BraiNCA: brain-inspired neural cellular automata and applications to morphogenesis and motor control
Abstract: Most of the Neural Cellular Automata (NCAs) defined in the literature have a common theme: they are based on regular grids with a Moore neighborhood (one-hop neighbour). They do not take into account long-range connections and more complex topologies as we can find in the brain. In this paper, we introduce BraiNCA, a brain-inspired NCA with an attention layer, long-range connections and complex topology. BraiNCAs shows better results in terms of robustness and speed of learning on the two tasks compared to Vanilla NCAs establishing that incorporating attention-based message selection together with explicit long-range edges can yield more sample-efficient and damage-tolerant self-organization than purely local, grid-based update rules. These results support the hypothesis that, for tasks requiring distributed coordination over extended spatial and temporal scales, the choice of interaction topology and the ability to dynamically route information will impact the robustness and speed of learning of an NCA. More broadly, BraiNCA provides brain-inspired NCA formulation that preserves the decentralized local update principle while better reflecting non-local connectivity patterns, making it a promising substrate for studying collective computation under biologically-realistic network structure and evolving cognitive substrates.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces BraiNCA, a new kind of computer model that takes inspiration from how the brain is wired. It helps lots of simple “cells” work together to build shapes (like a smiley face) and to control a robot (a tiny rocket landing on the Moon in a game). The big idea is to let cells talk not only to nearby neighbors but also to far-away partners, and to let them “pay attention” to the most important messages—just like parts of the brain do.
What questions were the researchers trying to answer?
- Can adding brain-like features—such as long-range connections and attention—help groups of simple units organize themselves faster and more reliably?
- Do these features make a difference in two very different tasks:
- Morphogenesis: cells self-organize into a target pattern.
- Motor control: cells collectively control actions to land a spacecraft safely.
- Does the way the network is laid out in space (“topology,” like having regions for different actions) make learning faster and more stable?
How did they study it?
The team built a system called BraiNCA. Here’s how it works, in everyday terms:
- Think of a grid of little “cells,” like pixels with tiny brains. Each cell has a small memory and can send/receive messages.
- In older models, a cell only listened to immediate neighbors. In BraiNCA, cells also have:
- Long-range connections: they can get messages from a few far-away cells, like shortcuts across the grid.
- Attention: instead of averaging everything they hear, cells learn to focus on the most useful messages, similar to paying attention to the friend who has the best info.
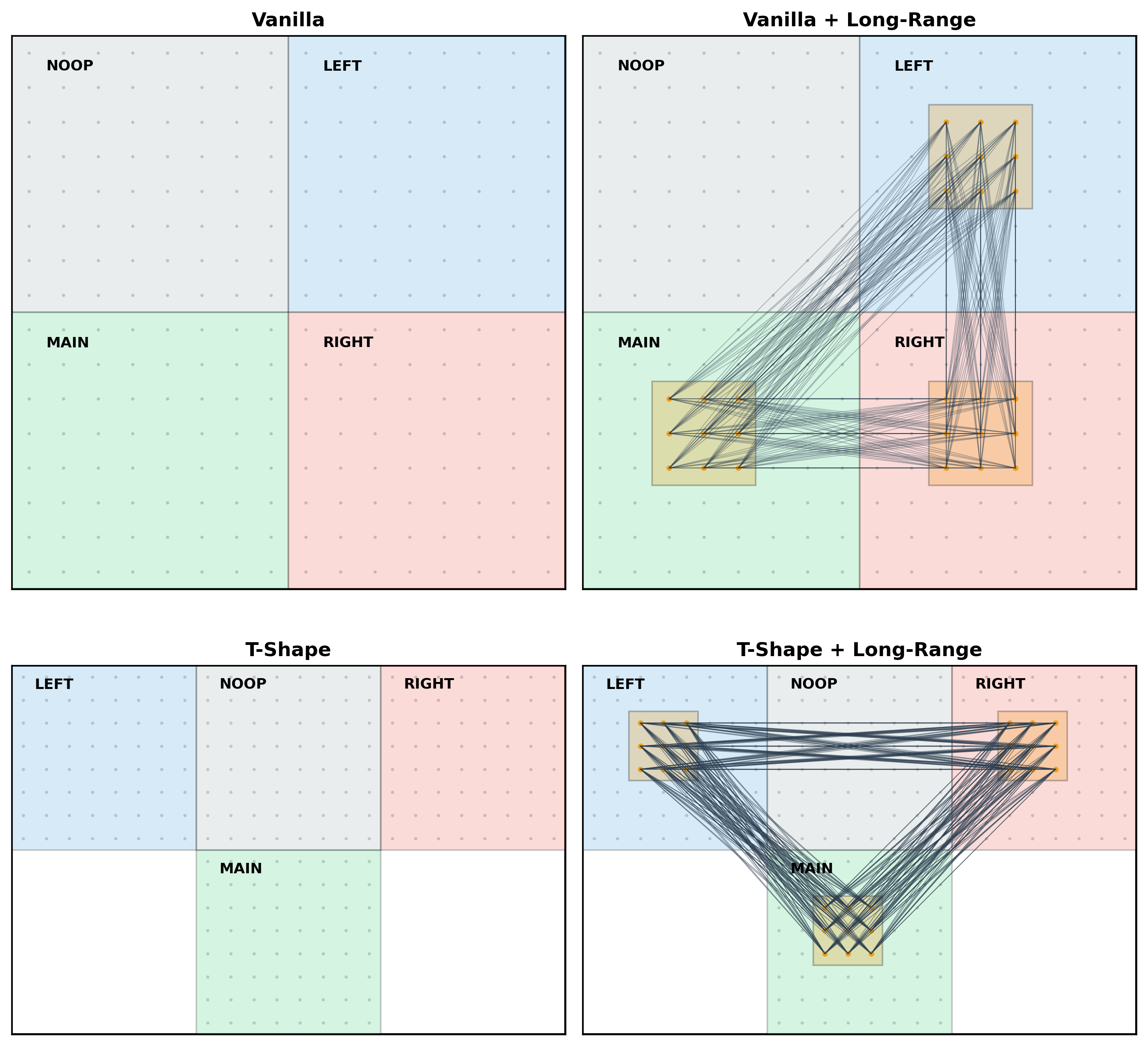
- The “topology” (layout) can be a regular grid or a more structured shape, like a “T” with regions that each vote for different actions—similar to how the brain has areas that specialize in different movements.
