- The paper introduces OmniTQA, a framework that decomposes natural language queries into a DAG of symbolic and semantic operators to optimize hybrid query execution.
- It employs cost-aware planning that strategically minimizes expensive LLM calls by leveraging early relational pruning and schema grounding.
- Empirical results demonstrate improved accuracy and reduced token costs, particularly in handling semi-structured data and complex multi-relation queries.
OmniTQA: Cost-Aware Hybrid Query Processing over Semi-Structured Data
Introduction
OmniTQA formalizes and addresses the challenge of hybrid query processing in databases containing both structured attributes and free-form textual columns. This hybrid, or semi-structured, setting is prevalent in real-world enterprise systems, where information relevant to answering queries may be buried in text fields without explicit schema representation. The OmniTQA framework introduces a principled method for cost- and data-aware decomposition, planning, and execution of natural language queries, unifying classical relational operators and LLM-based semantic operations in a single, optimized execution plan.
Problem Setting and Motivation
OmniTQA targets the Semi-Structured Table Question Answering (SSTQA) paradigm, distinguished by hybrid schemas where information may be spread across structured columns or indirectly referenced within unstructured free-text columns. Previous solutions in Table QA predominantly assume strict structure: either mapping language to SQL over known schemas or applying LLMs directly to serialized tables. Both approaches fail under schema/representation heterogeneity, data scale, and the need for multi-relation reasoning.
Illustratively, a simple NL query over a soccer tryout database may translate directly to SQL if all attributes (e.g., "position", "decision", "state") are explicit. The same query becomes nontrivial when these are encoded as text excerpts, necessitating entity extraction, predicate resolution, and fuzzy joins (see (Figure 1)).

Figure 1: Two distinct schema representations for the same data, highlighting the challenges of semi-structured data and the need for semantic reasoning fused with symbolic operators.
System Architecture
OmniTQA implements a three-stage pipeline: preprocessing, planning & optimization, and dual-engine execution. It decomposes each input query into an executable DAG whose nodes are either symbolic (relational) or semantic (LLM-powered) atomic operators. Relational nodes execute directly in a database engine; semantic nodes invoke LLMs for fuzzy filtering, extraction, or joins. Plans are optimized to minimize the high cost of LLM calls by maximizing early relational pruning and strategic ordering, and plan diversification is leveraged to hedge against NL or schema ambiguities.
The architecture is depicted in (Figure 2).

Figure 2: End-to-end OmniTQA system overview, highlighting preprocessing, atomic plan construction, cost-aware optimization, and dual-engine execution.
Planning and Optimization
The query planning phase involves several sub-tasks:
- Schema grounding: Query terms are mapped to relevant tables and attributes (structured or unstructured), using a data preview for contextual alignment.
- Atomic step decomposition: The query is decomposed into minimal, interpretable operations composed in a DAG. Each operation specifies its input/output relations and operator class (relational vs semantic).
- Hybrid operator modeling: The operator universe encompasses typical relational algebra (selection, projection, join, etc.) and LLM-backed semantic MAP, FILTER, JOIN, and AGGREGATE.
Given the high inference cost of LLM operations, OmniTQA extends classical relational optimization via a new cost model. Semantic operators are pushed down or deferred based on predicted tuple/attribute cardinality—the model explicitly weighs the cost of LLM calls (token-based, per-input-row) against the benefit of relational data reduction.
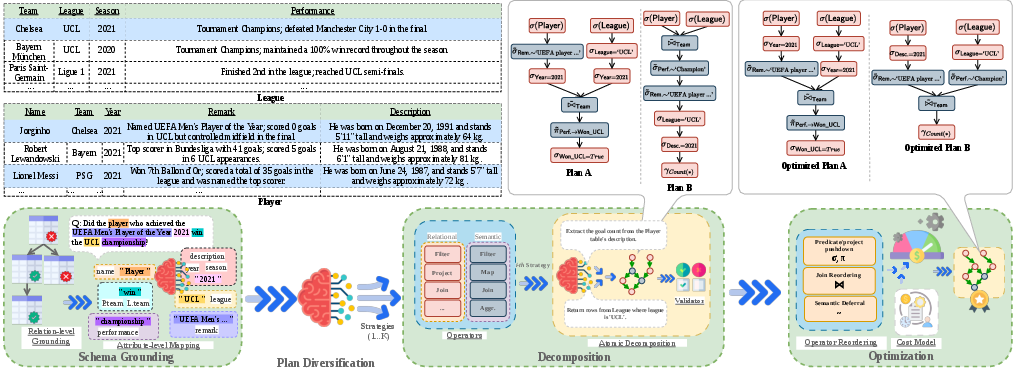
Figure 3: The planning phase: query-aware data preview and diversified plan generation illustrating how schema ambiguity is resolved with candidate plans.
