Moondream Segmentation: From Words to Masks
Abstract: We present Moondream Segmentation, a referring image segmentation extension of Moondream 3, a vision-LLM. Given an image and a referring expression, the model autoregressively decodes a vector path and iteratively refines the rasterized mask into a final detailed mask. We introduce a reinforcement learning stage that resolves ambiguity in the supervised signal by directly optimizing mask quality. Rollouts from this stage produce coarse-to-ground-truth targets for the refiner. To mitigate evaluation noise from polygon annotations, we release RefCOCO-M, a cleaned RefCOCO validation split with boundary-accurate masks. Moondream Segmentation achieves a cIoU of 80.2% on RefCOCO (val) and 62.6% mIoU on LVIS (val).







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
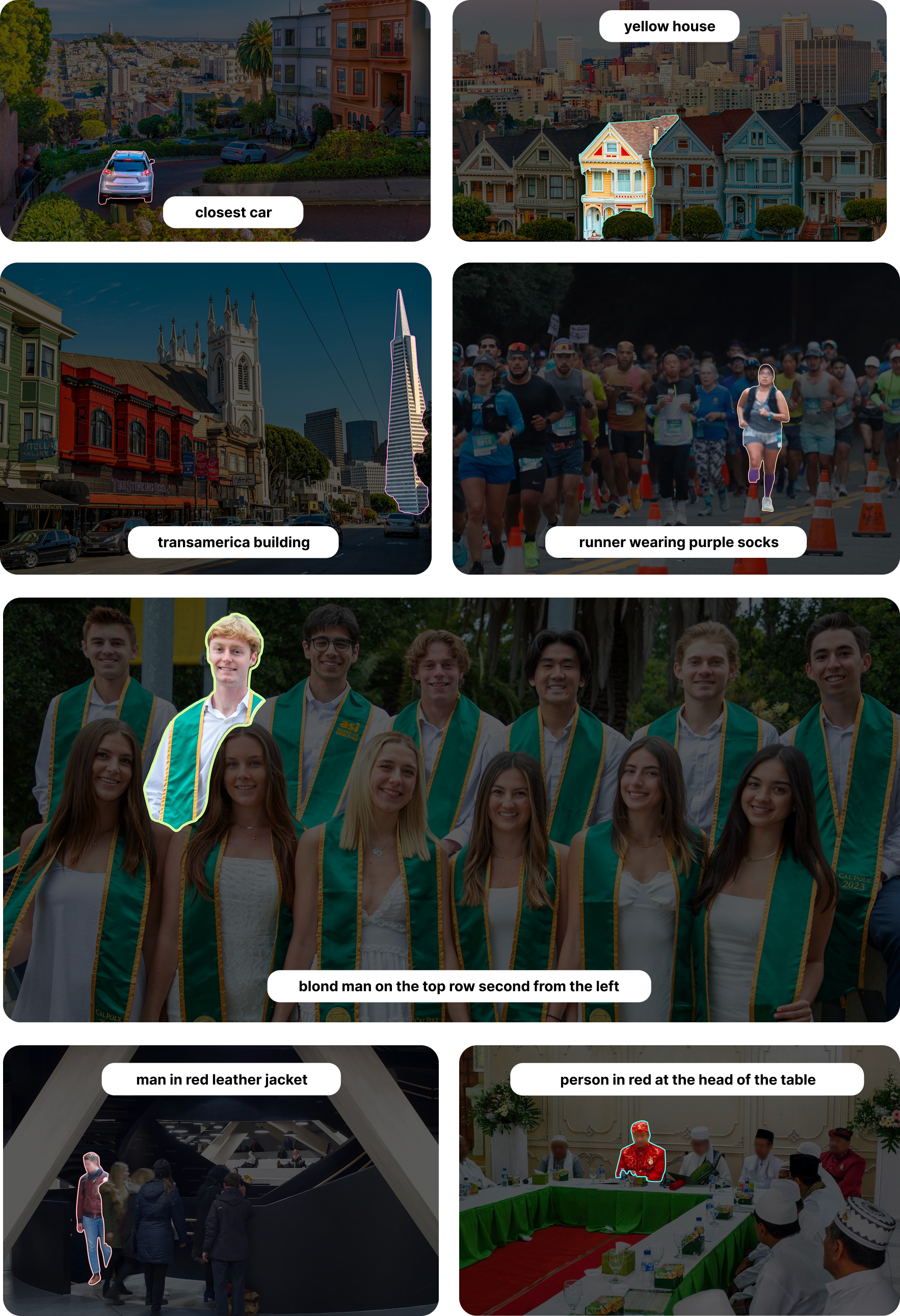
This paper introduces “Moondream Segmentation,” a computer program that can take a picture and a short description like “the red car on the left,” then accurately color in exactly those pixels that belong to the thing you asked for. In simple terms, it’s a tool that turns words into precise cut‑out shapes in an image, which is useful for editing photos, making collages, or labeling objects.