They tested BraiNCA on two tasks:
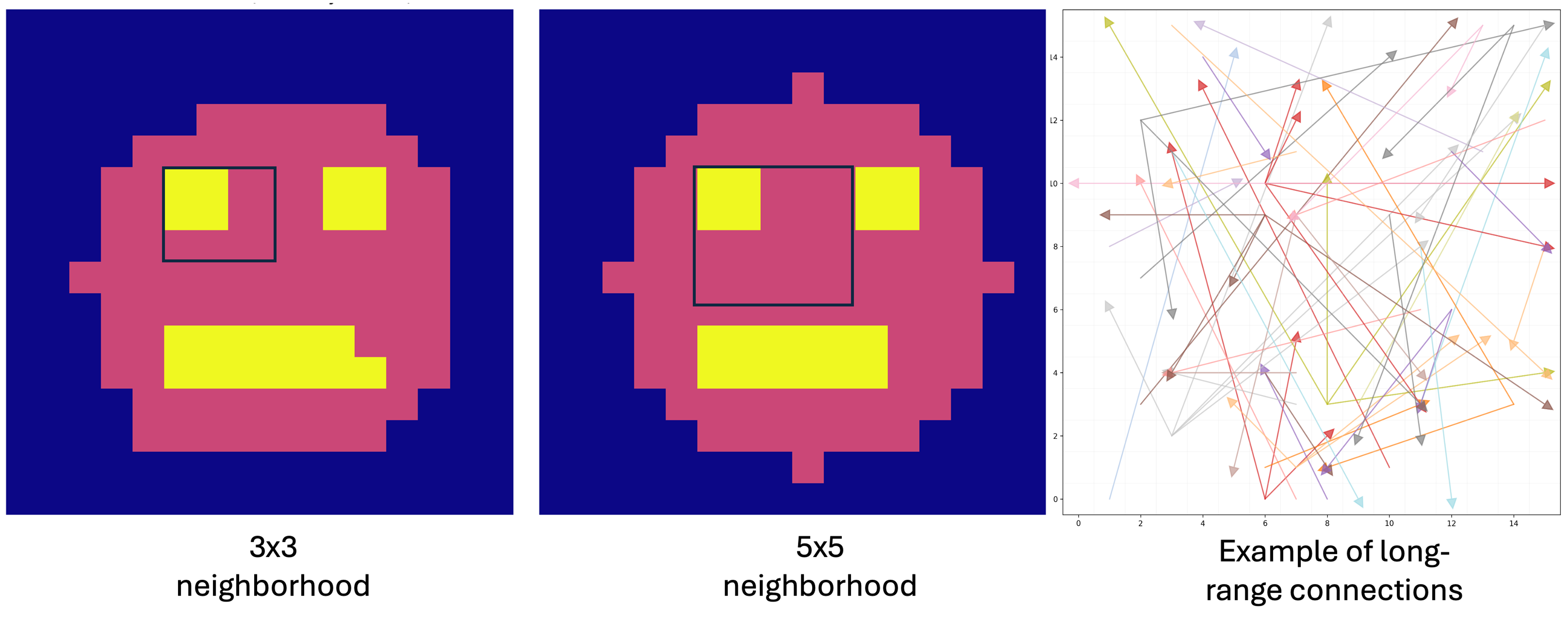
- Morphogenesis (pattern formation): 256 cells on a 16×16 grid had to grow into a smiley face pattern starting from random states. The model “learns” by comparing the final pattern to the target and improving over many tries.
- Lunar Lander (robot control): groups of cells saw the rocket’s state (position, speed, angle) and each voted whether to “fire” for one of four actions (no-op, left, main, right). The final action was chosen by combining votes from designated regions. The model learned by trying to maximize total reward (safe landing, minimal fuel, no crash) over many games.
In simple terms: the researchers gave the cells brain-like tools and different layouts, then checked whether that helped them learn faster and perform better.
What did they find, and why is it important?
