- The paper shows that high-frequency paraphrases significantly improve LLM accuracy in tasks such as math reasoning, translation, and commonsense problem solving.
- It introduces a novel methodology combining corpus-based frequency estimation, LLM-driven frequency distillation, and curriculum training to select effective paraphrastic forms.
- Empirical results reveal marked performance gains (up to 30% BLEU/chrF increases) and substantiate a theoretical link to Zipfian distribution properties in neural language models.
Adam's Law: Textual Frequency Law on LLMs
Introduction and Motivation
Adam's Law formulates and empirically validates the Textual Frequency Law (TFL) for LLMs, positing that among semantically equivalent paraphrases, those with higher sentence-level textual frequency are systematically preferred by LLMs during both inference (prompting) and parameter adaptation (fine-tuning). This runs counter to the traditional focus in curriculum learning, which prioritizes ease (and often, lower complexity as a surrogate for frequency) over frequency per se, and presents a controlled, corpus-agnostic approach for frequency computation—a necessity given closed-source LLM training sets.
The work identifies the gap between resource constraints and paraphrase augmentation: although including diverse paraphrases is useful, not all paraphrastic variants are equally effective when training or using LLMs. The central hypothesis is that high-frequency paraphrastic forms are both more prevalent in pretraining corpora and more directly accessible to LLMs' internal representations, as motivated by known psycholinguistic and neurocognitive evidence as well as distributions observed in neural LMs.
Principle and Framework
The framework consists of three key procedural components:
- Textual Frequency Law (TFL): Prefer the paraphrase (for prompting and fine-tuning) with the highest sentence-level frequency, defined (in the absence of training data) via a geometric mean of constituent word frequencies from large on-line corpora.
- Textual Frequency Distillation (TFD): Improve corpus-derived sentence frequency estimation by leveraging LLMs to generate completions (story continuations) over the corpus; the LLM-generated set refines the empirical sentence frequency estimate, facilitating adaptation to model-specific vocabulary distributions.
- Curriculum Textual Frequency Training (CTFT): Fine-tune the LLM using training instances sorted by increasing sentence frequency, operationalizing a curriculum from low- to high-frequency, thus leveraging the benefits of curriculum learning methodologies while incorporating frequency as the organizing principle.
A schematic view of the overall pipeline, as well as a toy example, is provided:
Figure 1: Schematic of the Textual Frequency Law pipeline: paraphrase rephrasing, frequency estimation, and selection for LLM prompting/fine-tuning.
Methodological Implementation
Frequency Estimation
Given closed-source pretraining corpora, frequency statistics are extracted from web-scale resources (wordfreq, ParaCrawl, etc.) using Zipf normalization. Sentence-level frequency is computed as the geometric mean across the frequency of constituent words, abstracting from position and bigram dependencies.
TFD enhances these statistics by using the LLM itself to continue each candidate sentence and then recalculates frequencies from these synthetic continuations, with convex combination weighted by a confidence hyperparameter and an adjustment factor when corpus statistics are vacuous.
Dataset Construction
The Textual Frequency Paired Dataset (TFPD) is curated by taking math reasoning (GSM8K), translation (FLORES-200), and commonsense reasoning (CommonsenseQA) samples, auto-generating 20 paraphrases per instance via GPT-4o-mini, and human vetting for cross-meaning equivalence. Each instance yields both a high-frequency and low-frequency paraphrase.
Empirical Evidence
Prompting: Math Reasoning
Applying high-frequency paraphrases in prompts yields consistent accuracy gains across DeepSeek-V3, GPT-4o-mini, and LlaMA3.3-70B-Instruct: for example, from 63.55% to 71.54% (DeepSeek-V3), 60.70% to 68.70% (GPT-4o-mini), and 80.49% to 88.75% (LlaMA3.3-70B-Instruct) on GSM8K-style tasks. Analysis demonstrates that the high-frequency formulation never degrades correct completions, thus only correcting model failures under low-frequency expressions.
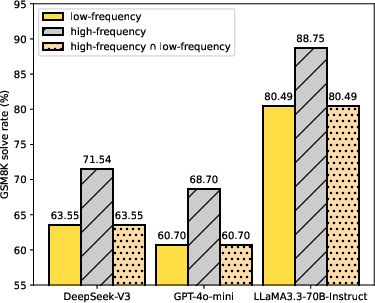
Figure 2: High-frequency prompts yield systematically higher accuracy on math reasoning, and performance is never degraded compared to low-frequency prompts.
