Woosh: A Sound Effects Foundation Model
Abstract: The audio research community depends on open generative models as foundational tools for building novel approaches and establishing baselines. In this report, we present Woosh, Sony AI's publicly released sound effect foundation model, detailing its architecture, training process, and an evaluation against other popular open models. Being optimized for sound effects, we provide (1) a high-quality audio encoder/decoder model and (2) a text-audio alignment model for conditioning, together with (3) text-to-audio and (4) video-to-audio generative models. Distilled text-to-audio and video-to-audio models are also included in the release, allowing for low-resource operation and fast inference. Our evaluation on both public and private data shows competitive or better performance for each module when compared to existing open alternatives like StableAudio-Open and TangoFlux. Inference code and model weights are available at https://github.com/SonyResearch/Woosh. Demo samples can be found at https://sonyresearch.github.io/Woosh/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Woosh, a set of AI models from Sony AI that can create and understand sound effects. Think of sound effects like footsteps, door slams, laser zaps, rain—short, clear sounds used in movies, games, and videos. Woosh includes tools that:
- turn audio into a compact form and back again,
- connect text descriptions to sounds,
- generate sounds from text, and
- generate sounds that match a video.
The team releases open models and code so researchers and creators can build on them.
What were the main goals?
The researchers wanted to:
- Build a “foundation model” focused on high-quality sound effects (not music or long scenes).
- Make tools that work together: a strong audio compressor, a text–sound “translator,” and generators for text-to-audio and video-to-audio.
- Make fast versions that run with fewer computer resources but still sound good.
- Compare Woosh to other open models to see how well it performs.
How did they do it? (Methods in simple terms)
To make this work, they built four main parts. Here’s a plain-language tour:
1) Audio encoder/decoder (Woosh-AE)
- Imagine zipping a big audio file into a small file and unzipping it later without losing important details. That’s what the encoder/decoder does.
- It uses a clever way of looking at sound in tiny time slices (like frames in a video) and learns how to rebuild the sound cleanly.
- It avoids common “robotic” or “buzzy” artifacts by using a design that handles pitch and timing carefully.
- Trained on a mix of public sounds, speech, synthetic tones, and music so it learns a wide range of audio patterns.
2) Text–audio alignment model (Woosh-CLAP)
- This is like a bilingual dictionary for sounds and words. It learns to place captions and audio in the same “map,” so “metal clang” finds metal clang sounds.
- It uses powerful language and audio models and learns by matching correct pairs and pushing apart incorrect pairs.
- There are two versions:
- Public: trained on open datasets (like Freesound and AudioCaps).
- Private: trained on professional, studio-quality sound libraries with more technical labels.
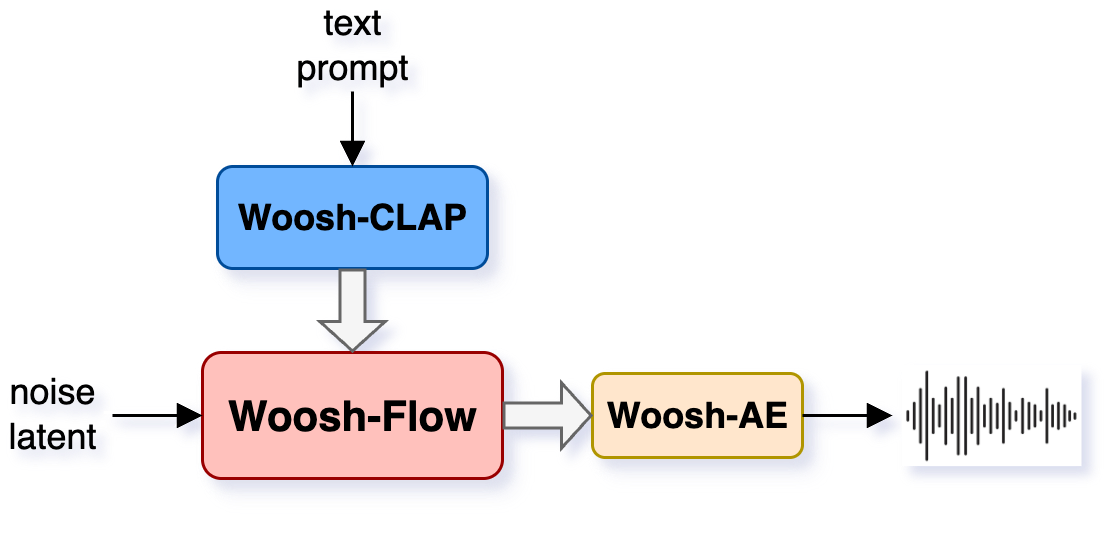
3) Text-to-audio generator (Woosh-Flow and fast Woosh-DFlow)
- Think of it like a sculptor that starts with random noise and carves out the exact sound you asked for (“a creaky door”).
- The “sculpting” process, called diffusion with flow matching, learns the best path from noise to the final sound.
- Distillation (teacher–student training) makes a much faster version (DFlow). The student imitates the teacher so it can create sounds in just a few steps instead of many.
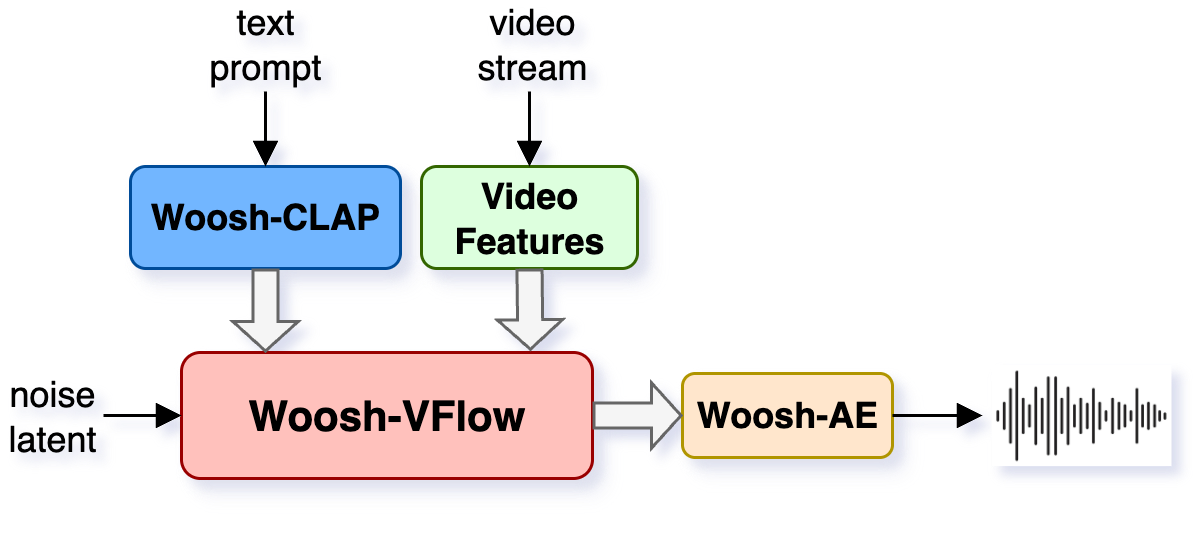
4) Video-to-audio generator (Woosh-VFlow and fast Woosh-DVFlow)
- This model watches video cues (like a ball hitting the ground) and generates matching sound effects.