For morphogenesis (building a pattern):
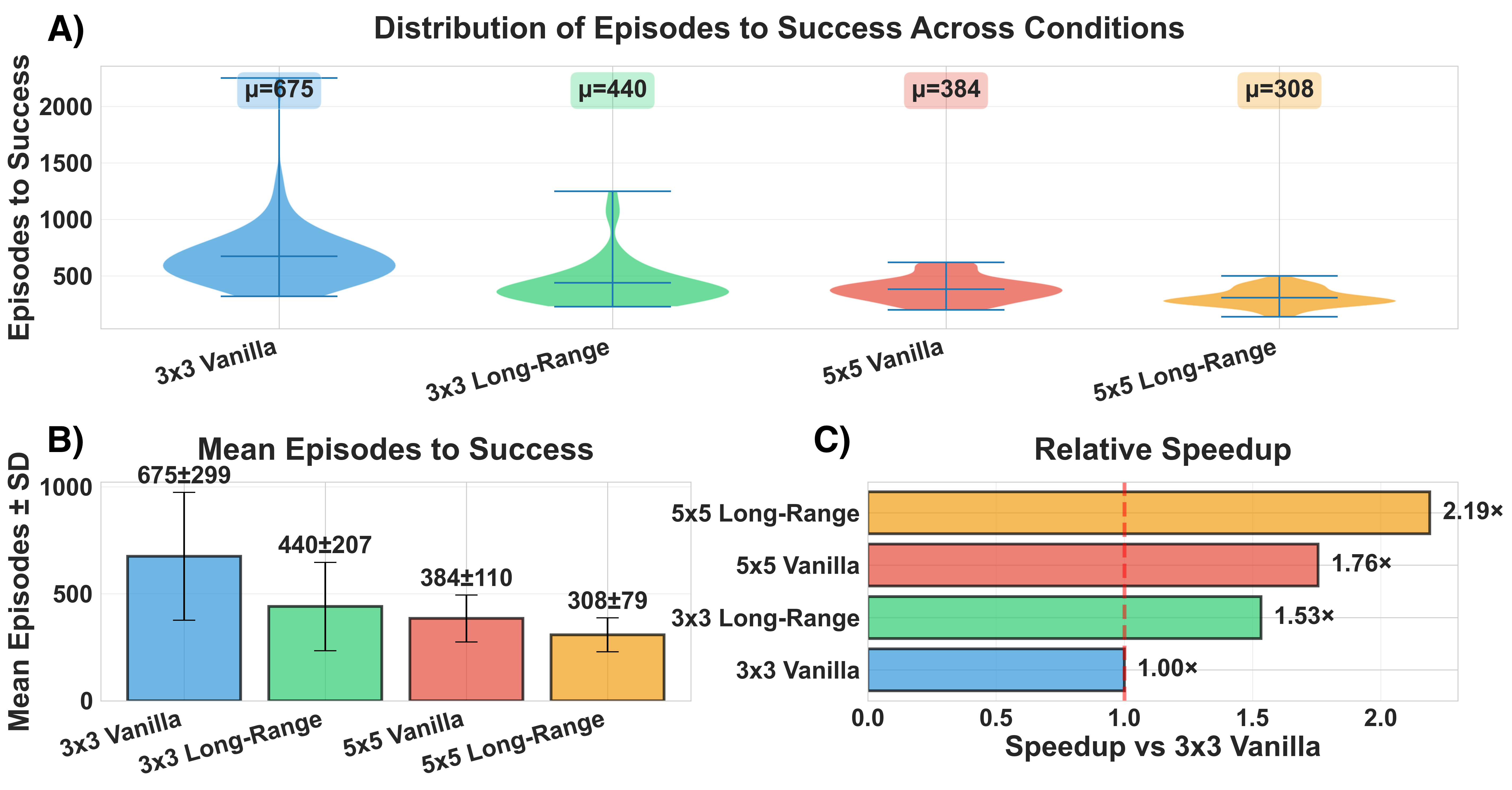
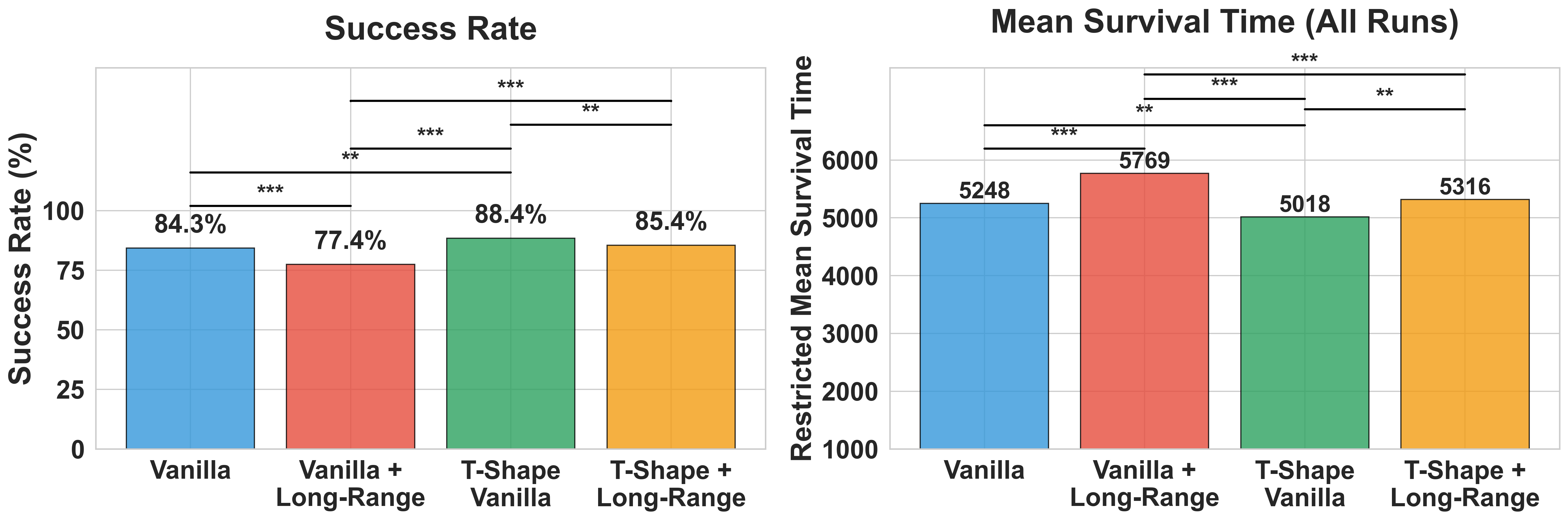
- Adding long-range connections helped the cells learn the target pattern faster.
