- The paper introduces SafeRoPE, a method using head-wise RoPE manipulation to selectively suppress unsafe semantics in multi-modal diffusion transformers.
- It employs SVD to identify safety-critical heads and leverages Latent Risk Scores to quantify unsafe subspace activations for targeted intervention.
- Experimental results demonstrate significant safety improvements, reducing unsafe rates from 38.8% to 15.4% while preserving image fidelity and prompt alignment.
Introduction
Advances in text-to-image (T2I) generative modeling—especially rectified-flow transformers such as FLUX and SD3—have improved prompt alignment, image fidelity, and coverage. However, increased model scale and inherent multimodal flexibility expose these systems to adversarial prompts (jailbreaks) and enable the generation of unsafe (e.g., explicit, violent) content. Existing safety methods, including concept unlearning and attention modulation, either lack architectural compatibility with transformer-based diffusion models or suffer from inefficiency and excessive distortion of benign outputs. The presented work systematically studies the internal mechanics of multi-modal diffusion transformers (MMDiT) and introduces SafeRoPE: a method that achieves fine-grained, data-driven safety alignment via head-specific rotary positional embedding (RoPE) manipulation, targeting unsafe subspaces.
Positional Encoding, Unsafe Subspace, and Head-level Risk
The study begins by analyzing positional encoding in FLUX.1, which, unlike previous architectures, employs RoPE to encode relative position within queries and keys post–projection. Each token is equipped with three positional vectors, dictating how RoPE rotates their Q/K representations based on position. This mechanism enables efficient encoding for long, unified text-image sequences.
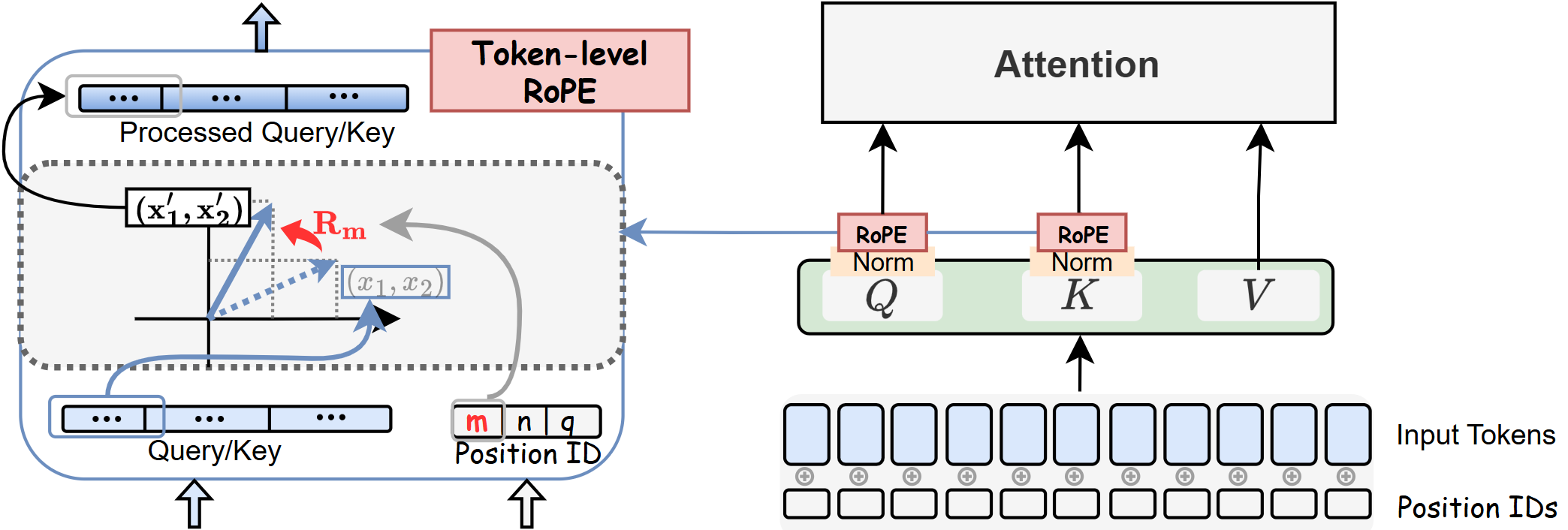
Figure 1: Each token in FLUX.1 is associated with three positional vectors, with RoPE rotations applied per segment of Q/K vectors to encode relative position.
