Fish Audio S2 Technical Report
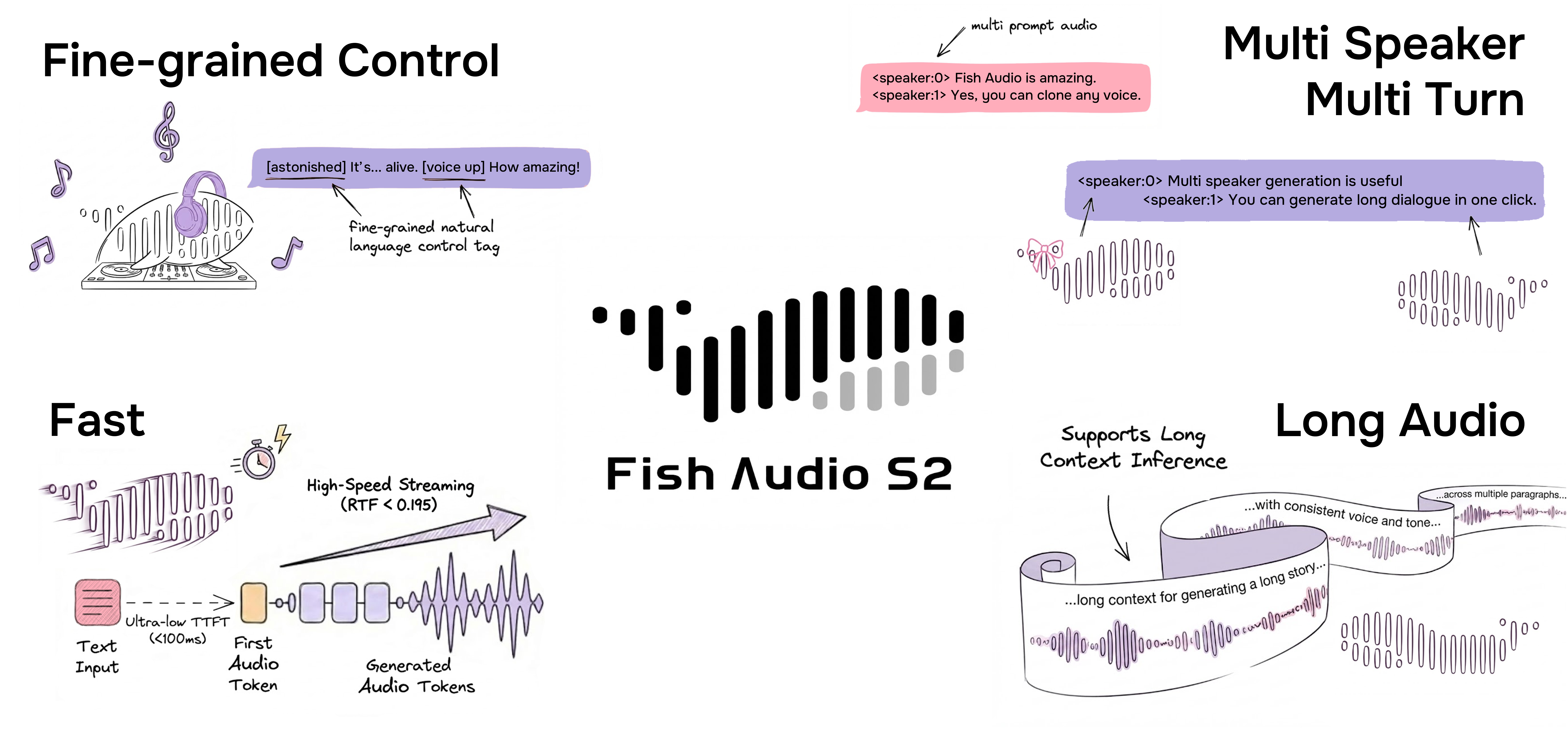
Abstract: We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Fish Audio S2, a powerful text-to-speech (TTS) system. TTS means turning written text into spoken voice. Fish Audio S2 can:
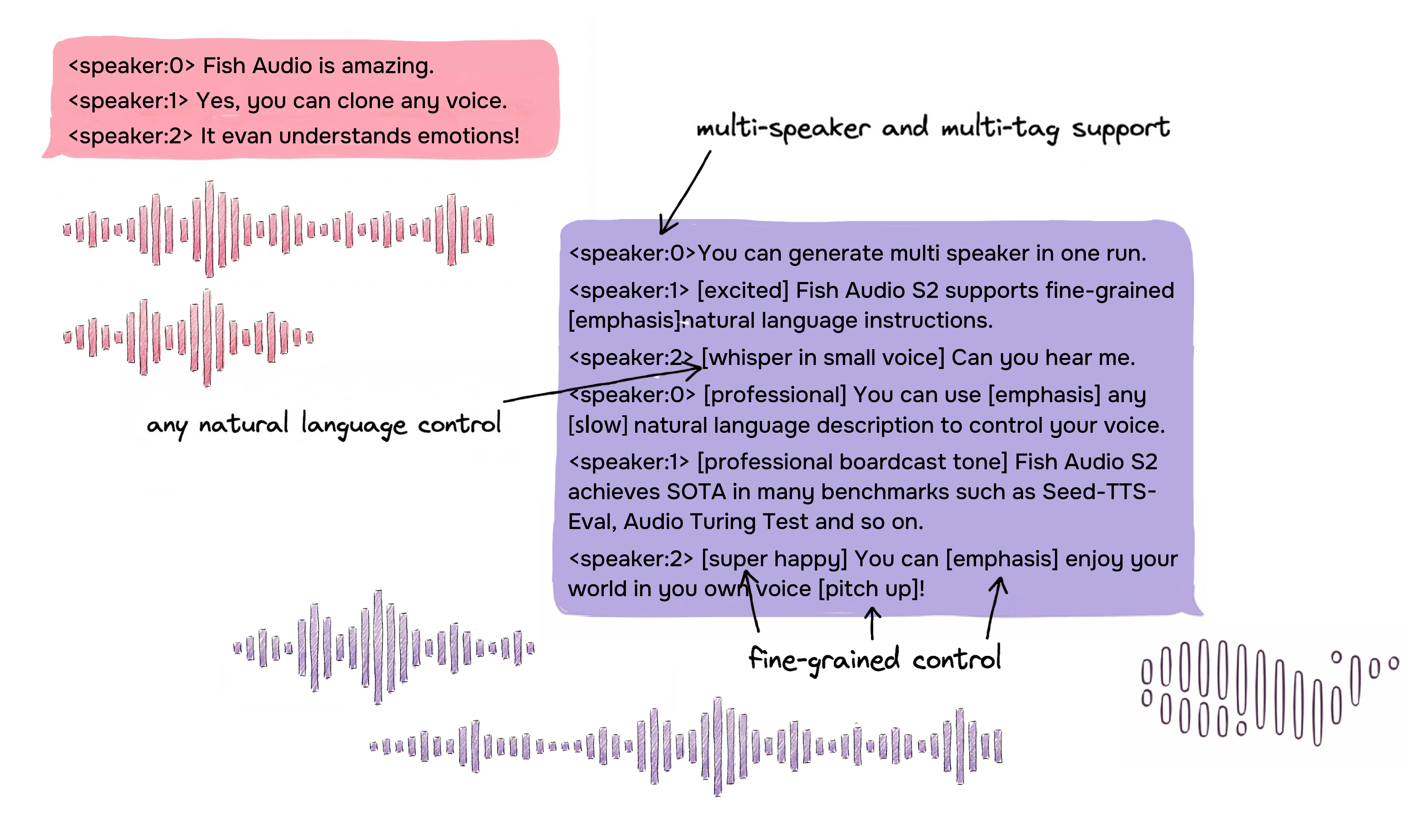
- Follow detailed, natural-language instructions like “speak softly, with a smile” or “switch to Speaker 2 and sound excited”
- Handle conversations with multiple speakers in a single go
- Speak for a long time without losing voice quality or making mistakes
- Run very fast, so it can stream audio almost immediately
It’s open-source, so people can use the model, fine-tune it, and run it in real applications.
What questions were the researchers trying to answer?
In simple terms, the team wanted to know:
- How can we make a TTS system that not only sounds natural but also follows detailed instructions about emotion, style, and timing?
- How can we train it on huge amounts of real-world audio while keeping quality high?
- How can we make it run fast enough for live, streaming use?
- How can we prove it works well across many languages, long recordings, and multi-speaker dialogues?
How did they build and train the system?
To make this easy to understand, think of the system as having three main parts: how audio is represented, how speech is generated, and how the data and training process teach it to follow instructions.
1) Turning sound into “building blocks” (Audio Tokenizer)
Imagine turning a song into LEGO pieces of different sizes. The system breaks audio into 10 layers of tokens:
- The first layer captures the “meaning” and basic pronunciation (like the outline of a drawing).
- The other layers add finer details like tone, texture, and crispness (like coloring and shading).
They made this tokenization fast and good for streaming, so it can start speaking with almost no delay.
