- The paper presents a novel abstraction (ReCAP) that enables early filtering during recursive path exploration, reducing intractable runtimes.
- It leverages an NFA-based encoding and selective aggregates to push property constraints deeper into relational query processing, avoiding exponential intermediate results.
- Empirical results demonstrate up to 400,000x speedup and 1,000,000x reduction in intermediate results, highlighting significant performance gains.
Efficient Path Query Processing in Relational Database Systems
Property graphs serve as central abstractions in numerous application domains, encapsulating not only the topological structure (entities and relationships) but also rich attribute data on vertices and edges. Analysis tasks over such graphs frequently demand expressive navigational queries—path queries—that combine regular expressions over edge labels with complex, possibly data-dependent, constraints on properties (e.g., timestamp ordering, bounded weight differences, etc.). Despite theoretical progress on such path queries, supporting their efficient execution in mature database management systems remains unresolved. Modern graph query languages (e.g., Cypher, GQL, SQL/PGQ) expose expressiveness for declarative specification, yet even leading graph and relational DBMS struggle to push property constraints deep within recursive path exploration, causing exponential intermediate results and intractable runtimes.
The paper presents ReCAP, an abstraction designed to enable early filtering of paths during recursive path search, capitalizing on structural properties of constraints that admit such optimization. The crux is making path-constraint structure explicit to the relational optimizer, overcoming its inability to extract and exploit early filter opportunities from generic SQL or Cypher query formulations.
Path Queries, Regular Expressions, and Constraints
Path queries on property graphs are formalized as triples (S,R,φ), where S is a set of start vertices, R is a regex over edge labels, and φ is a Boolean property constraint over paths. A canonical example involves searching for financial transaction chains adhering to both regular label patterns and homogeneous property constraints, such as monotonically increasing timestamps and bounded transaction amount dispersion.
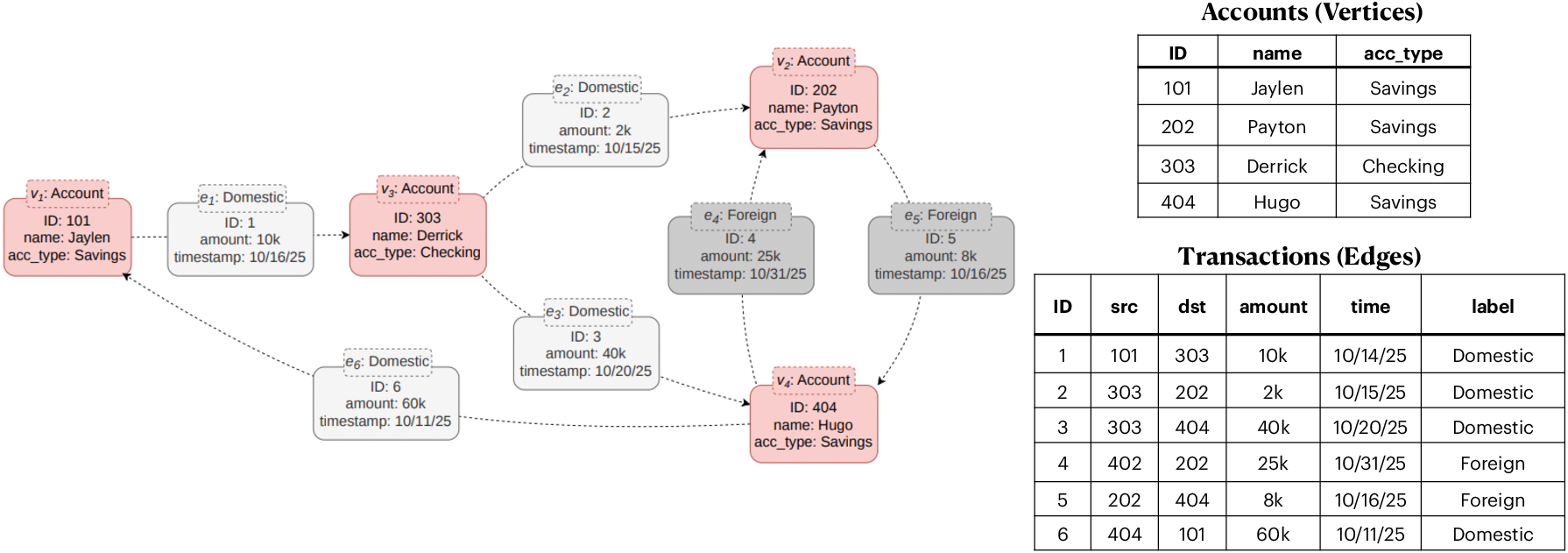
Figure 1: Graph with accounts as vertices and transaction edges, illustrating the multi-attribute structure targeted by path queries.
