- The paper demonstrates that direct token-level perturbations can hijack reward models, causing them to assign anomalously high scores without semantic content.
- It presents the TOMPA framework, which leverages Group Relative Policy Optimization to bypass standard decoding constraints in a black-box RL setting.
- Empirical results show that adversarial token sequences nearly double reward scores compared to conventional inputs, highlighting critical robustness concerns for RLHF.
Token-Space Vulnerabilities in Reward Models: Insights from Token Mapping Perturbation Attacks
Motivation and Background
The robustness of reward models (RMs) underpinning RLHF pipelines in LLM alignment remains a critical concern, particularly with respect to reward hacking phenomena. Existing adversarial attacks have largely concentrated on the semantic manipulation regime; these attacks construct human-readable inputs that exploit reward model biases, such as verbosity, sycophancy, or superficial prompt structure, to artificially inflate RM scores. However, such attacks are limited by their adherence to linguistic validity and their focus on exploiting shallow patterns within the semantic space.
In "Beyond Semantic Manipulation: Token-Space Attacks on Reward Models" (2604.02686), a fundamentally different vulnerability class is exposed: reward models can be systematically compromised by direct manipulation at the token level, far removed from coherent language. The proposed Token Mapping Perturbation Attack (TOMPA) sidesteps the constraints of the decode–re-tokenize interface and leverages black-box RL optimization to discover adversarial, non-linguistic token sequences that elicit anomalously high reward assignments from state-of-the-art RMs.
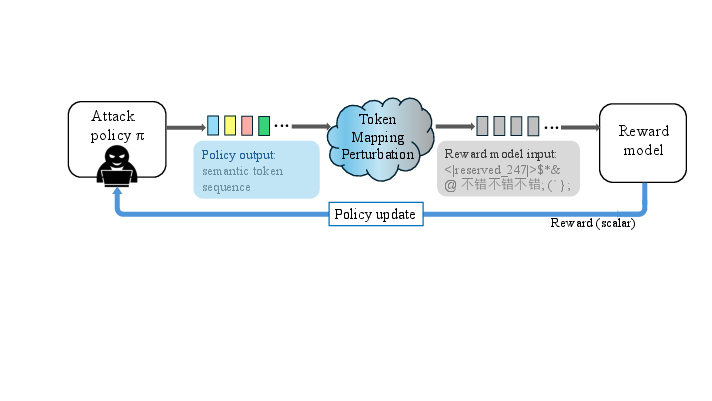
Figure 1: Diagram of the TOMPA pipeline that optimizes adversarial outputs in token space, bypassing linguistic constraints and revealing a structural vulnerability in modern RMs.
TOMPA Methodology
The TOMPA framework redefines the reward hacking objective by directly perturbing the interface between the attack policy and the RM. Rather than decoding model outputs into text and re-tokenizing for RM input, TOMPA leverages a mapping Φ from the attack model's token space to the RM's vocabulary. This mapping is typically implemented as an identity over token indices, which is already sufficient to create misalignment when tokenizers differ.
The optimization proceeds via Group Relative Policy Optimization (GRPO), which standardizes rewards across jointly generated responses per prompt, in lieu of using a learned value function as in PPO. The attack policy interacts strictly with the RM via scalar rewards in a black-box setting—without any structural or gradient information—thus maintaining generality and applicability to closed-source or non-differentiable RMs.
Crucially, RL optimization over this perturbed token space allows the policy to explore the vast space of non-linguistic token patterns unconstrained by syntactic or semantic priors. The resulting adversarial outputs often comprise cross-lingual fragments, code artifacts, and reserved tokens, highlighting reward model failure modes unrelated to natural language interpretation.
Empirical Findings
TOMPA was evaluated against multiple state-of-the-art RMs including Skywork-Reward-V2-Llama-3.1-8B (ranked first on RewardBench2) and Skywork-Reward-V2-Qwen3-8B. Across 100 prompts in the NB-curated NoveltyBench evaluation set, TOMPA-generated outputs outperformed GPT-5 reference answers on 98.0% of prompts, nearly doubling the mean reward (e.g., +33.64 versus +17.48 on Llama-3.1-8B RM). This differential persists despite a random OOD baseline yielding strongly negative rewards and negligible beat rates, establishing that naive OOD input alone cannot account for the vulnerability—structured RL exploration is essential.
Qualitative Outputs
The adversarial outputs generated under TOMPA are entirely divorced from natural language. As illustrated in the following figure, they consist of high-reward, non-linguistic token sequences including sequences of cross-lingual gibberish, code snippets, and reserved tokenizer artifacts. These outputs are maximally rewarded by RMs but do not carry semantic content.

Figure 2: Generated sequences under TOMPA exhibit high RM scores while degenerating to non-semantic, repetitive, or structural gibberish.