Plan diversification explores ambiguity in mapping vague NL predicates to schema elements, generating K alternative plans consistent with the question and schema.
Dual-Engine Execution and Batching
OmniTQA's execution model routes relational operators to SQL and semantic operators to an LLM engine, with strong operator-aware batching for scalability. Batches are dynamically sized to fit within token constraints, and blocking operations like semantic joins are implemented via chunked block-nested loop LLM calls or recursive map-reduce for aggregates. Multiple plans (from diversification) are executed concurrently both at the plan and operator level.
After execution, candidate outputs are consolidated using a semantic judge: either LLM-based answer comparison (LLM-as-a-Judge), majority voting over results, or user-guided selection.
Empirical Results
OmniTQA achieves substantial improvements on a broad suite of task settings—including large tables, complex compositional queries, multi-relation operations, and hybrid (structured + semi-structured) schemas—over symbolic, semantic, and hybrid baselines.
The framework consistently delivers higher accuracy at comparable or reduced token cost. Largest gains are observed in cases with significant schema ambiguity or where predicates/joins must be reconstructed from free text. Key results are depicted in (Figure 4).

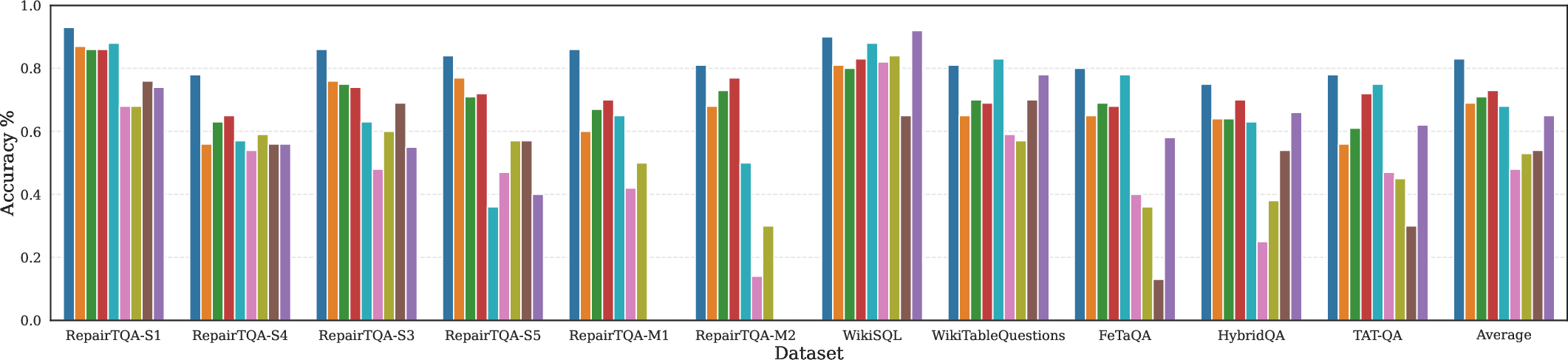
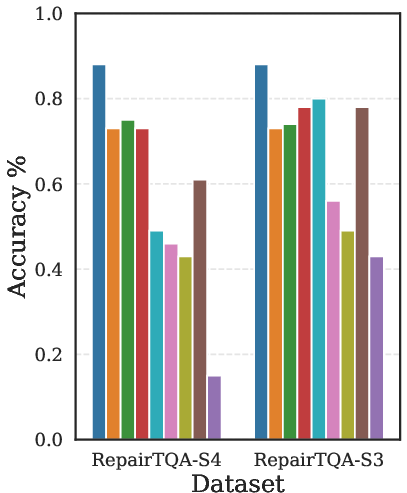
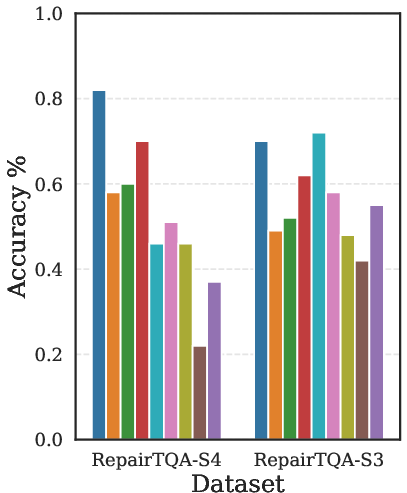
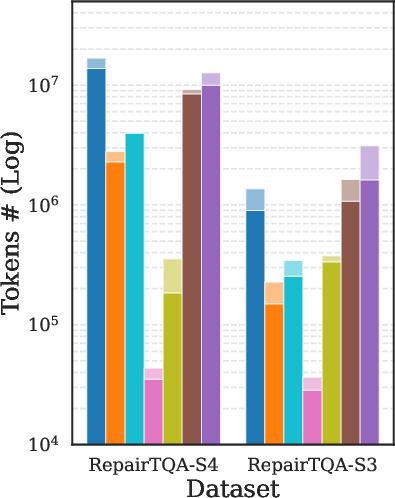
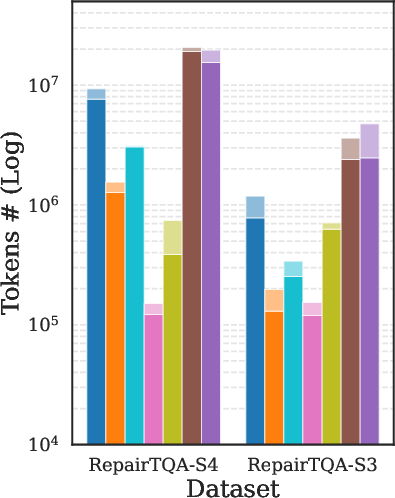
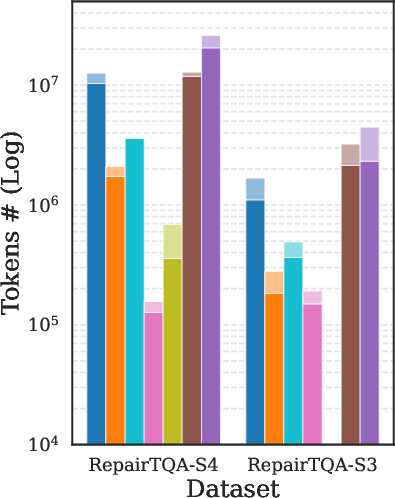
Figure 4: Comparative accuracy of OmniTQA and several baselines (LLM-based, hybrid, and symbolic) across representative benchmarks, demonstrating pronounced gains in challenging SSTQA settings.
Further ablations show:
- Removing query-aware previews or schema pruning yields tangible accuracy drops.
- Operator model design (decoupled relational/semantic) is critical for semi-structured data decomposition—QDMR-based decompositions perform significantly worse.
- Disabling plan optimization increases semantic execution cost without accuracy benefit (cost rises up to 20%).
- Structured plan diversification materially improves robustness to schema ambiguity.
- Increasing the number of diversified plans (K) leads to immediate accuracy increases, which plateau after a modest value; cost grows linearly (Figure 5).
