- The paper introduces HeartStream, a fully programmable 64-core RISC-V cluster achieving 410 GFLOP/s peak performance and 204.8GBps L1 bandwidth for B5G/6G O-RAN.
- It employs a hierarchical shared-memory design and flexible systolic execution to reduce memory overhead and accelerate matrix operations for baseband and AI tasks.
- The processor delivers high energy efficiency (up to 213 GFLOP/s/W) and low-latency (<4 ms) performance, supporting diverse MIMO and deep learning workloads.
HeartStream: A 64-Core RISC-V Shared-Memory Cluster for Energy-Efficient B5G/6G AI-Enhanced O-RAN
Introduction and Motivation
The transition from 5G Cloud RAN to 6G O-RAN necessitates open, programmable hardware/software platforms capable of supporting distributed intelligence and multi-vendor interoperability. The computational and energy demands of base stations are intensifying due to requirements for >20 Gbps uplink throughput and <4 ms end-to-end latency, especially as AI-native processing converges with wireless workloads. HeartStream addresses these challenges by delivering a fully programmable, energy-efficient, and high-performance manycore cluster tailored for B5G/6G O-RAN edge deployments.
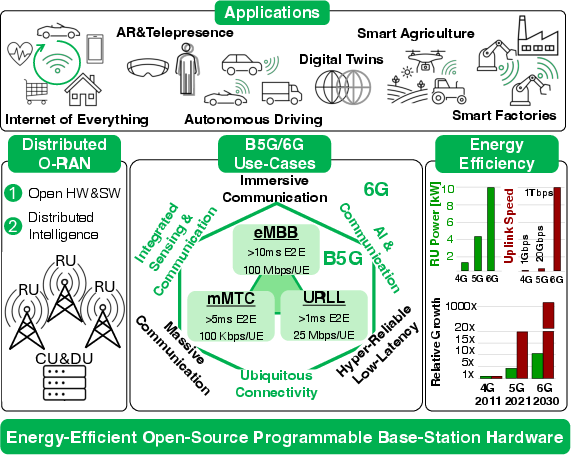
Figure 1: Energy-efficient open-HW/SW designs support B5G/6G O-RAN demanding use-case scenarios and a wide range of applications.
Architecture Overview
HeartStream comprises 64 RISC-V cores organized in a hierarchical shared-L1-memory cluster, achieving 410 GFLOP/s peak performance and 204.8 GBps L1 bandwidth in 12nm FinFET. The memory subsystem features 256×1 KiB banks, interleaved across 16 Tiles in 4 Groups, enabling 1–5 cycle low-latency access. Each Tile integrates four Core Complexes (CCs), each with a 32b RISC-V core, Integer Processing Unit (IPU), Floating Point Sub-System (FP-SS), and Systolic Queue-Linked Register (QLR). A Tile-shared FP division/square-root unit accelerates matrix inversion for MIMO detection.
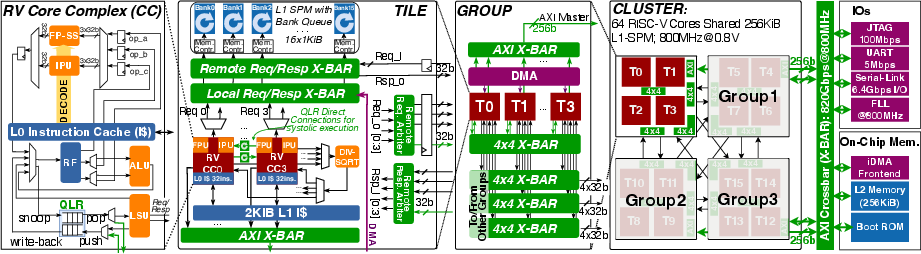
Figure 2: HeartStream's 64 RISC-V cores shared-L1-memory hierarchical design architecture. L1 memory addresses are 32-bit interleaved across banks of 16 Tiles in 4 Groups. Each Tile's cores share an FP division/square-root unit. Core-Complex includes a 32b RISC-V core, IPU, FP-SS, and Systolic QLR.
The die micrograph demonstrates a compact 5 mm² implementation with 65% logic cell utilization in the core area.