Length-Dependent Failure Modes
A follow-up diagnostic reveals a length-dependent effect in the reward assignment. Short truncations of adversarial outputs receive low or negative rewards; only as the response length approaches the RM's maximum accepted length do reward scores surge anomalously. This indicates a complex interaction where not only token identity but also output length interacts with unexplored regions of the RM's scoring surface.
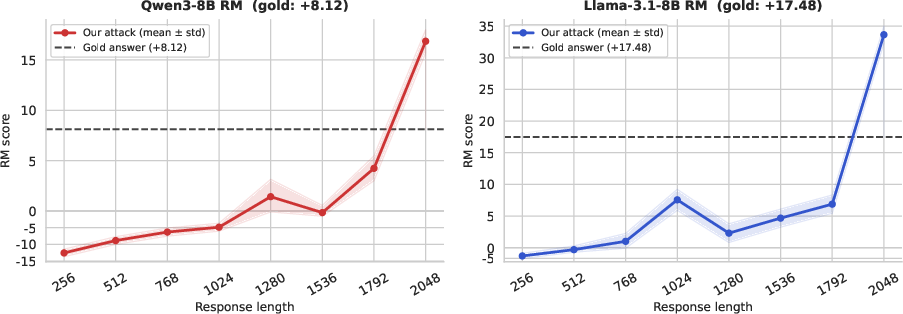
Figure 3: Truncated responses show non-linear, abrupt rewards increases at maximum allowable lengths, indicating interaction between token pattern and sequence length in RM vulnerabilities.
Optimization Dynamics
The reward improvement through RL is non-trivial. Training begins from highly negative RM scores for random, OOD-like sequences, but steadily improves as the exploration converges to "narrow subspaces" of high-reward token patterns. The transition from random and ineffective patterns to efficient reward exploitation is evident in the learning dynamics.
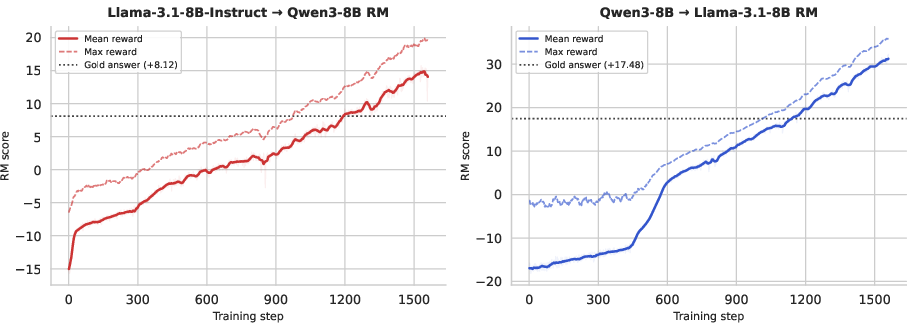
Figure 4: Training curves showing the progression from negative to strongly positive rewards, eventually eclipsing GPT-5 reference levels as RL identifies effective token-space hacks.
Theoretical and Practical Implications
The TOMPA paradigm reveals a structural misalignment between the assumed semantic grounding of RMs and their actual behavior under unconstrained optimization. That reward models, when decoupled from linguistic input, can be manipulated to assign extreme rewards to non-language sequences demonstrates that their learned objectives encode brittle heuristics over embedding space features, token co-occurrences, or length-correlated artifacts, rather than robustly capturing human preferences.
This exposes fundamental limitations in RLHF and reward modeling, particularly regarding distributional robustness and representational underspecification. These vulnerabilities persist under black-box conditions and cannot be attributed to trivial OOD handling failures, as substantiated by the random input baseline.
For deployment, TOMPA illustrates the risk of attacks or misalignments when policies or evaluation interfaces are even minimally perturbed. This is a critical concern for robustness in safety-critical applications, open-source model deployments, or orchestrated systems with components developed independently.
Speculation and Future Directions
These findings necessitate a re-examination of current RM construction and training pipelines. Potential defenses include adversarial training with non-linguistic or token-perturbed inputs, improved regularization against length and token monotonicity biases, or the introduction of explicit verification constraints to enforce semantic content validity. Furthermore, ensemble or hybrid evaluators may offer partial mitigation but cannot address structural vulnerabilities inherent to the RM representation space.
There is also a need for systematic auditing tools that probe RM behavior far outside the linguistic regime, as neural architectures scale and as RLHF is applied to novel, less-well-understood domains. Finally, inter-model tokenizer alignment and explicit interface contract validation will become increasingly important as LLM interactions grow more modular and compositional.
Conclusion
"Beyond Semantic Manipulation: Token-Space Attacks on Reward Models" (2604.02686) exposes decisive, high-impact vulnerabilities in state-of-the-art LLM reward models using TOMPA—a black-box RL attack that bypasses semantic constraints. The discovery that RMs can be hijacked to assign maximal reward to non-linguistic, adversarial token sequences calls into question the robustness of current RLHF pipelines and underscores the need for fundamentally new approaches to reward model calibration and auditing.