- Letting each cell listen to a larger local neighborhood also sped up learning.
- Combining both (bigger neighborhood + long-range links) gave the best speed-up.
- All versions eventually succeeded, but the brain-inspired version learned noticeably faster.
Why it matters: Real biological tissues often use both nearby and far-away signaling. This result supports the idea that these features make self-organization more efficient.
For motor control (lunar lander):
- A “somatotopic” layout—dividing the grid into regions that each specialize in one action (NOOP/LEFT/MAIN/RIGHT) and arranging them in a T-shape—made learning faster and more reliable than the plain grid.
- Simply adding long-range links in this task did not always help; in fact, it sometimes made performance less robust than the basic setup.
- The best improvement came from the organized, region-based topology (like the brain’s motor map), not just from long-range shortcuts.
Why it matters: How you arrange parts of a system can make a big difference. Organizing the model into specialized regions—like how the brain maps body movements—can make learning and control more stable and quicker.
What does this mean going forward?
- Design matters: For tasks where many units must coordinate over space and time, using brain-like features—attention, a few long-range links, and region-based layouts—can speed up learning and improve reliability.
- One size doesn’t fit all: Long-range connections helped a lot in the pattern-building task but weren’t always helpful for the lunar lander. The “right” wiring may depend on the problem.
- A step toward brain-like computing: BraiNCA keeps the idea of simple local rules but adds realistic brain-like wiring. This makes it a promising tool to study how complex, intelligent behavior can emerge from many small parts working together—useful for biology, robotics, and AI.
In short, the paper shows that giving simple systems brain-inspired ways to communicate and organize can make them learn faster and work more robustly, especially when their “wiring” matches the task.
Knowledge Gaps
Below is a consolidated list of specific knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items are phrased to be actionable for future research.
- Baseline coverage: No empirical comparison against graph-based NCA variants (e.g., Graph-CA/GNCA/E(n)-equivariant GNCA) or non-NCA baselines (standard MLP/GRU/Transformer policies for LunarLander), leaving unclear whether BraiNCA’s gains exceed those achievable by existing graph/message-passing models.
- Fairness of comparisons: Parameter counts, message bandwidth, and total neighbor counts were not controlled across conditions; improvements from long-range links might reflect increased capacity/communication rather than topology/attention per se.
- Attention mechanism ablations: The contribution of attention versus simply larger neighborhoods or more hidden channels remains unquantified; no ablations removing attention, using multi-head attention, or replacing attention with simpler aggregators.
- Long-range topology design: Long-range edges are hand-crafted (LunarLander) or scale-free-inspired random (morphogenesis); the paper does not systematically vary graph statistics (e.g., clustering coefficient, path length, modularity, rich-club coefficient) or compare small-world vs. scale-free vs. modular designs under a fixed communication budget.
- Learning the wiring: Long-range connectivity is fixed; there is no attempt to jointly learn, grow, or prune edges (e.g., differentiable edge gating, plasticity rules, neuroevolution) and compare to fixed-topology BraiNCA.
- Communication cost modeling: No modeling of wiring economy, communication latency, bandwidth limits, or energy cost; no regularization to encourage biologically inspired sparse/short connections or to test robustness under communication constraints.
- Scalability: Experiments are confined to small 2D grids (16×16) and a single agent control task; there is no evaluation on larger grids (e.g., 64×64+), 3D morphogenesis, irregular/non-grid graphs, or multi-agent settings.
- Generalization in morphogenesis: Only a simple 3-class “smiley” target is used; no tests on families of shapes, continuous target variations, unseen scale/rotation, out-of-distribution patterns, or regeneration after damage.
- Robustness in morphogenesis: No evaluation of damage tolerance (cell death/lesions), asynchronous updates, message dropout, noisy initializations, or environmental perturbations during development.
- Developmental dynamics: Loss is computed only at the final timestep; stability of intermediate dynamics, convergence to attractors, and resistance to perturbations during growth remain uncharacterized.
- Reason for LR degradation in control: Long-range links hurt LunarLander robustness/speed in some settings; the mechanism is unclear. No sweeps over LR density, edge placement, or gating strategies to diagnose when/why LR helps versus harms.
- Action readout design: The spatially partitioned action aggregation (quadrants/T-shape) is hand-designed; sensitivity to the partition, alternative readouts (learned pooling, global readout, graph readout), and extension to continuous control are not evaluated.
- Observation broadcast: All cells receive full observations in LunarLander; the benefits/limitations under partial/local observations, sensor noise, or restricted broadcast are not explored.
- Credit assignment and RL algorithms: Training uses REINFORCE without a baseline/critic; no comparison to actor-critic methods (e.g., A2C/PPO/SAC), advantages normalization schemes, or variance-reduction techniques that could improve sample efficiency and stability.
- Number of internal NCA steps: The effect of varying internal update steps per environment timestep (n_steps=3 fixed) on performance, stability, and compute cost is not studied.
- Compute/efficiency analysis: No profiling of wall-clock time, memory, FLOPs, or training-time energy for attention and long-range messaging relative to vanilla NCAs; scaling laws and efficiency trade-offs are unknown.
- Hyperparameter sensitivity: No systematic sensitivity analysis for attention width, hidden channels, GRU size, LR degree, initialization, optimizer settings, or noise levels; reproducibility across broader seeds/settings is unquantified.
- Asynchrony: Updates are synchronous; the impact of asynchronous or event-driven updates (closer to biological networks) on performance and robustness is not assessed.