Empirical probing reveals that, for FLUX.1-dev, random perturbation of text positional IDs via RoPE disrupts unsafe semantic generation (e.g., explicit, violent, or stylistic prompts), while benign generations are largely robust—demonstrating differential RoPE sensitivity for risky versus safe semantics.

Figure 2: Differential safety sensitivity: random perturbation of RoPE textual positions impairs explicit/unsafe generations, but not benign generations.
Unsafe Subspace Discovery and Safety-Critical Head Identification
A central insight is that unsafe concepts activate interpretable, low-dimensional subspaces in specific attention heads. Given MMDiT’s large number of heads (>1,000), the method employs SVD to estimate “unsafe subspaces” from Q/K activations corresponding to curated unsafe prompts. For each head, projections onto these unsafe components are quantified through a Latent Risk Score (LRS), measuring subspace alignment. An explicit Head Discrimination Score (HDS) distinguishes safety-critical heads (where the LRS difference between unsafe and safe prompts exceeds a set threshold), isolating a compact set of heads responsible for carrying risky semantics.
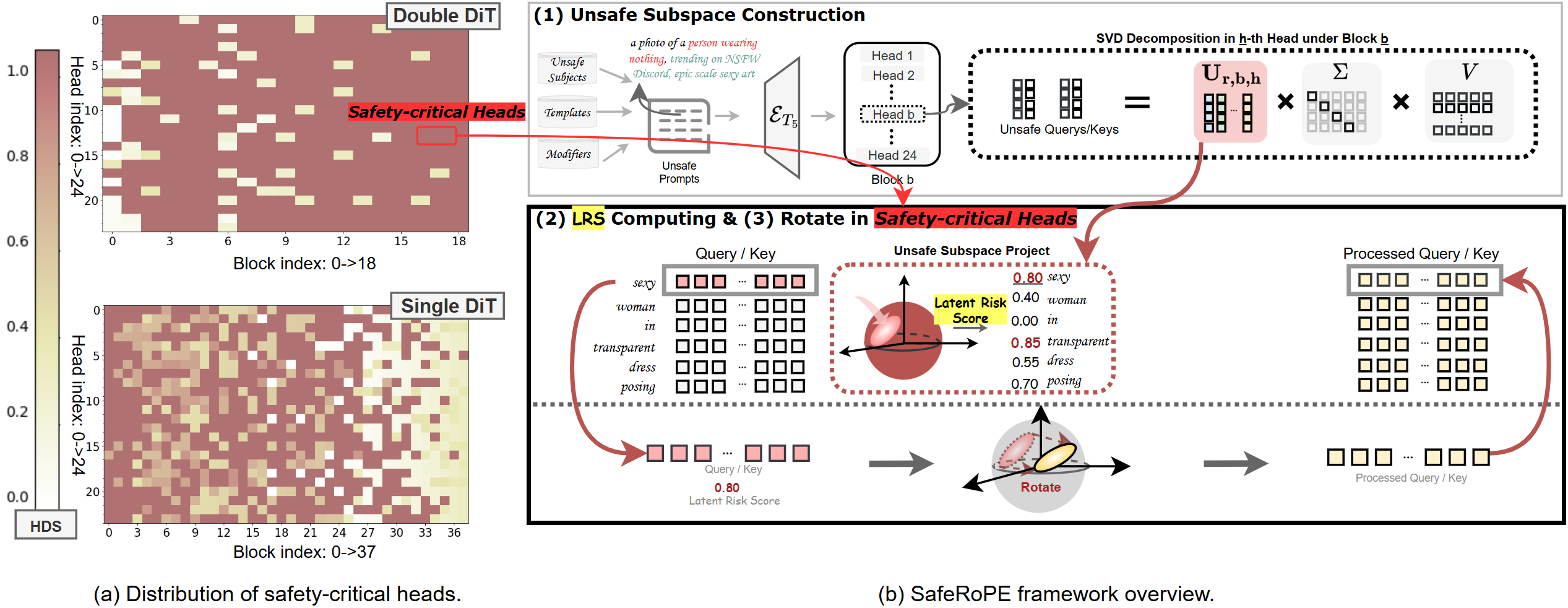
Figure 3: SafeRoPE pipeline: unsafe subspaces identified via head-level SVD, LRS calculated for each token, and LRS-guided subspace rotation applied in safety-critical heads.