- It uses a video feature extractor to understand what’s happening in the clip, then guides the audio generator to match it.
- It’s also distilled for speed, similar to the text model.
Training and evaluation in everyday terms
- Data: They used open datasets (like Freesound), synthetic examples, speech data, and, for some models, commercial studio libraries.
- Metrics: They checked how close the rebuilt or generated audio is to real audio, and how well sounds match the given text or video. They also measured how fast models run.
What did they find, and why does it matter?
Here’s what their tests showed:
- Encoder/decoder quality: Woosh’s audio compressor rebuilt sounds more accurately than several well-known open models, with fewer audio “mistakes” and better clarity.
- Text–audio alignment:
- On public datasets, a popular open model (LAION-CLAP) scored slightly better than Woosh-CLAP-Public—likely because it was trained on more data.
- On professional sound effect data, Woosh-CLAP-Private was far better at finding the right matches. This shows training on the “right kind” of data (studio SFX) really matters for pro use.
- Text-to-audio generation:
- On public tests, Woosh-Flow-Public produced higher-quality and better text-matching audio than other open models it was compared against.
- On professional SFX tests, Woosh-Flow-Private did best, meaning it shines when the target is clean, focused sound effects for production.
- The distilled version (Woosh-DFlow) ran much faster and still sounded close to the original, reducing steps from roughly 100+ to just 4. That’s a big speed-up.
- Video-to-audio generation:
- The video model learned to generate sounds that match what’s on screen.
- Some automatic sync metrics were unreliable, but manual checks showed the sounds line up well in practice.
- The distilled video model also kept quality while being much faster.
Overall: Woosh offers a strong, open, sound-effects-focused toolkit that matches or beats other open models in many tests, especially when trained on professional SFX data.
Why is this important?
- For creators and game developers: You can quickly generate clean, focused sound effects from a simple text prompt or a video clip—speeding up sound design.
- For researchers and students: The models and code are available for non-commercial use, making it easier to experiment, learn, and build new ideas.
- For industry: The results show that focusing on the right data and making specialized models can produce better, more controllable sound effects.
- For practical use: The distilled models are much faster and more lightweight, so you can run them on smaller machines or in real-time settings.
In short, Woosh is a step toward easy, high-quality, and fast sound effect generation—useful for everything from school projects and indie games to professional film and TV post-production.
Knowledge Gaps
Below is a consolidated list of concrete gaps, limitations, and open questions that remain unresolved in the paper, prioritized to guide follow-up research and ablations.
- Mono-only audio support: The entire pipeline (encoder/decoder and generators) operates on monaural audio; it remains unknown how the approach extends to stereo, binaural, and multichannel (e.g., 5.1/7.1) generation and what architectural or loss changes are required to preserve spatial cues.
- Long-duration generation: Training uses 5–10 s crops; the paper does not assess temporal coherence, repetition, drift, or scene transitions for longer ambiences or sequences, nor strategies for looping, chunked generation, or hierarchical conditioning to maintain long-term structure.
- Latent bitrate vs. generation quality: Woosh-AE uses relatively high-rate latents (100 Hz, 128-dim); there is no ablation on how latent frame rate and dimensionality impact T2A/V2A quality, sample diversity, training stability, or runtime, nor how to optimally trade off compression vs. generation performance.
- Phase prediction variant ablation: The alternative magnitude + normalized (x′, y′) approach is claimed to improve metrics, but there is no controlled ablation vs. the baseline VOCOS phase parameterization to quantify perceptual benefits, transient handling, or failure modes.
- Wapy synthetic data contribution: The effect of the internal Wapy dataset on reconstruction fidelity and generative quality is not quantified; an ablation is needed to measure its impact on high-frequency/transient reproduction and whether different synthetic recipe distributions would help.
- Robustness across SFX categories: There is no per-class analysis (e.g., impacts, whooshes, ambiences, mechanical, Foley) to identify strengths/weaknesses or category-specific failure modes.
- Music/speech leakage and disentanglement: AE training includes music and speech, but generation targets sound effects; the paper does not analyze whether the generators inadvertently produce music/speech, how to suppress them when undesired, or to explicitly control presence/absence.
- Domain gap without proprietary data: Private models trained on commercial SFX data clearly outperform on InternalSFX; the paper does not explore domain-adaptation or data-curation strategies that can close the gap using only public data.
- LLM-augmented captions: Private CLAP training expands terse labels via an LLM, but there is no quality audit (human study or automatic consistency checks) of these augmented captions, nor ablations to quantify their effect on retrieval and downstream generation.
- Multilingual conditioning: Text encoding relies on English RoBERTa; it is unclear how the models perform on non-English prompts, code-switching, or domain-specific jargon; multilingual or cross-lingual extensions remain unexplored.
- Prompt length and truncation: The effect of long or complex prompts (compositional instructions, negative prompts, contradicting attributes) on alignment and audio quality is not analyzed.
- Controllability and editing: The system supports only CFG-based global conditioning; there is no mechanism for timing control (onset/offset), loudness/envelope shaping, reverberation/room control, or localized editing/inpainting, nor evaluation of compositional layering of multiple events.
- Generalization and OOD robustness: There is no structured evaluation on unseen/rare SFX categories, adversarial or ambiguous prompts, or mismatched video scenes to test robustness and failure behavior.