The main questions the paper asks
- Can a vision–LLM (an AI that understands both pictures and text) turn a short text description into a clean, accurate outline of the right object in a photo?
- Can it do this with sharp edges and fine details, not just rough blobs?
- How can we train it so that it learns to draw the right shape even when there are many equally valid ways to describe that shape?
How the method works (in everyday terms)
Think of the task like cutting out a shape from a magazine after someone tells you which object to cut out.
The system works in two big steps:
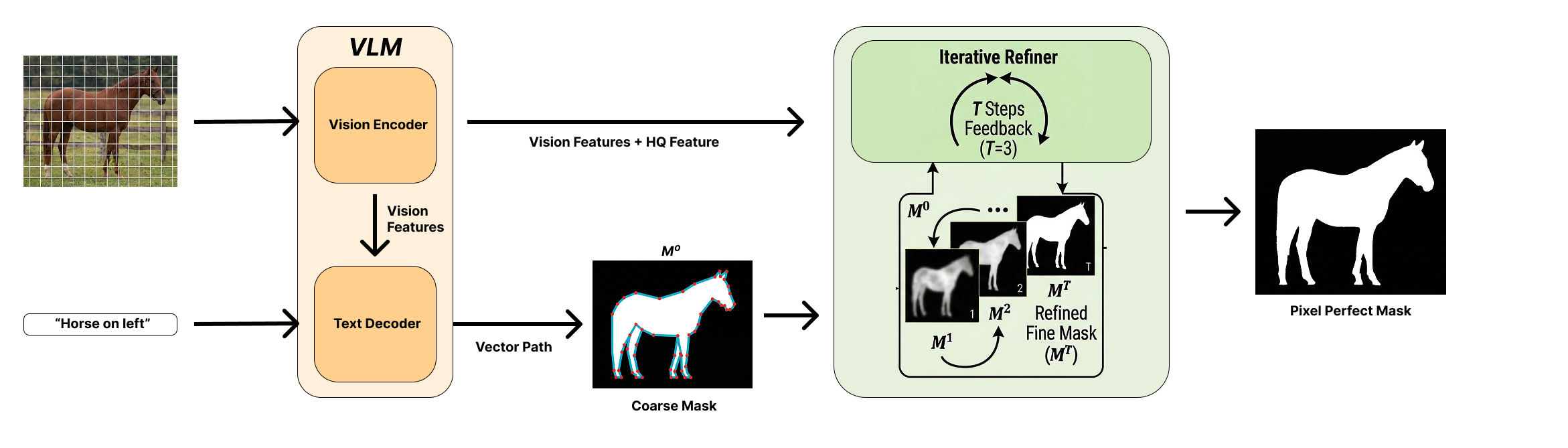
- Drawing a rough outline with a “vector path”
- Imagine tracing the object with a pen tool in a drawing app (like the “Pen Tool” in Photoshop or an SVG path).
- The model first guesses a bounding box (a rectangle around the object).
- Then it “writes” a sequence of drawing commands (move here, draw a line, draw a curve) that form a clean outline. This outline is called a “vector path.”
- That outline is then turned into pixels (this is called “rasterizing”), giving a coarse mask—basically a first draft of the cut‑out.
- Sharpening and fixing the mask with a “refiner”
- Next, a second module takes this rough mask and the image and improves it step by step.
- It tightens edges, fills in missing bits, and cleans up mistakes over several small “refinement” rounds, ending with a detailed, high‑quality mask.
Why two steps?
- The first step is like sketching the general shape quickly.
- The second step is like going over it carefully with an eraser and fine-liner to make it look clean and accurate.
A simple training trick: rewarding the final result There are many different correct ways to write the same vector outline (you can start at different points, use different curve commands, etc.), but they can all produce the same final shape. If you punish the model for not matching some exact text sequence, you teach it the wrong lesson. Instead, the authors use a reinforcement learning “reward” that scores the final mask quality (how well the cut‑out matches the true object), not the exact tokens used to draw it. It’s like grading the final cut‑out instead of the order of steps used to cut it.
They also change what they reward over time:
- Early on: reward finding the right area (good bounding box).
- Next: reward covering most of the object (few missing parts).
- Finally: reward crisp, accurate edges and thin details.
Cleaning the test data To fairly measure edge quality, the authors noticed that some public test masks have rough, polygon-based outlines that aren’t very precise. They created “RefCOCO‑M,” a cleaned-up validation set with sharper, boundary-accurate masks so that improvements at the pixel level really show up.