Ablation demonstrates that broad perturbations (acting across all heads) unnecessarily corrupt benign generations, verifying the necessity of selective intervention.

Figure 4: LRS-guided perturbations on all heads degrade utility, whereas restriction to safety-critical heads controls unsafe features with minimal side effects.
Additionally, detection experiments confirm that safety-critical heads offer sharper separation between prompt types and facilitate accurate unsafe-token localization.
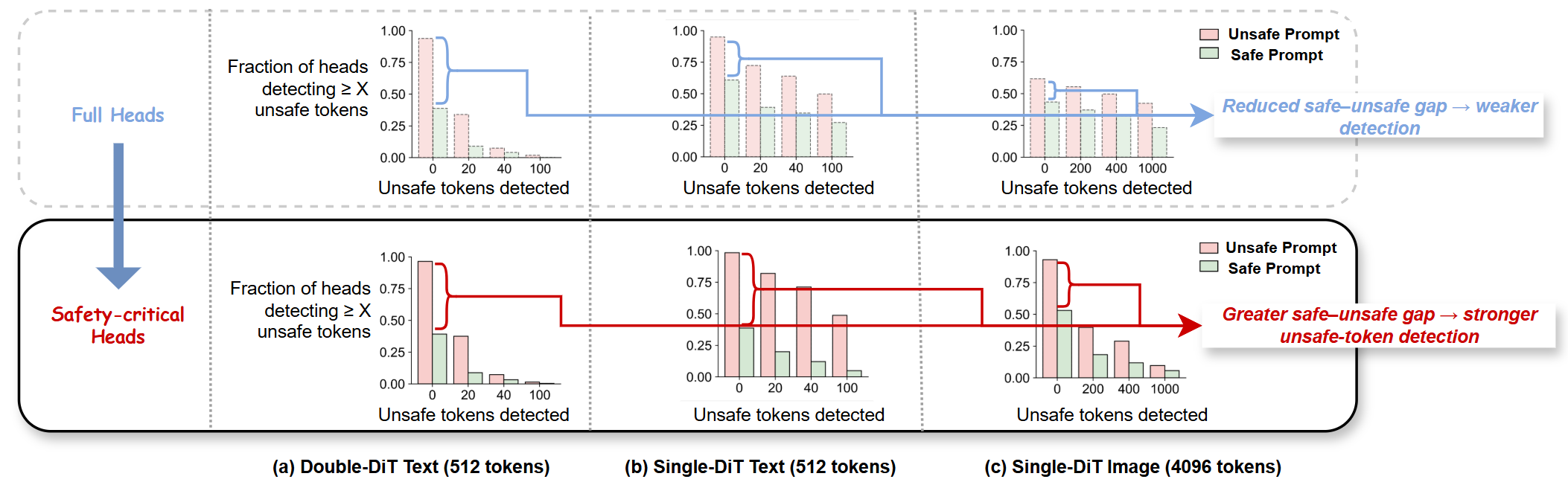
Figure 5: Projection-based unsafe token detection: safety-critical heads yield superior discrimination between explicit and benign prompts.