Prompting: Machine Translation
Translation from English into 100 languages (via FLORES-200) demonstrates robust gains: for DeepSeek-V3, 99/100 language pairs are improved for BLEU, with 63/99 seeing >1 point and 31/99 >3 point increases. No degradation exceeds 1 BLEU point, and gains are consistent for chrF and COMET scores, as well as with GPT-4o-mini.
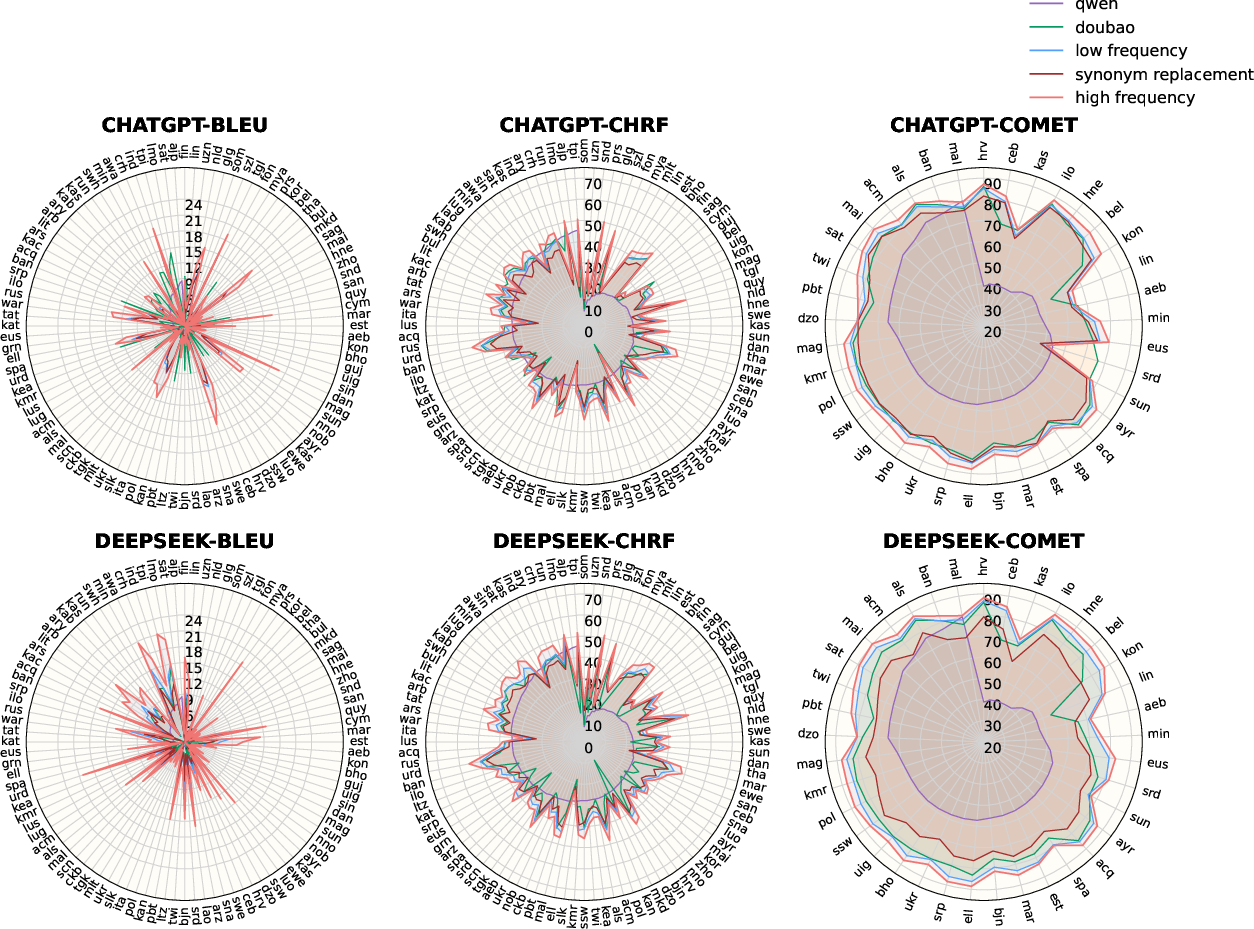
Figure 3: High-frequency formulations uniformly confer translation quality improvements across a typologically diverse sample of languages.
Prompting: Commonsense and Agentic Tasks
Improvements in accuracy, with high-frequency variants outperforming low-frequency paraphrases, are replicated on CommonsenseQA and tool-calling tasks.
Fine-Tuning and Curriculum Application
Fine-tuning with high-frequency partitions outperforms both low-frequency and randomly-mixed sets—sometimes exceeding fine-tuning on the original (unpaired) sentences. BLEU and chrF increases can reach 12–30%, and curriculum-sorted training (CTFT) further optimizes learning efficiency and final accuracy.
