- The paper introduces BigCodeArena, a platform integrating code execution into evaluation, resulting in more reliable human judgments of generated code.
- It analyzes over 14,000 sessions and 4,700 multi-turn samples from diverse programming tasks to capture nuanced LLM performance.
- It proposes BigCodeReward and AutoCodeArena benchmarks to align reward models with human coding preferences and automate evaluations.
BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution
Introduction
The paper "BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution" (2510.08697) addresses the challenges in evaluating code generated by LLMs. Traditional evaluation methods, particularly crowdsourcing, often fall short in contexts requiring the comprehension of complex or long chunks of code. This paper introduces BigCodeArena, a platform that incorporates execution outcomes into the evaluation of code to provide a more reliable basis for human judgment.

Figure 1: BigCodeArena enables user evaluation based on execution outcomes beyond raw code.
System Design and Implementation
BigCodeArena is designed to tackle the limitations of existing evaluation platforms by integrating a real-time execution environment. The model-generated code undergoes actual execution, and users can interact with the resulting outputs to form a more informed preference between code snippets. The platform supports multiple programming environments like Python, JavaScript, and frameworks like React and Vue, crucial for creating diverse code generation scenarios.
The system consists of a web-based frontend for user interaction and a secure backend for managing code execution. The frontend allows code inspections and comparative voting, while the backend handles sandboxed code execution to ensure both security and performance.
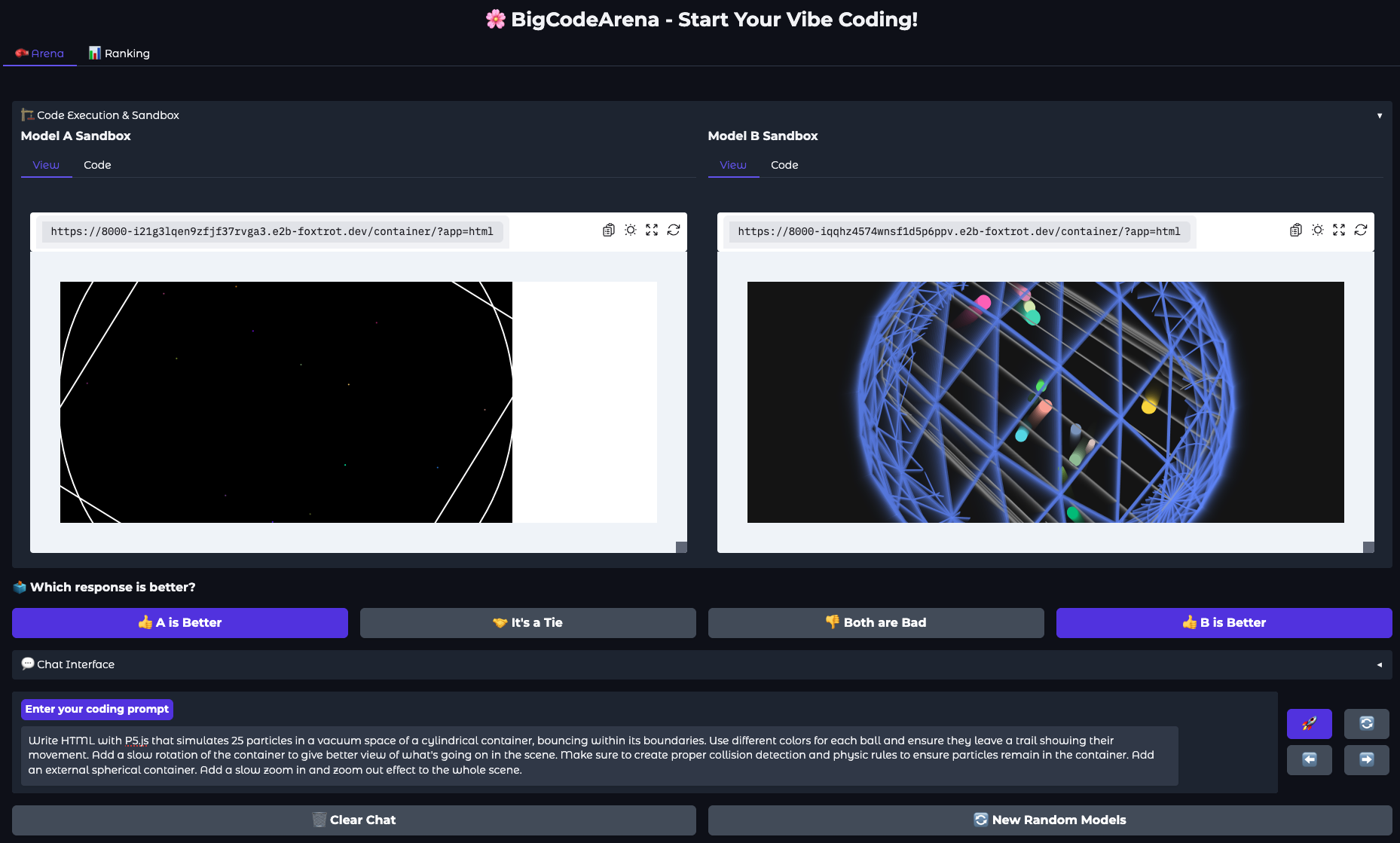
Figure 2: User interface of BigCodeArena.