- Human evaluation: All audio quality/alignment results rely on automatic metrics (FD/OpenL3, KL/PaSST, CLAP/LAION-CLAP, IB); there is no perceptual listening study with expert sound designers to validate subjective fidelity, usefulness, and alignment.
- Metric validity for SFX: The paper itself notes issues (e.g., SI-SDR unreliability for stochastic reconstructions, CLAP/KL bias toward public data, questionable SynchFormer sync scores); a key gap is the development and adoption of SFX-specific, perceptually valid metrics and benchmarks.
- Video–audio synchronization: Reported sync metrics are inconsistent with perception; alternative synchronization measures and human timing tests are needed, along with datasets providing event timestamps or localized audiovisual correspondences to train and evaluate sync explicitly.
- Video feature extractor dependence: V2A uses SynchFormer features exclusively; there is no ablation with alternative video encoders, frame rates, or multimodal fusion schemes, nor analysis of how video noise (e.g., camera motion, occlusions) affects alignment.
- Multi-condition interplay: For V2A+text, the model behavior under conflicting or complementary video and text cues is not studied; mechanisms for resolving conflicts or weighting modalities dynamically are not explored.
- Distillation trade-offs: MeanFlow + adversarial distillation reduces to 4 NFEs but induces a measurable quality drop; the paper does not examine alternative r/t schedules, teacher ensembles, second-order or adaptive solvers, or CFG-aware student designs to further close the gap.
- CFG distillation generality: The student is trained with CFG sampled in [1, 9], but it is unknown how well it generalizes to other CFG scales, prompt types, and out-of-distribution settings; calibration curves and failure cases are missing.
- Solver and renoising choices: For Woosh-Flow, DOPRI5 with tol = 1e-3 and ad hoc renoising weights are used; there is no ablation of solver type/tolerances or renoising schedules on quality, diversity, and runtime.
- Real-time constraints: Although “instant” generation is claimed for distilled models, there are no latency/throughput benchmarks on typical GPUs/CPUs, memory footprint analysis, or discussion of quantization/pruning for edge or mobile deployment.
- Training compute and reproducibility: The paper omits compute budgets, training times, seeds, and precise recipes for dataset filtering/segmentation/captioning; this limits reproducibility and makes it hard to assess scaling behavior and carbon footprint.
- Safety and copyright: There is no analysis of memorization risk, copyrighted content regurgitation, or safety filters (e.g., preventing unwanted speech/music, offensive or dangerous sound prompts), especially given training with licensed music and video-derived audio.
- Licensing and accessibility: Public weights are non-commercial; the feasibility of achieving private-model performance with fully open data and reproducible pipelines remains unanswered, as does the possibility of releasing commercial-grade checkpoints or recipes that close the gap.
- Evaluation breadth: Comparisons are limited to specific open models (SAO, TangoFlux, MMAudio-M); broader baselines (e.g., recent open T2A/V2A systems) and cross-benchmark evaluations are missing, particularly for professionally relevant SFX benchmarks.
- Temporal alignment in training: There is no explicit loss encouraging time-accurate alignment to text or video events (e.g., event-conditioned timings, alignment penalties), which could improve sync and controllability for Foley-style generation.
- Environmental robustness: The effect of background noise, reverberant conditions, and recording artifacts (common in public data) on learned representations and generation fidelity is not isolated or quantified.
- Failure case analysis: The paper lacks qualitative error taxonomy (e.g., over-smoothing, metallic artifacts, missing onsets, incorrect material/timbre) across modules, which would inform targeted model/loss modifications.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now using the released Woosh models and code (subject to license terms and compute availability).
- Media and entertainment (film/TV/games): fast Foley ideation and placeholder SFX
- What: Use Woosh-Flow (T2A) or Woosh-DFlow (distilled, 4-NFE) to generate placeholder Foley and transitional SFX from scene descriptions during rough cuts and previz; rapidly audition variations via prompt edits; export for human polish.
- Tools/workflows: NLE/DAW plugin (e.g., Adobe Premiere, Resolve, Pro Tools, Reaper) that sends timeline selections + text prompts to a Woosh inference server; preset prompt library (footsteps, doors, UI beeps); batch-render variants.
- Assumptions/dependencies: Public weights are non-commercial; for commercial production, licensing or access to the private model is needed. Generated audio is monaural at 48 kHz; stereo or surround requires downstream spatialization. GPU inference recommended for throughput.
- Media and entertainment: video-to-audio “auto-Foley” passes for temp tracks
- What: Use Woosh-VFlow/DVFlow to synthesize sync’d SFX from scene video and optional text hints (e.g., “leather jacket rustle; gravel footsteps; glass clink”).
- Tools/workflows: Timeline “Generate Foley Pass” that emits per-shot audio stems for editorial; editor confirms/overrides using quick prompts; re-generate only changed regions.
- Assumptions/dependencies: Sync metrics can be noisy; human review remains essential. Data domain matters (clean, non-music/speech shots perform better). Non-commercial license for public weights.
- Creator economy (YouTubers, streamers, podcasters): quick custom cues and stingers
- What: Generate short whooshes, risers, UI taps, and comedic hits via T2A for intros/outros and transitions.
- Tools/products: Web app or OBS plugin backed by Woosh-DFlow for low-latency generation; “style” prompt presets.
- Assumptions/dependencies: Model is monaural; stereo widening post-FX needed. Non-commercial use is permitted; commercial use requires licensing.
- Game development: rapid SFX prototyping and asset baking
- What: Designer-facing tool that maps gameplay events to text prompts and bakes a bank of SFX variants for iteration; enables “first-playable” audio without waiting on recording sessions.
- Tools/workflows: Unity/Unreal editor plugin that compiles an event-to-prompt manifest and batch-generates SFX; optional on-level “regenerate variant” hotkeys.
- Assumptions/dependencies: Real-time, on-device generation is not yet practical; generate offline and cache. Spatialization handled by engine middleware. License constraints for commercial shipping.
- SFX library search, auto-tagging, and deduplication (software/media)
- What: Use Woosh-CLAP to index large SFX libraries for text-to-audio retrieval, auto-generate verbose captions, and cluster/flag near-duplicates to reduce library bloat.