- Interpretability: Attention weights and long-range message patterns are not analyzed; no causal/graph-theoretic analysis of information routing, hub roles, or emergent modularity to explain observed performance differences.
- Biological grounding: Although framed as brain-inspired, the generated topologies are not quantitatively evaluated against connectomic statistics (small-worldness, degree distributions, rich-club organization) or wiring economy objectives.
- Joint morphology–connectivity development: Proposed as future work, but not implemented; no experiments where long-range connectivity grows and reorganizes concurrently with state dynamics, nor benchmarks for such co-development.
- Stability and failure modes: No characterization of oscillations, chaotic dynamics, or failure cases (e.g., when attention saturates or long-range links induce interference); no diagnostics for unsuccessful runs.
- Transfer learning: No tests of cross-task transfer (e.g., from one morphogenetic target to another), multi-task training, or policy transfer from one topology to another.
- Boundary conditions/topology variation: Only grid and T-shape topologies are considered; no tests on different boundary conditions (toroidal, reflective), hierarchical modular layouts, or task-matched topographic maps beyond the T-shape.
- Loss design in morphogenesis: Training supervises only visible channels at the final step; the effect of intermediate supervision, auxiliary self-prediction (predictive coding), or curriculum schedules on learning and robustness is unknown.
- Noise and lesions in control: Robustness in LunarLander is tested under wind/turbulence, but not under sensor dropout, actuator faults, cell/edge lesions, or communication noise at inference time.
These gaps suggest concrete next steps: benchmark against graph-NCA and standard RL baselines under matched budgets; ablate attention/GRU/long-range contributions with controlled neighbor/parameter counts; learn and regularize connectivity under communication costs; scale to larger, irregular, and 3D substrates; stress-test robustness (damage, asynchrony, partial observation); analyze attention and graph statistics; and explore alternative readouts and RL algorithms for improved sample efficiency.
Practical Applications
Practical Applications of BraiNCA
BraiNCA contributes three concrete innovations that shape its applicability: (i) attention-based message selection among neighbors, (ii) explicit, sparse long-range connectivity layered on top of local neighborhoods, and (iii) flexible, non-grid topologies (including somatotopic layouts for control). Empirically, these lead to faster learning and increased robustness for morphogenesis, and better robustness/speed for motor control when spatial-functional topology is aligned with the task. The GitHub repository enables immediate experimentation and integration.
Below are application opportunities derived from these findings, grouped by time horizon.
Immediate Applications
The following use cases can be deployed or prototyped now with the provided code and standard ML stacks.
- Robotics and Control
- Decentralized controllers for soft robots and modular robots
- Sector: robotics
- What: Replace monolithic policies with spatially distributed NCA controllers that coordinate via local rules plus sparse long-range “hub” links; use somatotopic zoning to map body regions to action primitives (e.g., grasp zones, locomotion zones).
- Tools/products/workflows: NCA-Controller SDK integrating Gymnasium-like environments; template for “action regions” and attention-tuned long-range links; on-robot inference via lightweight GRU+MLP per module.
- Assumptions/dependencies: Sim2real transfer requires calibration; long-range topology must match robot morphology; safety guards needed for RL-derived policies.
- Swarm robotics behaviors under turbulence/noise
- Sector: robotics, defense, logistics
- What: Use BraiNCA to achieve formation-keeping, landing/charging coordination, and task allocation with improved robustness due to attention gating and small-world links.
- Tools/products/workflows: Swarm control policies trained with stochastic perturbations; mission planner that injects/rewires sparse long-range edges (e.g., via leader drones).
- Assumptions/dependencies: Communication constraints limit effective long-range degree; requires on-board compute or edge aggregation.
- Simulation for Developmental Biology and Tissue Engineering
- In-silico morphogenesis planning and hypothesis generation
- Sector: healthcare, life sciences R&D
- What: Use BraiNCA to prototype bioelectric/topological communication strategies (e.g., gap-junction-like multi-hop signaling) that speed or stabilize pattern formation; compare local-only vs long-range-augmented signaling.
- Tools/products/workflows: MorphoSim notebooks to design/fit NCA rules to target tissue patterns and run robustness analyses; parameter sweeps over long-range degree and attention.
- Assumptions/dependencies: Abstract mapping to real tissues; needs experimental validation and domain constraints (diffusion, mechano-chemical cues).
- Distributed Systems and Edge/IoT Coordination
- Self-organizing coordination with small-world overlays
- Sector: software, telecom/IoT
- What: Apply BraiNCA-style local rules plus few long-range edges to speed consensus, routing, or load balancing in sensor nets and edge clusters.
- Tools/products/workflows: Drop-in “attention-gated neighbor aggregation” primitive for graph-based controllers; small-world topology generator with rich-club hubs.
- Assumptions/dependencies: Must respect bandwidth/latency constraints; stability proofs desirable for production networks.
- Game AI and Procedural Content
- Robust agent controllers and pattern-generating systems
- Sector: gaming, simulation, creative tools
- What: Use somatotopic BraiNCA controllers for agents; use morphogenesis NCAs for pattern generation (terrain, decals) with built-in damage tolerance and regeneration.
- Tools/products/workflows: Unity/Unreal plugins for NCA-based agents; content-authoring tools to specify target patterns and train NCAs to self-assemble them.
- Assumptions/dependencies: Runtime budgets must accommodate per-step NCA updates; tool integration needed.
- Education and Training
- Interactive teaching modules on emergence and brain-inspired computing
- Sector: education
- What: Use BraiNCA to demonstrate how connectivity and attention influence emergent behaviors; labs comparing vanilla NCA vs long-range/attention variants.