SafeRoPE: Risk-aware Head-wise Rotational Manipulation
SafeRoPE’s central mechanism is to replace the standard RoPE rotation in each safety-critical head with a learned, LRS-modulated orthogonal transformation—trained to maximally rotate unsafe directions (as determined by SVD) and leave safe subspaces invariant. This rotation is parameterized using a low-rank, skew-symmetric matrix (exponential map ensures orthogonality), decomposing each Q/K vector into unsafe and safe components. Only the unsafe part is rotated, localized to the subspace, maintaining fidelity for the rest.
The method is trained via a two-level bi-objective: unsafe prompts maximize deviation between original and rotated model outputs (encouraging suppression), while safe prompts minimize this deviation (preserving fidelity). All parameters are kept frozen except the rotation matrices; only those in safety-critical heads are optimized.
Experimental Results
Evaluation is conducted on FLUX.1-dev and FLUX.1-sch (Lightweight FLUX variants), across a suite of erasure tasks (nudity, violence, IP character, art style), standard benchmarks (I2P, Unsafe-1K), and benign prompt sets (COCO-1K). Metrics include CLIP and VQA scores for semantic alignment, FID for image quality, and automated unsafe detection for safety.
SafeRoPE consistently reduces unsafe rates (UR) on explicit and adversarial prompt sets well below those of baseline approaches (ESD, SLD, UCE, DES, EraseAnything), while preserving or improving FID, CLIP, and VQA scores—UR on Unsafe-1K is reduced from 38.8% (FLUX.1) to 15.4% (SafeRoPE), and explicit I2P unsafe rates drop to 7.0% with negligible impact on benign outputs. Notably, SafeRoPE’s learned rotations generalize across model variants; matrices trained on FLUX.1-dev improve FLUX.1-sch safety without retraining.
Qualitative comparisons demonstrate that SafeRoPE avoids common pitfalls such as unwanted structure deletions or text corruption observed in existing unlearning strategies.

Figure 6: Qualitative comparison: SafeRoPE effectively suppresses target concepts (nudity, style, IP) while maintaining prompt fidelity and visual quality, avoiding artifacts and errors common in baseline methods.
Ablation analysis further substantiates design choices: (1) sharing versus independent rotations, and (2) rank of the unsafe subspace. Lower rotation ranks produce under-intervention; high ranks degrade utility. The deployed configuration achieves strong safety-fidelity tradeoff.

Figure 7: Ablation results: optimal SafeRoPE configuration maintains benign fidelity while maximizing unsafe suppression; alternative strategies cause under- or over-correction.
Additional visualizations confirm precise, sparse, and effective localization of unsafe regions, and indicate that SafeRoPE maintains semantic content across benign categories while targeting only undesired features.

Figure 8: SafeRoPE achieves targeted erasure of explicit content without significant impact on non-explicit prompts in I2P and Unsafe-1K.
Implications and Future Directions
SafeRoPE demonstrates a data-driven, efficient, transformer-compatible approach to semantic safety via localized, risk-aware rotational intervention within attention heads. The method addresses key challenges in model alignment with minimal architectural overhead and without costly full-model retraining, supporting rapid adaptation to new risk domains and model variants.
By leveraging RoPE’s geometric expressivity for selective content suppression, SafeRoPE establishes a foundation for extending rotational interventions to broader modalities. The approach is architecture-agnostic: the algorithm applies to any transformer using RoPE, including emerging LLMs. The demonstrated interpretability of safety-critical subspaces suggests further opportunities for broader safety and bias mitigation, controllable editing, and transparent auditing.
Conclusion
The SafeRoPE framework offers a principled, efficient, and interpretable approach to concept-level safety alignment in rectified-flow transformer-based generative models. By isolating unsafe subspaces in attention heads and attaching risk-specific head-wise rotational operators via RoPE, SafeRoPE achieves robust suppression of adversarial or harmful semantics without degrading benign generation or incurring significant computational cost. The findings motivate further exploration of head-level latent geometry for flexible, extensible model alignment across both vision and language domains.