What the paper found (the main results)
Here are the highlights:
- On the popular RefCOCO dataset (which tests “find the object from a text description”), their system gets a cIoU of about 80.2% on the validation split. cIoU is a way of measuring how much the predicted cut‑out overlaps the correct one across all examples.
- On the LVIS dataset (tests many object categories), they reach 62.6% mIoU, matching one of the best promptable segmenters.
- On their cleaned RefCOCO‑M split, they score 87.6% cIoU and 85.4% boundary [email protected], showing very sharp edges and good fine detail.
- Compared to other systems, Moondream Segmentation usually makes cleaner masks with sharper boundaries and fewer “salt-and-pepper” specks.
Why this matters:
- Many apps need pixel-perfect cut‑outs: photo editing, graphic design, and building training data for other AIs.
- Sharper edges and better thin-structure recovery mean results look more professional and less “blobby.”
Why these results are important
- Turning everyday text (“the blue backpack near the door”) into crisp, precise cut‑outs makes image editing and search much easier.
- The two‑step design (vector path + refiner) combines the best of both worlds: compact, understandable shapes plus careful pixel-level polishing.
- Rewarding the final mask quality (instead of exact drawing steps) makes training more stable and more aligned with what users actually care about: how good the cut‑out looks.
Limitations and what’s next
- Very thin or disconnected shapes can still be hard for the vector-path approach.
- If you want multiple instances at once (e.g., “all the dogs”), today it usually runs multiple passes, one per object.
- Future work includes better handling of multiple objects in one go and extending the method to videos, so it can track and segment objects over time.
Takeaway
Moondream Segmentation shows a practical and effective way to go from words to high-quality cut‑outs: sketch a vector outline, then refine it. With smarter training that rewards the final shape and a cleaned evaluation set for fair testing, it delivers sharp, accurate masks that are useful for real creative and technical tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what is missing, uncertain, or left unexplored in the paper, framed as concrete, actionable items for future work:
- Quantify the RL stage’s contribution: provide ablations comparing SFT-only vs RL (GRPO), and per-reward-regime variants (box IoU vs Tversky vs boundary IoU) on cIoU/BIoU, valid-path rate, and stability.
- Sensitivity of the piecewise reward: study the effect of τ_box, τ_mask, α/β (Tversky), and ε (boundary band width) on convergence and final boundary quality.
- RL training details and reproducibility: disclose GRPO hyperparameters (group size, baseline strategy, KL/entropy terms, clip ratios), rollout counts, learning rates, and compute budget; release code/specs for exact reproducibility.
- Sample efficiency and failure modes in RL: analyze reward variance, invalid-path frequency pre/post RL, and convergence pathologies (e.g., mode collapse, over-coverage due to Tversky bias).
- Vector-path representation limits: clarify how the approach handles multiple disjoint components, holes, self-intersections, and extremely thin structures; specify the fill rule (even–odd vs non-zero winding) used in rasterization and assess its impact.
- Maximum path length and grammar constraints: report L_max, typical command counts, and failure modes when shapes exceed limits; explore adaptive or hierarchical path representations to cover complex topologies without truncation.
- Numeric parameterization of path coordinates: evaluate whether emitting numeric coordinates as text tokens harms precision/length; compare to specialized numeric heads or discretized coordinate vocabularies for stability and efficiency.
- Rasterization choices and differentiability: assess alternatives to non-differentiable rasterization (e.g., soft rasterizers) to reduce the need for RL or to enable gradient-based alignment objectives.
- Fixed refiner resolution: quantify the impact of using a fixed 378×378 refiner resolution on high-resolution images (e.g., 2–8K); evaluate multi-scale refinement or dynamic resolution policies for boundary fidelity on large images.
- Use of only global-crop features in the refiner: ablate adding pooled local-crop features (available in Moondream 3) to the refiner and measure the boundary and thin-structure gains.
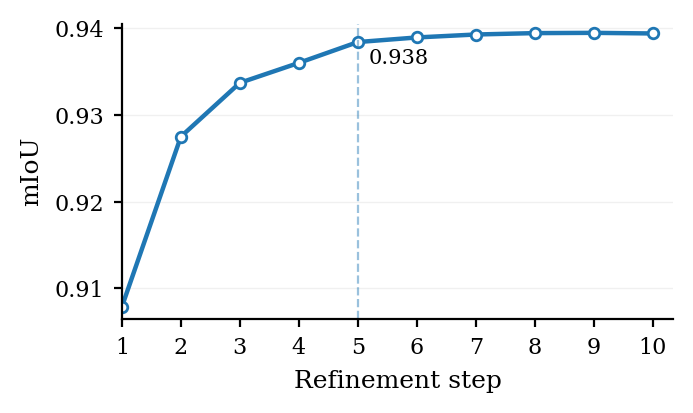
- Iteration count and early stopping: report latency vs quality for different T and investigate confidence-based or quality-head–driven early stopping to reduce computation on easy cases.