- Tools/workflows: “Smart SFX” search panel inside DAWs/NLEs; batch captioning pipeline for catalog ingestion; dedupe dashboard using embedding distances.
- Assumptions/dependencies: Domain mismatch matters—Woosh-CLAP-Private excels on pro SFX; public CLAP variants do better on public datasets. Some manual QA required.
- Audio ML and dataset engineering (academia/industry): augmentation and baselines
- What: Synthesize class-balanced SFX for training audio event detectors; use Woosh-AE latents as compact representations; adopt Woosh-Flow as an open baseline for SFX generation research.
- Tools/workflows: Data augmentation scripts that vary prompts, CFG, and noise seeds; evaluation with FD/KL/CLAP; active-learning loops to target underrepresented events.
- Assumptions/dependencies: Beware distribution shift and label leakage; synthetic data must be flagged; validate on real test sets.
- Postproduction QC: caption–audio alignment checks
- What: Use CLAP scores to verify that SFX stems match shot lists or cue sheets (e.g., “should contain door slam; not contain crowd”).
- Tools/workflows: Automated QC report that highlights low-alignment cues for human review; integrate into render farm checks.
- Assumptions/dependencies: Alignment metrics are imperfect; calibrated thresholds per genre/domain needed.
- Audio compression/review (software): high-fidelity reconstruction with Woosh-AE
- What: Use the encoder/decoder as a perceptual “codec” for quick-turn SFX reviews in remote pipelines.
- Tools/workflows: Upload portal that encodes SFX to latents and replays via decoder; side-by-side AB checks for stakeholders.
- Assumptions/dependencies: 221M-param model with 3.75× compression; compute overhead vs traditional codecs; monaural only.
Long-Term Applications
These use cases require further research, scaling, model extensions (e.g., multichannel), or productization beyond the current public release.
- Spatial, binaural, and multichannel SFX generation (media, XR)
- What: Directly generate stereo/5.1/7.1/binaural effects with scene-aware spatial cues (distance, azimuth, room response).
- Potential products: “Spatial Woosh” plug-ins for DAWs; XR SDK that renders environment-conditioned SFX on the fly.
- Assumptions/dependencies: Training data with spatial labels or multichannel stems; room/geometry conditioning; higher memory and I/O.
- Physics- and scene-aware Foley (media/games/robotics)
- What: Condition generation on 3D geometry, materials, and interaction state to yield physically plausible SFX (e.g., footsteps that adapt to surface and speed).
- Potential workflows: Link to physics engines for procedural audio; hybrid generative + convolutional reverb chains.
- Assumptions/dependencies: Rich multimodal datasets (video + depth + materials); controllable conditioning interfaces; real-time constraints.
- Real-time, on-device SFX for AR/VR and mobile (software/XR)
- What: Dynamic generation reacting to user actions and environment in AR/VR experiences.
- Potential products: Edge-optimized DVFlow variants with quantization and distillation; caching of short primitives.
- Assumptions/dependencies: Aggressive model compression/pruning; hardware acceleration; latency budgets <20–40 ms for responsiveness.
- End-to-end assistant for sound editorial (media)
- What: An “audio copilot” that detects events in the timeline, proposes layered SFX, mixes levels, and handles ducking—learns from editor corrections.
- Potential workflows: Event detection → prompt generation → batch synth → human-in-the-loop approval → versioning.
- Assumptions/dependencies: Robust event detectors; UI/UX inside NLE/DAW; audit trails and reproducibility for revisions.
- Audio restoration and inpainting
- What: Remove unwanted noise and regenerate plausible SFX fills conditioned on video and text (e.g., replace unusable production impacts).
- Potential tools: “Inpaint SFX” brush in DAWs tied to Woosh-AE + Flow.
- Assumptions/dependencies: Training for masked/inpainting objectives; careful guardrails to prevent semantic drift.
- Robotics and autonomy: scalable acoustic simulation for perception training
- What: Generate diverse, rare, and safety-critical environmental sounds (alarms, glass breaks, tool use) to expand training corpora and domain randomization.
- Potential products: Synthetic soundpacks for sim platforms; scenario generators with controllable attributes.
- Assumptions/dependencies: Transfer to real-world detection; bias control; validated evaluation protocols.
- Personalized and brand-consistent sonic identities (marketing/commerce)
- What: Fine-tune or prompt-control to create consistent “palettes” of SFX for brands, products, or creators.
- Potential tools: Style tokens/presets; governance for reuse across campaigns.
- Assumptions/dependencies: Mechanisms for style conditioning or lightweight adaptation; license terms allowing customization.
- Provenance, watermarking, and policy tooling (policy/industry standards)
- What: Watermark synthetic SFX, attach provenance metadata, and verify during delivery/ingest—support compliance (e.g., EU AI Act transparency).
- Potential products: “Generate with provenance” mode; ingest validators for post studios and broadcasters.
- Assumptions/dependencies: Robust audio watermarks for short, percussive SFX; industry alignment on metadata schemas.
- Education and training (academia/edtech)
- What: Interactive labs for sound design and audio ML; students explore prompt engineering, flow matching, and CLAP retrieval.
- Potential tools: Course kits and notebooks with open weights; challenge leaderboards.
- Assumptions/dependencies: Simplified installs; cloud credits; clear non-commercial licensing.
- Content safety and forensics (policy/public safety)
- What: Classify and flag potentially misleading or sensitive synthetic SFX in user-generated content; support investigations with cross-modal embeddings.
- Potential tools: Embedding-based detectors and retrieval for platform moderation.
- Assumptions/dependencies: Clear policy definitions (e.g., weapon sounds in sensitive contexts); risk of false positives; privacy and due process.
Cross-cutting assumptions and dependencies
- Licensing and usage scope: The public Woosh weights are released for non-commercial use; commercial deployment requires separate licensing or access to private models.
- Audio format: Current models are monaural at 48 kHz; multichannel/spatial use cases require downstream processing or future model extensions.
- Compute and latency: Although DVFlow/DVFlow reduce NFEs to 4, model sizes remain large; practical real-time/on-device use will need quantization and acceleration.
- Domain fit: Alignment and quality depend on the domain; Woosh-CLAP-Private/model variants trained on pro SFX data outperform on studio use cases, while public models fare better on public datasets.
