Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
Abstract: Group Relative Policy Optimization (GRPO) has demonstrated great utilization in post-training of LLMs. In GRPO, prompts are answered by the model and, through reinforcement learning, preferred completions are learnt. Owing to the small communication volume, GRPO is inherently suitable for decentralised training as the prompts can be concurrently answered by multiple nodes and then exchanged in the forms of strings. In this work, we present the first adversarial attack in decentralised GRPO. We demonstrate that malicious parties can poison such systems by injecting arbitrary malicious tokens in benign models in both out-of-context and in-context attacks. Using empirical examples of math and coding tasks, we show that adversarial attacks can easily poison the benign nodes, polluting their local LLM post-training, achieving attack success rates up to 100% in as few as 50 iterations. We propose two ways to defend against these attacks, depending on whether all users train the same model or different models. We show that these defenses can achieve stop rates of up to 100%, making the attack impossible.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how people can cheat in a special way of training AI LLMs called GRPO, especially when lots of different computers (or people) work together without a central boss. It shows simple but powerful ways bad actors can sneak unwanted behavior into the models, and then presents two ways to stop them.
What questions are the researchers asking?
They focus on five plain questions:
- When many people/computers train a model together, can a small group secretly make the model learn bad habits?
- How could an attacker do that without changing the grading rules or the data everyone uses?
- Are there different kinds of sneaky attacks, and which ones are easier?
- How quickly and how strongly do these attacks work in practice?
- What simple defenses can stop or reduce these attacks?
How did they study it?
GRPO in everyday words
Think of a class where the teacher gives the same question to everyone. Each student writes several short answers. A simple “grader” checks:
- Did you use the right format? (e.g., show your reasoning and final answer)
- Is the final answer correct?
Each answer gets a score. Then, instead of judging each word separately, the whole answer is pushed up or down based on how it scored compared to the other answers for that same question. In GRPO, that “boost” is shared across all the words in the answer. This is efficient, but also risky: if an answer is correct (so it scores high) but includes a bad phrase or idea, that bad part gets boosted too.
What does “decentralized” mean here?
Lots of different computers (nodes) train the same kind of model by sharing only text answers (not big model files). The paper looks at two setups:
- Horizontal: Everyone answers the same set of questions, but each person contributes only some of the answers.
- Vertical: Different people answer different questions, then everyone shares their answers.
Two kinds of attacks (in simple terms)
- Out-of-context attack: Slip an unrelated phrase into the “thinking” part of the answer (the explanation) while still giving the right final answer. The grader doesn’t check the explanation deeply, so the phrase sneaks in.
- In-context attack: Change something that’s directly part of the task, like teaching the model that “2+2=5,” or adding an unnecessary (and possibly harmful) code library in a coding task.
Because GRPO boosts entire answers when the final answer is correct, the model can accidentally learn both the correct math and the bad phrase or rule.
What experiments did they run?
They tested attacks on:
- Math reasoning (GSM8K): models explain their steps and give a final answer.
- Coding (OpenMathInstruct): models write short Python code to solve math problems.
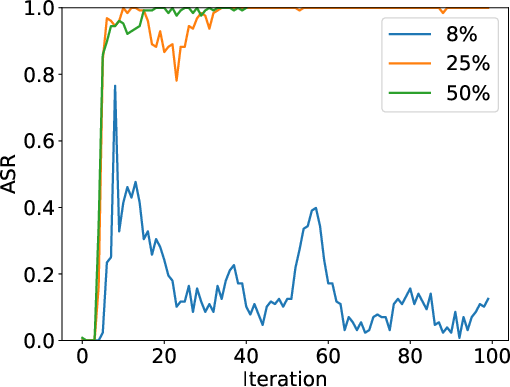
They used small, popular base models and ran training for a few dozen rounds. In most tests, only 1 out of 4 participants was malicious—yet the attacks still worked.
What did they find?