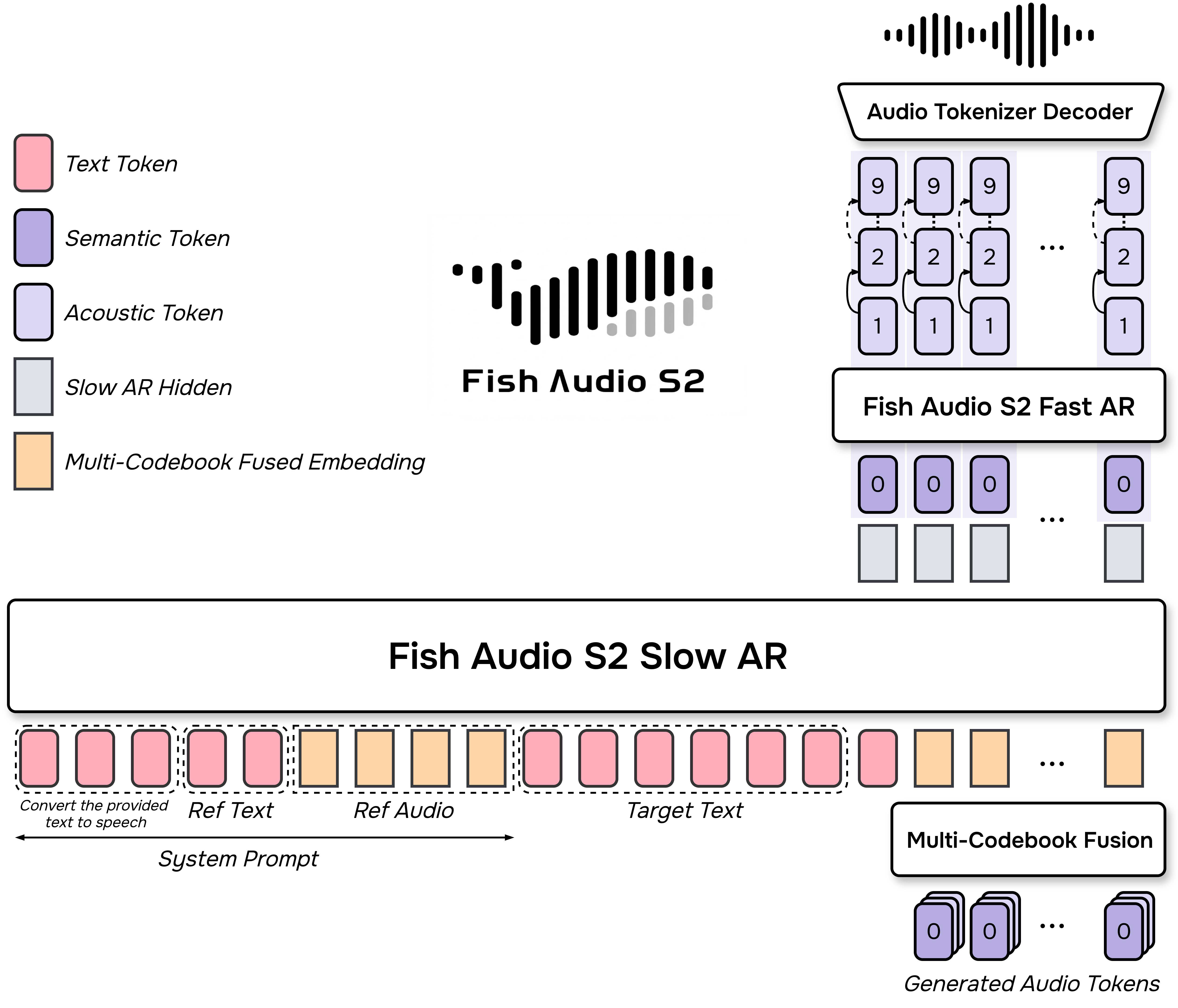
2) Generating speech with a two-part “brain” (Dual-Autoregressive model)
Think of a comic being made by two artists:
- The “Slow AR” is the planner. It decides what to say and the general flow. It handles the main storyline: the words and the rough style.
- The “Fast AR” is the detailer. Once the planner picks the next step, the detailer fills in the rich sound details—voice color, texture, and clarity.
This split lets the model handle long passages while still sounding rich and natural, and it keeps generation efficient.
3) Building a smart training pipeline (Data Pipeline)
The team designed a three-step data process so the model learns from high-quality, well-labeled examples. Here’s how it works:
- Stage 1: Separate and slice. They separate voice from background sounds and cut long audio into clean chunks.
- Stage 2: Quality check. A “sound judge” model filters out noisy or messy clips, keeping only good ones.
- Stage 3: Rich transcription. A speech-to-text model not only writes down the words but also adds tags like emotions, laughs, pauses, and speaker turns. For example: “<|speaker:1|> That’s amazing! [laugh]”
These same “judges” are reused later as rewards to teach the model to follow instructions—so training and judging match.
4) Teaching it to follow instructions better with rewards (Reinforcement Learning)
After basic training, the model is fine-tuned using a reward system. For the same prompt, it tries several versions; the system scores each one and nudges the model toward better behavior. The rewards check:
- Did it say the right words and follow the instructions? (accuracy)
- Does it sound clean and pleasant? (audio quality)
- Does the voice match the example speaker? (voice similarity)
This multi-part reward keeps it from “gaming” the system and helps it improve across all the important areas.
5) Making it run fast (Inference Engine)
They built the serving system on a high-performance engine so it:
- Starts playing audio in under 100 milliseconds (about a blink)
- Generates speech much faster than real time (about 5 seconds of speech in 1 second of processing)
- Handles many users at once without slowing down
It also reuses cached voice info so repeated requests with the same voice start even faster.
What did they find?
Here are the highlights, explained simply:
- Speed: It’s very fast for streaming. Time-to-first-audio is under 100 ms, and it generates speech at about 5× faster than real time (RTF ≈ 0.195).
- Instruction following: It responds well to fine-grained tags like emotions, laughs, and emphasis. On their own instruction test, it activated the right tags about 93% of the time and kept high quality (4.51/5).
- Realism: On the “Audio Turing Test,” which checks whether speech sounds human, it scored strongly—especially when prompts were rewritten to be clearer about style and intent.
- Multilingual strength: It works well across many languages (over 20 tested), with low error rates and stable speaker similarity.
- Long-form stability: It stays consistent over long passages, keeping the same voice and clear pronunciation.