- Runtime and memory footprint: provide an end-to-end latency/memory breakdown (path decoding, rasterization, each refinement step) on standard hardware to contextualize practicality vs baselines.
- Number of mask hypotheses K: specify K and study the trade-off between K, accuracy, and compute; analyze quality-head ranking accuracy and calibration across hypotheses.
- Quality-head calibration and abstention: evaluate calibration of q (e.g., ECE, correlation with IoU), ability to reliably rank masks across iterations, and thresholds for abstaining or requesting user input.
- Multi-instance segmentation in one pass: extend and evaluate a design that outputs multiple instances for prompts like “all cars,” including grouping, non-overlap constraints, and selection mechanisms.
- Language grounding under complex expressions: benchmark performance by expression attributes (length, compositionality, spatial relations, negation, coreference) and across languages; analyze failures on genuinely ambiguous expressions.
- Generalization beyond RefCOCO-family and LVIS: test on additional referring and open-vocabulary segmentation datasets (e.g., PhraseCut, PhraseRefer, Ref-YTVOS, ADE-Ref) and in-the-wild photos to assess robustness.
- LVIS evaluation protocol: compare the mIoU+Hungarian setup to standard AP-style LVIS metrics and report both to ensure comparability with prior instance-segmentation work.
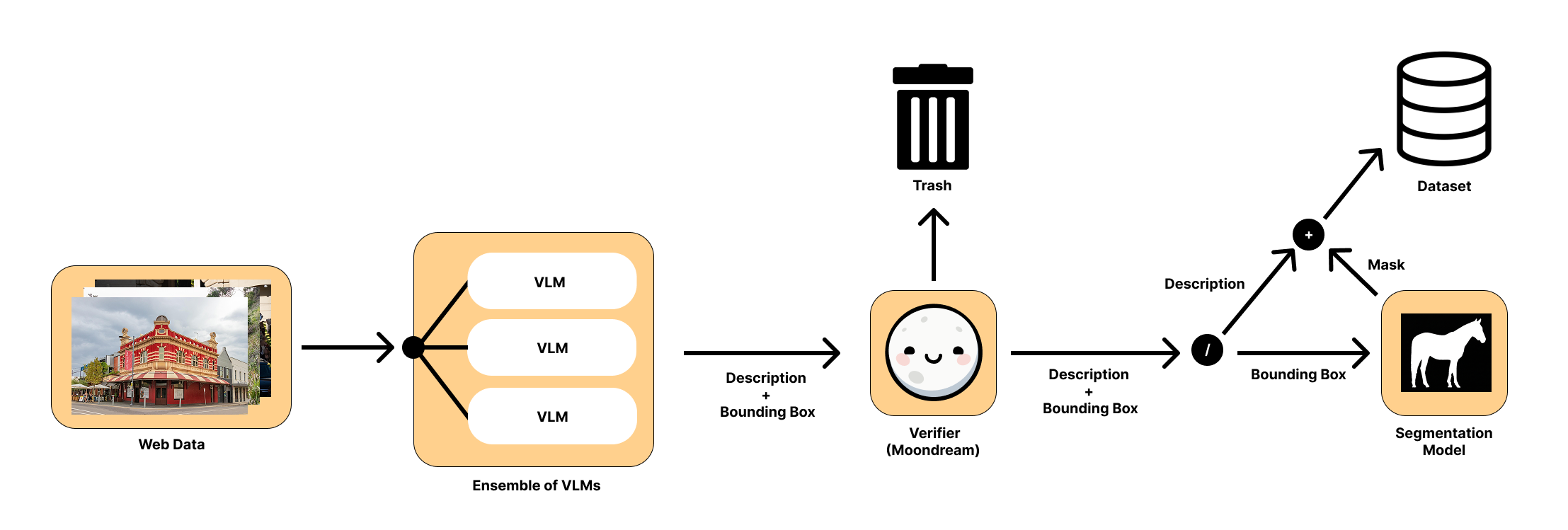
- Data pipeline bias and provenance: identify which segmenter produced masks for training, quantify inherited biases/artifacts, and test whether the model surpasses or mimics teacher failure modes (e.g., boundaries, thin parts).
- Release and audit of the 10M-sample dataset: clarify licensing, categories, demographics, and diversity; release subsets or statistics to enable reproducibility and bias analysis.
