- The paper shows that no single LLM achieves maximal diversity, motivating per-query model selection for enhanced output variety.
- It introduces the 'diversity coverage' metric to jointly quantify output quality and diversity, validated through experiments on multiple datasets.
- Learned routers outperform fixed and random ensembles, achieving up to 26.3% diversity coverage and adapting effectively to prompt-specific strategies.
Ensemble-Centric Diversity in LLM Outputs: A Technical Analysis of "No Single Best Model for Diversity: Learning a Router for Sample Diversity"
Problem Statement and Motivation
Current LLM research has focused extensively on increasing diversity within generations from individual models via inference or prompting strategies. However, with growing access to heterogeneous model families, the potential for model-level ensembling to maximize diversity remains under-explored. This work identifies that, on prompts with a large valid response space, no single LLM achieves globally maximal diversity, even among state-of-the-art open-source models. This finding motivates the central problem: can a learned router, operating via per-query model selection, systematically outperform any model or fixed ensemble at generating unique, high-quality outputs?
Diversity Coverage: Unified Metric for Diversity and Quality
The inadequacy of classical diversity metrics, especially under open-ended generative tasks, necessitates more nuanced evaluation. The paper introduces the "diversity coverage" (div-cov) metric, defined as the sum of quality scores over all unique responses—partitioned by semantic equivalence and normalized by the maximum attainable score at the given generation budget. This metric generalizes to both finite and infinite target spaces and unifies output diversity with response quality, sidestepping weaknesses in n-gram-based or sole embedding-based methods. The computation leverages a classifier-based semantic equivalence function and rewards via an external reward model, scaled to a discrete 1-10 range.
Empirical Analysis: No Universal Model Dominance
Comprehensive experiments with 18 models (Llama, Qwen, OLMo, Gemma) across several datasets (Simple Questions, NB-Curated, NB-WildChat, Infinity-Chat) elucidate that model-specific strengths exist but no model universally dominates in diversity coverage on open-ended prompts. The distribution of dominant models varies widely, and often for open-ended questions, no single model achieves a sufficiently large margin to be considered dominant.