Ablation and Data Scaling
Ablation of TFD consistently reduces performance, especially for languages where frequency estimation from online corpora is sparse or misaligned with LLM coverage. More comprehensive TFD data incorporation increases gains, confirming the TFD's critical role.
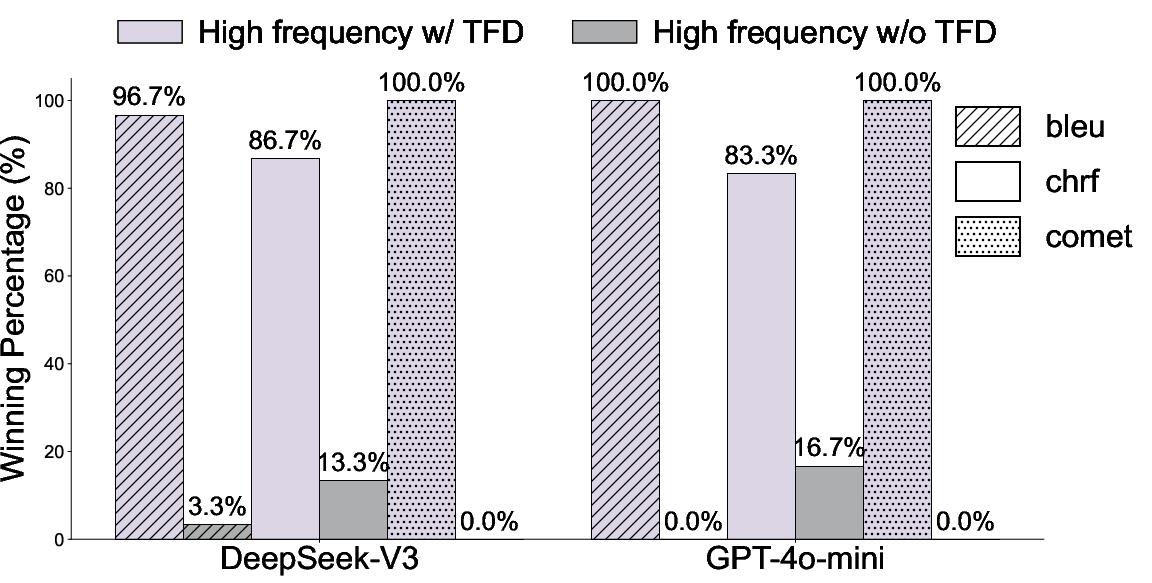
Figure 4: Ablation on TFD confirms its necessary contribution across metrics (BLEU, chrF, COMET).
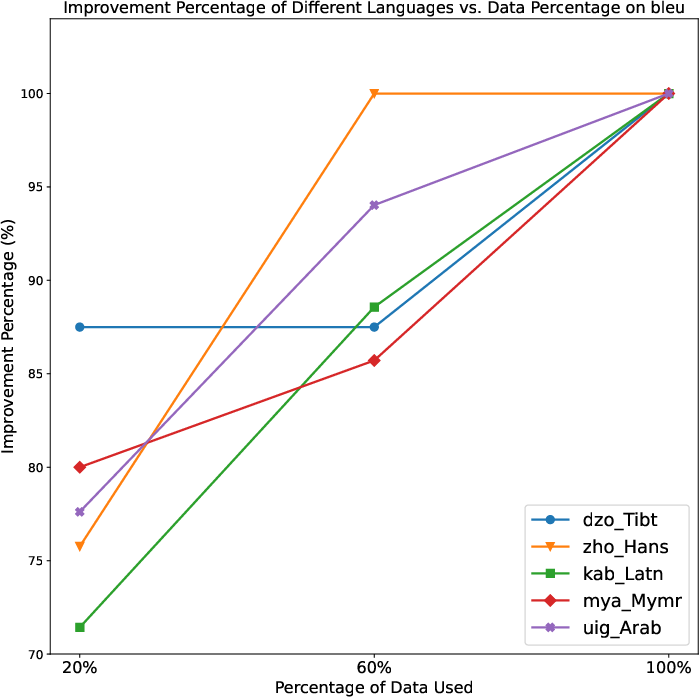
Figure 5: Gains scale monotonically with the amount of TFD-augmented data exploited.
Case Studies
Multiple qualitative analyses show the selection of paraphrastic variants with higher LLM alignment and accuracy for both translation and reasoning, identified by bolded outcomes in case studies.