- RefCOCO-M construction and bias: quantify annotation improvements with human QA or inter-annotator agreement, analyze category/size distribution shifts after removing 47% of instances, and release guidelines for replicating the cleaning.
- Fairness and safety analyses: measure segmentation quality across demographic attributes (e.g., skin tone, age, gender presentation) and categories, and assess susceptibility to harmful prompt content beyond the small filtered set.
- Robustness to occlusion, transparency, and adverse conditions: create targeted stress tests (e.g., heavy occlusion, reflections, motion blur, tiny/thin objects) to characterize boundary and coverage failures.
- Failure taxonomy and diagnostics: separate grounding vs boundary errors with a structured analysis (e.g., using ground-truth boxes to isolate boundary recovery) and provide an error taxonomy with frequencies.
- Alternatives to RL for supervision ambiguity: compare RL to alignment strategies such as minimum-of-N supervision, token-set losses, or matching to multiple valid tokenizations, and to differentiable rasterization losses.
- Training-through-iterations vs stop-grad: test backpropagation through refinement iterations (truncated BPTT) or DAgger-style on-policy relabeling to reduce train–test mismatch.
- Path-only vs box+path dependency: ablate dependence on the RegionModel’s box; measure robustness when the predicted box is misaligned and whether improved boxes or box-free path decoding helps.
- Video and temporal consistency (future-work pointer): design and evaluate temporal path decoding/refinement with consistency losses or rewards; analyze drift and flicker across frames.
- Open-sourcing completeness: appendices referenced (SVG grammar, RegionModel equations, inference pseudocode) are essential for replication—release full specs, code, and trained weights where possible.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s capabilities of Moondream Segmentation (vector-path decoding + iterative mask refiner) and the released RefCOCO‑M evaluation set.
- Bold, text-driven selection in creative tools [Software/Creative, Advertising/E‑commerce]
- Enable “mask by text” features in photo/video editors (e.g., “select the car on the left,” “isolate the model’s jacket”) with sharper, cleaner boundaries than typical VLM masks. Integrations: plugins for Photoshop, Figma, Blender; web editors; mobile photo apps.
- Workflow: user enters a referring expression → model decodes a vector path → rasterize + 5-step refinement → editable mask layer.
- Dependencies/assumptions: access to Moondream Segmentation weights or API; GPU inference for iterative refinement; prompt quality; license compliance; latency budget for T=5 iterations.
- Background removal and product cutouts with natural language [E‑commerce, Advertising]
- Automate precise product cutouts and variant imagery (e.g., “only the shoe outsole,” “the watch face without the strap”) without manual polygon tools.
- Tools: batch “text-to-cutout” service; storefront listing generator; DAM (digital asset management) plugins.
- Dependencies: varied catalog domains may require domain adaptation; careful prompt engineering; throughput scaling for large catalogs.
- Precision redaction and privacy filtering [Public Sector, Media, Legal/Compliance]
- Robustly mask PII with natural language prompts (e.g., “mask all license plates,” “mask children’s faces except the speaker”), benefiting from high boundary fidelity to minimize leakage.
- Tools: redaction pipelines for bodycam footage and images; newsroom content moderation tools.
- Dependencies: false negatives carry risk; need human-in-the-loop QA; policy-compliant logging; demographic performance audits.
- Mask refinement as a drop-in post-process [Software/CV Infrastructure]
- Use the refiner as a general mask “de-speckler” and edge sharpener for outputs from SAM-family models or detector-based pipelines.
- Workflow: feed in existing coarse masks (e.g., from detectors, weak labels) → Moondream refiner improves edges and thin structures.
- Dependencies: Moondream vision features are assumed in the paper; pairing with other encoders may need light finetuning; compute overhead per refinement step.
- Class-agnostic instance segmentation via text prompts [Research, CV Platforms]
- Segment LVIS-style categories by name without class-specific training (“segment all ‘ladles’ in this image”), useful for long-tail categories and zero-/few-shot benchmarking.
- Tools: analytics dashboards for object presence and region statistics in image repositories; QA of manufacturing imagery (“find ‘missing bolt’ areas”).
- Dependencies: open-set text grounding accuracy; curated synonym lists; prompt templates; performance varies by category rarity.
- Assisted dataset annotation and QA [Academia/Industry ML, Labeling Ops]
- Speed up polygon/mask labeling: annotator writes/refines an expression, gets a high-fidelity mask, then approves/edits; leverage the model’s vector path for compact edits.
- Tools: labeling co‑pilot in CVAT/Label Studio; auto-correction pass for boundary defects; active-learning triage using the quality head.
- Dependencies: annotation policy alignment; UI for path edits; versioning and audit trails.