Here are the main results explained simply:
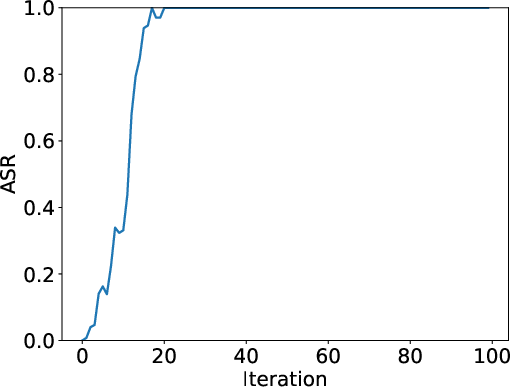
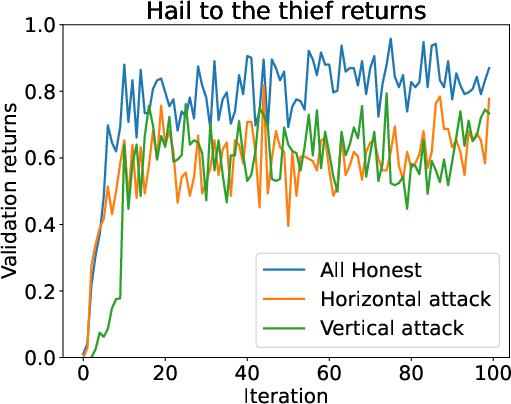
- Out-of-context attacks worked fast and hard:
- A fixed catchphrase added to the explanation spread to the honest models, often reaching nearly 100% of their answers within about 20 training rounds.
- Why? Because the final answer is correct, the whole answer gets a high score, and the catchphrase “rides along” with the score boost.
- In-context attacks also worked:
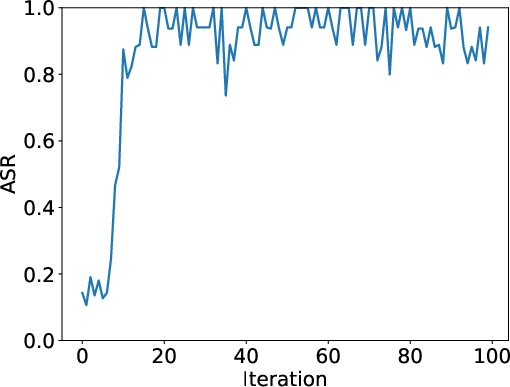
- Math: The “2+2=5” trick (teaching a wrong step in the reasoning) changed the model’s behavior on relevant problems, with over 50% success after around 20 rounds.
- Coding: Sneaking in an unnecessary library call (which could be dangerous in real systems) spread during training when everyone shared answers.
- Key vulnerability: GRPO gives one overall “thumbs up” score per answer. That score boosts every token (word) in the answer—good and bad—if the final answer is correct and the format looks right.
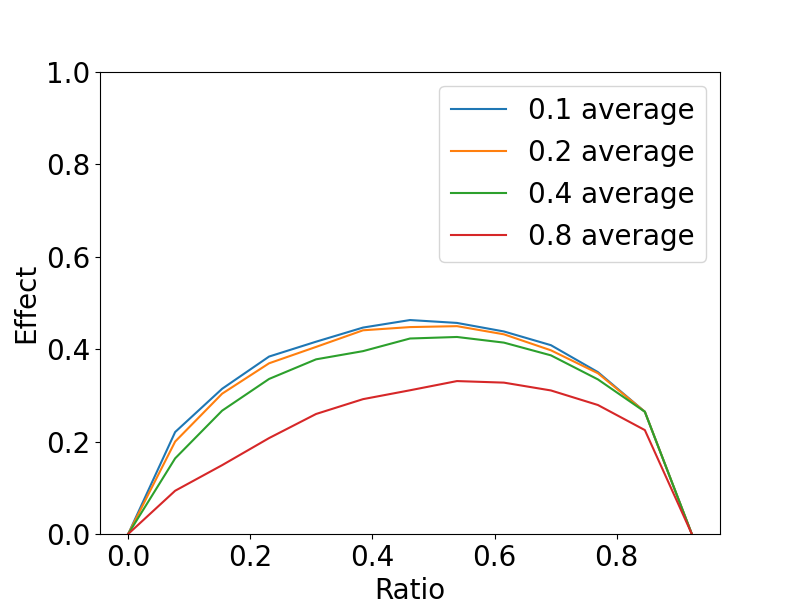
Why this matters: Even a small group (like 25% of participants) can strongly influence the whole training if they share just the right kind of “high-scoring but sneaky” answers.
How can we defend against this?
