V-GameGym: Visual Game Generation for Code Large Language Models
Abstract: Code LLMs have demonstrated remarkable capabilities in programming tasks, yet current benchmarks primarily focus on single modality rather than visual game development. Most existing code-related benchmarks evaluate syntax correctness and execution accuracy, overlooking critical game-specific metrics such as playability, visual aesthetics, and user engagement that are essential for real-world deployment. To address the gap between current LLM capabilities in algorithmic problem-solving and competitive programming versus the comprehensive requirements of practical game development, we present V-GameGym, a comprehensive benchmark comprising 2,219 high-quality samples across 100 thematic clusters derived from real-world repositories, adopting a novel clustering-based curation methodology to ensure both diversity and structural completeness. Further, we introduce a multimodal evaluation framework with an automated LLM-driven pipeline for visual code synthesis using complete UI sandbox environments. Our extensive analysis reveals that V-GameGym effectively bridges the gap between code generation accuracy and practical game development workflows, providing quantifiable quality metrics for visual programming and interactive element generation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces V-GameGym, a big test set and scoring system to see how well AI coding models can build simple visual games. Instead of only checking if code runs or has no syntax errors, V-GameGym looks at things that matter in real games, like how the game looks, if it’s playable, and how it feels to use.
What questions did the researchers ask?
The team wanted to answer a few simple questions:
- Can today’s AI coding models make small, visual games that actually work and look good?
- How do we fairly measure game-making ability, not just code correctness?
- Do bigger models really do better at making games, and how much better?
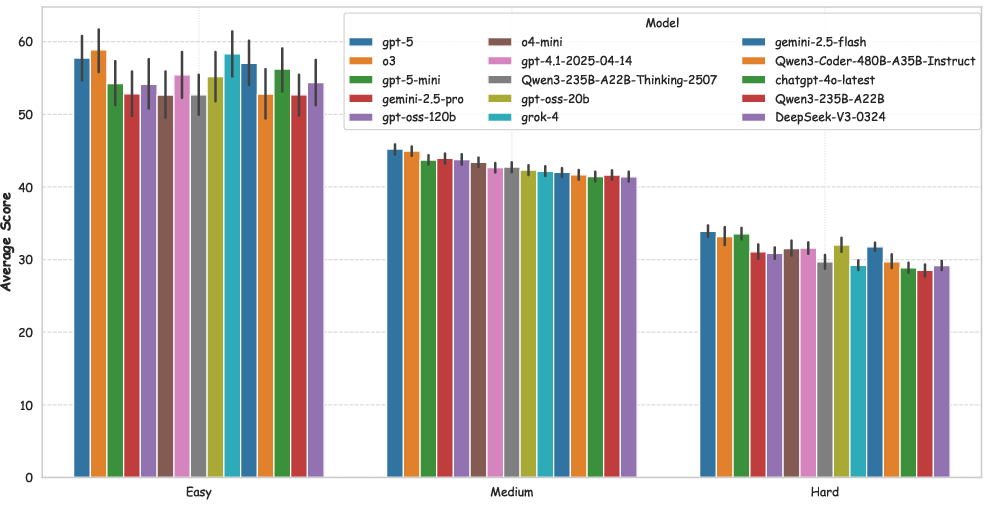
- Which parts of game-making (code, screenshots, videos) are strongest or weakest for different models?
How did they do the research?
Think of V-GameGym like a carefully built “gym” where AI models try to create mini-games, and judges score what they produce from different angles.
Here’s the approach in everyday terms:
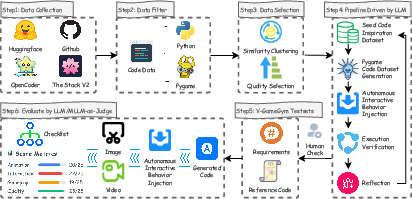
- Finding real games: They searched huge open-source code collections for Python games made with “Pygame,” a popular library for simple 2D games.
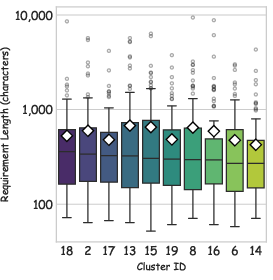
- Grouping similar games: Imagine sorting thousands of songs by their style and instruments. The team grouped game code into 100 clusters based on what the code does and how it’s structured, then picked the best example from each group. This kept the test set diverse and high-quality.