- Benchmarks: It achieved top or near-top results on several public tests for word error rate (how often the words differ from the script), speaker similarity, and instruction-following quality.
Why this matters: You get voices that not only read the words but also act them—sounding happy, serious, whispery, rushed, or even switching speakers—while staying accurate and stable.
Why does this research matter?
This work moves TTS from “reading text” to “performing text.” That matters for:
- Audiobooks and podcasts with expressive narration
- Video dubbing and multilingual content creation
- Games and virtual characters that sound natural and can change styles on cue
- Accessible tools for people who need voice technology to communicate
Because the model, code, and engine are open-source, others can build on it, improve it, and adapt it to new uses. The authors note there’s still room to grow—like doing even better in languages with less training data and pushing controllability further—but Fish Audio S2 is a strong step toward flexible, human-like, and fast voice generation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that the paper does not fully resolve and that future work could directly act on:
- Data/composition: Precise breakdown of the 10M+ hours (by language, dialect, gender, accent, domain, recording conditions) is missing, hindering reproducibility and bias assessment.
- Data licensing/consent: Provenance, consent, and licensing of the proprietary audio (especially from video sources) are unspecified; policies for speaker consent and opt-out are not described.
- Public assets: The curated datasets, speech quality model, rich-transcription ASR, and reward models are not released; without these, key claims (and the dual-purpose data/reward design) cannot be independently verified.
- Data bias/audit: No demographic and linguistic bias audit (e.g., accent/gender/age fairness) is reported for data, pretrained tokenizer, or the final TTS model.
- Instruction annotations: Accuracy and reliability of the automatically generated fine-grained vocal instructions (e.g., [angry], [laugh]) are not quantified; inter-annotator agreement and error modes are omitted.
- Error propagation: How transcription/tagging errors from the rich ASR propagate into SFT/RL (and affect controllability) is not studied.
- Code-switching: Robustness to intra-utterance code-switching and mixed scripts (esp. in low-resource languages) is not evaluated.
- Text normalization (TN/ITN): Handling of numbers, dates, abbreviations, casing, homographs, and domain-specific terms is not described or benchmarked.
- Low-resource languages: Underperformance in certain low-resource languages is acknowledged but not analyzed; no data scaling or curriculum strategies are proposed to close the gap.
- Phoneme/G2P policy: The phoneme injection augmentation is mentioned, but the phonemizer(s), language coverage, and its impact on pronunciation consistency are not reported.
- Tokenizer bitrate/ablation: The RVQ tokenizer’s effective bitrate, reconstruction fidelity (vs. EnCodec/Mimi), and ablations (e.g., N codebooks, 21 Hz frame rate) are not provided.
- Semantic distillation: How much linguistic content the first codebook actually captures (cross-lingual, low-resource, out-of-domain) is not measured; ablations without distillation are absent.
- Long-form limits: Long-form evaluation is truncated to ~185s due to an 8,192-token limit; behavior beyond this (e.g., 10–30 minutes), and mitigation strategies (sliding windows/chunk stitching) are not explored.
- Prosody over long spans: Objective measures of prosodic consistency (pause timing, breath placement, F0/energy drift) over long narratives are not reported.
- Multi-speaker dialogue: No dedicated benchmark quantifies turn-taking accuracy, speaker ID tag precision/recall, or identity preservation in interleaved, overlapping, or interruptive dialogues.
- Overlap/crosstalk: The system’s ability (or inability) to model overlapping speech or crosstalk is not addressed.
- Controllability semantics: The mapping from natural language instructions to prosodic controls lacks a formal specification (e.g., interpretable sliders for intensity, rate, pitch); conflict resolution for competing tags is unspecified.
- Compositional control: How well multiple simultaneous instructions (e.g., “whisper + angry + faster”) compose, and where failure modes occur, is not analyzed.
- Tag leakage: Methods for preventing inline tags from being spoken aloud (or being misinterpreted in multilingual contexts) are not evaluated.
- Dual-AR ablations: The 4-layer Fast AR capacity, fusion by summation (MCF), and codebook weighting schedule lack ablations; alternatives (e.g., cross-attention fusion, dynamic weighting) are unexplored.
- Depth-wise errors: Error propagation within the depth-wise Fast AR (e.g., from mid/high RVQ layers) and its impact on timbre detail or noise artifacts are not quantified.
- RL algorithm details: Key RL hyperparameters (group size G, sampling budget per prompt, rollout length, KL scheduling) and sensitivity analyses are missing; comparisons to PPO/value-based baselines are absent.
- Credit assignment: How advantages are assigned over extremely long sequences (and whether early vs. late token errors are handled differently) is not studied.
- Reward design: The weights λ of the multi-reward scheme, scheduling, and ablations (disable one reward at a time) are not reported; robustness to reward hacking or overfitting to the in-house ASR/SQA is untested.
- Voiceprint reward: The “external” speaker embedding model is unspecified; its cross-lingual robustness, bias, and vulnerability to spoofing/augmentation are not examined.
- ASR-as-reward risks: Using the same ASR family for both data curation and RL reward risks over-optimizing to that model; evaluations with independent ASR judges are limited.
- LLM-as-a-Judge validity: Correlation of Auto-ATT/Gemini judgments with human ratings (per-language and per-instruction) is not established; rater calibration and inter-judge agreement are not reported.