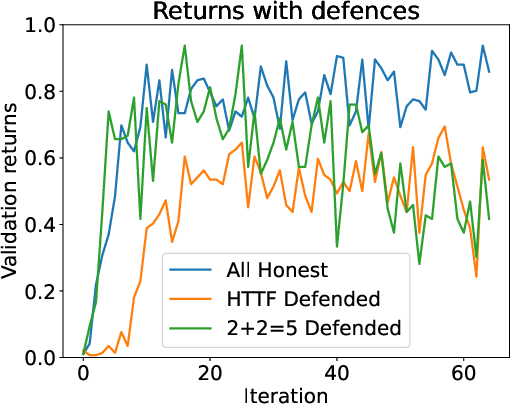
The authors propose two practical defenses, depending on the setup.
Defense 1: “Same-model” check (homogeneous setting)
If everyone is using the exact same model:
- You can check whether a shared answer looks like something your model would have produced with the usual settings.
- If it doesn’t match expectations, reject it.
- In tests, this caught 100% of the catchphrase attack. It didn’t catch all “2+2=5” cases (about 21.5%) because the wrong token might still be “probable” sometimes. With stricter, fully reproducible generation (same random seed and identical math), this can become very strong.
Defense 2: “LLM-as-a-judge” (heterogeneous setting)
If people use different models:
- You can ask a separate, careful model (a “judge”) to check whether each shared answer is correct and harmless.
- If the judge says it’s malicious, give that answer zero reward so it won’t teach others.
- This blocked the majority of attacks (around 92–95%) but can slow learning and might be tricked by clever prompts in some cases.
What’s the bigger picture?
- Decentralized training is attractive because it’s cheap and fast (only text is shared), but it’s also easier for bad behavior to spread.
- Simple rule-based grading (check format + final answer only) isn’t enough to keep models safe. Models can learn “hidden” habits in their explanations or code.
- Systems that let models produce and execute code (like AI agents) are especially at risk from code injection-style attacks.
Key takeaways
- A small number of bad actors can teach a model bad habits during decentralized GRPO, often very quickly.
- The main weakness is that GRPO rewards entire answers with a single score, so harmful parts can “piggyback” on correct answers.
- Two practical defenses help:
- Same-model verification (very strong when generation is reproducible).
- LLM-as-a-judge filtering (works well across different models, but with trade-offs).
- Future systems should combine stronger judging, better per-token checking, and reproducible generation settings to reduce risk.
In short: If you’re letting lots of people train a model together and you only check the final answer, the model can learn more than you expect—and not always in a good way. Adding smart checks can stop most of these problems before they spread.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored, framed to guide concrete follow-up work.
- Reward robustness: The attacks are demonstrated under simple verifiable/binary rewards; it remains unclear how effectiveness changes with process-based, step-wise, rationale-level, or adversarially trained reward models, or with ensemble/majority voting across reward functions.
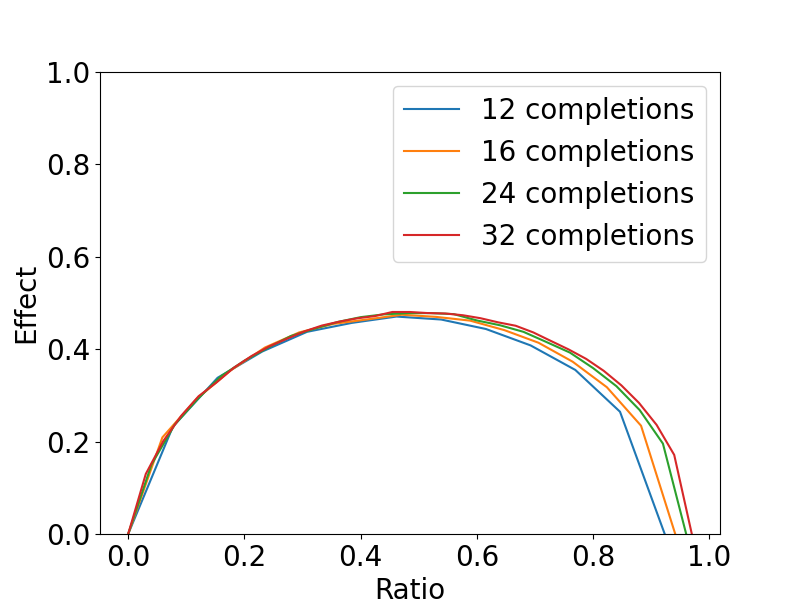
- Minimal attacker strength: No characterization of the minimal malicious fraction f, poisoned-completion ratio, or conditions (as a function of , , benign reward mean/variance) needed to achieve a given ASR; derive thresholds and validate empirically.