- Making games self-running: Many games wait for player input. The researchers used an AI pipeline to turn each game into a short, self-playing demo that can run in a “sandbox” (a safe test environment) without a human, record video and images, and check for errors. If something broke, the AI tried to fix and re-run it.
- Writing clean instructions: For each game, the AI also wrote a clear “requirement” (like a simple product description) so models could read the goal and try to recreate the game.
- Human verification: Eight graduate students manually checked around 2,219 games to make sure they run and look correct.
- Scoring with multiple judges: They scored three things:
- Code quality (does the program match the instructions?)
- Screenshot quality (do the static visuals look right?)
- Video quality (does the gameplay look correct when running?)
- These scores were combined into a final score and grouped into quality bands: Excellent, Good, Fair, Poor.
Technical terms explained:
- Benchmark: A big, standardized test set used to compare models fairly.
- Clustering: Grouping similar items (here, similar game codes) using patterns in their features.
- Multimodal: Using more than one type of data (text, code, images, videos) to judge performance.
- Sandbox: A safe, controlled environment to run programs without breaking your computer.
- Pygame: A Python tool for building simple 2D games.
- Model parameters: Roughly, how “big” an AI model’s brain is. More parameters usually means more power, but with limits.
What did they find and why does it matter?
Main results and takeaways:
- A rich, reliable test set: V-GameGym includes 2,219 unique, verified mini-games from 2,190 repositories, across 100 clusters. Every game runs and has video/image outputs, which makes evaluation consistent.
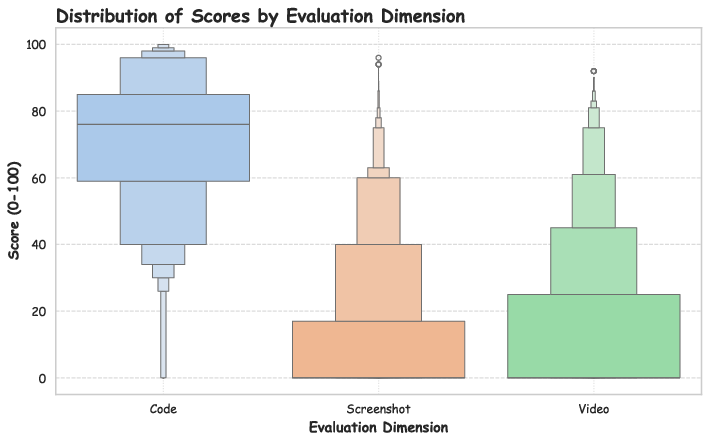
- Strong at code, weak at visuals: Most models score high in code correctness but much lower in image and video quality. This shows current AI is better at writing code than crafting good-looking, smooth, dynamic game experiences.
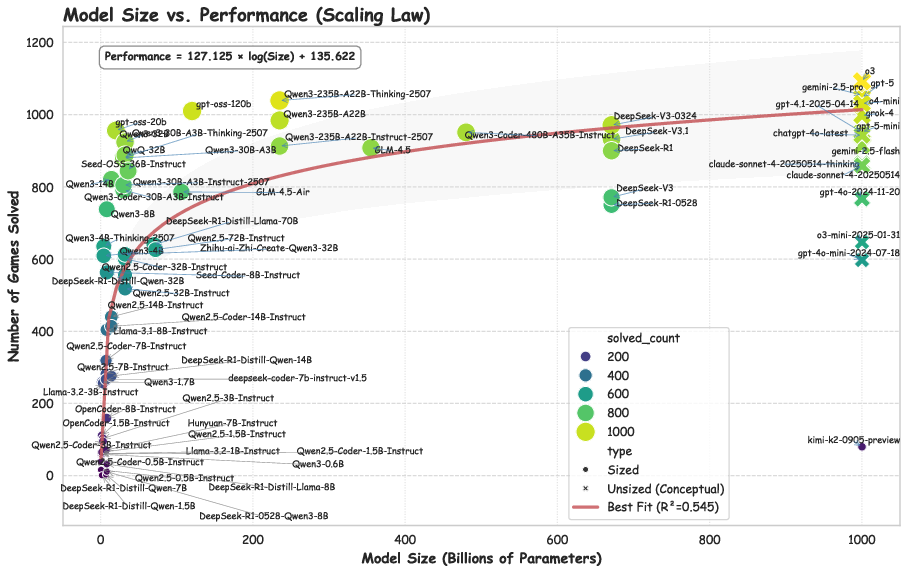
- Bigger helps—but not forever: Larger models generally perform better, but the improvement slows down as size grows. A simple rule they saw was similar to M = A * log(N) + B, meaning performance grows with the logarithm of model size, not linearly.