- Instruction benchmark reproducibility: The Fish Audio Instruction Benchmark’s full specs, prompts, scoring rubric, and raw evaluation artifacts are not clearly released for independent replication.
- Human studies: No large-scale human MOS/ABX studies across languages, styles, and control scenarios are presented to validate LLM-judge conclusions.
- Safety/misuse: No watermarking, cloning-consent enforcement, or voice anti-impersonation safeguards are described; attack surfaces (prompt/voice spoofing) and refusal policies are unspecified.
- Privacy/security: Caching reference-audio KV states raises cross-tenant leakage concerns; isolation, encryption, and cache eviction policies are not discussed.
- Robustness to noisy references: Performance when the reference audio is noisy, far-field, telephony-bandwidth, or reverberant is not benchmarked.
- Edge/hardware diversity: Inference results are only on an H200; performance, memory, and energy under A100/L40S/consumer GPUs, multi-GPU scaling, CPU/on-device, and mobile are not reported.
- Latency realism: TTFA/RTF under cold start, no-cache scenarios, and under real network and I/O constraints (vs. best-case cache hits) are not characterized.
- Compute/carbon: Training/inference compute, energy, and carbon footprint are not provided; efficiency vs. quality trade-offs are unquantified.
- Licensing/usage: The model’s license terms, restrictions on cloning real identities, and compliance with regional regulations are not specified.
- Text-only capability: Maintaining 30% pure-text training is noted, but post-training text-only performance (and potential degradation after audio RL) is not evaluated.
- Adversarial robustness: Susceptibility to adversarial prompts/audio (e.g., jailbreak-style tags, perturbations that bypass rewards) and defenses are not studied.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released models, fine-tuning code, and SGLang-based inference engine (RTF ≈ 0.195, TTFA < 100 ms), assuming server-class GPUs and standard MLOps.
- Real-time, expressive voice chat for assistants and customer support
- Sector: software, telecom, finance, retail
- Tools/workflows: SGLang microservice with WebRTC streaming; per-request “voice reference” caching via RadixCache; inline natural-language style tags (e.g., “calm,” “urgent,” “empathetic”) to adapt tone on-the-fly; A/B routing via KV-cache reuse for popular voices
- Assumptions/dependencies: GPU-backed serving (e.g., A100/H100/H200); consented/custom voices; latency budgets under 250 ms end-to-end; safety policies for impersonation
- Multi-character audiobook and podcast production with director-style control
- Sector: media/entertainment, publishing, creator economy
- Tools/workflows: NLE/DAW plug-ins or API integration; inline per-phrase instructions for emotion/prosody (e.g., “[whisper]”, “[laugh]”, “[angry]”); multi-speaker scripts produced in a single pass; long-form stability for >3 minutes segments
- Assumptions/dependencies: script markup discipline; rights/clearances for cloned voices; GPU batch rendering for throughput
- Film/TV/game dubbing and localization preserving speaker identity
- Sector: media/entertainment, gaming, localization
- Tools/workflows: cross-lingual TTS preserving timbre with instruction prompts; automated dialogue replacement (ADR) pipelines; subtitle-to-speech workflows with inline emphasis and timing
- Assumptions/dependencies: alignment to scene timing; verified linguistic QA for low-resource languages; voice-rights management
- Interactive NPCs and dynamic dialogue in games
- Sector: gaming
- Tools/workflows: engine plugins (Unity/Unreal) calling a streaming TTS endpoint; per-state emotion control; caching for recurring characters; multi-speaker scenes generated in a single pass
- Assumptions/dependencies: session-scale GPU concurrency; voice style guides; content safety for UGC inputs
- EdTech reading tutors and language-learning prosody practice
- Sector: education
- Tools/workflows: controllable prosody/emotion to teach intonation; code-switching and foreign-word robustness; tagged examples (“slowly, with clear stress on question intonation”)
- Assumptions/dependencies: curriculum-aligned tagging; guardrails for age-appropriate content; multilingual ASR for assessment if needed
- Accessibility: expressive screen readers and long-form document narration
- Sector: accessibility, public sector, productivity software
- Tools/workflows: long-form, stable synthesis for textbooks, legal docs, and news; per-section style control (e.g., “read footnotes neutrally,” “add emphasis to definitions”)
- Assumptions/dependencies: integrations with reading apps; user-controlled pacing and emphasis; on-device caching for frequent content
- Contact-center IVR and proactive notifications with brand-consistent voices
- Sector: telecom, finance, logistics, utilities
- Tools/workflows: IVR prompts with emotion and pacing tuned to customer state; RadixCache voice reuse to cut prefill cost; multi-turn back-and-forth synthesis
- Assumptions/dependencies: SLA and observability for latency; consented brand voices; regulatory disclosures for synthetic speech
- Marketing and ad-ops: rapid voiceover production with precise tone
- Sector: advertising, e-commerce
- Tools/workflows: creative briefs translated to inline instructions (“upbeat, confident, faster pace”); batch render variants for multivariate testing
- Assumptions/dependencies: agency review pipeline; content rights; brand governance for synthetic voices
- Live webinars/demos with synthetic co-hosts
- Sector: B2B SaaS, events
- Tools/workflows: stream S2 in real time as a co-presenter; programmatic style changes for emphasis and transitions
- Assumptions/dependencies: stable connectivity; audio mixing; clear disclosure to attendees
- Synthetic data generation for ASR, diarization, and speech QA
- Sector: AI/ML infrastructure
- Tools/workflows: multi-speaker/multi-turn corpora with ground-truth speaker turns and paralinguistics; controllable accent/emotion distributions; scalable generation with SGLang batching
- Assumptions/dependencies: domain-shift checks; licensing of synthetic datasets; balanced label distributions