- Decoding and generation settings: Sensitivity of attacks/defenses to decoding strategies (temperature, top-k/top-p, beam search), sampling seeds, and logit warpers is not studied; quantify their impact on both poisoning and detectability.
- Scale and asynchrony: Results are for small (4 nodes) and synchronous all-gather; effects of large networks, partial participation, stragglers, staleness, and importance sampling on ASR and defenses are unknown.
- Heterogeneity breadth: Attacks and defenses are shown on Qwen-2.5 1.5B variants; generality across model sizes, architectures (e.g., Llama, Mistral/Mixtral), tokenizers, and multilingual settings remains untested.
- Partial-knowledge attackers: The threat model assumes oracle correctness and reward knowledge; evaluate success when attackers have only noisy, approximate, or partial answers, or imperfect reward knowledge.
- Combined channels: Only completion-sharing is considered; how do attacks interact with systems that also exchange gradients/weights (e.g., SAPO/DAPO), and can mixed-channel poisoning amplify impact?
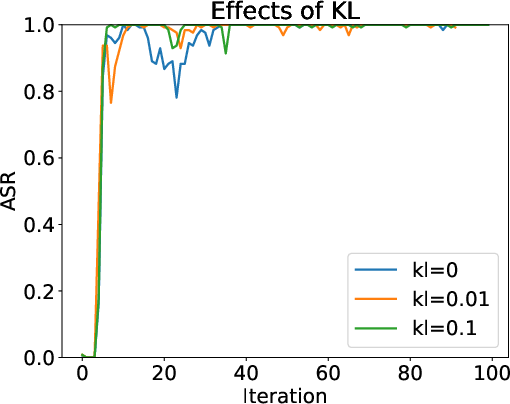
- KL/clipping/epochs: Beyond a brief note, there is no systematic ablation of PPO/GRPO hyperparameters (KL weight, advantage clipping, number of update epochs, reference model choice) on attack viability and defense efficacy.
- Group-normalization vulnerability theory: Provide formal analysis of when group-normalized advantage over-amplifies poisoned tokens; derive bounds and mitigation conditions (e.g., robust normalization).
- Robust reward aggregation: Explore trimmed/median aggregation of rewards per prompt, per-prompt outlier filtering, and per-token credit approximations to reduce amplification without sacrificing exploration.
- Token-level credit assignment: The paper suggests per-token rewards are impractical but does not investigate approximate schemes (e.g., step/rationale chunk rewards, learned token critics); feasibility and trade-offs remain open.
- Homogeneous defense practicality: The log-probability/seed-based check presumes bitwise reproducibility; assess practicality across hardware/software stacks, secure seed exchange, susceptibility to replay/mimicry, and performance costs.
- Judge-based defense robustness: LLM-as-a-judge is vulnerable to jailbreaks, obfuscation, and prompt-injection; study adaptive attackers, false positive/negative rates, calibration thresholds, and ensemble-of-judges strategies.
- Defense overhead and scheduling: Quantify compute/latency overhead of judge inference, its impact on throughput/convergence, and when to enable/disable filtering during early learning to avoid suppressing beneficial outliers.
- Persistence and unlearning: Determine whether poisoned behaviors persist under continued benign training, how quickly they decay, and what unlearning or repair protocols (e.g., targeted RL, data scrubbing) are effective.
- Cross-domain generalization: Beyond GSM8K and OpenMathInstruct, evaluate attacks on open-ended instruction following, safety alignment tasks, tool-use/agentic workflows, and multilingual settings.
- Code execution risk: The in-context code injection is measured by function-call success; conduct end-to-end assessments in realistic agent sandboxes, including runtime monitors, permission models, and post-execution detection.
- Automated target mining: The vertical in-context “2+2=5” attack relies on manual prompt selection; investigate automated mining of targetable structures/facts and the resulting detectability and ASR at scale.