- Human-in-the-loop: For professional workflows, human review remains essential for sync, mix balance, and creative intent.
- Data governance and ethics: Synthetic data used for ML training should be labeled as such; adopt provenance and consent practices for datasets and generated assets.
Glossary
- Adversarial loss: A training objective from GANs where a generator tries to fool discriminators that learn to distinguish real from generated data. "Adversarial loss --- A total of 8 discriminators are used for training: multi-period discriminators (MPD)~\cite{kong20} with periods , and multi-band multi-scale complex STFT discriminators (MBMS-STFT)~\cite{kumar23,zeghidour21,defossez22} with window sizes , each using 5~bands."
- classifier-free guidance (CFG): A technique for conditional generative models that blends conditional and unconditional predictions to steer outputs toward the condition. "Considering that Woosh-Flow is a text-conditioned model, the MF procedure can also account for classifier-free guidance (CFG)~\cite{ho22} at training time."
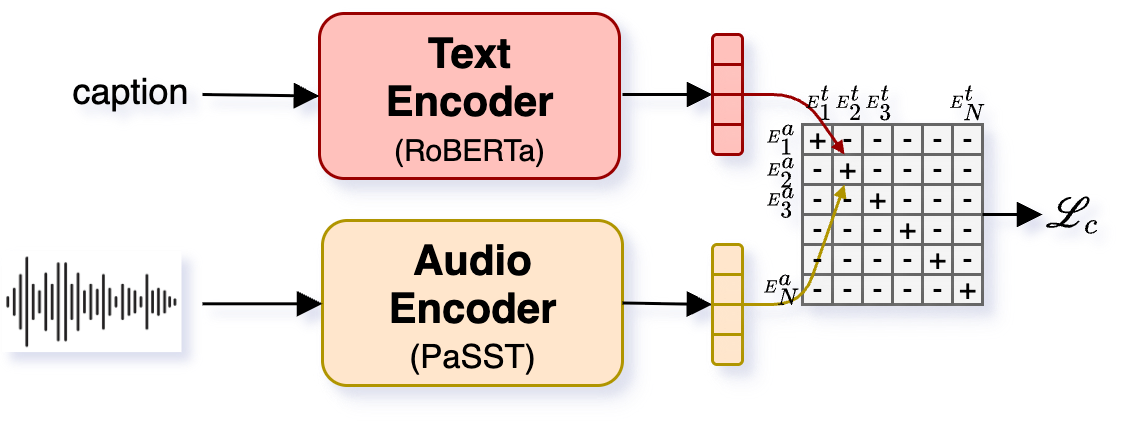
- contrastive language-audio pretraining (CLAP): A multimodal training approach aligning text and audio embeddings so that related pairs are close and unrelated pairs are far in a shared space. "The Woosh-CLAP text conditioning module uses a text encoder trained for text-audio alignment following the contrastive language-audio pretraining (CLAP)~\cite{elizalde22} approach."
- contrastive loss: An objective that pulls matching pairs together and pushes mismatched pairs apart in embedding space. "The symmetric contrastive loss~\cite{radford21} is then computed as"
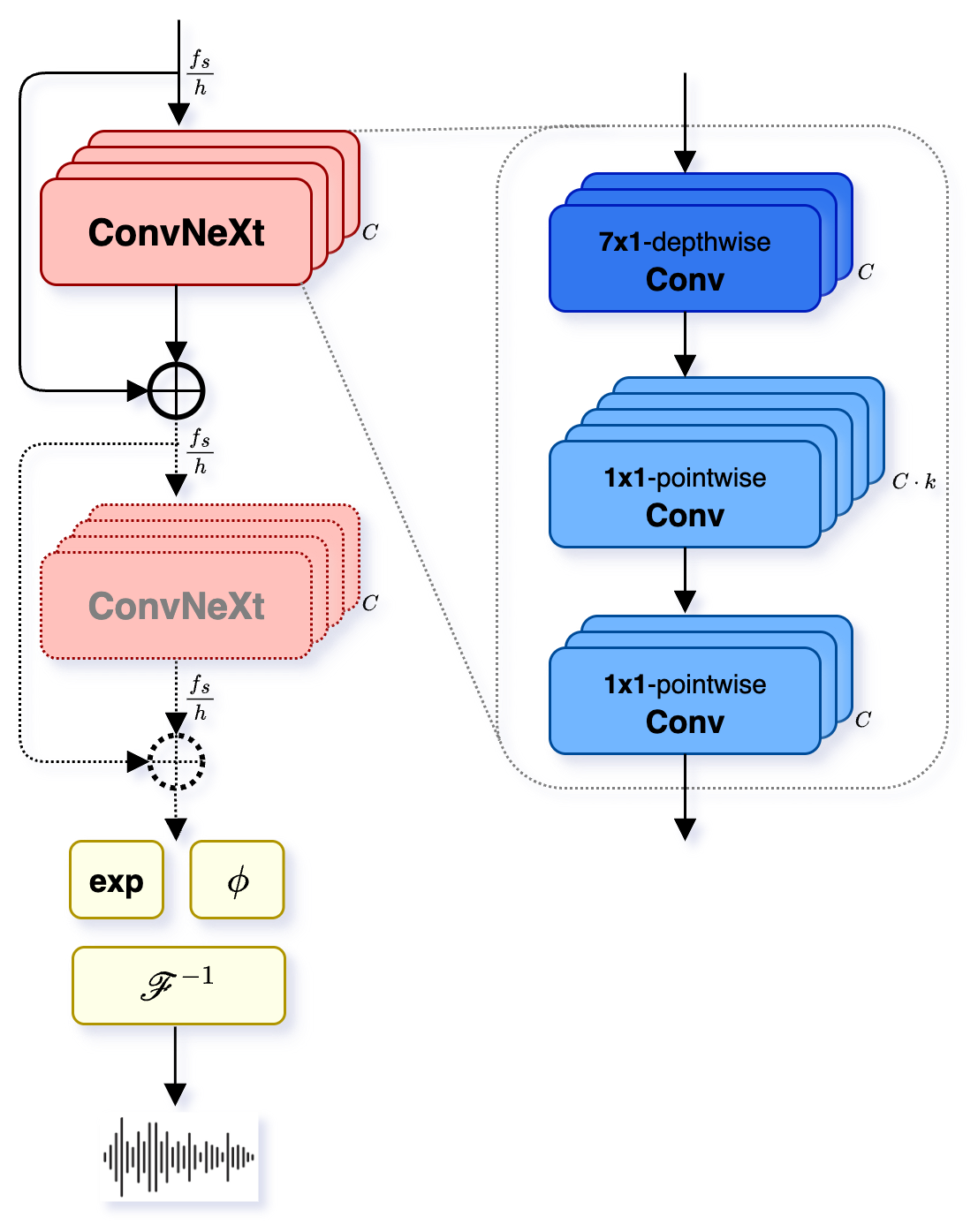
- ConvNeXt: A convolutional neural network architecture with modernized design that serves as building blocks in encoders/decoders. "The VOCOS architecture uses a cascade of ConvNeXt blocks with residual connections both in the encoder and decoder~\cite{siuzdak24}"
- Dormand–Prince (DOPRI5): A higher-order adaptive Runge–Kutta ODE solver often used for efficient sampling in diffusion models. "At inference time, the learned dynamics via velocity estimation define a well-specified initial-value problem, for which arbitrary ordinary differential equation (ODE) solvers can be used, e.g.,~higher-order adaptive solvers such as DormandâPrince (DOPRI5)."