Figure 3: Die micrograph and design summary. HeartStream was implemented in GlobalFoundries' 12nm FinFET technology on a 5 mm² die. It achieves a 65% high utilization logic cell placement in the core area.
Systolic Execution and Data Movement
A key innovation is hardware-supported flexible systolic execution with programmable topology. QLRs enable implicit inter-core register-file communication, eliminating explicit memory and control instructions. This is particularly effective for matrix multiplication (MatMul) and complex FFT (CFFT), where data is streamed between cores via QLRs, reducing synchronization and memory access overhead.
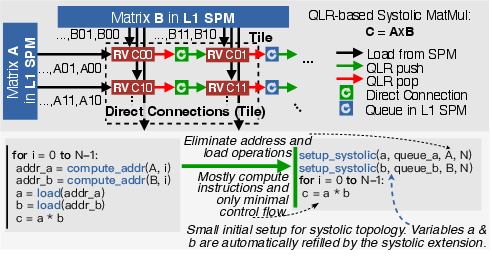
Figure 4: In a systolic MatMul, cores at the edge of the topology fetch from L1 and then forward data through QLR/memory queues, eliminating memory and control instructions; pseudocode shows that implicit inter-core communication eliminates many memory access and control instructions, boosting performance.
HeartStream achieves up to 243 GFLOP/s on complex-valued baseband workloads at 0.8V, with IPCs ranging from 0.52–0.88. On deep learning integer benchmarks (MatMul, Conv2D, DotP), IPCs reach 0.84–0.96 and up to 72 GOP/s. Systolic kernels demonstrate higher compute utilization and reduced overhead instructions.
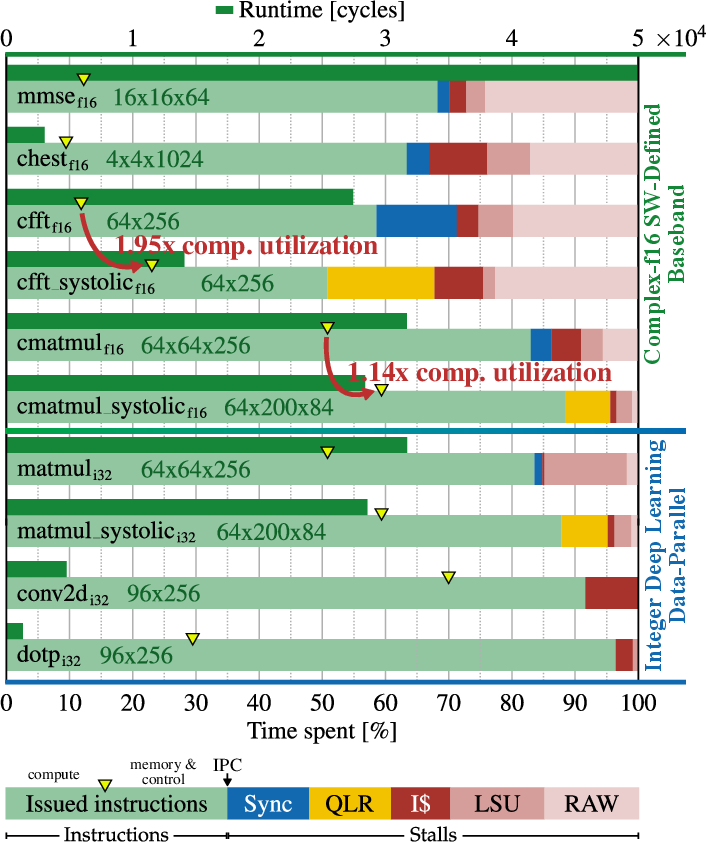
Figure 5: Absolute runtime and instruction/stall cycle fractions for 16-bit complex (real/imaginary) baseband and 32-bit integer deep learning kernels. Systolic kernels achieve higher compute utilization and performance by reducing overhead instructions.
PUSCH processing, a latency-critical baseband task, is efficiently mapped to HeartStream. For a typical TTI with 14 symbols and 1024 subcarriers, the pipeline includes CFFT, MatMul, DMRS-based channel estimation, and MMSE equalization. Systolic extensions yield 50% and 12% runtime reduction for OFDM and beamforming, respectively.