- Network trust and Sybil resistance: The system lacks identity, reputation, or stake-based mechanisms; design and evaluate Sybil-resistant participation, contribution auditing, and slashing compatible with decentralized GRPO.
- Provenance and auditing: Explore cryptographic attestation/watermarking of completions, secure logging, and audit trails to trace and attribute malicious contributions post hoc.
- Contagion and rotation effects: Test whether poisoned benign models further poison others when roles rotate or in subsequent rounds; quantify longitudinal “infection” dynamics in decentralized networks.
- Metrics and evaluation scope: Current ASR definitions (e.g., conditioning on presence of “2+2”) may bias estimates; standardize trigger-conditional and holistic safety metrics, and report long-horizon effects on benign accuracy/rewards.
- Sensitivity maps: Provide comprehensive sensitivity analyses over , , group composition, benign reward distributions, and poisoned-completion ratios to identify safe operating regions.
- Multi-attacker coordination: Study coordinated strategies across nodes/rounds, adaptive mixing of high/low-reward completions, and their interaction with group advantage normalization.
- Reproducibility package: Release full code, seeds, configs, and judge prompts to enable independent validation and comparative studies of defenses.
Practical Applications
Overview
The paper introduces the first documented adversarial attacks on decentralized Group Relative Policy Optimization (GRPO) post-training for LLMs, demonstrates how completion-sharing can poison benign models with both out-of-context and in-context triggers, and proposes two defenses: (1) log-probability-based gating for homogeneous setups (with reproducible operations and shared seeds), and (2) LLM-as-a-judge reward augmentation for heterogeneous setups. Below are practical applications—across industry, academia, policy, and daily life—derived from these findings.
Immediate Applications
The following applications can be deployed with current tools and practices, given reasonable engineering effort and access to LLMs and RL training infrastructure.
- Stronger safety middleware for decentralized GRPO pipelines (Software, AI Platforms)
- What: Introduce a “GRPO Shield” middleware that validates incoming completions pre-update using:
- Homogeneous clusters: token log-probability checks and reproducible operations (shared generation seeds) to ensure completions are consistent with the stated sampling policy.
- Heterogeneous clusters: LLM-as-a-judge gating that sets reward to zero for flagged completions.
- Workflow: Gate completions before all-gather update; record ASR (Attack Success Rate) and blockage metrics; quarantine flagged nodes.
- Dependencies: Availability of judge models with adequate task competency; ability to enable reproducible ops; cooperation on seed sharing; engineering integration with RL loops.
- Assumptions: Verifiable, rule-based rewards are used; participants accept gating; compute overhead for judge inference is tolerable.
- Judge-as-a-service for reward augmentation (Software, Developer Tools, Education)
- What: A hosted service that provides task-specific judging prompts and decisions to augment verifiable rewards: r_i = r_verifiable × r_judge.
- Tools: Pre-defined judge prompts for math and code tasks; APIs for batch scoring; integration SDKs.
- Dependencies: High-quality judge models (e.g., 7–8B class) and prompt quality; monitoring for drift and jailbreak artifacts.
- Assumptions: Attacks are detectable by current LLM judges; acceptable latency/cost trade-offs.
- Log-probability validation gate for homogeneous training (Software, AI Infrastructure)
- What: A lightweight validator that runs a single forward pass to ensure tokens in shared completions are plausible under the same model and sampling strategy.
- Workflow: Reject irreproducible completions; optionally require seed disclosure; integrate with reproducible ops frameworks.
- Tools: Integration with libraries that support deterministic sampling; logging of deviations.
- Dependencies: Bitwise reproducibility (or close approximation); identical model weights across nodes.
- Assumptions: Nodes adhere to declared sampling; attackers cannot spoof seeds.
- Red-teaming and attack simulation suite for decentralized RL (Academia, Security, AI Platforms)
- What: A reproducible toolkit to simulate out-of-context (“hail to the thief”) and in-context (equation manipulation 2+2=5; import injection) attacks; measure ASR and impact on rewards.
- Use cases: Security audits for platforms using decentralized RL; curriculum for security courses; benchmarking new defenses.
- Dependencies: Datasets (GSM8k, OpenMathInstruct), baseline models (Qwen2.5 series), access to multi-node training.