State-of-the-art DBMS handle such queries via recursive CTEs (SQL) or variable-length pattern matching (Cypher), collecting all candidate paths for the regex and subsequently filtering via property constraints. This results in a blow-up of intermediate paths, especially when output selectivity is high. Query plan inspection (see Figure 2) confirms that filtering occurs only after complete path enumeration, squandering substantial work on doomed paths.
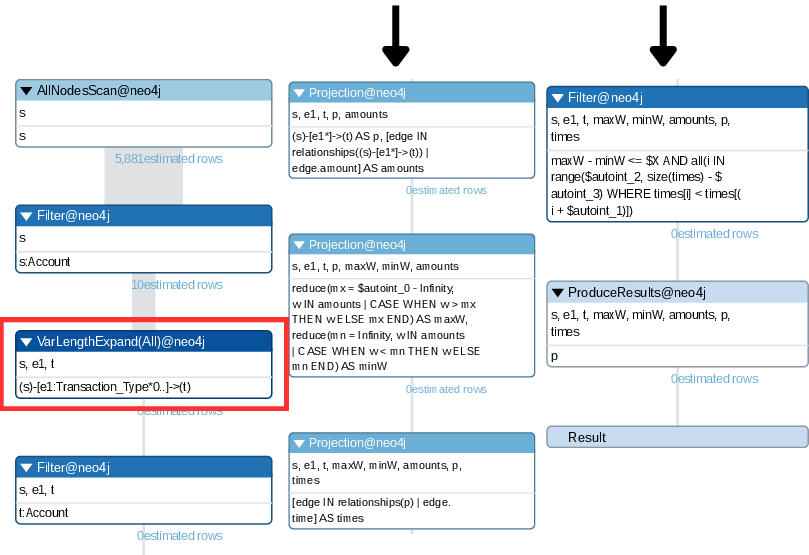
Figure 3: Query plan highlighting delayed application of property constraints after full path expansion.
The ReCAP Abstraction
The central contribution is ReCAP, which systematically exposes and exploits opportunities for early filtering of doomed path prefixes. The abstraction is parameterized by:
The default construction for constraint enforcement (Figure 6) accumulates all relevant edge and vertex properties along paths in list D for later evaluation—akin to list processing in state-of-the-art engines.