- Tools/products/workflows: Classroom-ready notebooks; sliders to vary neighborhood, long-range degree, and attention strength; targeted curricula in complex systems/AI.
- Assumptions/dependencies: Simplified visualizations and stable defaults help non-experts.
- AI for Industrial Process Control (Simulation-first)
- Decentralized control policies for multi-zone plants
- Sector: manufacturing, process control
- What: Map plant zones to spatial regions and adopt somatotopic action mapping; use few long-range supervisory links to coordinate across zones.
- Tools/products/workflows: Digital twin integration; BraiNCA policies trained under disturbances; monitoring of region-level action logits.
- Assumptions/dependencies: Certification/safety barriers; careful sandboxing before deployment.
- Research Tooling for ML
- Benchmarks and ablations on topology-aware NCAs
- Sector: academia, software
- What: Use repository to benchmark message gating and long-range edges on new tasks (e.g., ARC-like reasoning, graph tasks).
- Tools/products/workflows: Automated sweeps over topology generators (scale-free, small-world), ablation runners, survival-analysis dashboards for convergence.
- Assumptions/dependencies: Compute budget for large sweeps; task-specific metrics.
Long-Term Applications
These require further research, scaling, safety validation, or hardware support.
- Regenerative Medicine and Bioelectric Interventions
- Designing stimulation protocols and “morphological programs”
- Sector: healthcare, medical devices
- What: Use BraiNCA-derived communication motifs to propose electrode placements/temporal patterns that guide regeneration or wound healing by stabilizing desired tissue attractors.
- Tools/products/workflows: Closed-loop therapy planners that simulate tissue-level NCAs with learned attention and long-range signaling; optimization over safety/regulatory constraints.
- Assumptions/dependencies: Translational biology; accurate biophysical mapping from NCA channels to real ion flows/morphogen gradients; clinical trials and regulatory approval.
- Neuromorphic and On-device Distributed Intelligence
- NCA-on-chip for energy-efficient control
- Sector: hardware, robotics, IoT
- What: Implement attention-gated local rules and sparse long-range links on neuromorphic or low-power accelerators to enable always-on, self-organizing control.
- Tools/products/workflows: Compiler from BraiNCA graphs to spiking/event-driven substrates; co-design of topology with hardware routing; formal verification of stability.
- Assumptions/dependencies: Hardware support for dynamic routing/attention; local learning rules or off-line training with on-device inference.
- Urban-Scale Coordination
- Traffic lights, UAV corridors, and emergency response
- Sector: smart cities, transportation, public safety
- What: Deploy local NCAs at intersections/waypoints with limited long-range “hub” nodes to improve convergence under disruptions; somatotopic zoning for corridor-specific actions.
- Tools/products/workflows: Digital twins; staged pilots in controlled districts; resilience KPIs; interfaces for human override.
- Assumptions/dependencies: Interoperability with legacy infrastructure; cybersecurity; policy and public acceptance.
- Smart Grid and Energy Systems
- Self-healing and demand-response via small-world overlays
- Sector: energy
- What: Use localized control with sparse supervisory links to coordinate load shedding, storage dispatch, and islanding strategies.
- Tools/products/workflows: Grid simulators with BraiNCA controllers; contingency drills; integration with SCADA; certification processes.
- Assumptions/dependencies: Regulatory compliance; rigorous stability margins; adversarial robustness.
- Autonomous Space Systems
- Distributed landing and docking controllers
- Sector: aerospace
- What: Extend the Lunar Lander proof-of-concept to real-time, damage-tolerant control for landing/docking using spatial action mapping with redundancy.
- Tools/products/workflows: High-fidelity simulators; radiation-tolerant hardware for inference; formal methods for safety guarantees.
- Assumptions/dependencies: Extensive verification/validation; mission-specific constraints; explainability requirements.
- Self-organizing Materials and Morphogenetic Fabrication
- Material systems that “grow” target shapes
- Sector: advanced manufacturing, materials
- What: Embed local update rules and communication pathways into responsive materials that self-assemble or repair patterns.
- Tools/products/workflows: Co-design of chemical/electrical signaling pathways with NCA policies; 4D printing workflows; in-situ sensing for feedback.
- Assumptions/dependencies: Material platforms that support programmable coupling; safety and durability.
- Policy and Governance of Distributed AI
- Standards for safety-testing self-organizing controllers
- Sector: policy/regulation
- What: Develop test suites and certification criteria for topology-aware, attention-based distributed controllers (stress tests, fault injection, adversarial perturbations).
- Tools/products/workflows: Open benchmarks; reporting standards (topology specs, long-range degree, attention mechanisms); incident response playbooks.
- Assumptions/dependencies: Cross-industry coordination; traceability of emergent behavior; auditing tools.
- Advanced Cognitive Substrates and Adaptive Networks
- Evolving task-aligned topologies and long-range wiring
- Sector: AI research, enterprise software
- What: Learn not only cell rules but the connectivity itself (growing/rewiring graphs) to create adaptive, modular “cognitive tissues” for complex tasks (reasoning, planning).
- Tools/products/workflows: Joint optimization of rules and graphs; continual learning pipelines; safety filters for topology changes.
- Assumptions/dependencies: Stable training procedures; catastrophic interference controls; compute for co-evolution.
Cross-cutting Assumptions and Dependencies
- Task fit: Gains are most pronounced when tasks require distributed coordination over extended spatial/temporal scales; benefits may be limited on purely local problems.
- Topology matters: Long-range links help in morphogenesis but can hurt in control if mismatched; topology must align with function (e.g., somatotopy).