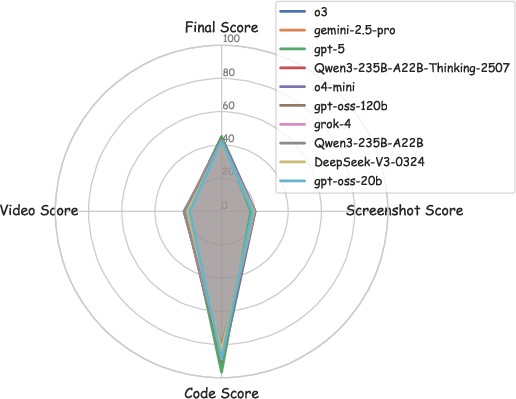
- Proprietary vs. open-source: The top scores were from proprietary models (like GPT-5), but some large open-source models are catching up. Still, even the best model’s final score was around 45/100, showing lots of room to improve.
- Most generated games aren’t great yet: When they bucketed outputs into Excellent, Good, Fair, Poor, most fell into Fair and Poor. Truly polished game generation remains hard.
- Rankings are stable across difficulty: On easy, medium, and hard games, the best models stayed near the top, suggesting the benchmark does a good job of separating stronger and weaker models.
Why this matters:
- It shows that “game generation” is different from solving coding puzzles. To make a decent game, models must combine logic, visuals, and timing—and they’re not good at all of these yet.
- It gives the community a shared way to measure progress that goes beyond “does the code compile?”
What does this mean for the future?
- Better tools and training: AI models need improved visual understanding and dynamic scene generation, not just strong coding skills. Training on more multimodal data (code + art + motion) could help.
- Real-world readiness: If models are to help game developers, they must learn to balance code quality with visual design and smooth gameplay. V-GameGym highlights exactly where models struggle today.
- Fair comparisons: This benchmark gives researchers and companies a common “playing field” to test and improve their models for real game-making, not just algorithms.
In short, V-GameGym shifts AI code evaluation toward what actually matters when building games—how they look, feel, and play—and provides a solid path to make future AI better at creating fun, working games.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and benchmark.
- Scope limitation to Python/Pygame 2D: No coverage of other engines/frameworks (e.g., Unity, Unreal, Godot, Web/HTML5/JS), 3D rendering, physics engines, networking, or mobile/console targets; unclear how findings generalize beyond Pygame.
- No audio dimension: Artifacts exclude sound; audio synthesis, synchronization, and scoring are unaddressed despite being central to many games.
- Interactivity sidelined: Automated “autonomous demonstration” injection removes real input handling; the benchmark does not test responsiveness, control mapping, latency, or robustness to diverse user inputs.
- Short fixed-duration runs: Averages of ~10 seconds may miss core mechanics, multiple game states (menus/levels), win/lose loops, or progression systems; no coverage analysis for temporal completeness.
- Requirements synthesized from code: Specs are reverse-engineered by an LLM from the implementation, risking overfitting to implementation details and not reflecting ambiguous, incomplete, or evolving real-world product requirements.
- No requirement quality validation: There is no human study or rubric on requirement clarity, completeness, or ambiguity; no inter-annotator agreement on requirement correctness.
- Potential dataset contamination: Source code comes from widely used corpora (The Stack v2, OpenCoder), likely included in model training; no near-duplicate detection or data-leakage audit to quantify contamination risks.
- Cluster-to-final dataset inconsistency: The curation formalism selects one sample per cluster, yet the final dataset has 2,219 samples across 100 clusters; the mapping from clusters to final set composition is unclear and needs clarification and auditing.
- Curation heuristics may bias content: The structural-completeness/length-based quality score may systematically favor longer/monolithic files; no ablation on feature extraction, KMeans hyperparameters (k), or selection criteria.
- LLM-generated requirements may introduce bias: Using Claude to write requirements could bias tasks toward that model’s style; the benchmark does not quantify or mitigate generator–evaluator/model coupling effects.