- Boundary-focused evaluation and benchmarking with RefCOCO‑M [Academia, MLOps]
- Adopt RefCOCO‑M to reduce evaluation noise for boundary-heavy tasks and to track [email protected] alongside cIoU.
- Tools: CI metrics for segmentation repos; regression tests for boundary quality; leaderboard-style internal benchmarks.
- Dependencies: dataset license and redistribution policies; ensure task definitions match (RIS vs. generic segmentation).
- Content understanding and search with region analytics [Media, Enterprise Search]
- Queries like “count people wearing helmets,” “find the cracked screen region” with per-region statistics for compliance and analysis.
- Tools: enterprise image search with “segment-by-query” overlays; safety/compliance dashboards.
- Dependencies: scalable indexing; consistent taxonomy; grounding quality for nuanced queries.
- Accessibility overlays and assistive guidance [Accessibility/Consumer Apps]
- Real-time highlighting of referred objects (“highlight the exit sign,” “outline the curb”) to aid low-vision users.
- Tools: on-device or edge-assisted mobile apps; haptic/audio feedback tied to the predicted mask.
- Dependencies: latency constraints; on-device acceleration; careful HCI design; safety disclaimers.
- Teaching and demos of vision-language grounding [Education/Outreach]
- Interactive classroom labs demonstrating referring expressions → region masks, showcasing ambiguity and RL alignment.
- Tools: browser demos; Jupyter notebooks; course modules on RL for structured outputs.
- Dependencies: simplified runtime; visualizers for vector paths and refinement steps.
Long-Term Applications
These use cases are promising but depend on further research, domain adaptation, or scaling beyond the paper’s current scope.
- Video rotoscoping and temporal segmentation by language [Media/Film, AR/VR]
- “Track and mask the lead actor’s jacket across the scene” with temporally consistent masks driven by text.
- Required advances: extend Moondream Segmentation to video tokens and temporal consistency; handle occlusions and long sequences; efficient caching across frames.
- Dependencies/assumptions: larger models or memory modules; streaming inference; dataset curation for video RIS.
- Multi-instance, disjoint-region segmentation in one pass [Software/CV, Robotics]
- Handle “all the trees on the left” without multiple passes, improving speed for multi-object scenes and set-level operations.
- Required advances: multi-mask decoding heads or set prediction during path generation; better handling of thin/disconnected structures (a current limitation).
- Dependencies: new training objectives and architectures; dataset supervision for multi-instance RIS.
- Embodied instruction following and robotic manipulation [Robotics/Logistics]
- “Pick up the red mug near the sink” with precise, grasp-ready masks that improve grasp point selection and collision avoidance.
- Required advances: real-time perception, depth fusion, robust thin-structure handling (handles, wires), closed-loop control integration.
- Dependencies: low-latency deployment on edge accelerators; calibration with robot cameras; safety validation.
- Clinical and scientific imaging segmentation from textual prompts [Healthcare, Scientific R&D]
- “Outline the left ventricle,” “segment the tumor margin” in MR/CT or microscopy with high boundary fidelity.
- Required advances: domain pretraining on medical/scientific modalities; 3D/volumetric extensions; uncertainty quantification; FDA/CE regulatory pathways.
- Dependencies: HIPAA/GDPR compliance; expert supervision; rigorous validation on domain data.
- Aerial/remote sensing analysis by natural language [Energy/Utilities, GIS]
- “Segment all solar panels,” “isolate corroded pipeline sections,” “flooded areas” from aerial or satellite images.
- Required advances: adaptation to overhead imagery scale and textures; multi-resolution tiling; handling small/disconnected regions.
- Dependencies: labeled domain datasets; geospatial alignment; operational throughput for large scenes.
- On-device AR assistants and wearables [Consumer/Industrial AR]
- Hands-free, text/voice-driven segmentation (“highlight the valve labeled V‑12”) rendered in see-through displays for maintenance and training.
- Required advances: compression/distillation of Moondream 3 + refiner; streaming partial refinement; fast wake word → mask pipelines.
- Dependencies: specialized hardware (NPUs/GPUs on devices); robust speech-to-text grounding; battery and heat constraints.
- Policy and standards for boundary-accurate evaluation [Policy/Government, Standards Bodies]
- Incorporate boundary metrics (e.g., BIoU) and dataset cleaning practices (RefCOCO‑M-style) into procurement and regulatory guidelines for CV systems used in public services.
- Required advances: consensus on metrics and thresholds; repeatable curation pipelines; auditing frameworks for boundary quality and fairness.
- Dependencies: multi-stakeholder working groups; public reference suites; documentation of annotation provenance.
- CAD/CAM and manufacturing inspection with vector intermediates [Manufacturing]
- Leverage the vector-path representation to align masks with CAD geometry (“segment the fillet around bolt holes”), facilitating downstream parametric edits.