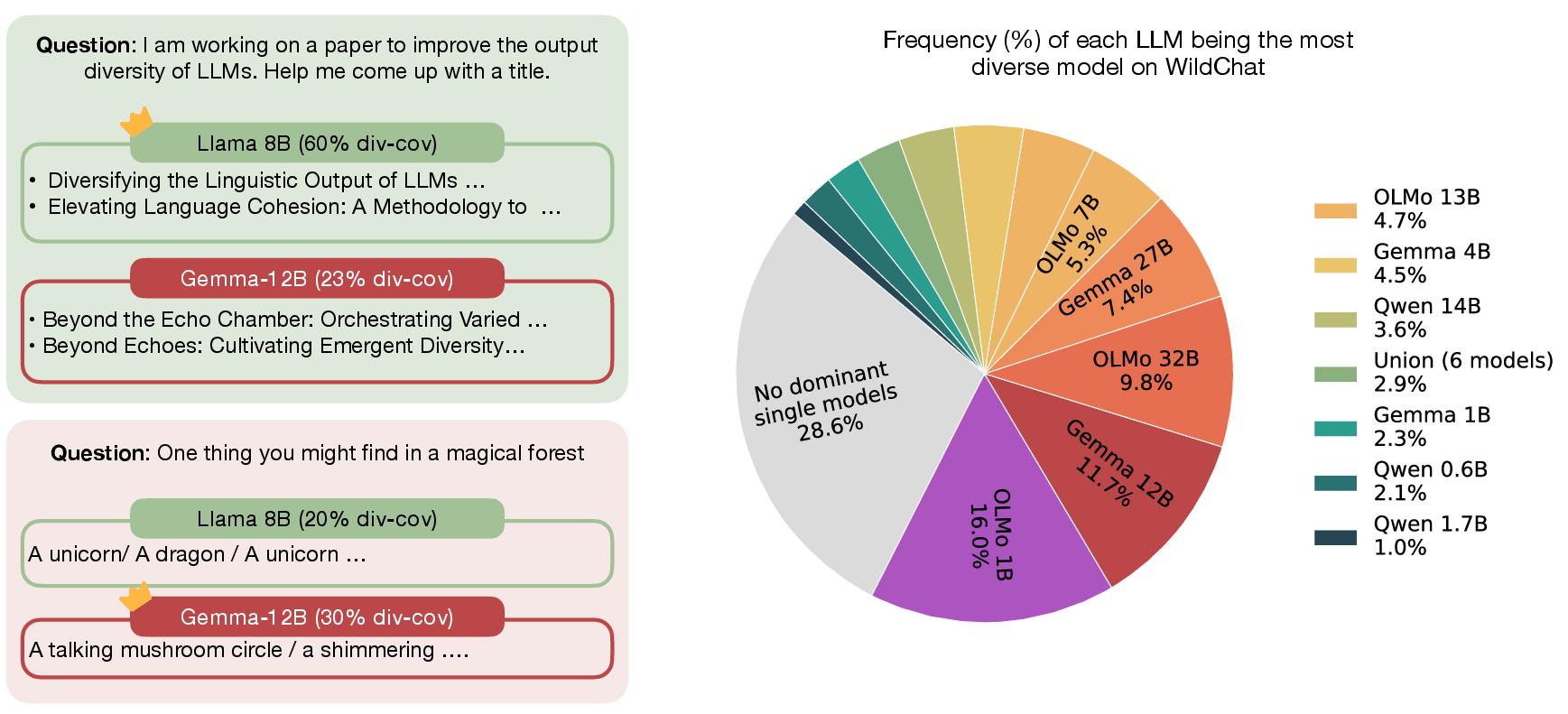
Figure 1: LLMs exhibit different diversity coverage; model dominance is absent on NB-WildChat, while on Simple Questions, performances converge and no model dominates.
Further, quantifying the frequency of models being optimal (with a strict margin) exposes the lack of a universal winner, especially as prompt open-endedness increases.
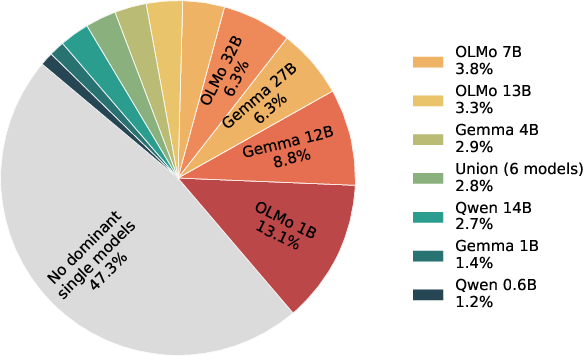
Figure 2: No model consistently achieves the highest diversity coverage on NB-WildChat, corroborating the absence of universal dominance; performance is nearly uniform on Simple Questions.
Oracle Ensembling and the Upper Bound of Per-Query Routing
Oracle experiments, assuming perfect knowledge of per-query model performance, reveal that selecting the best model per query (oracle routing) substantially outperforms the top overall model baseline—gap exceeding 29% for highly open-ended NB-WildChat questions. Simple heuristics such as always combining the best two models or random model selection are consistently suboptimal. Notably, ensembling via oracle-selected model pairs further enhances diversity coverage, revealing the compounding gains achievable with flexible model routing.
Router Design: Learning Model Selection for Maximum Diversity
The router task is framed as a classification problem: either multiclass (select the most promising model among the pool per query) or as a suite of binary classifiers (one per model). Two query featurizations are compared: an agnostic retriever-based embedding (inf-retriever-v1) and model-specific final-layer states, with the latter giving superior gains in in-domain datasets. Classifiers (MLPs and BERT) are fine-tuned on training sets labeled with oracle selections. Performance is tracked with both the diversity coverage metric and its decompositions (number of unique answers, average quality, and quality among unique answers).
Numerical Results and Analysis
On NB-WildChat, the best learned router (Binary MLP with model-specific encodings) achieves a 26.3% diversity coverage, statistically significantly surpassing the best single-model baseline (23.8%). On out-of-domain NB-Curated, routers maintain competitive generalization, though the performance gap attenuates. Notably, training data scaling experiments on even broader Infinity-Chat data demonstrate that router performance improves monotonically with dataset growth and generalizes across tasks. Moreover, router-guided selection of model pairs (top two) yields further boosts (up to 35.8% on NB-WildChat), approaching the oracle upper bounds.