Data Collection and Analysis
Over five months, BigCodeArena collected more than 14,000 conversation sessions involving code generation tasks implemented by 10 different LLMs. A crucial subset, comprising 4,700 multi-turn samples, focused on human preferences, allowing for in-depth analysis.
The platform categorizes conversations into common programming topics such as Web Design and Game Development. The inclusion of diverse languages and frameworks presents a broad spectrum for evaluating LLM performance in code generation.
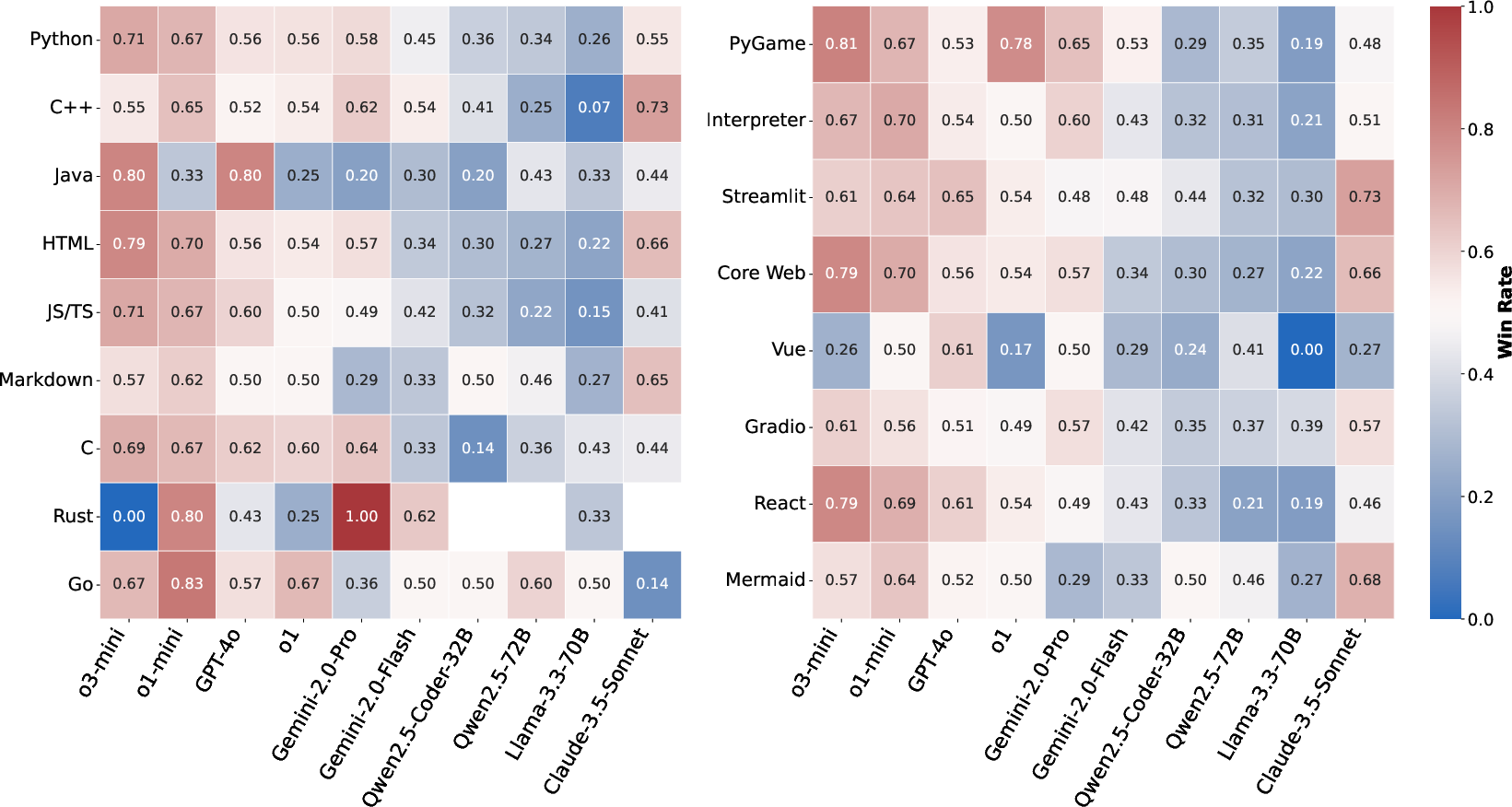
Figure 3: Overall win rate heatmaps (percentage of all pairwise comparisons won) of each model in the sessions across languages (left) and execution environments (right).