- Required advances: mappings between predicted paths and CAD primitives; sub-pixel contour accuracy; integration with metrology.
- Dependencies: domain-specific datasets; tightly controlled imaging; tolerance-aware evaluation.
- Generalized RL-for-structured-outputs training recipe [Academia/ML Platforms]
- Apply the piecewise reward curriculum (box IoU → Tversky → boundary IoU) to other ambiguous sequence-to-structure tasks (e.g., polygonized annotations, vectorized maps, layout extraction).
- Required advances: task-specific rasterizers/validators; stable GRPO/PPO variants for larger models; scalable rollout infrastructure.
- Dependencies: compute for RL fine-tuning; unbiased reward estimators; reproducibility frameworks.
- Safety-critical perception (ADAS/Autonomy) [Automotive/Robotics]
- Text-configurable segmentation for rare or emergent hazards (“highlight debris on road shoulder”), aiding fallback operators or interactive debugging.
- Required advances: real-time guarantees; extensive validation and safety cases; robust out-of-distribution handling.
- Dependencies: integration with sensor fusion stacks; rigorous monitoring; regulatory acceptance.
Notes on feasibility across applications
- Model access: Availability and licensing of Moondream 3 and segmentation weights determine near-term deployability.
- Latency/throughput: Iterative refinement (T≈5) improves quality but adds latency; batching and distillation may be needed for production.
- Domain shift: High fidelity on natural images may not transfer without adaptation to specialized domains (medical, aerial, industrial).
- Ethical use: Strong potential for misuse in non-consensual manipulation; deployments should include consent checks, watermarking, and audit logs.
- Current limitations: Challenges with disjoint regions and ultra-thin structures; multi-instance requires multiple passes; video not yet supported.
Glossary
- Additive fusion: Combining two feature maps by element-wise addition to inject prompt information into vision features. "We prompt the refiner by additive fusion:"
- Arity: The number of arguments a command or function takes; here, path commands require a specific number of parameters. "Some rollouts may be invalid paths (e.g., wrong arity for a C command)."
- Autoregressive decoding: Generating a sequence one token at a time, each conditioned on previously generated tokens. "we autoregressively decode a vector path in an SVG-style syntax"
- BCE (Binary cross-entropy): A loss function for binary classification comparing predicted probabilities to binary labels. "SegLoss combines binary cross-entropy (BCE) with a Dice loss term"
- Binned spatial values: Discretized coordinate/size values represented via a tokenizer with finite bins. "a region-tokenizer interface for binned spatial values (used for points and boxes)."
- [email protected]: Boundary IoU measured using a boundary band of width 5% of the image diagonal. "the final RefCOCO-M column reports [email protected]."
- Boundary band operator: An operator that retains only pixels within a mask close to its boundary. "we define a boundary band operator that keeps only pixels inside a mask and within distance ε of that mask's boundary."
- Boundary fidelity: The accuracy and sharpness of predicted mask edges relative to true object boundaries. "Boundary fidelity."
- Boundary IoU: IoU computed on boundary bands of masks to emphasize edge alignment. "We then define boundary IoU as the IoU between the boundary bands of the prediction and target:"
- Boundary-loss schedule: A training schedule that gradually increases weight on boundary-focused loss. "We use a boundary-loss schedule λ∂(s) that is 0 early in training"
- Boundary-weighted BCE: A BCE loss variant that gives higher weight to boundary pixels. "BoundaryLoss is a boundary-weighted BCE term"
- cIoU: Cumulative IoU aggregated over a dataset by summing intersections and unions across samples. "Moondream Segmentation achieves a cIoU of 80.2% on RefCOCO (val)"
- Cross-attention: Attention where one token set attends to another, enabling information exchange between modalities or roles. "alternates self-attention on Z, cross-attention Z→X, an MLP on Z, and cross-attention X→Z"
- Decoding constraints: Rules imposed during sequence generation to ensure syntactic validity and stable geometry. "We constrain decoding to ensure syntactic validity and stable geometry."
- Dice loss: A differentiable loss based on the Dice coefficient, balancing overlap for segmentation. "SegLoss combines binary cross-entropy (BCE) with a Dice loss term"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that compares rollouts within a group to guide updates. "We optimize this objective using Group Relative Policy Optimization (GRPO)"
- High-quality feature fusion: Combining multi-level vision features to improve detail and boundary quality. "following the high-quality feature fusion design as seen in HQ-SAM"
- HQ-SAM: A variant of SAM focused on higher-quality segmentation outputs and boundary detail. "following the high-quality feature fusion design as seen in HQ-SAM"
- Hungarian matching: An algorithm for optimal assignment used to pair predicted and ground-truth masks. "Predicted and ground-truth masks are paired via Hungarian matching on IoU"
- Hypernetwork: A network that generates parameters (e.g., channel weights) for another network component. "A small per-mask MLP (hypernetwork) maps s_m to channel weights"
- Intersection-over-union (IoU): The ratio of intersection to union between predicted and ground-truth masks. "We evaluate using intersection-over-union:"
- Iterative refinement: Repeatedly updating a prediction by feeding back the model’s output as input. "Refinement is applied for T=5 iterations at both training and inference."