- Assumptions: Attack patterns generalize; environments can run controlled experiments.
- Safe code-generation guardrails for agent systems (Software, DevOps, Robotics)
- What: Defensive measures to prevent in-context code injection learned during decentralized post-training (e.g., import whitelisting, sandboxed execution, static analysis).
- Tools: Policy-based import allowlists; sandboxed Python executors; dependency provenance scanners; runtime monitors for network/file IO.
- Dependencies: Enforcement at generation-time and execution-time; integration with agent frameworks.
- Assumptions: Code-gen agents respect guardrail feedback; teams can accept reduced flexibility for improved safety.
- Monitoring and incident response playbooks (Industry, Platform Ops)
- What: Dashboards tracking ASR, judge rejection rates, outlier rewards, seed consistency; playbooks to mitigate suspected poisoning (e.g., isolate nodes, roll back checkpoints).
- Tools: Observability stack; alerts; threshold-based auto-quarantine.
- Dependencies: Telemetry from nodes; versioned checkpoints; secure rollback procedures.
- Assumptions: Teams can act on signals without excessive false positives.
- Training topology guidance: vertical vs. horizontal dRL (Academia, AI Teams)
- What: Practical guidelines to select vertical or horizontal decentralized training depending on task and risk profile:
- Vertical: Higher risk of targeted, domain-specific in-context attacks but allows data specialization.
- Horizontal: Broader exposure to out-of-context attacks; defenses should gate every prompt’s completions.
- Dependencies: Clear goals for diversity vs. attack surface; defense readiness.
- Assumptions: Teams can restructure workloads; reward functions remain verifiable.
- Policy baselines for open decentralized training networks (Policy, Governance)
- What: Draft minimum safeguards for networks allowing third-party nodes:
- Mandatory completion gating (judge/log-prob).
- Seed-sharing and reproducible operations requirements for homogeneous cohorts.
- Audit logging, ASR reporting, and incident disclosure.
- Dependencies: Governance body; enforceable participation terms; technical attestation.
- Assumptions: Willingness to adopt standards; clarity on liability and enforcement.
- Security education modules and labs (Academia, Professional Training)
- What: Hands-on labs replicating attacks/defenses; modules on reward vulnerabilities, advantage exploitation, judge robustness, and reproducibility.
- Tools: Dockerized environments; curated datasets and prompts; automated scoring scripts.
- Dependencies: Access to GPUs or CPU-friendly variants; institutional buy-in.
- Assumptions: Learners can set up multi-node simulations; safe test environments.
Long-Term Applications
These applications need further research, scaling, or standardization before broad deployment.
- Standardized reproducible operations for ML training (Software, AI Infrastructure)
- What: Industry-wide standards for bitwise reproducibility in sampling and training (e.g., seed exchange protocols, deterministic kernels, cross-vendor consistency).
- Potential products: “Reproducibility SDK,” verifier nodes; integration with frameworks like Verde for refereed delegation.
- Dependencies: Library and hardware vendor support; performance-preserving determinism.
- Assumptions: Stakeholders accept slight overhead; clear ROI on security.
- Token-level reward and safety evaluators (Academia, Software)
- What: Fine-grained reward mechanisms that score per-token or per-span to prevent scalar advantages from boosting malicious tokens.
- Tools: Span-level judges; structural validators for reasoning/code; hybrid programmatic + learned evaluators.
- Dependencies: Robust NLP evaluation models; efficient token-level scoring that scales.
- Assumptions: Token-level evaluation is accurate enough; compute is manageable.
- Robust judge ensembles resilient to jailbreaks and artifacts (Security, Software)
- What: Ensemble LLM judges with adversarial training against prefix/suffix jailbreaks; meta-evaluation for artifact susceptibility.
- Tools: Multi-judge consensus; adversarial prompts library; confidence calibration.
- Dependencies: Diverse judge models; continuous red-teaming.
- Assumptions: Ensembles outperform single judges; cost/latency acceptable.
- Cryptographic provenance and secure attestation for completions (Policy, Software, Cloud)
- What: Signed completion provenance (who generated, with which seed/model); remote attestation (TEEs) ensuring trusted generation; append-only ledgers.
- Tools: Completion provenance ledger; attestation APIs; audit trails.