- LLM-as-judge reliability unverified: No human-grounded validation (e.g., correlation with expert ratings), inter-judge agreement, or calibration tests for code/image/video judges; prompts and scoring rubrics are not disclosed for reproducibility.
- Single-judge dependence: Each modality uses a single judge model (Qwen variants); no ensemble judging, adversarial robustness checks, or alternate-judge sensitivity analysis.
- Underspecified scoring weights: The aggregate score uses weights w_k but values, rationale, and sensitivity analyses are missing; rankings may be unstable to weight choices.
- Behavioral correctness under-tested: Code scoring appears LLM-based rather than unit tests/instrumented assertions; there’s no dynamic verification of mechanics (e.g., collision rules, scoring increments), only visual plausibility.
- Handling of execution failures unclear: Task scoring when generations fail to execute is not standardized (e.g., zeroing vs. exclusion); failure categories, root causes, and their impact on rankings are not analyzed.
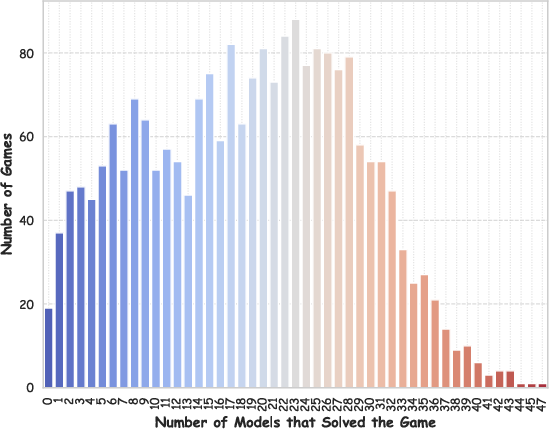
- Difficulty estimation is proxy-based: “Difficulty” = number of models that solved a task conflates difficulty with model similarity and scaling; no human or algorithmic intrinsic difficulty estimation.
- Scaling law validity not established: The proposed M = A·log(N)+B fit lacks uncertainty estimates, per-family fits, confounder controls (context length, prompting, tool-use), or goodness-of-fit metrics; external validity is unknown.
- No multi-turn/agentic evaluation: The benchmark uses single-shot generation with temperature 0; it does not assess planning, iterative self-debugging, tool-use, retrieval, or multi-agent collaboration commonly used in code development.
- No assessment of engineering hygiene: Code quality dimensions (readability, modularity, tests, asset management, performance/FPS, memory usage, safety) are not measured.
- Missing performance instrumentation: There’s no runtime profiling (FPS, CPU/GPU/memory), so claims around performance optimization cannot be evaluated.
- Asset generation and pipeline omissions: Real game pipelines include asset creation (sprites, animations, sound), packaging, and deployment; these are excluded and remain open for evaluation design.
- Generalization beyond curated tasks: No cross-benchmark validation to show that V-GameGym performance correlates with real-world game-dev productivity or downstream user satisfaction.
- Human validation details sparse: The 8-annotator validation lacks task guidelines, time-per-item, inter-annotator agreement, and error taxonomy; reproducibility and consistency are unclear.
- Environment determinism not specified: Random seeds, headless rendering setup (e.g., Xvfb), and OS/package pinning for deterministic artifact capture are not detailed; video variance may affect visual scores.
- Security and sandboxing details missing: The sandbox’s threat model, syscall/network/file access restrictions, and timeout/resource limits are not specified; risks from executing untrusted model code are unaddressed.
- Multilingual coverage absent: Requirements appear English-only; no multilingual tasks or evaluations of cross-lingual instruction following.
- Genre/taxonomy labels lacking: Clusters are unlabeled; there’s no per-genre analysis (e.g., platformer/shooter/puzzle), making targeted capability diagnosis difficult.
- Prompting and decoding transparency: Model prompts, context windows, output token limits, and closed-API decoding parameters are not fully reported; fairness and reproducibility are affected.
- Statistical significance not reported: No confidence intervals, bootstrap analyses, or paired tests to establish that model rank differences are robust.
- Judge bias toward visual style: Image/video scores may reward aesthetics over mechanic correctness; no disentanglement or causal tests to separate “pretty but wrong” from “ugly but correct.”