- Mask hypotheses: Multiple candidate mask outputs produced simultaneously, from which the best is selected. "multiple mask hypotheses and a learned mask-quality predictor"
- Mask logits: Pre-sigmoid scores per pixel indicating confidence for the foreground class. "The refiner outputs K mask logits Lt"
- Mask token: A learned token that, via a hypernetwork, decodes into a segmentation mask. "We reuse this mask-token and quality-head pattern in our refiner"
- Mixture-of-Experts (MoE): A sparse model architecture with many expert sub-networks and a router that selects a subset per input. "a 2B active / 9B total parameter mixture-of-experts (MoE) vision-LLM"
- mIoU: Mean IoU, averaged over instances or categories to summarize segmentation performance. "and 62.6% mIoU on LVIS (val)."
- Overlap-aware reconstruction: A method to stitch overlapping local crops into a coherent feature grid. "Local token grids are stitched with overlap-aware reconstruction"
- Patch tokens: Tokens produced by a vision transformer by embedding fixed-size image patches. "converts an image into a fixed-length set of patch tokens"
- Piecewise reward: An RL reward that switches metrics based on competence stages to stabilize learning. "We use a piecewise reward that changes with model competence"
- Promptable segmentation: A segmentation interface that responds to user prompts (e.g., points, boxes, text). "Segment Anything (SAM) introduced a promptable segmentation interface"
- Quality head: A prediction head that estimates the quality (e.g., IoU) of each mask hypothesis for selection. "mask token + quality head pattern"
- Quality token: A learned token whose embedding is mapped to per-mask quality scores. "consisting of K mask tokens and one quality token."
- Rasterization: Converting vector graphics or paths into a pixel-based mask. "we rasterize the vector path into a coarse mask"
- Referring image segmentation (RIS): Segmenting a region specified by a natural-language expression. "Referring image segmentation (RIS)~\citep{hu2016segmentation} takes an image and a referring expression"
- RegionModel: A specialized module that decodes discretized spatial tokens (coordinates/sizes) into real values. "the RegionModel, a region-tokenizer interface for binned spatial values (used for points and boxes)."
- Rollouts: Samples generated by a policy during RL, used to compute rewards and train the model. "Rollouts from this stage produce intermediate coarse masks"
- Salt-and-pepper artifacts: Small isolated false positives/negatives resembling speckled noise in segmentation outputs. "a failure mode commonly described as 'salt-and-pepper' artifacts"
- Semantic grounding: Linking language expressions to the correct visual instance in an image. "semantic grounding (identifying which instance the expression refers to)"
- SoftIoU: A differentiable approximation of IoU used as a regression target for quality prediction. "ĥqt=SoftIoU(σ(Lt),M) is a differentiable soft-IoU target"
- Stop-gradient: An operation preventing gradients from flowing through certain tensors during training. "we apply a stop-gradient operator to the updated mask between iterations"
- SVG-style syntax: A command-based representation for vector paths (e.g., M, L, C, Z) akin to SVG paths. "a vector path in an SVG-style syntax"
- Teacher forcing: Training strategy where the ground-truth next token is fed during sequence modeling. "We train with teacher forcing"
- Top-8 routing: An MoE routing strategy that activates the eight most relevant experts per token. "feed-forward blocks are MoE with 64 experts and top-8 routing."
- Two-way transformer: A block that alternates attention updates between output tokens and image tokens in both directions. "A two-way transformer alternates self-attention on Z, cross-attention Z→X, an MLP on Z, and cross-attention X→Z"
- Tversky index: A generalized overlap metric weighting false positives and negatives differently. "The Tversky index is"
- Upsampling stages: Progressive spatial resolution increases in decoder features, often by factors of 2. "three 2× upsampling stages"
- Vector path: A sequence of drawing commands and control points representing a shape compactly. "the model autoregressively decodes a vector path"
- Vision-LLM (VLM): A model jointly processing images and text to perform multimodal tasks. "a vision-LLM"
- Vision Transformer (ViT): A transformer architecture applied to image patches for visual encoding. "pairs a Vision Transformer (ViT) vision encoder"
Collections
Sign up for free to add this paper to one or more collections.