- Feature matching loss: A GAN regularization that matches intermediate discriminator feature statistics between real and generated samples. "Feature matching loss --- The L1 norm of the difference between discriminator feature maps for real and generated audio, taking expectation over all layers and discriminators"
- flow matching (FM): A training objective where the model learns a velocity field that transports noise to data along straight probability paths. "In a first stage, Woosh-Flow is trained using a flow matching (FM) objective~\cite{lipman23,lipman24}."
- Fréchet distance (FD): A distribution-level metric (here over embeddings) comparing generated outputs to references; lower is better. "To measure the perceptual quality of the generated audio, we compute the Fréchet distance between the OpenL3 embeddings of the generated and the ground truth audio samples (FD)~\cite{pascual23}."
- GAN hinge loss: A discriminator loss variant for GANs that uses hinge margins to stabilize training and improve sample quality. "The GAN hinge loss~\cite{lim17} is used in the discriminator together with adversarial losses."
- inverse short-time Fourier transform (iSTFT): The process reconstructing time-domain audio from STFT complex spectra. "The iSTFT avoids aliasing artifacts, typically linked to transposed convolutions used in upsampling~\cite{pons21icassp} in alternative approaches."
- Jacobian vector product (JVP): An efficient way to compute derivatives of vector-valued functions with respect to inputs without forming full Jacobians. "The Jacobian vector product (JVP) operation is used to evaluate ."
- Kullback–Leibler divergence (KL): A measure of divergence between two probability distributions (or predicted class distributions). "Additionally, we use the Kullback-Leibler divergence between the PaSST embeddings~\cite{koutini22} (or class probabilities) of the generated audio and the corresponding ground truth (KL)"
- LAION-CLAP score (CLAP): A cosine similarity-based text–audio relevance metric computed using the LAION-CLAP encoders. "We evaluate the alignment between the generated audio and the input conditioning modalities using the LAION-CLAP~\cite{WuCZHBD23laionclap} score (CLAP)"
- latent adversarial diffusion distillation: A distillation method that uses adversarial training in latent space to speed up diffusion sampling. "Based on the latent adversarial diffusion distillation approach~\cite{sauer24}, the discriminator learns to distinguish noisy ground truth (i.e.,~true samples), from noisy student-predicted (i.e.,~fake samples)."
- Latent diffusion model (LDM): A diffusion model operating in a learned latent space rather than raw data space for efficiency. "our latent diffusion model (LDM) has been optimized from the ground up for sound effects and for professional use."
- Least squares GAN (LSGAN): A GAN variant with a least-squares discriminator objective that can improve stability and gradients. "The sum of discriminator outputs is used in a least squares GAN objective, as in~\cite{kumar23,mao17}"
- Log-mel Distance (MelDist): An L1 distance metric between log-mel spectrograms of reference and reconstructed audio. "Log-mel Distance (MelDist) --- The L1 distance between ground-truth audio and reconstructed audio log-mel spectra."
- Log-STFT Distance (STFTDist): An L1 distance between STFT magnitude spectra of reference and reconstructed audio. "Log-STFT Distance (STFTDist) --- The L1 distance between ground-truth audio and reconstructed audio STFT magnitude spectra."
- MeanFlow (MF): A distillation approach that trains a model to predict average velocities over time intervals to reduce sampling steps. "the pretrained diffusion model is further distilled using the MeanFlow (MF) approach~\cite{geng25}, allowing to reduce the NFEs at inference time from 100 to 4"
- MBMS-STFT (multi-band multi-scale complex STFT discriminators): A family of discriminators operating on multi-band, multi-scale complex STFT representations. "multi-band multi-scale complex STFT discriminators (MBMS-STFT)~\cite{kumar23,zeghidour21,defossez22} with window sizes , each using 5~bands."
