces bridge sensor data with language and vision, supporting cross-domain search, explanation, and interactive interfaces.
- Language-grounded reasoning: Sensor-to-text pipelines support captioning, Q&A, and high-level explanation through LLMs.
- On-device and federated deployment: Edge-ready models balance accuracy with constraints on latency, computation, and privacy, enabling personalization while preserving population-level robustness.
Major Research Directions and Results
Three distinct trajectories define the current evolution of sensor-based HAR FMs:
- HAR-specific Pretrained Foundation Models: Exemplified by models such as oneHAR, MASTER, and NORMWEAR, these deliver state-of-the-art cross-user and cross-dataset transfer, demonstrating scaling behaviors and generalization improvements analogous to those observed in large vision/language FMs [Wei_2025, qiu2025towards, narayanswamy2025scaling].
- Adapting General Time-Series/Multimodal FMs: Transfer learning from time-series FMs (e.g., Chronos, PatchTST) or from multimodal models (e.g., CLIP-style) accelerates HAR model convergence and broadens downstream capability, albeit with some loss in domain specificity [moon2023imu2clip, pillai2025time2lang].
- Leveraging LLMs for Language-grounded Activity Understanding: LLMs act as reasoning engines or annotation machines, with models like SensorLM, DailyLLM, and HARGPT achieving both zero-shot activity recognition and natural language explanations, effectively bridging the semantic gap between sensor inputs and human-interpretable outputs [zhang2025sensorlm, ji2024hargpt, chen2024sensor2text].
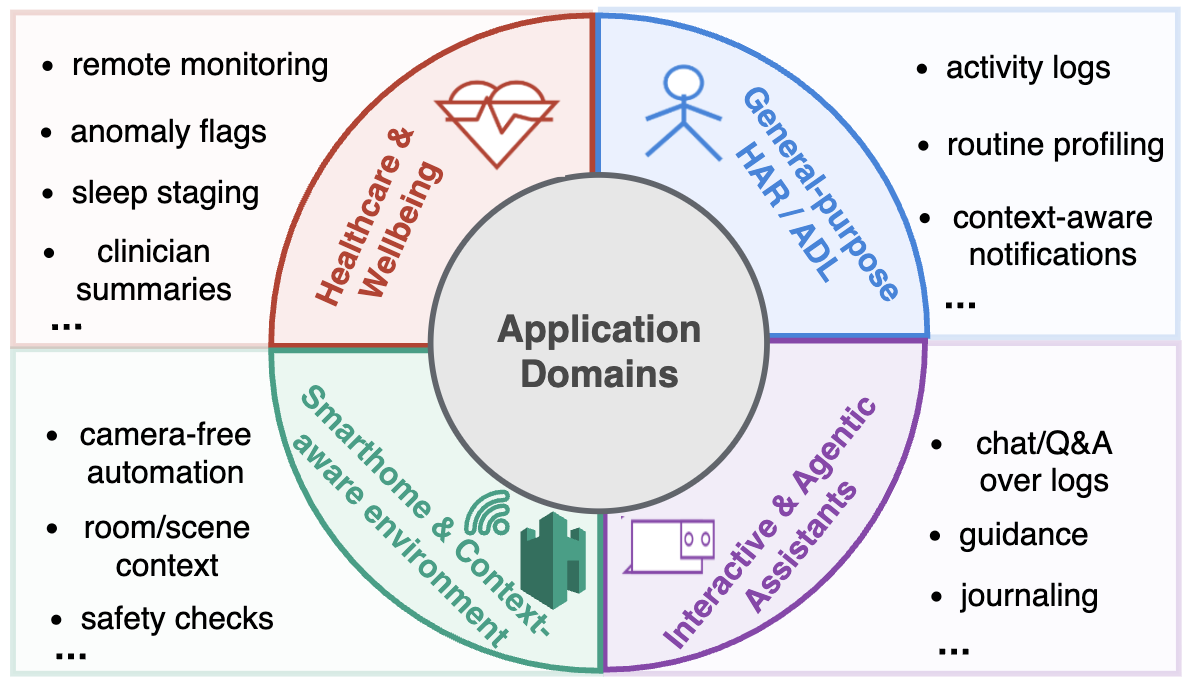
Figure 6: Application domains for sensor-based HAR foundation models, from general HAR to health monitoring, smart home, and agentic assistants.
Implications, Open Challenges, and Future Outlook
Sensor-based HAR foundation models signal a paradigm shift away from specialist, dataset-bound classifiers toward reusable, semantically-grounded, and human-aligned models. Already, strong generalization is observed under cross-user/domain evaluation, and models demonstrate label efficiency and capability emergence, e.g., out-of-distribution activity recognition. Nonetheless, significant challenges remain:
- Scaling & Privacy: Data fragmentation and privacy constraints limit the scale achievable by pretraining. Federated and privacy-preserving learning will be crucial.
- Temporal & Semantic Representation: There is still limited understanding of how best to encode hierarchical activities and routines across time, especially those only weakly anchored to language.
- Adaptation & Deployment: Model fragility under domain and user shift, and the complexity of lifecycle-aware adaptation, mandate further research into robust, on-device, and continual updating protocols.
- Evaluation & Responsibility: Standardizing cross-domain and open-set evaluation protocols—incorporating system-level costs, interpretability, and reliability under distributional uncertainty—is mandatory, especially for deployment in health or agentic settings.
Conclusion
Foundation models are fundamentally redefining sensor-based HAR, synthesizing advances from deep learning, self-supervision, and multimodal architectures into robust, general-purpose frameworks for human activity understanding. As the field evolves, hybrid frameworks aligning scalable sensor-native pretraining, flexible adaptation, and language-centric reasoning are likely to emerge as standard. Addressing scale, privacy, generalization, and evaluation will determine the successful transition of HAR FMs from research prototypes to foundational infrastructure in ubiquitous sensing and human-centered AI.