- The paper introduces a domain-incremental framework using disentangled feature representation and adaptive weight fusion to enhance perception in dynamic settings.
- It employs a dual-stream encoder with separate semantic and domain branches, leveraging cross-gradient blocking to prevent information leakage.
- Empirical results on CDDB, CORe50, and DomainNet show improvements up to 9.96% without using domain labels or exemplar replay, ensuring both privacy and efficiency.
Robust Embodied Perception in Dynamic Environments via Disentangled Weight Fusion
Introduction
Dynamic and open environments present persistent challenges in robust perceptual modeling for embodied agents, such as autonomous vehicles and service robots. In contrast to traditional static vision tasks, embodied perception involves continuously shifting sensory data streams due to uncontrolled environmental variations—illumination, weather, sensor noise, and more—which introduce domain shifts that must be solved under strict resource and privacy constraints. The paper "Robust Embodied Perception in Dynamic Environments via Disentangled Weight Fusion" (2604.01669) presents a domain-id and exemplar-free domain incremental learning (DIL) paradigm tailored for embodied multimedia systems, targeting robust cross-domain generalization and drastic reduction of catastrophic forgetting.
Limitations of Prior DIL Methods
Conventional DIL approaches often rely on advance knowledge or prediction of domain ids at test time, which is infeasible in deployment settings involving unknown or continually changing environments. Prompt-based and dual-branch domain models typically degrade to simpler task-incremental learning (TIL) under these constraints, inherently depending on prior information not available in practice. Furthermore, these methods are susceptible to overfitting context-specific perceptual artifacts, resulting in poor transferability and weak performance in unseen domains, as shown by notable performance drops when transferring to novel test domains (Figure 1).
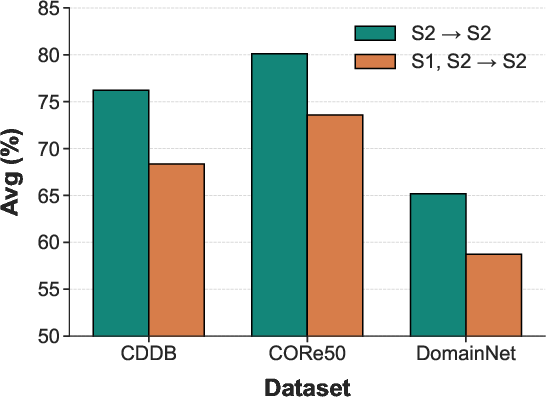
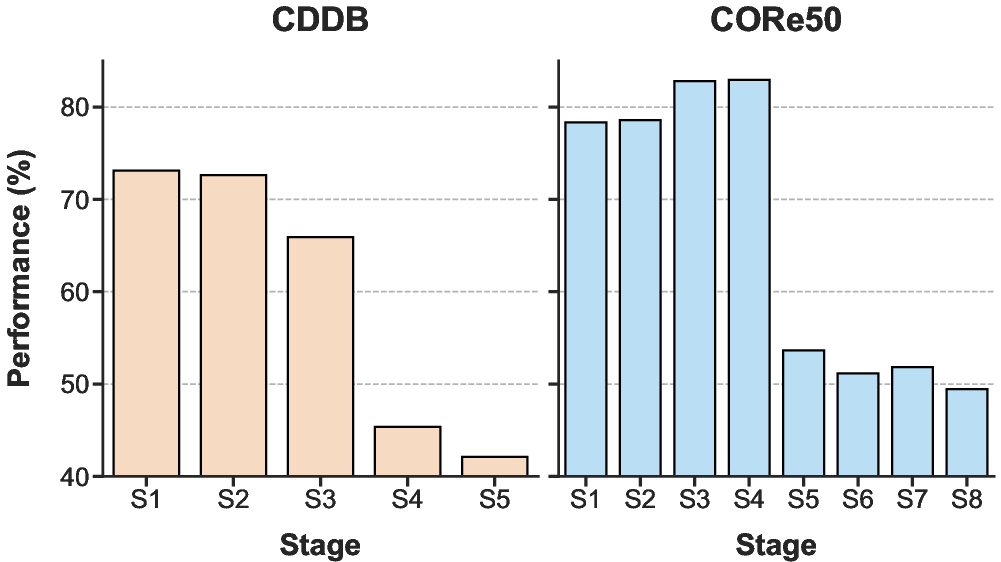
Figure 1: The performance of method S-iPrompts under different experimental conditions, highlighting significant degradation on unseen domains.
