- The paper introduces a dual-grouping RL framework to counter reward collapse by generating diverse spatiotemporal video variants and textual responses.
- It employs an importance-aware frame selection strategy based on cross-modal scoring to maintain high reward variance and guide learning.
- Empirical results show consistent improvement across VQA benchmarks, enabling robust spatiotemporal reasoning in video QA tasks.
Structured Spatiotemporal Exploration in Reinforcement Learning for Video Question Answering
Introduction
The paper "STRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering" (2604.01824) addresses core optimization challenges in reinforcement learning (RL) applied to large multimodal models (LMMs) for video question answering (VQA). The authors identify a critical limitation in existing group-based policy optimization methods—particularly the collapse of reward variance during RL fine-tuning, which significantly hinders stable policy improvement. STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration) introduces structured spatiotemporal variant construction and joint input-output grouping to explicitly leverage video structure during RL. The framework also incorporates a principled, importance-aware frame selection strategy informed by cross-modal semantic relevance. This dual-grouping paradigm provides a foundation for more stable, efficient optimization and empirically yields significant improvements across several challenging VQA benchmarks.
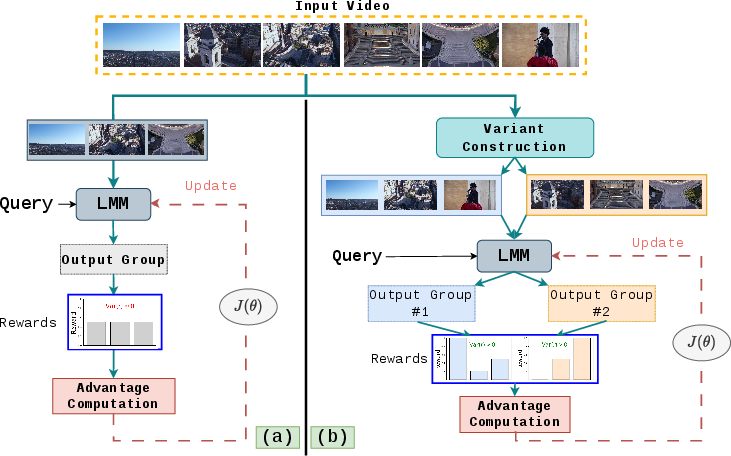
Figure 1: STRIVE prevents advantage collapse in video RL by creating multiple spatiotemporal video variants (panel b), maintaining higher group reward variance compared to fixed video inputs (panel a).
Methodology
Zero-Advantage Collapse in Group-Based RL
Group Relative Policy Optimization (GRPO) offers efficient RL post-training by optimizing over groups of sampled responses, calculating relative advantages without an explicit value function. However, when response diversity is insufficient (i.e., when all responses are nearly equally correct or incorrect for a given video-question pair), intra-group reward variance vanishes. This can lead to either vanishingly small or unstable gradients, impeding effective policy improvement. Prior solutions (e.g., Dr.GRPO) modify normalization or reward shaping, but they act solely on the textual domain and ignore potential visual sources of diversity.
STRIVE: Dual Grouping over Spatiotemporal Variants and Text
STRIVE fundamentally expands the grouping dimension by jointly sampling both multiple textual generations and multiple structured video variants per QA pair. For each input video, the framework generates M spatiotemporal variants using a targeted transformation module and, for each variant, produces G textual responses. The RL objective is then optimized over the entire G×M pool, with normalized advantages computed jointly. This dramatically increases the reward variance available per update and regularizes the model to maintain cross-variant consistency in its reasoning.
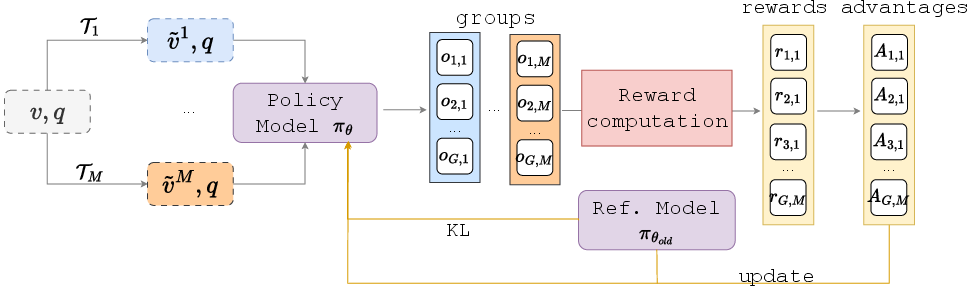
Figure 2: STRIVE’s framework: from a single input (v,q), multiple video variants and group textual generations are produced, advantages are jointly normalized in the G×M matrix.
Importance-Aware Variant Construction
Beyond naive temporal or stochastic perturbations, STRIVE introduces an importance-based sampling mechanism. Per-frame relevance is estimated by a cross-modal scoring function (e.g., dot product of normalized vision and language embeddings), conditioned on the input query. Video frames with higher query alignment are sampled preferentially, but with temperature-scaled stochasticity to preserve exploration and prevent overfitting to isolated frames. Temporal partitioning ensures context is retained, avoiding the loss of global scene structure.
This importance-aware grouping is robust—it guides the model toward visually and semantically salient content, supporting stronger grounding of textual outputs. Ablations confirm that cross-modal similarity scoring outperforms both deterministic grouping and gradient-based attribution mechanisms for most settings.
Experimental Results and Analysis
The authors conduct extensive, controlled experiments across six VQA benchmarks (VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, PerceptionTest), utilizing both Qwen2.5-VL-7B and the more advanced Qwen3-VL-8B architectures. For all settings, a constant frame and generation budget is enforced to isolate the effect of STRIVE's grouping.