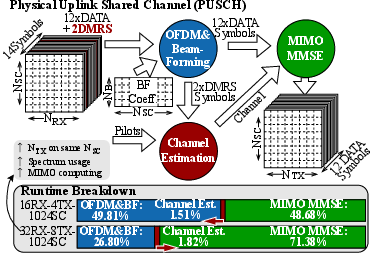
Figure 6: The baseband PUSCH processing steps for a transition time interval with 14 symbols, 1024 Sub-Carries (SC) in 15kHz spacing, and compute runtimes breakdown for different NRX×NTX scenarios.
Energy efficiency is maximized at low-voltage operation (645 MHz @ 0.65V), achieving 33.2 GFLOP/s/W for OFDM and 213 GFLOP/s/W for beamforming, with up to 1.89× improvement due to systolic execution.
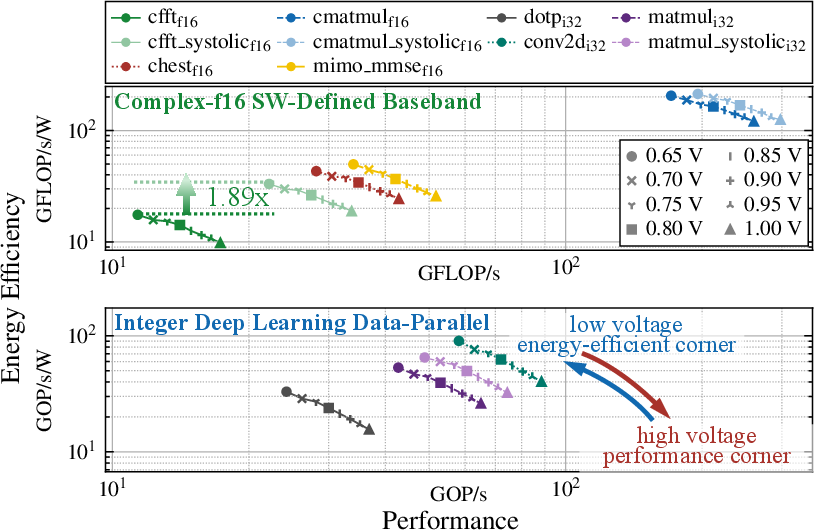
Figure 7: HeartStream's efficiency and performance on key kernels for baseband and deep learning processing. The different core supply voltages target high energy efficiency or high performance. The systolic extension improves energy efficiency up to 1.89×.
Runtime and Quality of Service
HeartStream sustains <4 ms end-to-end latency for uplink processing in 8×8 MIMO scenarios, supporting up to 32 antennas, 8 beams, and 8 users. Runtime and energy efficiency breakdowns for PUSCH steps show that low-voltage operation is preferable for low NRX×NTX, while high-voltage is optimal for high NRX×NTX.
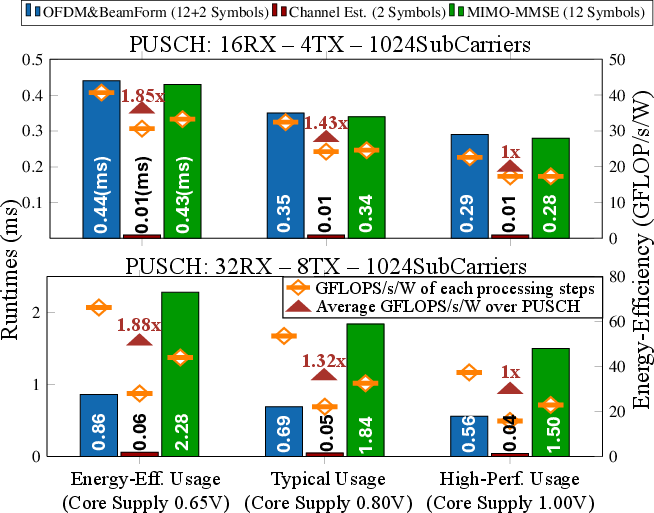
Figure 8: Runtime and energy efficiency breakdown of PUSCH processing steps: low-voltage for low NRX×NTX achieves energy efficiency, and high-voltage for high NRX×NTX achieves high performance.
Mixed-precision 16/32-bit floating-point extensions maintain BER/SNR parity with 64b golden models in 16×16 MIMO MMSE (AWGN channel), ensuring high QoS.