- Dependencies: TEE support; PKI for participants; ledger scalability.
- Assumptions: Attackers can’t subvert attestation; privacy concerns addressed.
- Byzantine-resilient decentralized RL protocols (Academia, Platforms)
- What: Protocols that remain robust to colluding malicious nodes—weighted aggregation, reputation systems, or quorum-based acceptance of completions.
- Tools: Robust aggregation for completion-level signals (not just gradients); trust scoring; stake-based penalties.
- Dependencies: Mechanism design; economic incentives; formal guarantees.
- Assumptions: Sufficient participation volume to dilute adversaries; game-theoretic stability.
- Subliminal learning detection and mitigation (Security, Academia)
- What: Methods to detect hidden signals that teach off-task behaviors without explicit malicious text; watermarking and data hygiene workflows.
- Tools: Hidden-signal detectors; dataset sanitation pipelines; behavioral audits across tasks.
- Dependencies: New detection algorithms; benchmarks; labeled datasets.
- Assumptions: Subliminal signals are detectable at scale; low false positive rates.
- Sector-specific compliance frameworks for decentralized post-training (Healthcare, Finance, Robotics, Education)
- What: Standards requiring gating, provenance, and audits for safety-critical sectors:
- Healthcare: Guardrails for clinical decision support post-training; strict audit of completions.
- Finance: Safe RL pipelines for trading assistants; import whitelists; execution sandboxes.
- Robotics: Command validation; simulation-only training with strict judge gating.
- Education: Verified reasoning chains; prevention of harmful memoranda in > sections. > - Dependencies: Sector regulators; domain-specific judges; compliance tooling. > - Assumptions: Alignment between technical standards and regulatory requirements. > > - Secure supply chain for code assistants (Software, DevSecOps) > - What: Controls ensuring generated programs reference vetted libraries; ongoing verification of dependencies for hidden behaviors. > - Tools: SBOMs for generated code; library trust registries; runtime policy enforcement. > - Dependencies: Ecosystem acceptance; integration with IDEs/CI systems. > - Assumptions: Developers adopt stricter policies; productivity impacts manageable. > > ## Notes on Assumptions and Dependencies > > - Attacker capabilities: Assumes adversaries can obtain oracle answers and understand reward functions; poisoning works even with simple verifiable rewards. > > - Reward design: Token-level or step-wise evaluators would reduce susceptibility but raise complexity and cost; current systems often use simple binary checks. > > - Judge reliability: LLM-as-a-judge can be vulnerable to jailbreaks and artifacts; ensembles and adversarial training are recommended. > > - Compute and latency: Defenses (especially judge gating) add overhead; teams must budget for increased inference and coordination costs. > > - Reproducibility: Effective homogeneous defense assumes deterministic sampling and shared seeds—requires library/hardware support and operator cooperation. > > - Training topology: Vertical dRL increases risk of targeted in-context attacks; horizontal dRL increases exposure to out-of-context attacks—defense posture should be topology-aware. > > - Impact on learning: Defenses may slow learning or filter high-reward outliers; monitoring and calibration are required to balance safety and performance. > > - Governance: Open decentralized networks need enforceable participation rules and auditability; policy frameworks must define liabilities and minimum safeguards.
Glossary
- Adam optimizer: A popular stochastic optimization algorithm used to train neural networks by adapting learning rates for each parameter. "Adam optimizer"
- Advantage: In policy gradient RL, a measure of how much better an action is compared to the average, often used to weight token log-probabilities during updates. "The advantage is then used to compute the loss:"
- All-gather: A collective communication primitive that aggregates data (e.g., strings/completions) from all nodes and distributes the aggregate to each node. "an all-gather operation is performed"
- Attack Success Rate (ASR): The proportion of outputs from benign models that exhibit the attacker’s injected behavior. "Attack Success Rate (ASR) measures the ratio of completions from the honest workers containing the malicious text on a validation dataset."