- mel spectrogram: A time–frequency representation mapping frequencies to the perceptual mel scale, often used in audio ML. "multi-scale L1 losses are computed on mel spectrograms with window sizes "
- Multi-period discriminators (MPD): A set of waveform discriminators each sampling at a different periodicity to capture diverse temporal structures. "multi-period discriminators (MPD)~\cite{kong20} with periods "
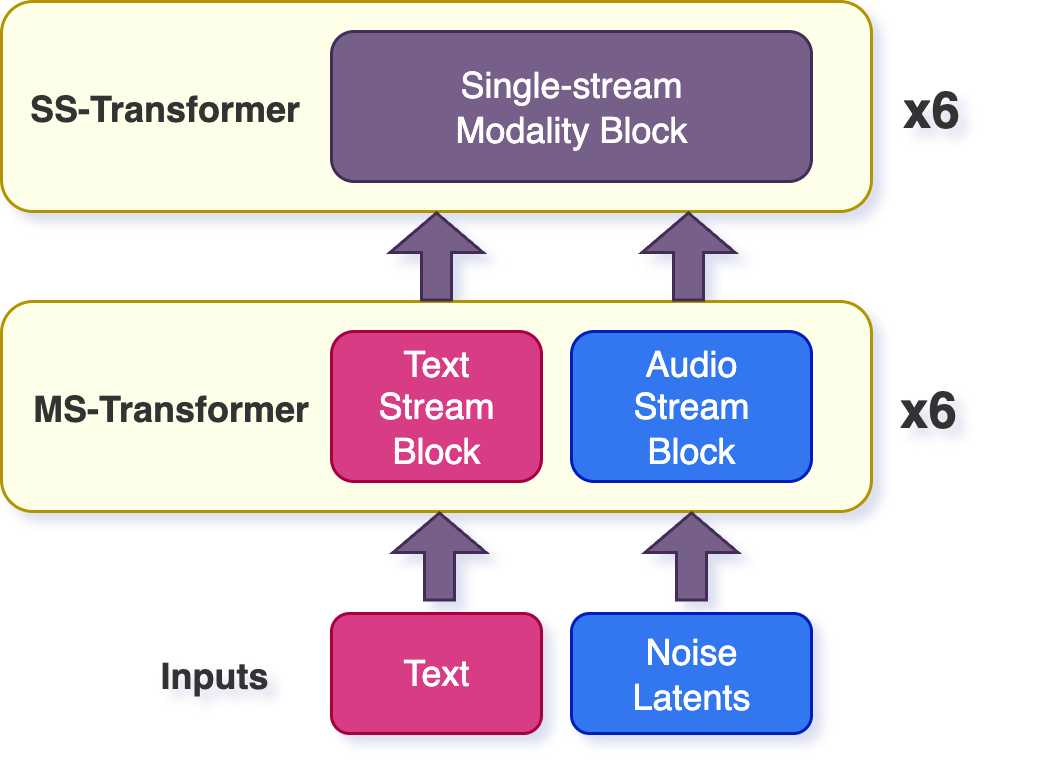
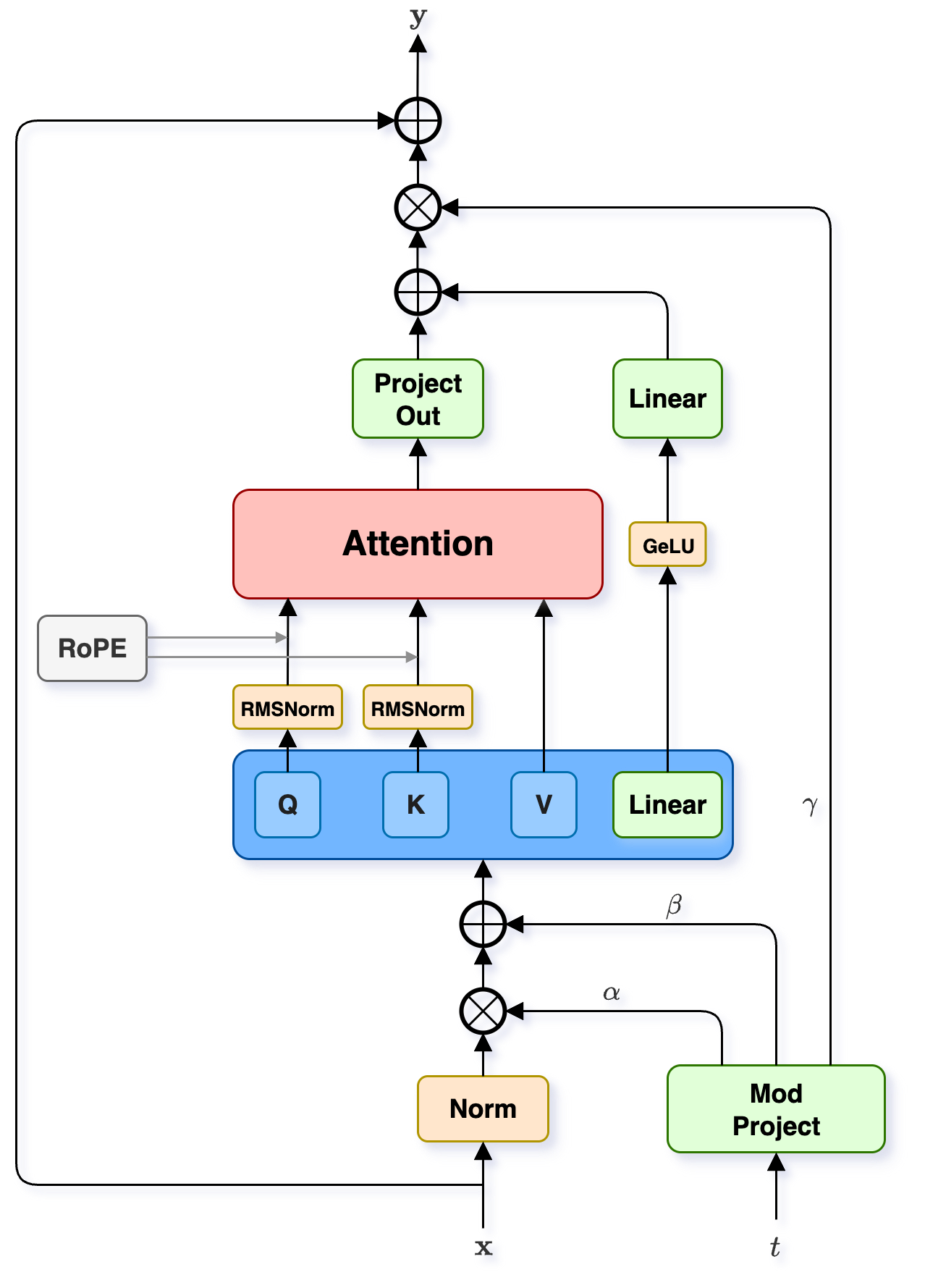
- MultiStream transformer block: A multimodal transformer block that processes each modality stream with separate self-attention and FFN. "MultiStream modality blocks compute both self-attention and feed-forward network outputs on each modality sequence independently, and use rotary positional embeddings (RoPE)~\cite{su23}."
- OpenL3: A self-supervised audio (and audiovisual) embedding model used for downstream metrics like FD. "we compute the Fréchet distance between the OpenL3 embeddings of the generated and the ground truth audio samples (FD)~\cite{pascual23}."
- PaSST: A transformer-based audio encoder using patched spectrogram inputs, suited for long audio via chunk aggregation. "Woosh-CLAP uses RoBERTa-Large~\cite{liu19} as the text encoder and PaSST~\cite{koutini22} as the audio encoder."