- Training stability: REINFORCE and BPTT were used; scaling may need advanced RL (actor-critic), curriculum learning, or regularization to avoid instability.
- Resource constraints: Attention adds compute and memory vs vanilla local aggregation; deployment on constrained hardware needs pruning/quantization.
- Safety and verifiability: Emergent behaviors demand monitoring, fail-safes, and formal analyses—especially in safety-critical sectors.
- Data/Sim fidelity: Biological and physical transfer requires validated models; for real-world control, high-fidelity simulators and domain randomization mitigate sim2real gaps.
- Governance: For policy-facing deployments, auditability and transparency of topology and message routing will be necessary.
These applications build directly on BraiNCA’s demonstrated advantages—attention-based message selection, explicit long-range connectivity, and task-aligned topology—while recognizing that careful topology design and safety validation are critical for real-world use. The public codebase provides a starting point for both immediate prototyping and longer-term translational programs.
Glossary
- Adam optimizer: A stochastic gradient-based optimization algorithm that adapts learning rates per parameter using estimates of first and second moments. "parameters updated via backpropagation through time using the Adam optimizer with learning rate , , and ."
- adjacency-defined neighborhood: In graph-based models, the set of neighbors determined by the edges of the adjacency graph, not by spatial proximity. "replace the lattice with an arbitrary interaction graph, where each node updates from its adjacency-defined neighborhood"
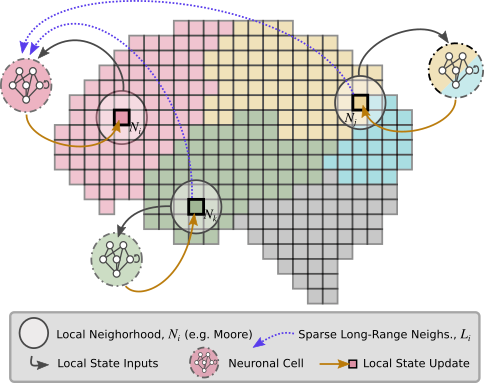
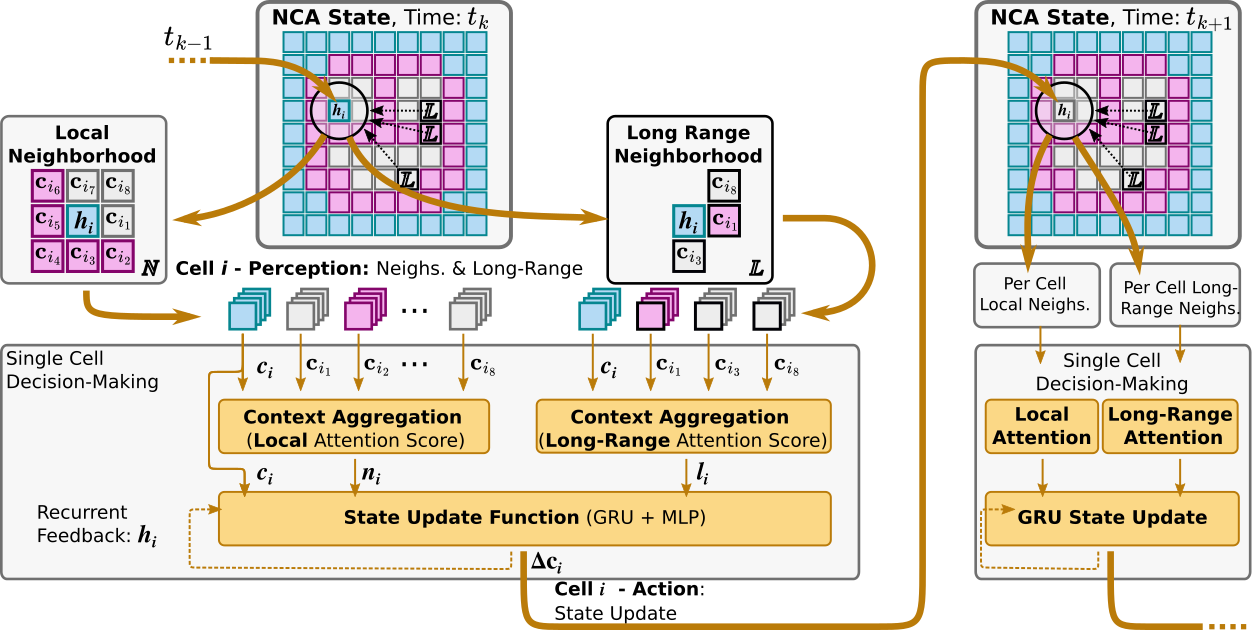
- attention layer: A mechanism that weights and selects information from neighbors based on learned relevance. "a brain-inspired NCA with an attention layer, long-range connections and complex topology."
- attention maps: Learned functions that produce attention weights over neighbors for message aggregation. "Both local and long-range attention maps and , Eq.~(\ref{eq:state:attention:map}), use a two-layer MLP (64 hidden units, GELU), respectively."
