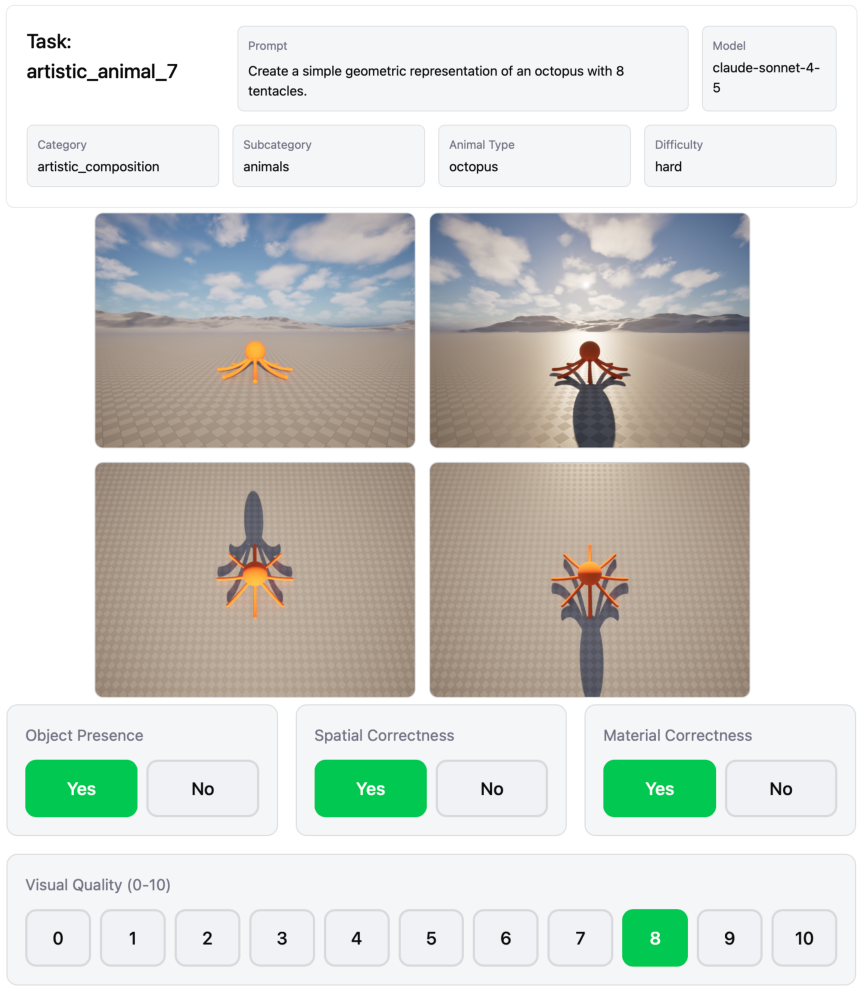
- The paper introduces VoxelCodeBench, a benchmark that evaluates LLMs' ability to generate spatially accurate 3D scenes via code generation.
- It employs a controlled code-generation framework using Python API calls in an Unreal Engine environment to assess symbolic, geometric, and artistic tasks.
- Results reveal significant performance stratifications among models and highlight challenges in compositional geometric reasoning and API adherence.
VoxelCodeBench: A Comprehensive Benchmark for 3D Spatial Reasoning via Code Generation
Introduction
VoxelCodeBench proposes a novel framework for empirical assessment of 3D spatial reasoning in LLMs by bridging code generation and procedural 3D object creation. Building upon VoxelCode—an Unreal Engine-based voxel manipulation environment—the benchmark systematically evaluates LLMs’ ability to translate natural language prompts and API documentation into Python code that, when executed, produces spatially accurate, semantically consistent, and visually coherent 3D scenes. The approach stands in contrast to monolithic, end-to-end neural models typical of text-to-3D (“black-box”) pipelines, enabling fine-grained scrutiny of model internal reasoning and generalization to complex, multi-step spatial tasks. The released infrastructure (benchmark tasks, renderer, evaluation tools) standardizes progress measurement and aids the community in furthering LLM spatial reasoning research.
VoxelCode leverages Unreal Engine and the Voxel Plugin 2.0 to realize a closed-box execution environment that accepts Python-based API calls for primitive voxel manipulation. Notably, LLMs are only provided with header-level function prototypes and a controlled number of minimal working example scripts, ensuring that task success reflects generalization and true API comprehension rather than rote memorization from model pretraining.
VoxelCodeBench consists of 220 diverse tasks, partitioned along three principal axes:
- Symbolic Reasoning: Tests low-level API use, coordinate mapping, pattern reconstruction, and text/symbol rendering. Tasks specify exact placements and geometric parameters.