- phase wrapping: Ambiguity arising when phase angles exceed their principal range, causing discontinuities; models avoid it with alternative parameterizations. "This formulation avoids phase wrapping issues for any phase vector ."
- RoBERTa-Large: A large pretrained transformer LLM used here as the text encoder for CLAP. "Woosh-CLAP uses RoBERTa-Large~\cite{liu19} as the text encoder"
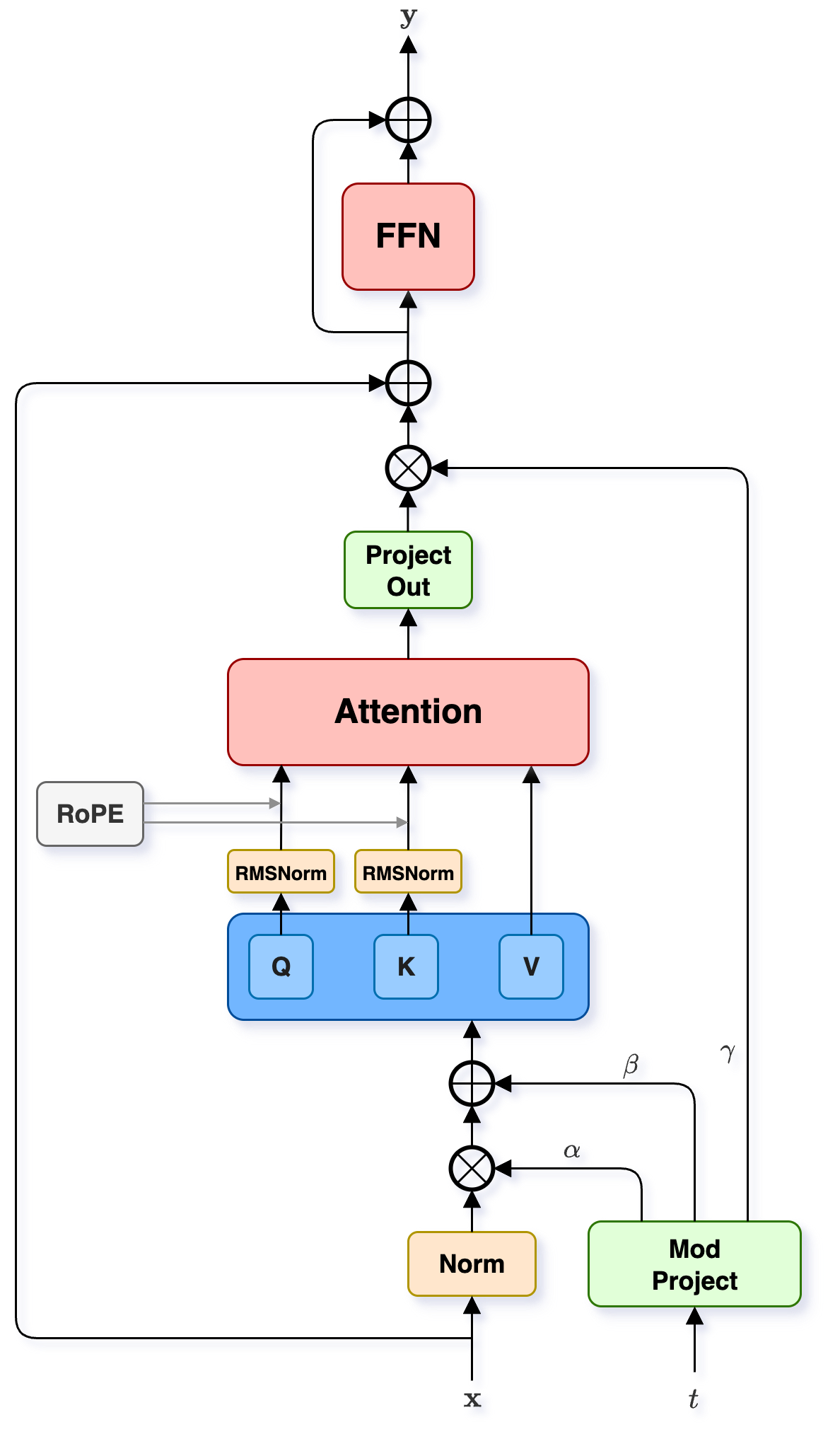
- rotary positional embeddings (RoPE): A positional encoding method for transformers that rotates query/key representations to encode positions. "and use rotary positional embeddings (RoPE)~\cite{su23}."
- Scale Independent Signal-to-Distortion Ratio (SI-SDR): A scale-invariant ratio measuring reconstruction fidelity between target and estimate. "Scale Independent Signal-to-Distortion Ratio (SI-SDR) --- Ground truth audio norm to reconstruction error norm ratio, scaling the ground truth to match the reconstructed audio."
- short-time Fourier transform (STFT): A time–frequency transform computing spectra over sliding windows, producing complex coefficients. "a GAN-based vocoder operating on the domain of the short-time Fourier transform (STFT) complex coefficients."
- SingleStream transformer block: A multimodal transformer block that computes self-attention over a time-concatenated sequence of all modalities. "SingleStream modality blocks compute self-attention on a single sequence of time-concatenated modality sequences, also using RoPE."
- SynchFormer: A model for extracting video features and assessing audio–video synchronization. "the video conditioner utilizes features extracted from the input video using SynchFormer~\cite{iashin24} at a frame rate of 24\,Hz."
- variational autoencoder (VAE): A probabilistic autoencoder that learns latent variables by maximizing an evidence lower bound. "StableAudio-Open variational autoencoder (SAO-VAE) \cite{evans24sao}"
- VOCOS: A GAN-based vocoder architecture that predicts complex STFT components via ConvNeXt blocks. "The Woosh-AE module is based on the VOCOS architecture~\cite{siuzdak24}, a GAN-based vocoder operating on the domain of the short-time Fourier transform (STFT) complex coefficients."
- vocoder: A neural network (or DSP) that generates waveforms from intermediate acoustic representations. "a GAN-based vocoder operating on the domain of the short-time Fourier transform (STFT) complex coefficients."
Collections
Sign up for free to add this paper to one or more collections.