- Limited coverage of edge-case inputs: Since tasks are auto-played, edge-case handling (e.g., boundary collisions, rare states) is not evaluated; no fuzzing or scripted input diversity is used.
- Dataset licensing and redistribution: License auditing for included repositories and downstream redistribution terms are not discussed.
- Version drift and re-evaluation: Many proprietary models are evolving; procedures for handling model updates, longitudinal comparisons, and benchmark versioning are not described.
- Public release completeness: Availability of code, evaluation scripts, judge prompts, artifacts, and environment configs is unspecified; end-to-end reproducibility is uncertain.
Practical Applications
Overview
Below are actionable, real-world applications of the paper’s findings, methods, and innovations. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development). Each item notes relevant sectors and potential tools/products/workflows, along with key assumptions or dependencies affecting feasibility.
Immediate Applications
- Benchmarking-as-a-service for code LLMs in visual game generation
- Sectors: software (AI tooling), gaming, finance (vendor evaluation)
- What emerges: standardized leaderboard and scoring APIs (Code, Image, Video); procurement scorecards; CI/CD integration for continuous evaluation
- Assumptions/dependencies: reproducible sandbox, stable judge models (e.g., Qwen-based), licensing clarity for test artifacts, consistent hardware/software stack
- Automated QA/playtesting for indie and studio pipelines
- Sectors: gaming, software QA
- What emerges: “AutoPlaytest” workflows using the analyze–inject–validate–generate pipeline to convert interactive builds into autonomous demos, capture videos/screenshots, and flag playability failures
- Assumptions/dependencies: Pygame or equivalent integration; deterministic execution; policy-compliant sandboxing of untrusted code; acceptance of LLM-as-Judge where some visual scoring is subjective
- Model selection and vendor due diligence for AI coding assistants
- Sectors: enterprise software, MLOps, procurement
- What emerges: SLAs tied to V-GameGym final and modality scores; cost/performance trade-off dashboards using the observed scaling law
- Assumptions/dependencies: alignment between benchmark tasks and target use cases; a governance process to interpret multimodal scores; budget constraints for larger models
- Documentation and requirement synthesis from legacy game code
- Sectors: software engineering, education, IT modernization
- What emerges: “SpecSynth” tooling that reads existing Pygame code and generates PM-style requirements/specs, aiding onboarding, refactoring, and migration
- Assumptions/dependencies: code access and licensing; LLM reliability for intent inference; human review for high-stakes projects
- CI gating for visual and interactive quality
- Sectors: gaming, software engineering
- What emerges: LLM-as-Judge hooks (Code/Image/Video scores) in CI; pull request gates that ensure minimal playability/aesthetics thresholds before merging
- Assumptions/dependencies: acceptable false-positive/false-negative rates; calibration per project; maintenance of judge prompts and weights
- Curriculum assets for CS, SE, and digital media courses
- Sectors: education
- What emerges: course modules where students implement/modify games from requirements; automated grading via multimodal scoring; visual deliverables for portfolios
- Assumptions/dependencies: classroom compute; instructor oversight for fairness and cheating mitigation; accessible sandbox environments
- Marketing-ready gameplay demo generation
- Sectors: gaming, media/content
- What emerges: automated generation of short, self-running demos and captured clips for store listings and social media
- Assumptions/dependencies: quality thresholds for aesthetics; compliance with platform content policies; brand review
- Reference dataset and tooling for multimodal code generation research
- Sectors: academia, open-source communities
- What emerges: reproducible benchmark with human-validated tasks; analysis of code–visual trade-offs; ablation studies across model sizes and training regimes
- Assumptions/dependencies: continued community support; open availability; documented curation and execution pipelines
- Clustering-based curation for domain-specific code datasets
- Sectors: software tooling, research
- What emerges: “ClusterCurator” workflows to diversify and select high-quality exemplars from large code corpora (beyond games), improving benchmark representativeness
- Assumptions/dependencies: robust feature extraction; quality heuristic tuning per domain; scalable infrastructure
Long-Term Applications
- Cross-engine generalization (Unity, Unreal, WebGL/Canvas, HTML5, native GUI frameworks)
- Sectors: gaming, software, web
- What emerges: engine-agnostic evaluation suites; adapters that replicate V-GameGym’s pipeline for commercial engines, web front-ends, and desktop GUIs
- Assumptions/dependencies: engine access and licensing; multi-platform sandboxing; richer visual/dynamic metrics; extended error-correction loops
- Standards and certification for AI-generated interactive software