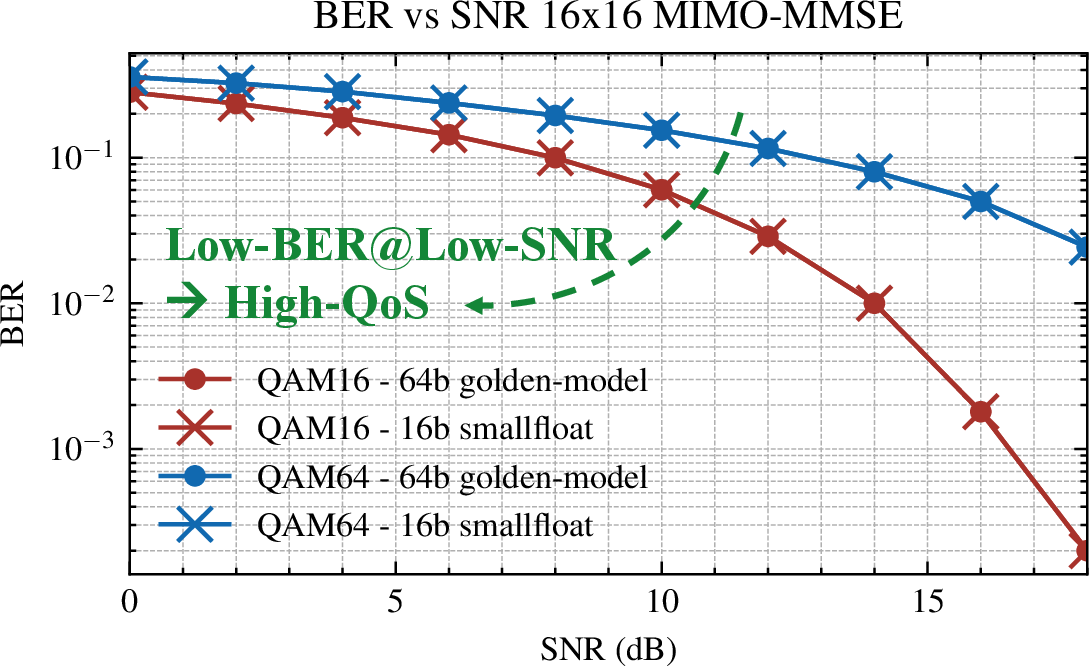
Figure 9: BER vs. SNR of a 16x16 MIMO MMSE (AWGN channel), implemented with mixed-precision 16/32-bit floating-point extensions, yields the same results as the 64b golden model. Lower SNR at a given BER indicates higher Quality of Service (QoS).
Comparison with State-of-the-Art
HeartStream is the first open-source, fully programmable RISC-V O-RAN processor supporting full B5G/6G uplink and deep learning operators. It delivers the highest peak performance (410 GFLOP/s) and competitive throughput/energy efficiency compared to partially programmable and fixed-function ASIC/ASIP designs. Notably, it supports flexible MIMO sizes and diverse network scenarios, unlike prior solutions with inflexible datapaths.
Implementation and Deployment Considerations
HeartStream's open-source RTL and software stack facilitate integration into O-RAN edge deployments. The hierarchical shared-memory architecture and systolic execution model are well-suited for both baseband and AI workloads, enabling rapid adaptation to evolving standards and heterogeneous workloads. The design is compatible with base station power and latency constraints, consuming only 0.68 W at 645 MHz/0.65V, and is scalable for future increases in antenna and user counts.
Implications and Future Directions
HeartStream demonstrates that fully programmable, energy-efficient manycore clusters can meet the stringent requirements of B5G/6G O-RAN, including AI-native processing. The convergence of wireless and AI workloads is enabled by architectural flexibility, mixed-precision support, and systolic execution. Future work may explore scaling to larger clusters, integration with advanced memory technologies (e.g., HBM), and further specialization for emerging AI/ML baseband algorithms.
Conclusion
HeartStream establishes a new reference for programmable, energy-efficient baseband and AI processing in B5G/6G O-RAN. Its architectural innovations—hierarchical shared-memory, systolic execution, and mixed-precision support—yield high performance, flexibility, and energy efficiency, positioning it as a viable platform for next-generation wireless edge deployments and AI-native RAN systems.