- Audio data curation at scale using the released pipeline concepts
- Sector: audio platforms, data providers
- Tools/workflows: adopt speech-quality and rich-transcription models to filter and annotate uploads; reuse as reward functions to avoid train–eval mismatch
- Assumptions/dependencies: availability of comparable ASR/speech-quality models; GPU capacity for bulk scoring; policy for removing low-quality or infringing content
- Academic benchmarking and research baselines for controllable TTS
- Sector: academia, open-source
- Tools/workflows: Fish-Instruction-Benchmark for fine-grained control; GRPO-style multi-reward RL code; reproducible SGLang inference stacks
- Assumptions/dependencies: research compute; adherence to model/data licenses; transparent reporting
- Public-sector information and emergency alerts in multiple languages
- Sector: government, public health
- Tools/workflows: multilingual, clear, and calm TTS with fine-grained emphasis; quick updates and re-reads with consistent timbre
- Assumptions/dependencies: proofreading workflows; legal requirements for synthetic speech disclosures; local language QA
- Personal “read-it-later” and productivity voice apps
- Sector: consumer software
- Tools/workflows: user-selectable voices with plain-English style controls (“read faster and more energetic in bullet sections”)
- Assumptions/dependencies: cloud inference costs; voice library licensing; user consent for custom voices
Long-Term Applications
These applications are promising but require further research, optimization, or standardization (e.g., model compression, cross-system integration, regulatory frameworks).
- Real-time speech-to-speech translation preserving speaker identity and emotion
- Sector: communications, media
- Tools/workflows: ASR → MT → S2 TTS with emotion/control tags propagated; simultaneous streaming
- Assumptions/dependencies: ultra-low-latency ASR/MT; robust prosody transfer across languages; echo cancellation and jitter control
- On-device or edge TTS for mobile, wearables, and AR/VR
- Sector: consumer electronics, XR
- Tools/workflows: pruning, distillation, and quantization of the Dual-AR stack; hardware-aware scheduling of LLM + vocoder
- Assumptions/dependencies: model compression without quality loss; NPU/DSP acceleration; battery constraints
- A “voice direction” copilot for creators
- Sector: media/entertainment, creator tooling
- Tools/workflows: timeline-aware assistant that rewrites scripts with inline instructions; interactive previews; constraint solving for timing and emotion arcs
- Assumptions/dependencies: robust LLM-to-TTS instruction mapping; NLE integrations; user-in-the-loop QA
- Industry standard for inline prosody/emotion control tags
- Sector: standards bodies, software
- Tools/workflows: a cross-vendor markup or natural-language convention for fine-grained control interoperable across TTS engines
- Assumptions/dependencies: multi-stakeholder coordination; backward compatibility with SSML; evaluation suites (e.g., Fish Instruction Benchmark)
- Safety, provenance, and consent frameworks for voice cloning
- Sector: policy, compliance, platform governance
- Tools/workflows: opt-in consent capture; watermarking/provenance tags; deepfake detection integrations; policy enforcement at upload and inference
- Assumptions/dependencies: reliable audio watermarking under transformations; legal alignment (jurisdiction-dependent); platform-wide adoption
- Clinical and therapeutic applications (e.g., CBT role-play, speech therapy)
- Sector: healthcare
- Tools/workflows: controlled emotion ranges; clinician dashboards; patient-tailored prosody to reduce anxiety or support speech practice
- Assumptions/dependencies: clinical trials and approvals; stringent privacy and safety guardrails; bias and harm audits
- Training simulations and multi-agent scenario generation
- Sector: enterprise L&D, public safety, sales enablement
- Tools/workflows: multi-speaker scenes with controllable personalities, stress levels, and interruptions; automated scenario grading with ASR rewards
- Assumptions/dependencies: domain-specific evaluation rubrics; scenario authoring tools; secure data handling
- Low-resource language revitalization and community voice preservation
- Sector: public-interest tech, cultural heritage
- Tools/workflows: community-driven data collection; pipeline reuse for quality filtering and RL alignment; style transfer from related languages
- Assumptions/dependencies: participatory governance; linguistic expertise; funding for sustainable datasets
- Generalizing multi-reward RL alignment to other generative audio domains
- Sector: music/sfx, multimodal AI
- Tools/workflows: reward suites for rhythm/harmony/timbre (music) or semantics/context (multimodal); GRPO-style training at scale
- Assumptions/dependencies: reliable, hack-resistant reward models; scalable rollout infrastructure; careful preference data curation
- Expressive voices for social/assistive robots tied to affective state
- Sector: robotics, eldercare
- Tools/workflows: affective state estimation driving natural-language style prompts; persona and context memory for consistent timbre
- Assumptions/dependencies: robust affect detection; safety constraints; long-horizon voice consistency in edge environments
- Meeting dubbing, anonymization, and cross-lingual re-voicing
- Sector: enterprise productivity, privacy tech
- Tools/workflows: real-time TTS overlays preserving role-specific styles; privacy-preserving voice re-synthesis (same style, anonymized identity)
- Assumptions/dependencies: diarization accuracy; privacy/legal controls; user consent flows
- Regulatory toolkits for synthetic speech labeling and audits
- Sector: policy, platforms
- Tools/workflows: ATT-style indistinguishability audits; periodic conformance tests for instruction-following and misuse risk; labeling standards
- Assumptions/dependencies: agreed-upon thresholds; public reporting; third-party certification ecosystems
Notes on feasibility and dependencies (cross-cutting):
- Compute and cost: Reported RTF/TTFA are on server-grade GPUs (e.g., H200). Throughput and latency on commodity hardware will be lower unless models are compressed or served via GPU clouds.