- Sectors: policy/regulation, enterprise compliance, gaming platforms
- What emerges: playability/aesthetics/user-engagement metrics as part of formal standards; certification programs for AI coding tools; procurement guidelines and risk controls
- Assumptions/dependencies: multi-stakeholder consensus (industry, academia, regulators), test reproducibility across environments, safety protocols for executing generated code
- Training next-generation code LLMs with multimodal rewards
- Sectors: AI/ML research, software
- What emerges: reinforcement learning and preference optimization using Code/Image/Video scores; curricula blending structural completeness and visual dynamics
- Assumptions/dependencies: scalable data and compute; robust reward modeling; guardrails to avoid reward hacking
- Co-creative design assistants blending code, visuals, and audio
- Sectors: gaming, digital media, education
- What emerges: tools that generate code and stylistically coherent assets; evaluators that score visual aesthetics and dynamic gameplay; interactive assistants for art–code iteration
- Assumptions/dependencies: multimodal model advances; asset licensing; nuanced aesthetic scoring aligned with human perception
- Intelligent, multi-agent playtesting and balancing
- Sectors: gaming
- What emerges: autonomous agents that probe difficulty, engagement, and accessibility; automated feedback loops to adjust parameters, level design, and pacing
- Assumptions/dependencies: reliable simulation, behavior diversity, engagement metrics beyond simple heuristics; human-in-the-loop validation
- Serious games and simulation generation for training and education
- Sectors: education, enterprise training, robotics simulation
- What emerges: domain-specific interactive modules (e.g., physics labs, safety drills, robotics task simulations) generated and evaluated with multimodal scoring
- Assumptions/dependencies: domain alignment of tasks; verification of correctness and pedagogical efficacy; hardware/peripheral integration for simulations
- Marketplace vetting and app store compliance for AI-generated games
- Sectors: gaming platforms, app distribution
- What emerges: automated triage pipelines using sandbox execution and multimodal scoring to flag non-functional or low-quality submissions
- Assumptions/dependencies: platform policy alignment; scalability of triage; appeals/review mechanisms for creators
- Accessibility and inclusivity audits for interactive content
- Sectors: gaming, public sector, education
- What emerges: evaluators that check color contrast, motion sensitivity, input methods, and cognitive load; recommendations for inclusive design
- Assumptions/dependencies: standardized accessibility metrics; integration with assistive technologies; expansion of Image/Video scoring to capture accessibility criteria
- Safety and content moderation for generated games
- Sectors: policy/regulation, platforms
- What emerges: pipelines to detect harmful content, unsafe code behaviors, and privacy risks in generated artifacts; compliance reporting
- Assumptions/dependencies: robust classifiers; clear policy frameworks; secure sandboxing; low false positive rates
Notes on Cross-Cutting Assumptions and Dependencies
- Technical: Python/Pygame environment availability; deterministic, secure sandboxing for untrusted code; video/image capture tooling; reproducibility across OS/GPU stacks.
- Legal/licensing: compliance with source repository licenses; provenance tracking; permissible use of generated assets and demo media.
- Model-related: stability and transparency of judge LLMs and prompts; calibration of modality weights; awareness of bias and subjectivity in visual scoring.
- Operational: compute budget for large models; CI/CD integration effort; human-in-the-loop validation for high-stakes deployments.
- Generalization: extensions beyond Pygame will require engine-specific adapters, richer metrics, and possibly different quality heuristics.
Glossary
- analyze-inject-validate-generate workflow: A closed-loop process for transforming and validating code artifacts using iterative LLM analysis and correction. "operationalizes a closed-loop ``analyze-inject-validate-generate'' workflow."
- argmax: The operation that returns the input value at which a function attains its maximum. "The subsequent operation within each disjoint set guarantees that the selected program is the most complete and runnable exemplar of that particular functional group, based on the quality heuristic:"
- artifact space: The combined space of outputs (e.g., images and videos) produced by executing generated code. "Here, represents the artifact space, composed of the video space and the image space "
- Autonomous Interactive Behavior Injection: A refactoring stage that makes interactive code run autonomously for evaluation. "This is followed by a Autonomous Interactive Behavior Injection stage,"
- clustering-based curation methodology: A dataset construction strategy that partitions samples by learned features and selects high-quality exemplars per cluster. "adopting a novel clustering-based curation methodology to ensure both diversity and structural completeness."