- attention-weighted neighborhood integration: Aggregating neighbor information using attention weights to prioritize relevant messages. "BraiNCA replaces purely local aggregation with attention-weighted neighborhood integration"
- backpropagation through time: A training method for recurrent models that unfolds computations across timesteps to compute gradients. "after which the loss is computed and parameters updated via backpropagation through time"
- bioelectrical prepattern: A spatial distribution of bioelectric signals that guides tissue patterning during development. "similar to the bioelectrical prepattern we can observe during frog embryogenesis"
- categorical policy: A probability distribution over discrete actions used for sampling actions in reinforcement learning. "Action selection then uses a 4-way categorical policy:"
- connectome: A comprehensive map of neural connections within a nervous system. "and connectome studies further highlight hub-like ârich-clubâ cores"
- cross-entropy loss: A loss function measuring the difference between predicted probabilities and true labels. "Training employs supervised learning with cross-entropy loss"
- E(n)-equivariant GNCA: Graph neural cellular automata whose computations are equivariant under Euclidean group E(n) transformations. "Later work extended GNCA to E(n)-equivariant GNCA formulations"
- Fisher's exact test: A statistical significance test used for categorical data, especially with small sample sizes. "Vanilla was significantly more robust than Long-Range (Fisher's exact one-sided test, )."
- Gated Recurrent Unit (GRU): A recurrent neural network unit with gating mechanisms for controlling information flow over time. "the state update module that employs a Gated Recurrent Unit (GRU), see Fig.~\ref{fig:architecture}."
- GELU: Gaussian Error Linear Unit, a smooth activation function used in neural networks. "two-layer MLP (64 hidden units, GELU)"
- graph neural networks: Neural models that operate on graphs using message passing between nodes. "using permutation-invariant aggregation in the spirit of graph neural networks"
- Graph-CA: Cellular automata defined over graphs rather than grids. "e.g. Graph-CA, Graph-NCA and GNCAs"
- Graph Neural Cellular Automata (GNCA): NCAs formulated on graphs with neural message passing between nodes. "Building on the GNCA paradigm of learned, message passing over arbitrary graphs"
- Graph-NCA: A graph-based neural cellular automaton variant. "e.g. Graph-CA, Graph-NCA and GNCAs"
- gradient clipping: A technique to limit the magnitude of gradients to stabilize training. "Network parameters are updated with Adam (learning rate , weight decay ) and gradient clipping."
- hub (network hub): A node with disproportionately many connections in a network. "scale-free hub connections can bypass communication globally."
- liveness channel: An auxiliary state channel indicating cell viability or opacity, used as visible output in NCAs. "visible channels (for instance, RGB plus an opacity/liveness channel)"
- log-rank test: A statistical test comparing survival distributions between groups. "log-rank one-sided "
- long-range connections: Edges connecting distant cells/nodes to enable non-local communication. "with an attention layer, long-range connections and complex topology."
- message passing: The process of exchanging and aggregating information between neighboring nodes/cells. "coordinate through message passing with their neighbors"
- Moore neighborhood: The eight surrounding cells in a 2D grid (one-hop neighbors). "Most of the Neural Cellular Automata (NCAs) defined in the literature have a common theme: they are based on regular grids with a Moore neighborhood (one-hop neighbour)."
- morphogenesis: The process by which a system develops its form or structure. "enabling spatially distributed coordination in morphogenesis experiments"
- multilayer perceptron (MLP): A feedforward neural network consisting of multiple fully connected layers. "are multilayer perceptron networks (MLPs)"
- non-Euclidean substrates: Data domains that are not embedded in regular Euclidean grids, such as graphs. "thereby supporting non-Euclidean substrates"
- permutation-invariant aggregation: A way of combining messages that is independent of the order of inputs. "using permutation-invariant aggregation"
- positional encodings: Numerical representations of position used to provide spatial information to models. "normalized 2D positional encodings"
- predictive coding: A theory/model where the brain minimizes prediction errors via feedback and feedforward processes. "the free-energy/predictive-coding framework connects these error signals to learning and perceptual phenomena"
- predictive-processing: A framework positing hierarchical generative models where perception involves prediction and error correction. "Predictive-processing theories propose hierarchical generative models"
- REINFORCE: A Monte Carlo policy gradient algorithm for reinforcement learning. "Learning employs the REINFORCE policy gradient algorithm with entropy regularization"
- restricted mean survival time (RMST): The expected time to event restricted to a specified time horizon, used in survival analysis. "reduced RMST from 658.4 to 454.2 episodes"
- rich-club: A network property where high-degree nodes are more densely interconnected. "hub-like ârich-clubâ cores that support efficient communication across modules"
- scale-free: A network with a power-law degree distribution, often featuring hubs. "Long-range connectivity is generated using a scale-free-inspired random procedure"
- small-world structure: Networks with high clustering and short path lengths due to local clustering and sparse shortcuts. "improving global integration without sacrificing local specialization \cite{watts1998collective}"
- softmax: A function converting logits into a probability distribution over classes. "The first three dimensions encode a probability distribution over the three cell types via softmax transformation"
- somatotopic organization: Spatial mapping of body-related variables onto corresponding topographic regions (e.g., in cortex). "somatotopic organization observed in human cortex"
- survival analysis: Statistical methods for time-to-event data that can handle censored observations. "We evaluated convergence using survival analysis on episodes-to-success"
- T-shaped topology: A non-rectangular spatial layout arranged in a T-shape to induce functional regionalization. "we introduce a new T-shaped topology that mimics structured, spatially grounded connectivity patterns for the lunar lander task."
- tunneling nanotubes (TNTs): Thin membrane channels enabling direct long-range intercellular transport. "Tunneling nanotubes (TNTs), for example,"
- weight decay: L2 regularization applied during optimization to discourage large parameter values. "with Adam (learning rate , weight decay )"
- Xavier uniform initialization: A parameter initialization scheme that preserves variance across layers. "initialized using Xavier uniform initialization for weights and zeros for biases."
- Zipf-distributed hub degree: A heavy-tailed distribution of node degrees following Zipf’s law, used to generate hubs. "Zipf-distributed hub degree capped at a maximum of six outgoing connections per hub."
Collections
Sign up for free to add this paper to one or more collections.