- Rights and consent: Custom voice cloning requires explicit consent, license management, and safeguards against impersonation.
- Multilingual coverage: Strong results across many languages, but gaps persist in low-resource settings; additional data and alignment may be needed.
- Pipeline components: The paper’s reward models (ASR, speech quality) are critical for alignment; comparable models are needed if replicating the RL pipeline.
- Context limits: Current long-form context is finite; ultra-long content may require chunking or hierarchical prompting.
- Safety: Watermarking, provenance, and misuse detection are not intrinsic to S2; they should be layered into production deployments.
Glossary
- Acoustic decoder: A model that reconstructs full audio waveforms from high-level or discrete acoustic representations. "which are then decoded into the full waveform by a separate acoustic decoder"
- Advantage (RL): The difference between a sampled reward and a baseline used to guide policy updates without a value network. "which eliminates the value network entirely by estimating advantages from group-level statistics."
- ASR (Automatic Speech Recognition): A system that converts speech audio into text, often also producing rich annotations. "a rich-transcription ASR model"
- Audio Turing Test (ATT): A benchmark where evaluators classify audio as Human, Machine, or Unclear to assess human-likeness. "we adopt the Audio Turing Test (ATT) framework."
- Audio tokenizer: A module that converts continuous audio into discrete token sequences suitable for sequence modeling. "Our audio tokenizer is built upon the architecture of the Descript Audio Codec (DAC)"
- Autoregressive: A generation process where each next token is conditioned on previously generated tokens. "The Fast AR then autoregressively generates"
- Causal convolutions: Convolutions that only use past context to enable streaming and low-latency generation. "replacing standard convolutions with masked causal convolutions."
- Character Error Rate (CER): A metric computing character-level transcription errors as a percentage. "Character Error Rate (CER)"
- Codebook: A discrete set of vector entries used by quantizers to represent features; in RVQ, multiple codebooks capture different detail levels. "utilizing codebooks ( in our model): the primary codebook serves as the semantic codebook"
- ConvNeXt V2: A convolutional neural network architecture used here to extend encoder downsampling. "ConvNeXt~V2"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "compute cosine similarity."
- CUDA graph replay: An optimization that records and replays GPU workloads to reduce kernel launch overhead. "CUDA graph replay"
- Decoder-only Transformer: A Transformer architecture using only decoder blocks for autoregressive modeling. "retains the decoder-only Transformer backbone"
- DiffRO: A training or inference variant (referenced in baselines) combined with TTS models; specifics are external to this paper. "CosyVoice3-1.5B + DiffRO"
- Direct Preference Optimization (DPO): An RL method that optimizes models directly from preference data without explicit reward modeling. "Direct Preference Optimization (DPO)"
- Dr.GRPO: A GRPO variant that adjusts normalization to mitigate difficulty bias in group-based advantage estimation. "Following Dr.GRPO, we remove normalization by the intra-group standard deviation"
- Dual-Autoregressive (Dual-AR): An architecture that separates temporal semantic generation (Slow AR) from depth-wise acoustic detail generation (Fast AR). "we apply a Dual-Autoregressive (Dual-AR) architecture"
- EVA-GAN: A generative adversarial network architecture used here as a high-quality audio decoder. "we employ the structure of EVA-GAN as our generator"
- Focal loss: A loss function that down-weights easy examples to focus learning on hard cases. "using a combined objective of MSE and focal loss"
- Fully Sharded Data Parallel (FSDP): A distributed training approach that shards model parameters, gradients, and optimizer states across devices. "The entire pre-training framework is built upon Fully Sharded Data Parallel (FSDP)"
- GAN loss: An adversarial training objective in which a generator and discriminators are optimized together. "We employ a composite GAN loss framework"
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages from group-level statistics, avoiding a value network. "we implement a variant of GRPO"
- Highest density interval (HDI): A Bayesian interval containing the most probable values of a posterior distribution at a given mass (e.g., 95%). "95\% highest density intervals (HDI)"
- I/O bypass: A serving optimization that skips standard tokenization/detokenization paths for custom token streams. "we implemented an I/O bypass at the API level"
- KL divergence: A measure of how one probability distribution diverges from a reference distribution, used here as a regularizer. "per-token KL divergence"
- KV cache: Cached key/value attention states that speed up autoregressive decoding by avoiding recomputation. "paged KV cache"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adaptation matrices into pretrained weights. "we design a LoRA weight-swap mechanism"
- Modality interleaving: A training strategy that interleaves text and audio tokens to enforce alignment and stability. "we apply a modality interleaving strategy"
- Multi-Codebook Fusion (MCF): A mechanism that fuses multiple RVQ codebook embeddings (and LM embeddings) into a single input for the next step. "Multi-Codebook Fusion (MCF)."