- conditional probability distribution: A probability model of one variable given another, used here to model code given instructions. "approximates the conditional probability distribution "
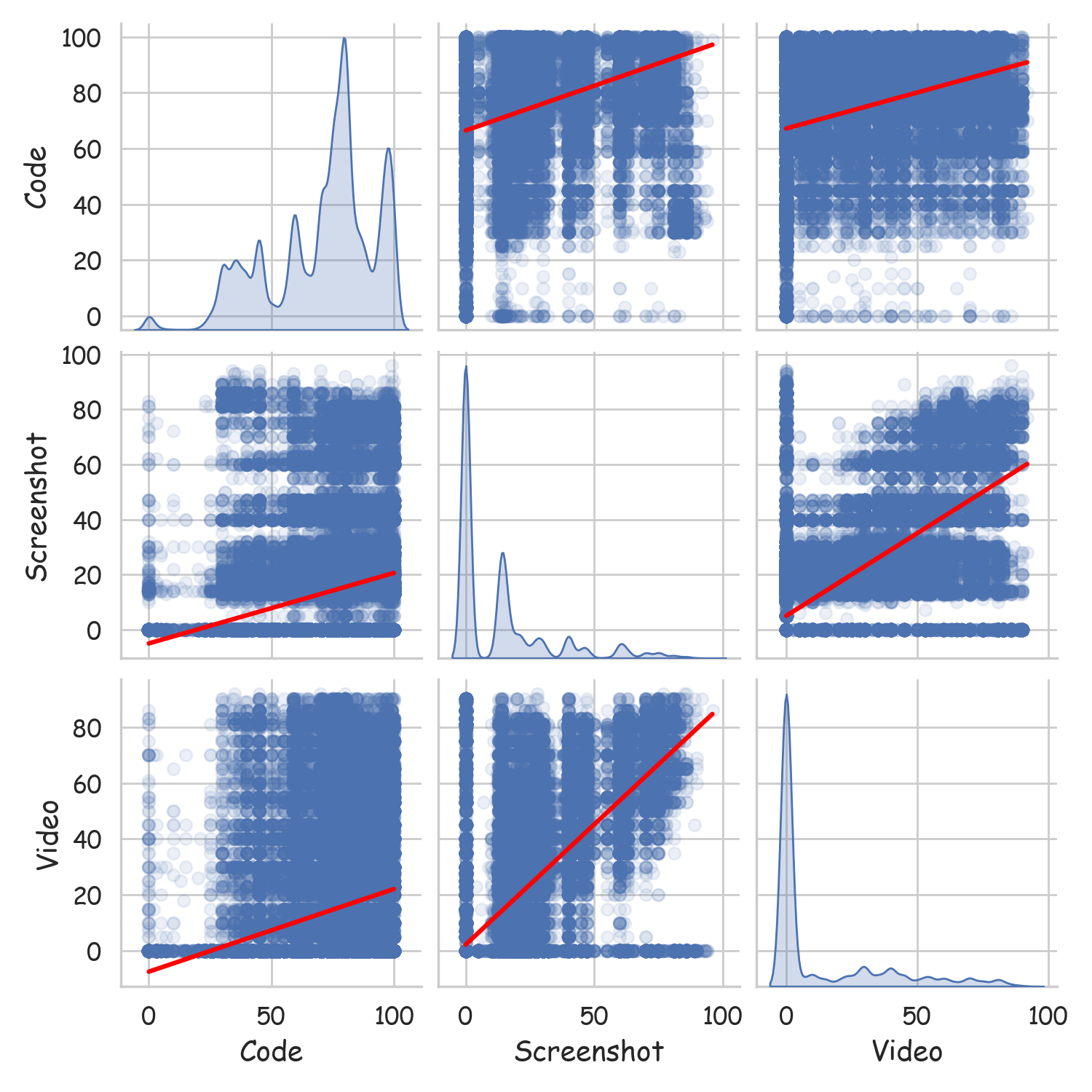
- correlation matrix: A tabular summary of pairwise correlations among multiple variables or evaluation dimensions. "Correlation matrix between Code, Screenshot, and Video evaluation dimensions, demonstrating the interdependence of multimodal capabilities in game development."