- Geometric Construction: Targets procedural composition involving Boolean operations, iterative structure synthesis, and advanced parametric primitives (e.g., spirals, helixes, Hermite curves).
- Artistic Composition: Assesses creative world modeling—multi-object scenes, thematic builds, organic/natural forms, and abstract arrangements—requiring both geometric manipulation and implicit world knowledge.
Task specifications are issued as natural language instructions, ranging from rigid geometric descriptions to highly open-ended creative prompts. This diversity enables controlled study of code-based spatial understanding across the complexity spectrum.

Figure 2: Representative 3D outputs from VoxelCode, illustrating the breadth from simple primitives through complex, multi-part compositions.
Evaluation Protocol
A hybrid evaluation protocol captures both strict programmatic and subjective dimensions of model performance:
This methodology enables decomposition of failure modes: distinguishing models that produce valid code but spatially incorrect structures from those that simply fail to execute.
Experimental Results
The benchmark rigorously evaluates state-of-the-art LLMs: GPT-5, GPT-5 Mini, GPT-5 Chat, Claude Sonnet 4.5, Claude Opus 4, Claude 3.5 Sonnet, Claude 3 Opus, and Gemini 3 Pro. Each model receives identical API documentation, working examples, and natural language task specifications.
Results show a clear performance stratification:
- GPT-5 achieves top overall performance (87.9% shape correctness, 5.71 visual quality), exhibiting robustness to prompt complexity and stable behavior across symbolic, geometric, and creative tasks.
- Claude Sonnet 4.5 excels at symbolic tasks requiring parameter adherence (90.3%), but drops significantly on geometric composition (52.8%), revealing divergent internal encoding of spatial concepts.
- Gemini 3 Pro fails to generalize basic API usage (19.5% shape correctness), indicating brittle handling of new domain-specific environments.
Cross-task analysis highlights geometric construction as the most challenging: performance consistently drops versus symbolic or artistic tasks across all models. High visual quality scores in creative/artistic categories for leading models suggest that interpretive flexibility mitigates some geometric limitations.
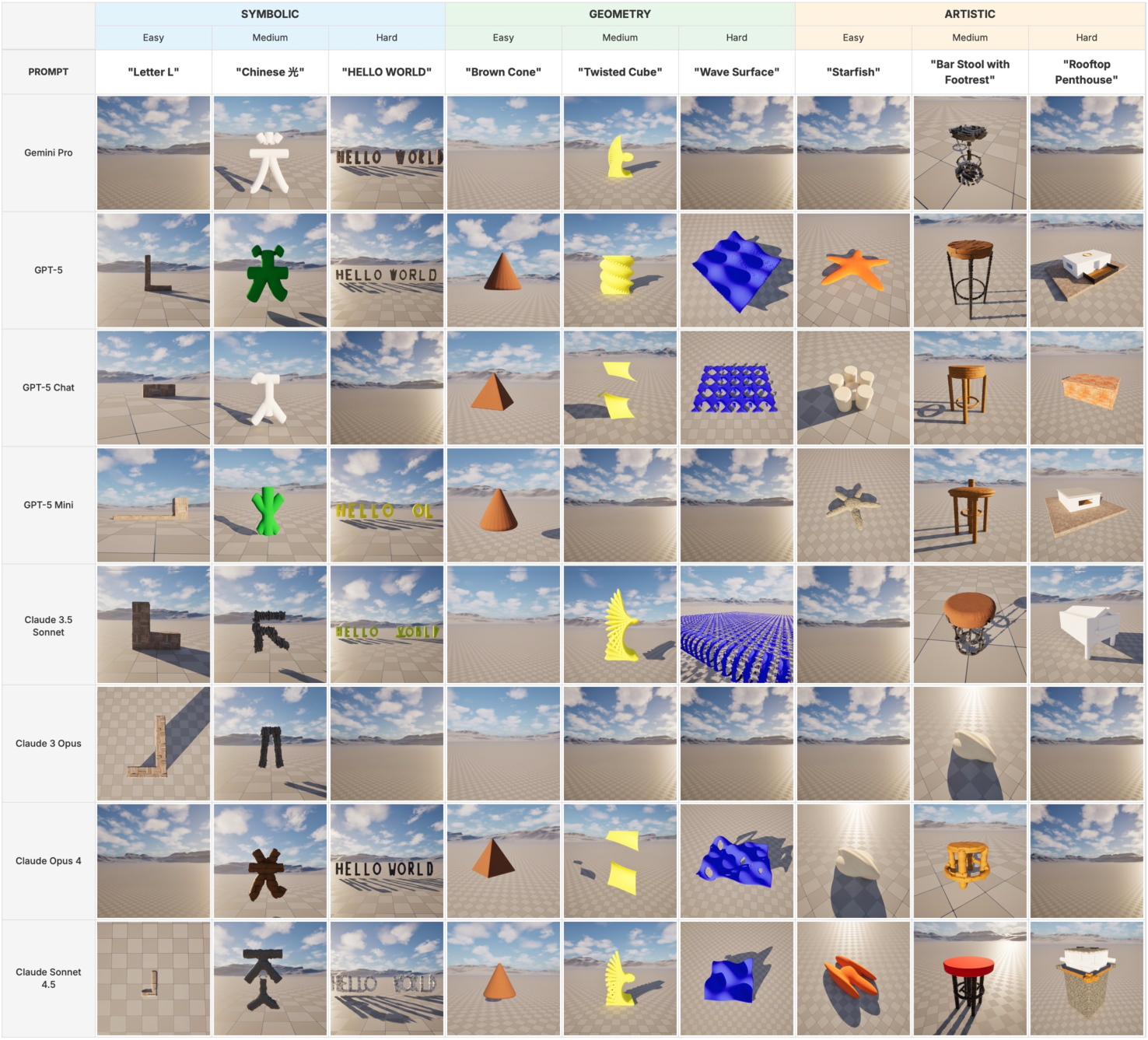
Figure 3: Qualitative comparison: Model generations (rows) for symbolic, geometric, and artistic tasks (columns), organized by difficulty; empty cells indicate code failure or non-conformance.