Additional challenges arise from the storage and computational overheads associated with experience replay, which are prohibitive in privacy-sensitive or memory-constrained scenarios. Regularization and distillation-based methods have been shown inadequate in managing the stability-plasticity balance necessary for open-environment DIL.
Disentangled Weight Fusion Framework
To circumvent these critical bottlenecks, the paper introduces a DIL framework built upon two major innovations: a disentangled feature representation mechanism and adaptive weight fusion. This system aims to achieve both environment-agnostic feature extraction and continual integration of new domain knowledge, without reliance on domain labels or rehearsal.
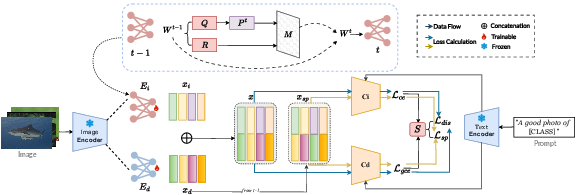
Figure 2: The framework of disentangled representation and weight fusion for DIL, illustrating the division into intrinsic and domain streams and adaptive parameter inheritance.
Disentangled Feature Representation
At the architectural level, a dual-stream encoder, initialized via a pre-trained CLIP backbone, separates input representations into intrinsic (semantic) and domain (environmental) latent spaces. Cross-gradient blocking and exclusive branch optimization prevent semantic leakage between these spaces, enforcing orthogonality. The use of a re-weighting strategy, based on the discrepancy between intrinsic and domain classifier losses, biases the learning process towards samples not easily resolved by environmental cues, thus promoting genuine semantic abstraction.
Generalized cross-entropy is employed in the domain branch to mitigate noisy label effects, further isolating robust structural features. This systematic decoupling significantly reduces the entanglement between class-relevant and domain-redundant components.
Adaptive Intrinsic Weight Fusion
To address catastrophic forgetting while eschewing exemplar replay, the proposed framework introduces a QR decomposition-based parameter-level fusion strategy. At each task boundary, orthogonal bases of semantic subspaces are extracted from prior encoder weights, and the fusion mask is adaptively computed per-parameter to distinguish critical inherited knowledge from redundant directions. This mask mediates an element-wise blending of previous and newly initialized weights, dynamically allocating plasticity to non-essential parameter directions while preserving informative subspaces. As a result, the model achieves fine-grained control over knowledge retention, supporting continuous adaptation and minimizing representational drift across domain shifts.
Domain-Invariant Feature Augmentation
To further strengthen invariance to domain artifacts, a counterfactual feature-swap based augmentation strategy is introduced. In each batch, intrinsic features are paired with domain features from previous domains to simulate cross-domain conditions in latent space, incentivizing the classifier to maintain performance on intrinsic cues alone. The resulting swap loss penalizes correlations between class predictions and domain-aligned factors, enforcing a model robust to spurious statistical associations.
Empirical Evaluation
Comprehensive experiments on benchmark datasets—including CDDB (continual deepfake detection), CORe50 (object recognition in shifting environments), and DomainNet—demonstrate the superiority of the proposed method under exemplar-free and domain-id free conditions.
- CDDB: Achieves 86.35% average accuracy, outperforming prominent baselines such as LRCIL, iCaRL, and LUCIR by up to 9.96%. Notably, this is attained without storing or replaying any past domain examples, setting a new standard for privacy-preserving continual learning.