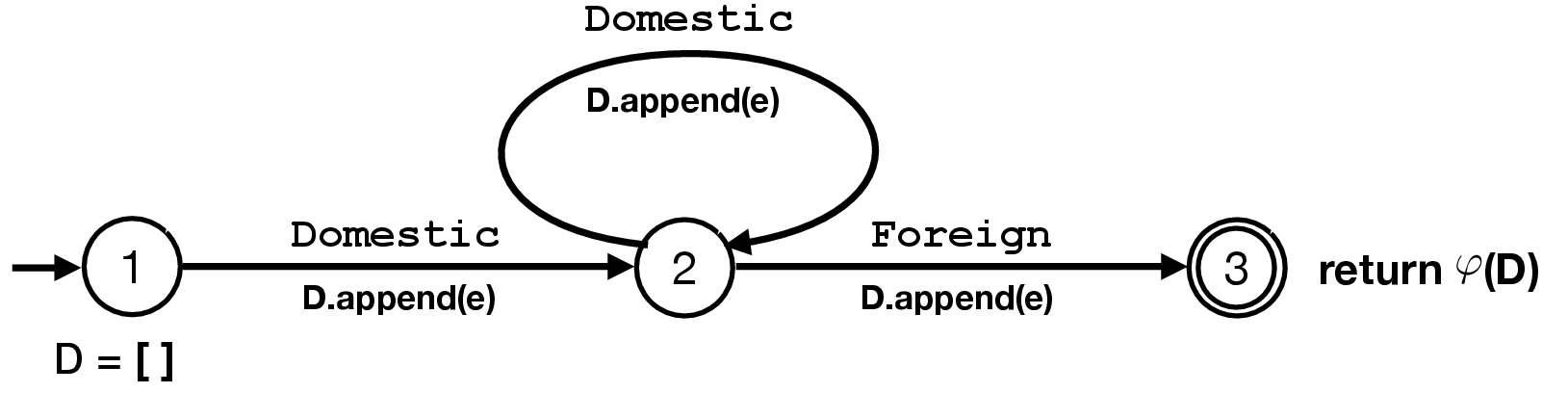
Figure 7: Default construction accumulates path property data and applies φ only at accepting states, precluding early pruning.
ReCAP generalizes this by allowing users to specify incremental state maintenance and viability checks (update, is), driven by NFA transitions, to prune doomed prefixes on-the-fly (see Figure 8 for an annotated NFA).
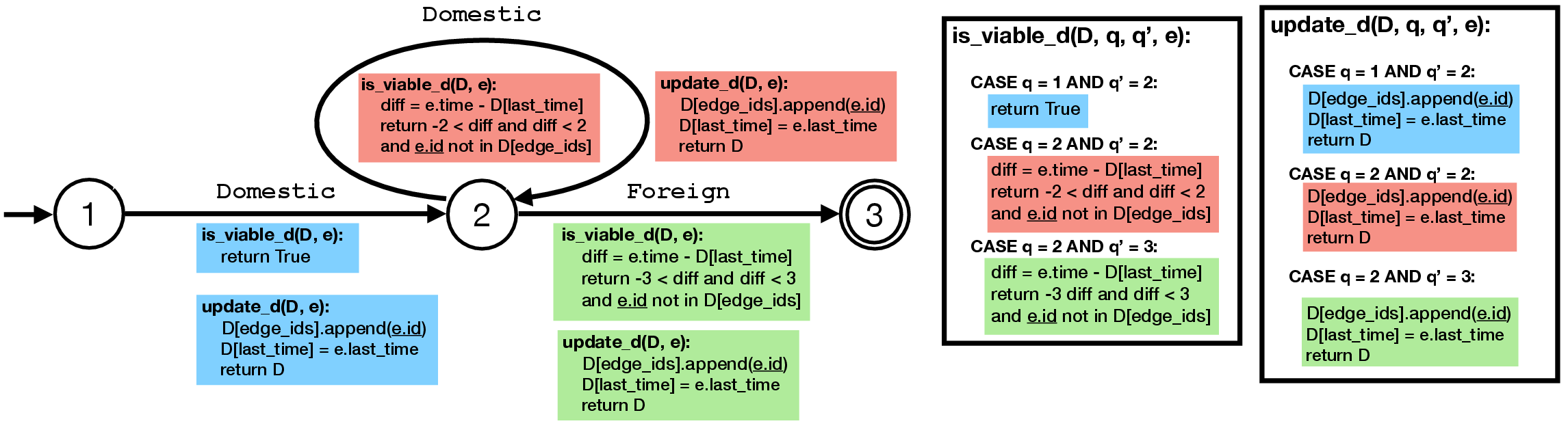
Figure 2: NFA for a complex pattern (e.g., Domestic+ Foreign) with transition-annotated update and viability checks for early filtering.