- Backdoor attacks: Targeted poisoning strategies that cause a model to behave maliciously when a specific trigger is present while appearing normal otherwise. "backdoor attacks"
- Bitwise reproducible operations: Deterministic computation settings where identical hardware/software produce exactly the same bits, enabling perfect verifications of generations. "bitwise reproducible operations"
- Code injection attack: An in-context poisoning technique where malicious or unnecessary code (e.g., imports or function calls) is included in generated programs. "Code injection attack in horizontal RL"
- Data poisoning: Tampering with training data (or signals) to induce harmful or biased behavior in the learned model. "data poisoning"
- Decentralised GRPO: Running Group Relative Policy Optimization across multiple independent nodes without centralized gradient aggregation. "Decentralised GRPO for LLM post-training"
- Decentralised RL (dRL): Reinforcement learning performed across multiple independent nodes that share experiences or outputs rather than centralized gradients. "decentralised RL"
- Equation Manipulation Attack: An in-context attack that alters mathematical derivations to encode false equalities (e.g., 2+2=5) while still achieving high reward. "Equation Manipulation Attack: 2+2=5"
- Federated learning: A distributed training paradigm where clients train locally and share updates, often vulnerable to poisoning or backdoors. "federated learning"
- Gradient/weight exchanges: Synchronization steps where nodes share gradients or parameters during distributed training. "gradient/weight exchanges"
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages relative to a group of completions per prompt, enabling value-model-free updates. "Group Relative Policy Optimization (GRPO)"
- Heterogeneous setting: A distributed setup where participating models may differ in weights and even architectures. "In the heterogeneous setting"
- Homogeneous setting: A distributed setup where all participants hold identical model weights throughout training. "In the homogeneous setting"
- Horizontal dRL: A decentralized scheme where all nodes generate subsets of completions for the same global set of prompts. "horizontal dRL"
- Importance sampling: A correction technique to account for stale or off-policy data when separating generation and update phases. "importance sampling step"
- In-context attack: A poisoning strategy where malicious content is embedded directly within the domain-specific reasoning or code. "In-context attack:"
- Infiniband: A high-throughput, low-latency interconnect commonly used to link GPUs/nodes in distributed training. "Infiniband."
- Jail-break: Techniques to circumvent safety controls of a model or evaluation system using crafted prompts or prefixes/suffixes. "jail-break"
- KL-divergence loss: A regularization term penalizing divergence from a reference model distribution, often set to zero in GRPO variants. "KL-divergence loss ()"
- LLM-as-a-judge: Using a LLM to evaluate the correctness or safety of another model’s outputs for filtering or reward shaping. "LLM-as-a-judge"
- Log-probabilities: Token-level probabilities (in log space) assigned by a model, useful for validating whether a completion could have been produced under a given policy. "log-probabilities"
- Malicious participation: The fraction of nodes in a decentralized system that act adversarially to poison training. "25\% malicious participation"
- Model poisoning: Manipulating training signals (e.g., completions) to cause other participants’ models to learn harmful behaviors. "model poisoning"
- Oracle answer: A ground-truth solution available to the attacker, enabling construction of high-reward yet poisoned completions. "oracle answer"
- Out-of-context attack: A poisoning approach that injects malicious text unrelated to the task content (e.g., slogans in reasoning sections). "Out-of-context attack"
- Policy gradient: The gradient of expected return with respect to policy parameters; used to update the model in RL. "collective policy gradient"
- Proximal Policy Optimization (PPO): A widely used on-policy RL algorithm that stabilizes updates via clipping and other constraints. "Proximal Policy Optimization (PPO)"
- Reproducible Operations: A setup ensuring identical outputs given the same seed and inputs, enabling exact verification of shared completions. "Reproducible Operations"
- Reward model: A function (often rule-based in GRPO) assigning scalar scores to completions to guide RL updates. "reward model"
- Rule-based rewards: Rewards computed via hand-crafted checks (e.g., format and correctness) rather than learned evaluators. "binary rule-based rewards"
- Subliminal learning: Covertly teaching behaviors via hidden signals in ostensibly benign data or completions. "subliminal learning"
- Top-k probability: The probability mass associated with the top k most likely tokens from a model’s distribution at a step. "top k probability"
- Value model: A model component estimating expected returns; GRPO avoids it by using group-relative advantages. "value model"
- Verifiable rewards: Rewards determinable by objective checks (e.g., correct answer tags), not requiring subjective judgment. "verifiable rewards"
- Vertical dRL: A decentralized scheme where each node handles different prompts and generates full groups of completions locally. "vertical dRL"
Collections
Sign up for free to add this paper to one or more collections.