- CORe50: Surpasses state-of-the-art methods with an average accuracy of 92.36%, confirming the framework's robustness against backgrounds, illumination, and viewpoint variations. The preservation of stability against catastrophic forgetting is particularly evident, outperforming the runner-up DUCT even without any historical sample access.
- DomainNet: Achieves 71.12% average accuracy, advancing over exemplar-free prompt-based models (e.g., L2P, DUCT, PINA) by up to 2.06%. This underscores the efficacy of disentangled semantic learning under severe multi-domain distribution shifts.
Ablation analysis reveals cumulative performance gains from each module: isolated disentanglement yields up to +8.25%, weight fusion adds up to +3.22%, and domain-invariant augmentation brings a further +1.23% on the most challenging benchmarks.
Hyperparameter and Sensitivity Analysis
The method remains robust across a wide range of hyperparameter configurations for q (GCE amplification) and λ (augmentation weight), with optimal operation at moderate values (q=0.7,λ=5) (Figure 3).
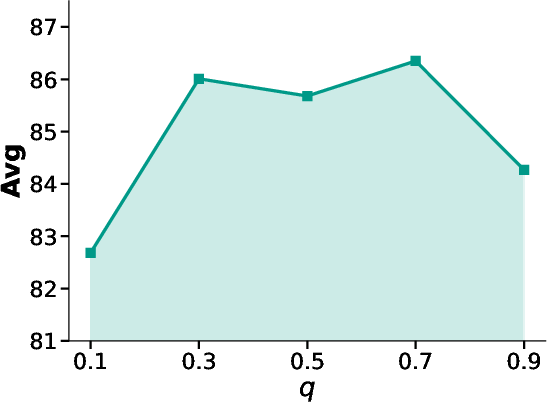
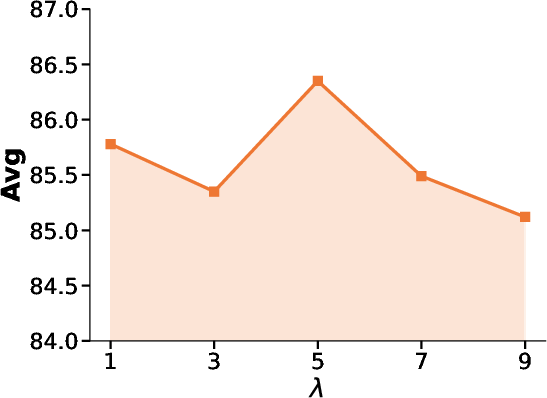
Figure 3: The sensitivity analysis on q and λ with CDDB, confirming stable and optimal performance in the recommended configuration space.
Theoretical and Practical Implications
This work demonstrates that feature disentanglement, when combined with parameter-level adaptive inheritance and counterfactual augmentation, forms a potent paradigm for domain-incremental learning in fully open and privacy-sensitive settings. Eliminating both domain id dependencies and data replay aligns this approach with real-world deployment constraints—particularly for edge devices with restricted memory or environments where data storage is strictly regulated.
The framework offers theoretical contributions to continual learning, explicitly separating semantic encoding from dynamic context and formalizing subspace-preserving parameter updates. Practically, it provides a foundation for embodied perception systems capable of long-term autonomy without manual intervention or prohibitive resource requirements.
Future Directions
Future research may extend this approach to joint class-domain incremental learning, address simultaneous style and semantic novelty, and explore integration with causality-inspired representation methods. There is further opportunity to generalize the adaptive fusion principle to large-scale transformer architectures and real-world multi-agent or federated settings.
Conclusion
The disentangled weight fusion framework establishes a new benchmark for robust, domain-agnostic, and exemplar-free continual learning in dynamic environments. Through disentangling intrinsic and domain features, adaptive parameter fusion, and domain-invariant feature augmentation, this method significantly outperforms prior approaches, minimizes catastrophic forgetting, and enables practical deployment of embodied intelligence in unpredictable real-world conditions.