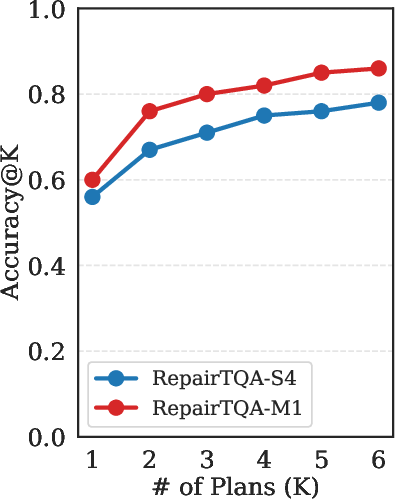
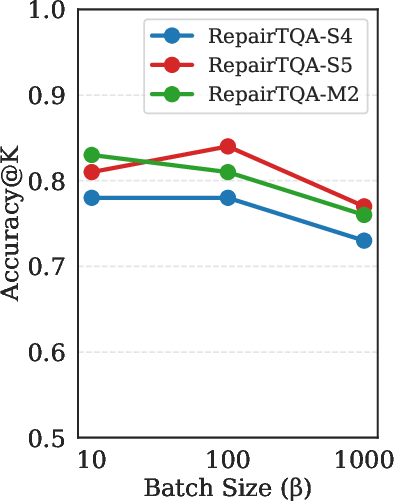
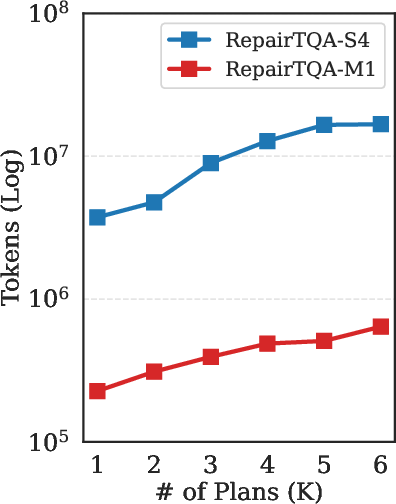
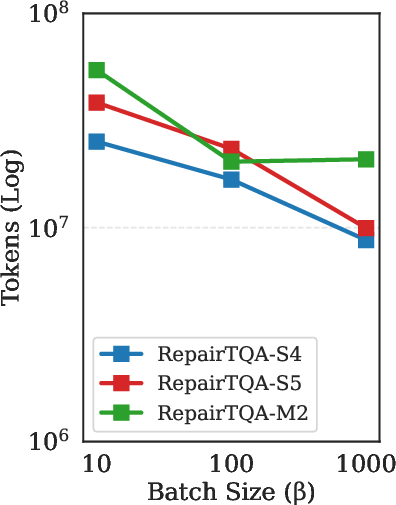
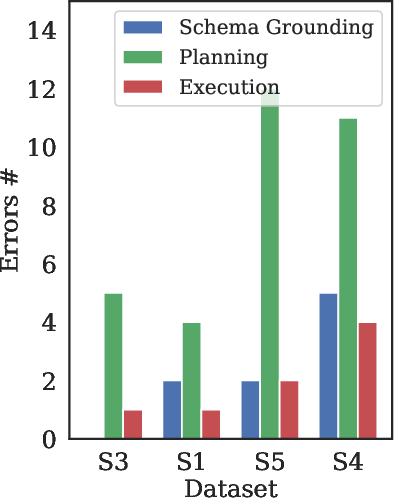
Figure 5: Number of diversified candidate plans (K) vs. accuracy, showing diminishing returns after K=2.
Practical and Theoretical Implications
OmniTQA illustrates that hybrid symbolic-semantic query execution is feasible and efficient in semi-structured settings, provided that semantic operations are first-class operators within an optimized query plan. This architecture enables scalable, compositional, and cost-controlled answers to NL queries, even when schema drift or latent attribute encoding preclude full symbolic interpretation.
The separation of execution engines with operator-level batching generalizes to other hybrid NLP+DB workloads and supports efficient scaling across data and model constraints.
Theoretically, this approach strengthens the case for DAG-based multi-engine query planning, operator-level optimization across heterogeneous cost models, and LLMs as programmable reasoning modules in broader data systems.
Future Directions
Several research directions emerge:
- Integration of efficient low-recall symbolic pre-filters or entity linking to further reduce LLM workloads.
- Automated, model-aware control of K in plan diversification based on query complexity.
- Cascaded model architectures: routing lightweight semantic tasks to efficient models, reserving large LLMs for harder cases.
- Extensions for time-series, graph-structured, or entirely unstructured document settings.
Conclusion
OmniTQA establishes a scalable, robust, and cost-aware hybrid query execution framework for semi-structured Table QA, unifying symbolic and semantic reasoning within an optimized, interpretable plan. Its architectural principles—atomic reasoning steps, explicit semantic operators, data-aware planning, and dual-engine execution—are widely applicable for next-generation natural language interfaces to complex, heterogeneous databases.