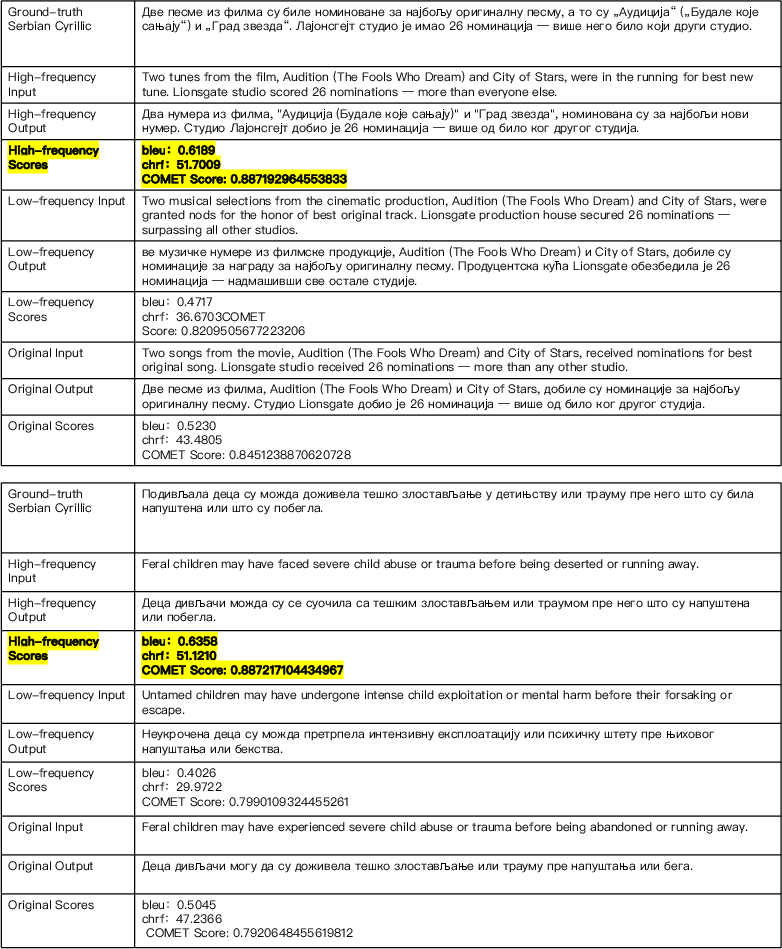
Figure 6: Selected case studies demonstrate where high-frequency prompts/finetuning not only produce more accurate outputs but also more idiomatic, LLM-favored continuations.
Theoretical Underpinning
A formal proof is provided showing that, under assumptions approximating Zipfian marginal distributions and bounded divergence between model and empirical frequencies, the sequence-level negative log-likelihood for a paraphrase is monotonic in its geometric-mean word frequency. Thus, higher sentence frequency guarantees (to within model adaptation errors) lower expected loss and, by extension, higher model accessibility and performance. The formal proof (presented in the Appendix) exposes all limitations—including those related to margin size, model errors for low-frequency tokens, and the approximation inherent in unigram-based sentence scoring.
Implications and Future Directions
This work has several practical and theoretical ramifications:
- Prompt Design: For maximal accuracy in LLM inference, choose paraphrastic forms with maximal corpus-derived frequency, especially for low-resource settings or tasks sensitive to phrasing, such as translation and multi-step reasoning.
- Data Budget Optimization: In resource-constrained fine-tuning or augmentation, prioritize high-frequency paraphrases for greater robustness and model alignment, rather than indiscriminately augmenting with all paraphrastic variants.
- Curriculum Learning: Incorporating frequency as a curriculum dimension (ordered fine-tuning) yields further improvements, orthogonal to data complexity or length-driven curricula. Frequency and complexity are empirically decorrelated.
- Language and Task Generalization: Gains are stable across languages, including those with sparsity in large web corpora, provided TFD is leveraged to close coverage gaps.
- Theory: The results illuminate Zipfian structure not just as a property of human language, but as a control variable for neural sequence learning dynamics in LLMs—driving efficient, loss-minimized generalization.
- Limits: Costly story-completion for frequency distillation poses computational challenges when scaling, but the theoretical necessity and empirical payoff are clear.
Conclusion
Adam's Law advances a precise, empirically validated Textual Frequency Law for LLMs: when semantic equivalence holds, high-frequency paraphrases should be preferred for both prompting and fine-tuning, yielding monotonic and often dramatic improvements in downstream accuracy and translation performance. The methodological toolkit—combining corpus-based estimation, LLM-based distillation, and curriculum sorting—enables practitioners to exploit this law independent of access to closed pretraining corpora. The result is a robust, theoretically grounded strategy for optimizing the effectiveness of LLM-centric NLP pipelines in a resource-aware and linguistically principled manner.
(2604.02176)