Prompting Strategy and its Effect on Diversity
The study systematically contrasts diverse prompting strategies: "generate one", "generate two", and "generate all" (sequential enumeration). The sequential approach markedly outperforms parallel strategies in diversity coverage, albeit at the cost of diminished per-answer quality for later outputs. Notably, routers learn prompting-strategy-specific policies; across-prompt generalization is weak, underscoring the coupling between prompt structure and model diversity.
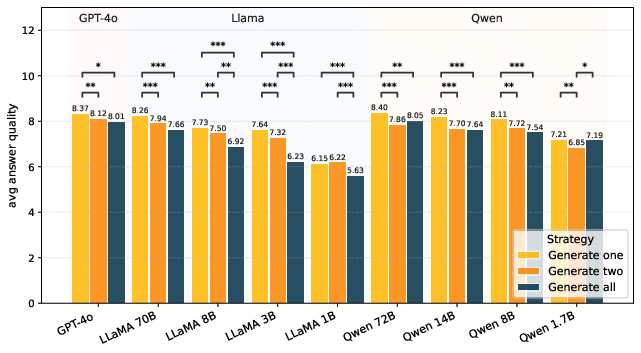
Figure 3: Average answer quality for responses generated from different prompts on NB-Curated; sequential (generate-all) prompts result in lower per-answer quality compared to generate-one.
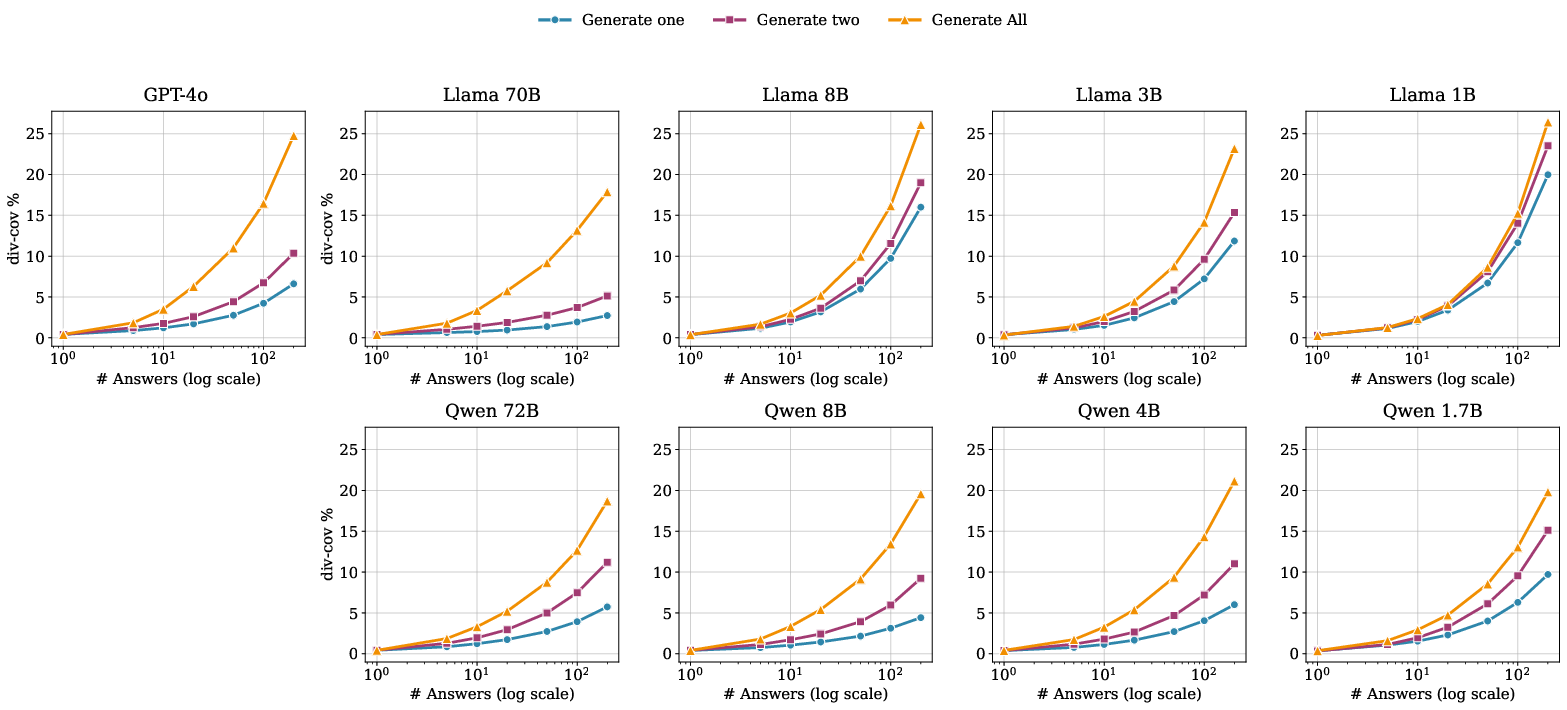
Figure 4: Comparison of diversity coverage trajectories for different prompt templates and models as a function of the number of samples generated.
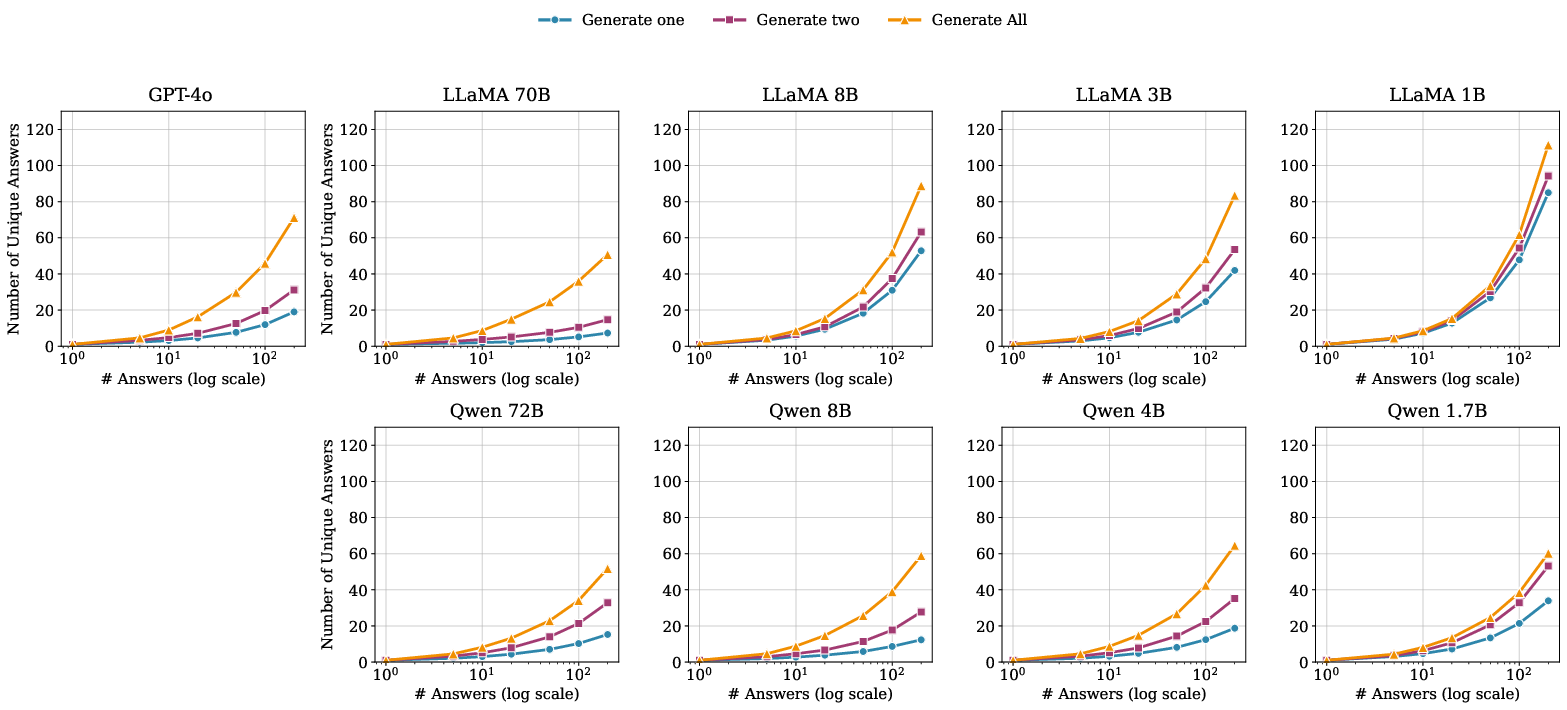
Figure 5: As more answers are generated (X-axis, log-scale), the diversity coverage converges towards the theoretical maximum.
