- The paper introduces a certified online learning algorithm that computes Nash equilibrium policies for zero-sum LQ games with unknown dynamics.
- It combines regularized least squares estimation with confidence sets and surrogate model certification to maintain closed-loop stability during policy updates.
- The approach achieves O(√T) cumulative regret, as confirmed by numerical simulations on a 3D state-space system, with applications in robotics and adversarial control.
An Online Learning Algorithm for Two-Player Zero-Sum Linear Quadratic Games with Unknown Dynamics
Introduction and Problem Setting
This paper delivers a formal treatment of online learning for two-player zero-sum linear quadratic (LQ) games when the system dynamics are unknown. The main challenge is to design a learning procedure that computes Nash equilibrium (NE) policies solely from interaction data, ensuring closed-loop stability and robust performance guarantees, notably sublinear regret with respect to the steady-state game value.
The setup is a discrete-time dynamic system
xt+1=Axt+B1ut+B2vt+wt,
where ut (player 1) minimizes and vt (player 2) maximizes the infinite-horizon average cost, quadratic in state and controls. Both players' objectives are perfectly antagonistic. The matrices A, B1, B2 are unknown, necessitating online identification.
The Nash equilibrium can, in principle, be encoded via generalized algebraic Riccati equations (GARE). With unknown dynamics, learning must occur interactively, presenting unique technical impediments not present even in single-agent online LQR: the adversarial coupling of policies, the need for regularity, and persistent satisfaction of Riccati solvability and system stability during learning.
Online Learning Algorithm: Certified System Identification and Policy Synthesis
The core methodological innovation is a certified online certainty equivalence algorithm imposing strong regularity constraints during surrogate model updates. Each iteration proceeds as follows:
Persistent excitation (typically enforced via i.i.d. exploration signals ut5 added to the controls) is assumed. Policies are updated episodically whenever the information matrix determinant doubles, as per the traditional doubling-trick to control statistical error.
Regret Analysis and Main Theoretical Guarantees
A comprehensive regret analysis establishes that, with high probability, the algorithm achieves overall cumulative regret ut6 over the horizon. The proof is organized as follows:
- Estimation error rates: The certified surrogate model remains uniformly close to the true system, with ut7, as guaranteed by the confidence ellipsoid and persistent excitation.
- Regularity transfer: Exploiting Lipschitz continuity of the Riccati operator and saddle gains with respect to the dynamics parameterization, errors propagate linearly from dynamics to policies, and quadratically in cost.
- Regret decomposition: Regret is split into three additive terms:
- Transient regret: At most ut8, due to episodic resets.
- Exploration cost: ut9, matching minimax rates.