Relational Implementation and Optimization
ReCAP's practical impact stems from its relational implementation. The abstraction is formalized as a recursive SPJ query, with all customization encapsulated in transition tables (for regex) and selective aggregate function calls. The encoding leverages JSON columns for complex state, yet the authors optimize this further via dictionary flattening (mapping state to native columns/types) and function inlining (expanding UDFs to native SQL expressions), avoiding JSON and Python function call overhead. Figures 10–14 walk through these code transformations, demonstrating how fully optimized ReCAP queries remove UDF and JSON costs entirely.
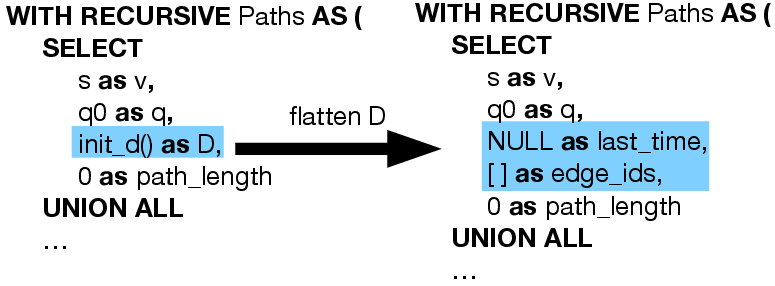
Figure 4: Inlining initialization of path state into the anchor SELECT.
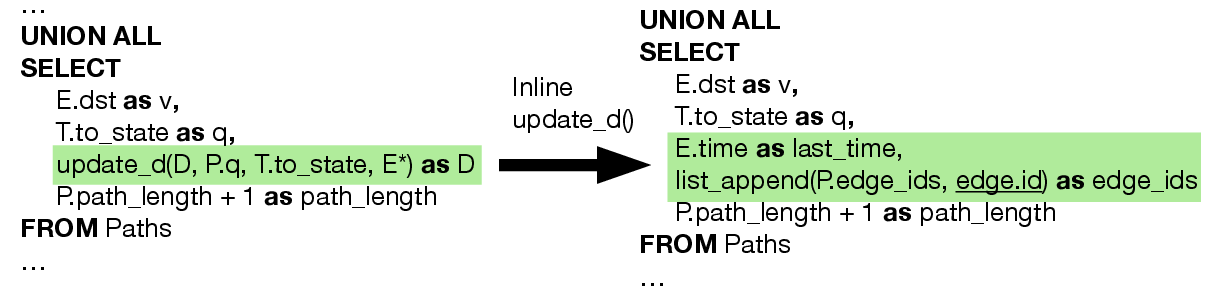
Figure 11: Inlining state update logic during recursion for maximal pushdown.
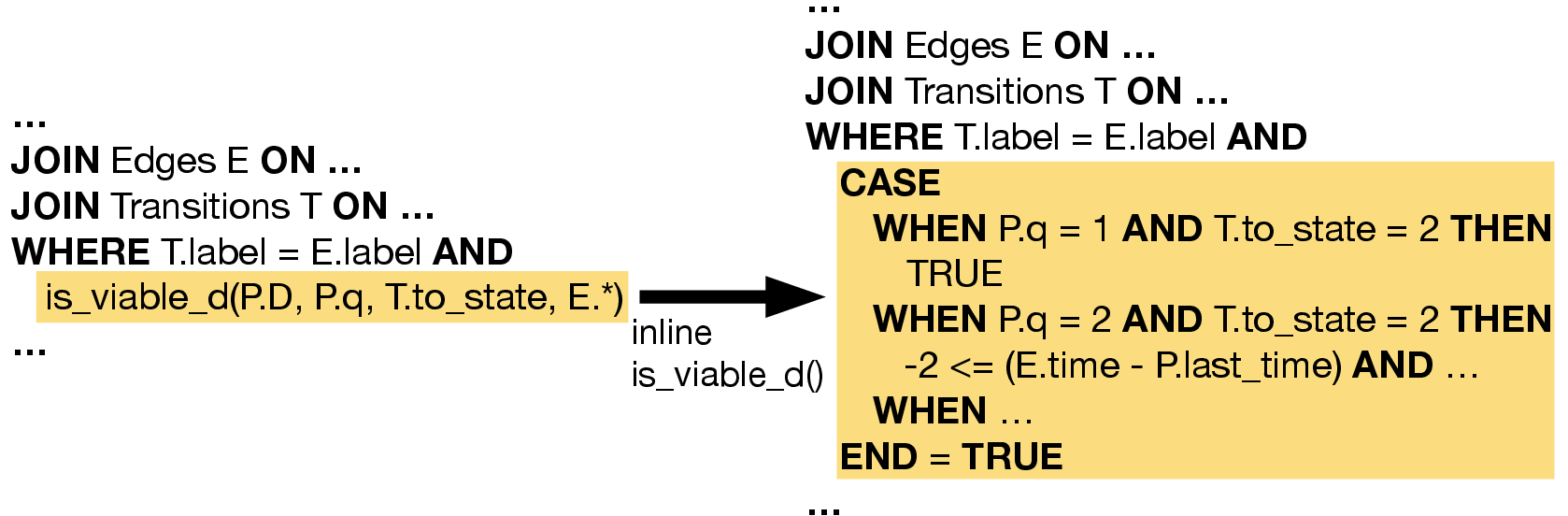
Figure 6: Incorporating viability checks directly in recursive WHERE clauses.