- deterministic environment function: A fixed mapping from code to produced artifacts (images/videos) without randomness. "executed by a deterministic environment function , which synthesizes a set of multimedia artifacts"
- end-to-end evaluation pipeline: A complete, automated process from code generation through execution and scoring. "prevent complete end-to-end evaluation pipeline completion."
- execution success rate: The proportion of samples that run successfully to produce required artifacts. "Critically, the dataset's high quality is underscored by a 100\% execution success rate and complete video coverage for all samples, ensuring its reliability for evaluation purposes."
- feature vector extraction function: A mapping that converts code into a numerical feature representation for clustering. "Let be the high-dimensional feature vector extraction function described previously"
- high-dimensional feature vector: A large, multi-component numerical representation capturing code properties. "using high-dimensional feature vectors"
- high-throughput filtering pipeline: A scalable processing system that rapidly filters large code corpora for domain-specific content. "we engineered a high-throughput filtering pipeline."
- LLM-as-Judge: Using a LLM to evaluate outputs (code, images, videos) as an automated judge. "We employ an LLM-as-Judge using Qwen3-Coder-480B-A35B-Instruct to evaluate code scores and Qwen2.5-VL-72B for image/video scores."
- LLM-driven pipeline: An automated workflow orchestrated by a LLM for analysis, transformation, and validation. "an automated LLM-driven pipeline"
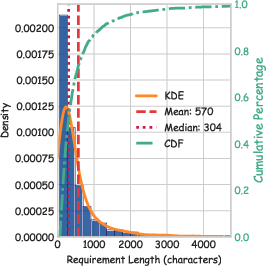
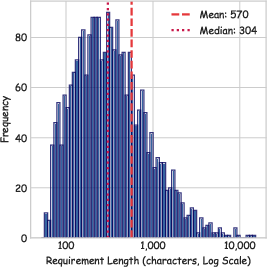
- log-normal form: A distribution whose logarithm is normally distributed, often right-skewed in the original scale. "the distribution approximates a log-normal form"
- MiniBatchKMeans: A clustering algorithm variant that uses mini-batches for efficient partitioning of large datasets. "using the algorithm on the feature vectors ."
- multimodal evaluation framework: An assessment system that jointly evaluates code, static visuals, and dynamic video gameplay. "we introduce a multimodal evaluation framework with an automated LLM-driven pipeline for visual code synthesis using complete UI sandbox environments."
- Multimodal Scoring: A process aggregating evaluation across code, image, and video modalities with weighted scores. "Multimodal Scoring"
- quantitative fingerprint: A numeric signature capturing code characteristics like size, structure, API usage, and semantics. "maps a code sample to its quantitative fingerprint (encompassing size, structure, API usage, and semantics)."
- quality heuristic: A rule-based scoring function that estimates structural completeness and integrity of code. "based on the quality heuristic:"
- radar chart: A multi-axis plot for comparing model performance across several dimensions. "Radar chart comparing the top 10 models across four key performance dimensions."
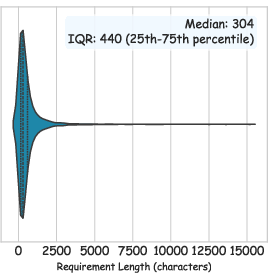
- right-skewed distribution: A distribution where the tail extends to the right, indicating many lower values and fewer higher ones. "a highly right-skewed length distribution"
- sandboxed environment: An isolated execution setting that safely runs code and captures outputs. "Execution Verification within a sandboxed environment."
- Scaling Law of Visual Game Generation: A relation describing how performance scales (e.g., logarithmically) with model size. "Scaling Law of Visual Game Generation"
- Self-Correction loop: An iterative process where error logs are fed back to the LLM for automated debugging and regeneration. "Self-Correction loop"
- structural completeness: The degree to which a program includes necessary components and is runnable. "structural completeness metrics"
- UI sandbox environment: A user interface-enabled isolation environment used to run and inspect visual outputs. "complete UI sandbox environment"
- violin plot: A visualization combining a box plot and kernel density to show distribution shape. "visualized in the violin plot and histogram"
- visual game synthesis: The generation of playable games with coherent visuals and interactions from code. "Visual game synthesis further advances this domain by incorporating multi-modal understanding to generate games with coherent visual and interactive elements."
Collections
Sign up for free to add this paper to one or more collections.