- Multi-period discriminator: A GAN discriminator specialized to capture periodic patterns in audio. "a multi-period discriminator to capture periodic signals"
- Multi-resolution discriminator: A GAN discriminator that evaluates audio at multiple spectral resolutions. "a multi-resolution discriminator for spectral consistency"
- Multi-scale STFT discriminator: A GAN discriminator leveraging STFTs at different scales to ensure spectral detail and phase coherence. "a multi-scale STFT discriminator to ensure high-frequency detail and phase coherence"
- MPS (NVIDIA Multi-Process Service): A GPU feature that allows concurrent execution of kernels from multiple processes/streams. "we therefore leverage MPS to co-schedule vocoder decoding with LLM decoding"
- Paralinguistic: Non-lexical vocal features such as emotion, prosody, and laughter that convey meaning beyond words. "annotating paralinguistic features"
- Posterior mean: The expected value of a posterior distribution, used here to summarize ATT outcomes. "achieves a posterior mean of 0.483"
- Proximal Policy Optimization (PPO): A popular RL algorithm using clipped policy updates to stabilize training. "Proximal Policy Optimization (PPO)"
- RadixAttention: An attention optimization in SGLang enabling efficient prefix caching for faster decoding. "RadixAttention for efficient prefix caching."
- RadixCache: A cache structure in SGLang for prefix states, extended here to handle joint semantic/acoustic token keys. "We extend the original RadixCache"
- Radix tree: A tree data structure enabling efficient prefix-based caching and retrieval of KV states. "SGLangâs Radix tree caches the corresponding KV states."
- Residual Vector Quantization (RVQ): A hierarchical quantization scheme where successive codebooks encode residuals for finer detail. "Residual Vector Quantization (RVQ) strategy"
- Reward modeling: Training or using models to score outputs so they can serve as reward signals for RL. "voice-quality assessment, and reward modeling."
- RoPE positional embeddings: Rotary positional embeddings that encode token positions via rotation in embedding space. "RoPE positional embeddings."
- rsLoRA (rank-stabilized LoRA): A LoRA variant with stabilization techniques and specified rank/scale to improve training stability. "rank-stabilized LoRA (rsLoRA, )"
- Schulman estimator: A method to estimate KL divergence or related quantities per token for RL regularization. "computed via the Schulman estimator."
- SGLang: A high-performance serving framework for LLMs (extended here to TTS) with advanced scheduling and caching. "our inference engine is built upon SGLang"
- Semantic distillation: Training to force a bottleneck (e.g., a codebook) to retain linguistic information by predicting representations from a semantic model. "we adopt semantic distillation"
- Short-Time Fourier Transform (STFT): A time-frequency transform applying Fourier analysis on short, overlapping windows. "multi-scale STFT discriminator"
- Supervised fine-tuning (SFT): Post-pretraining optimization on labeled data to improve specific behaviors or controls. "After pre-training, we perform SFT on curated internal high-quality labelled data"
- Temporal Semantic Backbone (Slow AR): The Dual-AR component that plans semantic and coarse prosodic content over time. "Temporal Semantic Backbone (Slow AR)"
- Time-to-First-Audio (TTFA): The latency from request to first audio output in a streaming TTS system. "Time-to-First-Audio (TTFA)."
- Transformer Bottleneck: An architectural module using Transformer blocks as a bottleneck to model long-range dependencies with bounded memory. "Transformer Bottleneck."
- Value network: In actor-critic RL, a model estimating state (or token-level) value to compute advantages; omitted in GRPO-style methods. "which eliminates the value network entirely"
- Voice Activity Detection (VAD): An algorithm that detects speech segments within audio, enabling utterance-level segmentation. "Voice Activity Detection (VAD)"
- Voiceprint model: A model that extracts speaker embeddings for identity comparison and similarity scoring. "utilizes an external voiceprint model"
- Vocoder: A neural audio decoder that reconstructs waveforms from intermediate acoustic tokens or features. "co-schedule vocoder decoding with LLM decoding"
- Warmup-Stable-Decay (WSD): A learning-rate schedule with phases for warmup, stability, and decay to improve large-scale training. "a Warmup-Stable-Decay (WSD) scheduling strategy"
- w2v-BERT 2.0: A self-supervised speech representation model used here as a semantic target and in quality modeling. "a pre-trained w2v-BERT~2.0 model"
- Word Error Rate (WER): A standard ASR metric measuring word-level transcription errors as a percentage. "Word Error Rate (WER)"
- Zero-shot: Performing a task without task-specific fine-tuning, relying on generalization from prior training. "the model's zero-shot instruction-following capabilities"
Collections
Sign up for free to add this paper to one or more collections.