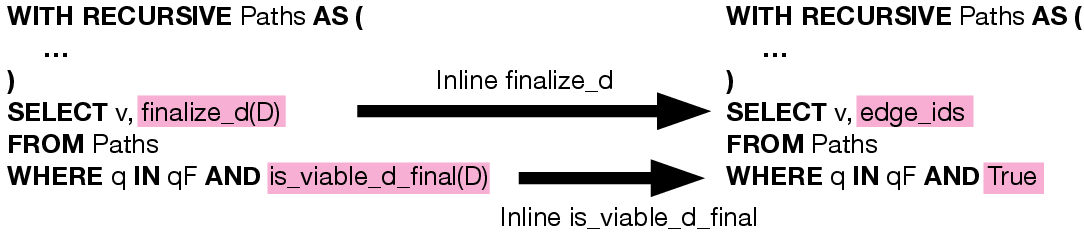
Figure 8: Inlining finalize and is functions at query termination.
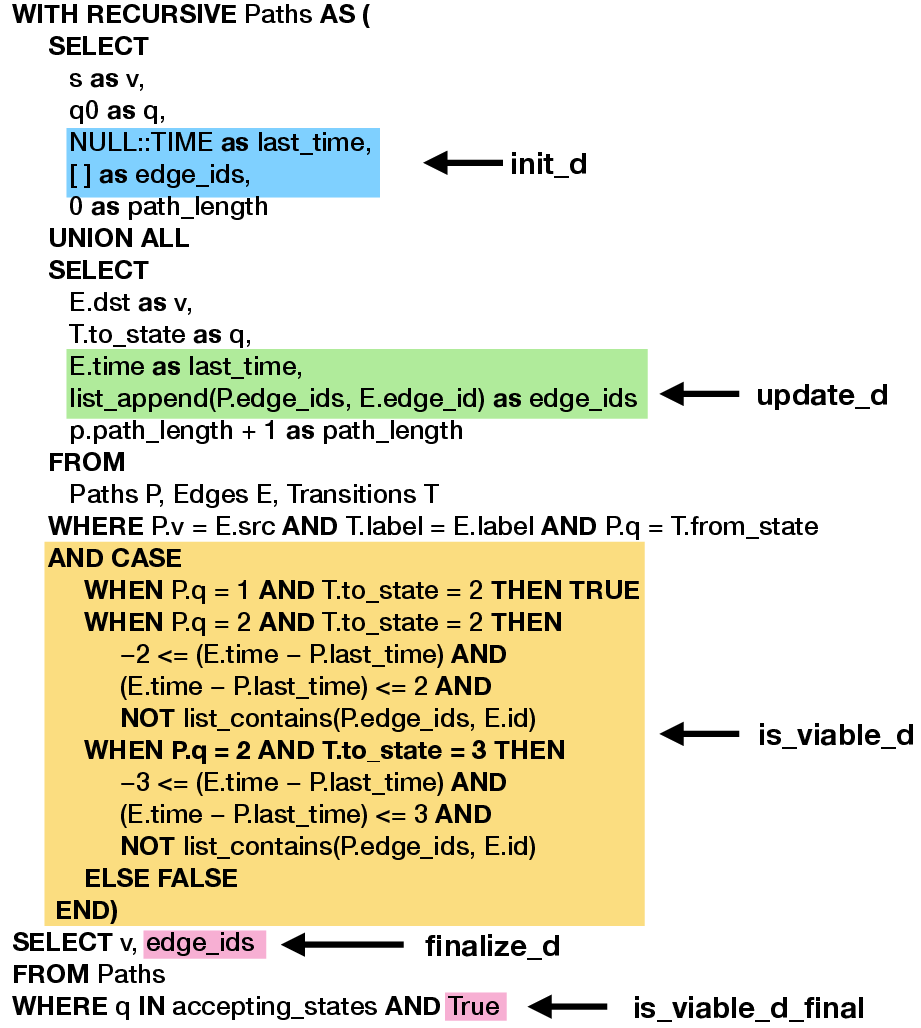
Figure 9: End-to-end fully optimized SQL code generated for the discussed ReCAP instance.
Empirical Results and Quantitative Claims
The experimental evaluation spans real-world and synthetic property graphs, comparing ReCAP in DuckDB (with all optimizations) against leading graph DBMSs (Neo4j, Kùzu, Memgraph) and relational engines (including a high-performance commercial system). Across a spectrum of realistic queries with varying early filtering potential, ReCAP yields up to 400,000x faster runtimes and reduces intermediate results by up to 1,000,000x relative to competitors. The performance advantage tracks the degree of early filter opportunity in constraints; for constraints not admitting early pruning, ReCAP degrades gracefully to the status quo.
Notable technical claims include:
- Order-of-magnitude improvements: For several query/data combinations, ReCAP achieves >103–105× speedup in runtime and intermediate result reduction.
- Constraint expressiveness: ReCAP seamlessly supports all regular expressions and any data-dependent constraint for which early pruning is possible.
- "Regret-free" optimization: When constraints do not admit early pruning, ReCAP reduces to conventional execution, introducing no additional overhead or penalty.
Implications and Theoretical Perspectives
ReCAP directly addresses the core deficiency in contemporary DBMS query optimization for graph workloads: the inability to exploit the incremental structure of many property constraints. This work underlines the gap between query language expressiveness and system-level optimization, stressing the need for explicit abstractions that reveal structure to the engine. The implications for both DBMS engineering and the theory of query processing are substantial:
- System integration: ReCAP demonstrates that with minimal changes (adding select few user-defined, yet inlinable, functions and a transition relation), existing relational engines can match or exceed the performance of specialized graph systems on a broad class of queries.
- Language design: The results raise important questions for the evolution of graph query languages and standards. Supporting direct mapping of constraints into incremental filtering logic may be essential for scalable graph analytics.
- Automata with memory: ReCAP's generality extends prevailing automata-based approaches (e.g., register automata, variable automata), subsuming them as special cases oriented toward practical system implementation rather than theoretical formalisms.
For future directions, the authors highlight the potential for automated compilation from high-level constraint specifications to optimized SQL, leveraging further selectivity-driven fragment ordering and supporting ranked path queries.
Conclusion
ReCAP, as formulated in this work, offers a principled and practical solution to the longstanding challenge of efficient path query processing with property constraints in relational DBMSs (2604.02553). By embedding the structure of regular and data-dependent constraints as explicitly-expressible incremental logic, ReCAP bridges the gap between the declarative richness of modern query languages and the optimizer's capacity for principled, aggressive pruning. The empirical evidence, supported by orders-of-magnitude gains, demonstrates that with simple, generic abstraction and implementation strategies, mature relational systems can deliver high-performance graph analytics on par with or superior to domain-specific graph engines, while remaining fully compatible with standard SQL infrastructure.