Error and Ablation Analyses
Ablation studies expose critical characteristics of LLM code generation in API-driven domains:
- Context Sensitivity: Increasing the number of working examples aids low-performing models (e.g., Gemini Pro: +24.8pp) but degrades shape correctness for high-performing models (e.g., Claude 3.5 Sonnet: -34.8pp), likely due to context over-extension or distracting in-context noise. This effect reflects notable idiosyncrasies in in-context learning for code generation (2604.02580).
- Error Profiling: The majority of failures arise from invalid API attribute referencing and parameter errors—model hallucinations of plausible but non-existent functions. Execution timeouts (particularly for Claude Sonnet 4.5) reveal incomplete understanding of computational feasibility, further separating correct code synthesis from geometric reasoning as independent challenges.
Geometric and Structural Analysis
The code-based approach enables the generation of 3D objects with consistent interior (not just surface) structure—an advantage over diffusion-based or mesh-generation neural models, which typically lack semantic or topological continuity beneath the rendered surface. Fine-grained details (such as ladders within silos, internal yacht cabins, or articulated structural layers) are readily specified through explicit composition of primitives and Boolean algebra.

Figure 4: Code-based shape generation yields consistent, detailed internal geometries, a challenge for purely neural, surface-oriented 3D methods.
Qualitative evaluation exposes that geometric vocabulary understanding (e.g., distinguishing between “frustum,” “prism,” “capsule”) is highly non-uniform across models, with symbolic variants outperforming on parameterized API invocation but struggling with more composite or abstract spatial instructions.
Implications and Future Directions
The results illuminate both the promise and limitations of LLMs in procedural 3D world modeling:
- Interpretability: Code as an intermediate representation offers a transparent window into model spatial reasoning, facilitating directed debugging, runtime constraint injection, and user intervention.
- Robustness Gaps: Consistent handling of Boolean composition and geometric property adherence remains hard for even top-performing models. Failure to robustly parse new API documentation leads to brittle performance divergences.
- Downstream Applications: These findings are directly relevant to embodied AI, robotics, CAD/content authoring, and educational visualization—domains where spatial code generation is a core enabler.
Several research trajectories arise:
- API Adaptation: Investigating model adaptation to previously unseen procedural APIs, including few-shot or chain-of-thought prompt engineering to foster grounding.
- Curriculum and Meta-Learning: Structured task organization and incremental complexity exposure (e.g., curriculum learning protocols) may yield more universally robust spatial reasoning.
- Hybrid Paradigms: Combining interpretable code synthesis with implicit neural rendering (or neural-symbolic integration) could address current limitations in fine-grained control and high-fidelity output.
- Generalization to Novel Environments: Future benchmarks should target cross-domain transfer to new engines, function sets, or spatial ontologies, further probing the limits of model understanding and generalization.
Conclusion
VoxelCodeBench advances the empirical study of 3D spatial reasoning in LLMs by introducing an open, executable, code-driven evaluation pipeline. The transparent separation between language, code, and rendered geometry allows for precise attribution of model failure and success. While current models demonstrate significant capability—especially in creative and basic symbolic manipulation—gaps in compositional geometric reasoning and API adherence persist, signaling open challenges for robust, generalizable spatial intelligence. The platform and methodology set a foundation for both improving LLM code-generation architectures and for controlled study of high-level geometric reasoning as a component of embodied and generative AI (2604.02580).