Key empirical findings:
- Compared to standard GRPO, STRIVE achieves a consistent ∼1 point improvement in average accuracy across all tasks and LMM architectures.
- Unlike GRPO, STRIVE does not degrade temporal or spatial reasoning performance on any benchmark when scaling to larger LMMs.
- STRIVE effectively suppresses the fraction of zero-advantage updates, maintains higher reward variance, and stabilizes gradient norms during RL training.
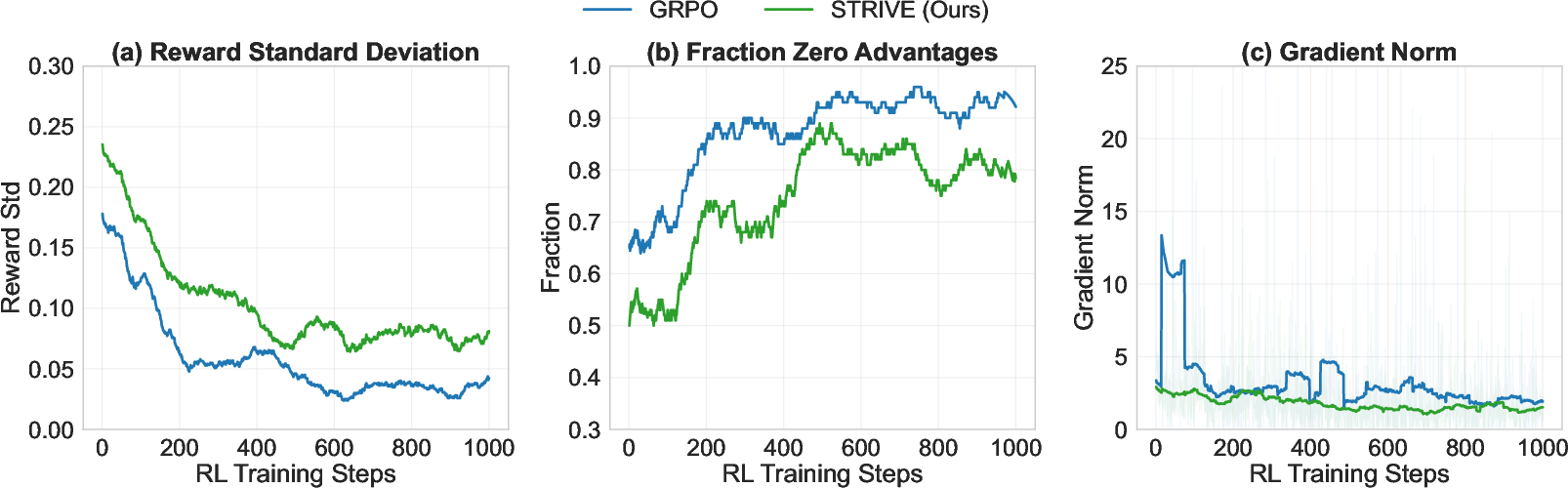
Figure 3: STRIVE maintains higher reward variance (a), eliminates zero-advantage training steps (b), and stabilizes the gradient norm (c), overcoming the critical optimization instability of GRPO.
Ablation studies reveal:
- Importance-based grouping (with semantically grounded frame selection) outperforms purely stochastic or deterministic temporal grouping strategies.
- The performance is robust to the scoring model used for relevance estimation; lightweight scorers (e.g., LLaVA-OV-0.5B) strike a balance between computational speed and semantic completeness.
- An optimal trade-off exists between the number of visual variants and textual generations: splitting the budget evenly (e.g., M=2,G=4) achieves best results.
- STRIVE provides consistent, often additive gains when combined with other RL algorithms (e.g., Dr.GRPO).
Qualitative analysis further demonstrates that STRIVE enables the model to (i) isolate frames relevant to the posed question and (ii) correctly resolve fine-grained temporal and causal relations, even in the presence of substantial visual distractions.

Figure 4: STRIVE (top) accurately selects salient driving frames for the correct answer, unlike GRPO. (Bottom) STRIVE maintains fine-grained temporal orderings, reflecting superior spatiotemporal reasoning.
Theoretical and Practical Implications
From an algorithmic perspective, STRIVE provides a general and modular improvement to relative policy optimization methods for RL-fine-tuned LMMs in multimodal settings. By injecting semantically meaningful structure into the group dimension, the approach regularizes the optimization landscape, always ensuring informative gradient updates and preventing reward/advantage collapse. This is particularly relevant for tasks with long input horizons (video, document, or multi-hop reasoning).
Practically, STRIVE's schema aligns model learning much closer to human-style "evidence grouping," exposing the policy to a variety of complementary perceptual perspectives during training. For deployment in highly safety- or accuracy-critical domains (e.g., video forensics, autonomous driving, surveillance, instructional QA), these improvements in stability, robustness, and consistency are substantial.
Future work may explore extending this dual-grouping strategy to other modalities (audio, scientific time series), integrating more elaborate semantic sampling schemes, or combining STRIVE with active perception and adaptive input selection architectures.
Conclusion
STRIVE establishes structured spatiotemporal variant construction as an essential paradigm for RL optimization in video reasoning LMMs. It sidesteps the failure modes of existing group-based RL by leveraging input diversity, semantically aligned exploration, and robust joint normalization. The framework scales across model sizes, RL baselines, and task types, supporting the development of more stable and reliable multimodal AI systems. The findings directly inform practical RL fine-tuning pipelines for next-generation video LLMs and highlight promising avenues for adaptive exploration in high-dimensional multimodal learning (2604.01824).