Benchmarks: BigCodeReward and AutoCodeArena
To complement the evaluation framework, the authors introduce two benchmarks: BigCodeReward and AutoCodeArena. BigCodeReward investigates the alignment of reward models with human coding preferences by leveraging the collected human judgments. AutoCodeArena aims to automate the evaluation process, reducing reliance on human input by using LLMs to simulate human judgment through experimental setups.
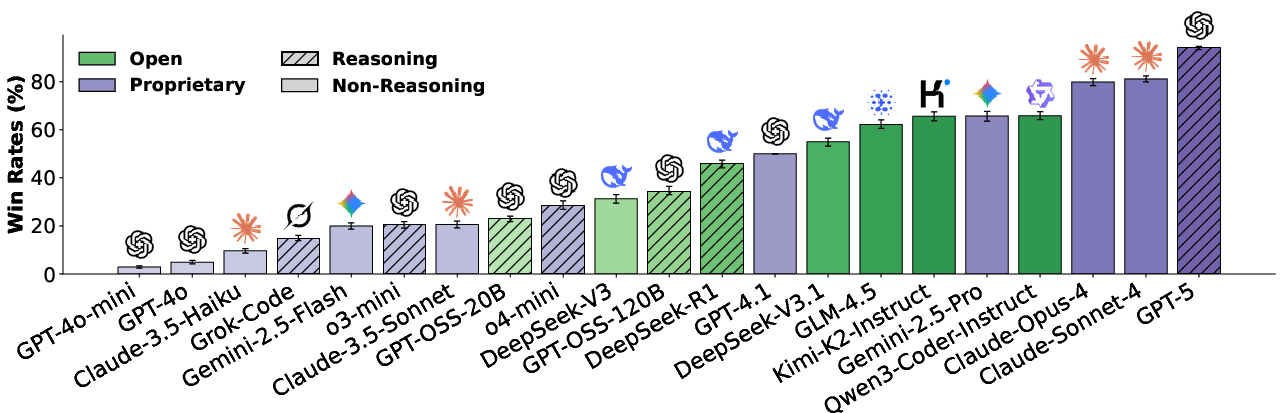
Figure 4: Overall performance of more recent LLMs on AutoCodeArena.
Implications and Future Directions
BigCodeArena significantly enhances the reliability of human-in-the-loop evaluation platforms by focusing on code execution as a pivotal factor for human judgment. This approach challenges traditional static evaluation methods, demonstrating that execution feedback can reveal critical details often missed in static code review.
This initiative paves the way for more informed development of LLMs in software engineering contexts, especially in dynamically typed or rapidly evolving technological environments. Future research may explore expanding the range of supported languages and integrating continuous feedback loops to adaptively refine evaluation criteria.
Conclusion
BigCodeArena offers a significant advancement for evaluating code generation by incorporating live execution, providing an empirical foundation for assessing LLM performance. By revealing gaps left by static evaluations, it lays the groundwork for more robust and context-aware AI systems in software development. The benchmarks derived from this platform offer essential baselines and insights, driving future innovations in AI-driven code generation evaluation.