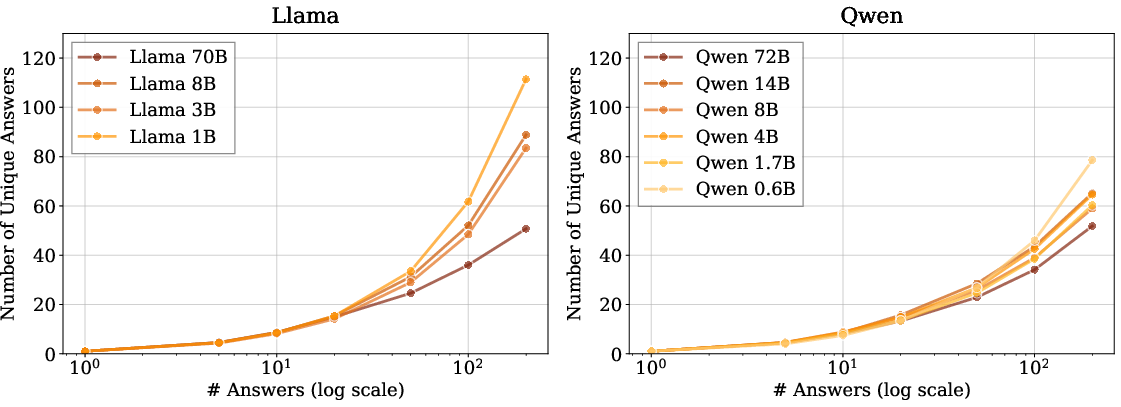
Figure 6: Llama family models produce more unique answers as sampling increases, but with increased intra-family variance compared to Qwen.
Architectural and Practical Implications
From a systems perspective, router-driven ensembling introduces only 2-3× inference overhead relative to a top single model, while oracle ensembles introduce up to 19× overhead. The router cost is predominantly due to sampling larger models, not routing computation itself. Unlike fixed-combination strategies, routing dynamically leverages complementary model strengths, tailoring model selection to query difficulty and open-endedness, thus maximizing diversity coverage with tractable additional cost.
Theoretical Implications and Prospects
This work recontextualizes diversity optimization as a meta-model selection problem and provides evidence that heterogeneity at the model level is inherently advantageous for generative diversity. The results suggest that the space for diversity improvement via ensembling is not saturated, especially as model pools become more exansive and diverse. The diversity coverage metric, decoupled from generation order, provides a solid foundation for future multi-model system evaluation, particularly in applications requiring broad coverage of non-canonical or creative outputs.
Importantly, the observation that per-query model selection is necessary to optimize diversity calls into question the adequacy of single-model deployment strategies for open-ended generative tasks, even in the presence of strong base models.
Conclusion
This study demonstrates that (1) no single LLM family or size dominates diversity coverage across open-ended prompts, (2) significant diversity gains accrue from oracle and learned per-query routing, and (3) routing scales positively with data and model pool size. Taken together, these results have direct implications for the operationalization of LLM ensembles in settings where comprehensiveness of valid generative outputs is paramount, and they motivate further exploration into the design of efficient, scalable, and generalizable routing algorithms in multi-LLM systems.