- Policy gap: vt0, due to imperfect model-based policies within each episode, controlled by the squared parameter error.
The dominant term is the exploration-induced vt1, making the algorithm rate-optimal.
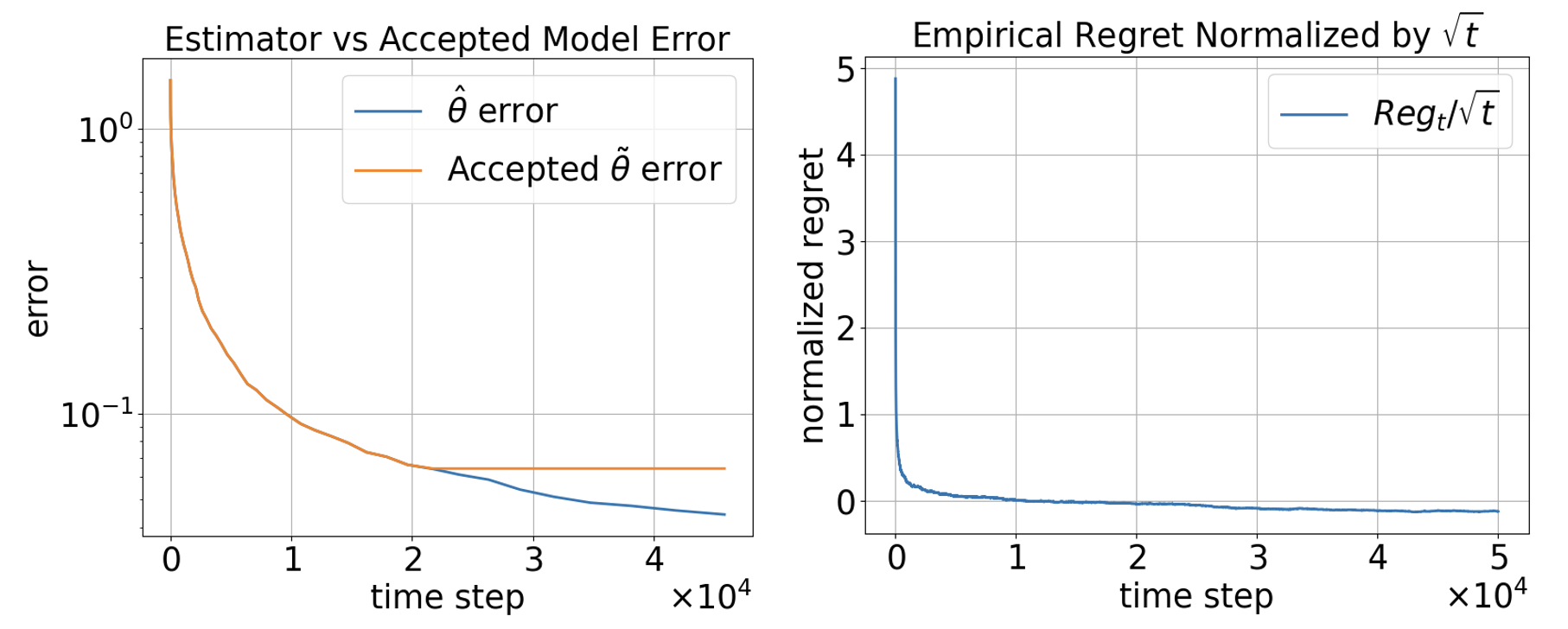
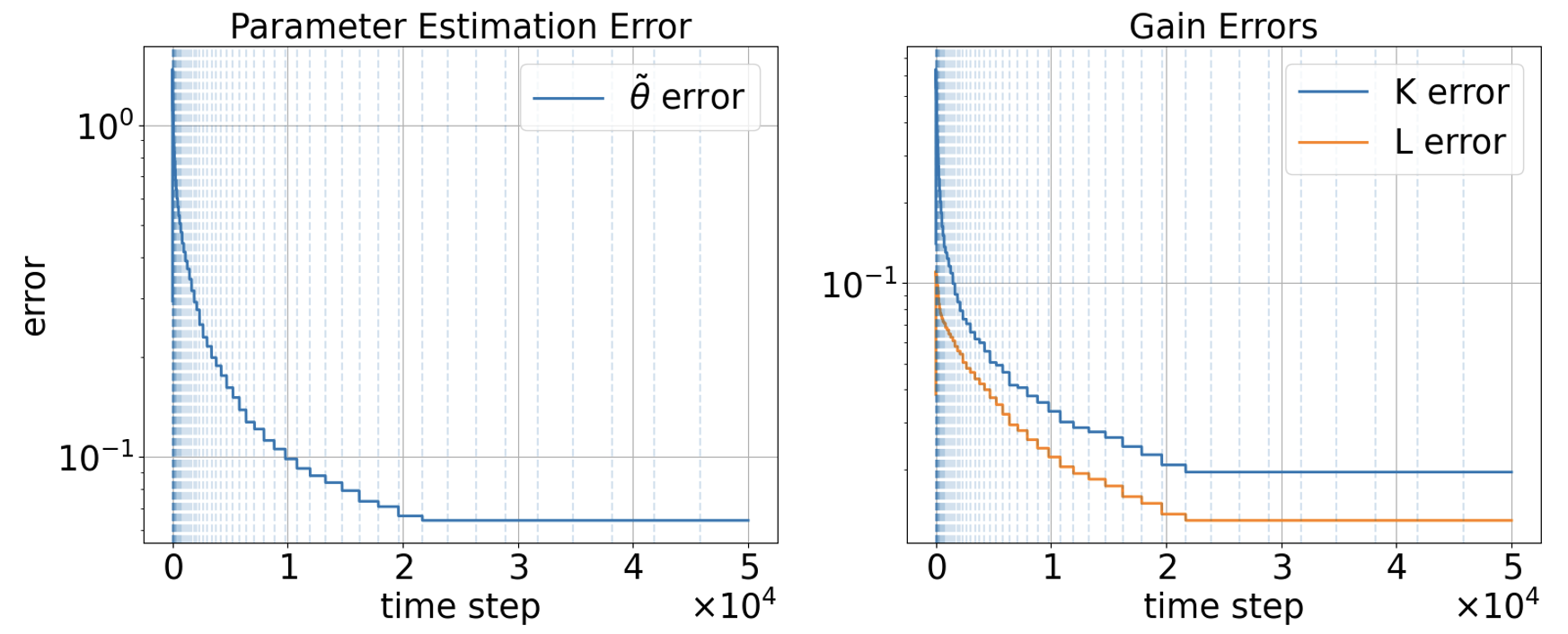
Figure 2: Comparison of vt2 and vt3 (left), and regret convergence (right).
Simulation results confirm these analytical claims: both parameter estimates and NE gain errors monotonically decrease, and the observed regret normalized by vt4 asymptotes to a bounded value, verifying the sublinear rate.
Numerical Evaluation
The numerical experiments instantiate a 3-dimensional state-space system and demonstrate all key aspects:
- Theta estimation error and gain errors for both players decrease consistently with policy update episodes.
- The certified surrogate remains more conservative than the raw ridge estimate, notably in early episodes, illustrating the necessity and performance impact of regularity enforcement.
- Regret normalized by vt5 stabilizes, empirically matching the theoretical sublinear bound.
Practical and Theoretical Implications
This approach bridges online statistical estimation, robust control synthesis, and game-theoretic equilibrium computation for adversarial multi-agent systems with unknown dynamics. From a practical standpoint, the technique is applicable to a range of LQ game settings in multi-robotics, adversarial cyber-physical control, and robust networked systems.
The chief methodological advantage is the simultaneous assurance of regret-optimal learning and robust feasibility of each policy update—a major shortcoming in existing naive online control algorithms in general-sum or adversarial settings.
Theoretically, the analysis introduces novel techniques in transferring concentration and regularity bounds through nontrivial Riccati operators and establishes the first vt6 regret result for the adversarial two-player, zero-sum LQ control with fully unknown dynamics.
Future Directions
Several possible extensions are immediate:
- Removing the requirement for explicit i.i.d. exploration (persistent excitation).
- Extending the framework to the partially observed setting, where the system state is not directly available.
- Generalizing to vt7-player games with more complex objective structures.
- Addressing non-stationary or time-varying dynamics.
Conclusion
This paper establishes a theoretically sound and empirically validated online learning algorithm for zero-sum LQ games with unknown dynamics. By integrating statistical estimation, model certification, and robust control, the method ensures vt8 regret, stability, and feasibility throughout learning. The surrogate-based regularization framework resolves a crucial open problem at the interface of learning-based control and dynamic games, with significant potential for further extension to more complex and high-dimensional multi-agent systems.
Reference: "An Online Learning Approach for Two-Player Zero-Sum Linear Quadratic Games" (2604.02619)