- The paper introduces MM-ReCoder, a multimodal model that leverages reinforcement learning for iterative self-correction in chart-to-code generation.
- It employs a two-stage RL curriculum, combining supervised fine-tuning and composite reward modeling to enhance both code executability and visual fidelity.
- Benchmark results demonstrate that MM-ReCoder outperforms traditional models by achieving superior low-level scores and improved visual accuracy on standard datasets.
MM-ReCoder: Reinforcement Learning and Self-Correction for Multimodal Chart-to-Code Generation
Introduction
The paper "MM-ReCoder: Advancing Chart-to-Code Generation with Reinforcement Learning and Self-Correction" (2604.01600) introduces MM-ReCoder, a multimodal LLM (MLLM) designed specifically for chart-to-code generation. MM-ReCoder incorporates a reinforcement learning-based (RL) self-correction mechanism that enables iterative refinement of code, mimicking human-like chart programming workflows. The approach moves beyond traditional supervised fine-tuning (SFT) and one-shot RL paradigms by enabling multi-turn self-correction. MM-ReCoder achieves state-of-the-art performance on multiple benchmarks and provides new theoretical and practical insights into iterative code synthesis guided by execution feedback.
Limitations of Prior Chart-to-Code Approaches
Existing chart-to-code systems primarily rely on SFT with large datasets of chart–code pairs. Although SFT approaches such as ChartCoder [zhao2025chartcoder], ChartMaster [tan2025chartmaster], and others attain moderate success, next-token prediction metrics do not guarantee syntactic executability or precise visual fidelity. Some RL-based systems like ChartMaster introduced reward optimization for code-data congruence, but these frameworks operate strictly in a one-shot regime, lacking iterative correction capacity inherent to human programming.
Empirical investigations reveal that current MLLMs demonstrate superficial gains in evaluation metrics between sequential code generations; on closer inspection, improvements largely stem from increased rates of code executability, not genuine code refinement for visually faithful rendering. Filtering for cases where first-turn code is already executable, leading models show negative or negligible improvement upon subsequent turns, underscoring their inability to leverage execution feedback for targeted code revision.
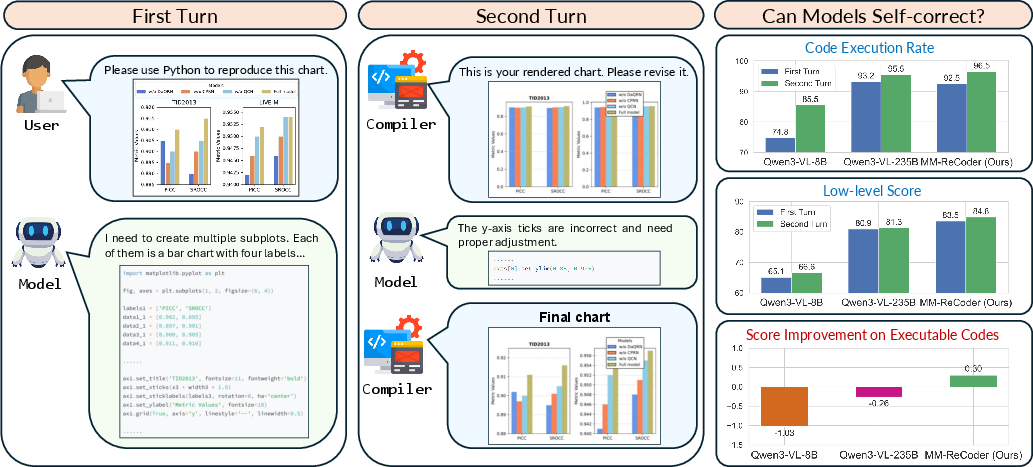
Figure 1: Analysis of multi-turn Chart2Code: While existing MLLMs improve overall evaluation scores between turns, most gains are attributable to increased executability, not genuine visual refinement. Only MM-ReCoder yields positive improvement on already-executable code.
MM-ReCoder Architecture and Training Pipeline
MM-ReCoder augments the conventional MLLM stack (Qwen2.5-VL-7B as backbone) by introducing a two-stage RL framework predicated on Group Relative Policy Optimization (GRPO). The system is first cold-started through SFT on large-scale single-turn chart–code pairs, followed by SFT on curated two-turn self-correction dialogs. Subsequently, it undergoes two RL stages: a shared-first-turn optimization targeting just the self-correction step, and a full-trajectory RL procedure that jointly optimizes both the initial code generation and its iterative refinement.
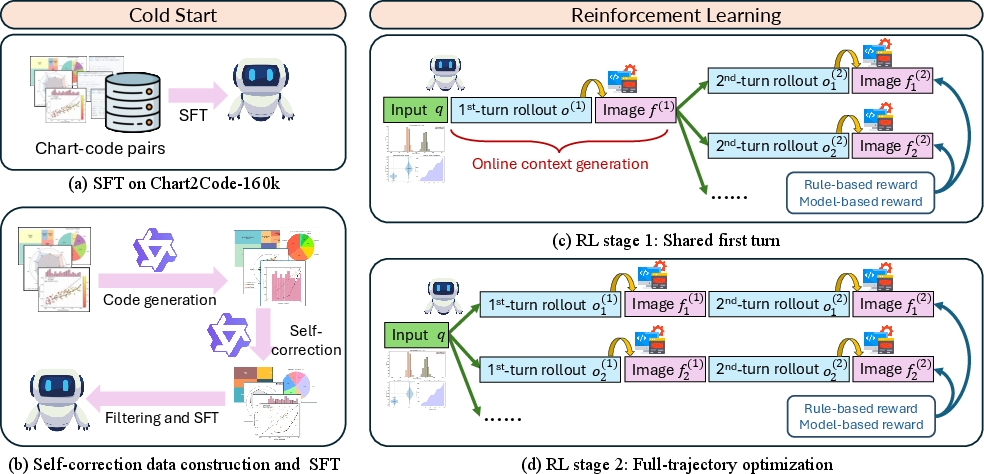
Figure 2: MM-ReCoder’s training pipeline: SFT on chart-code pairs, SFT on curated self-correction data, followed by two RL stages—shared-first-turn and full-trajectory optimization.
Reward Function Design
Reward modeling is multifaceted: low-level, rule-based rewards measure explicit congruence on chart type, color, textual content, and layout using deterministic extractors; high-level, model-based rewards leverage a VLM (Qwen2.5-VL-72B judger) to evaluate semantic and stylistic similarity on rendered outputs. The outputs are composed by a weighted sum, encouraging not only visual match and syntax conformity, but also promoting explicit “thinking traces” with appropriate format.
Ablation studies show that omitting model-based rewards leads to charts with poor visual clarity (overlaps, misalignments; see Figure 3), while excessive reliance on model-based reward degrades faithfulness to fine chart details. Appropriate reward mixing is essential for balanced performance.
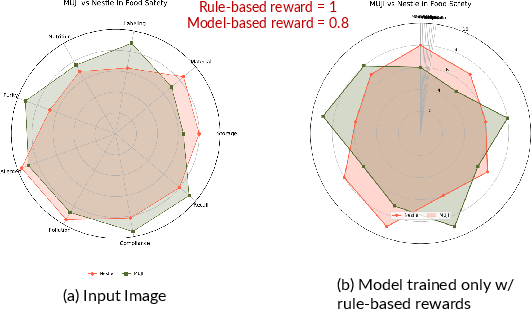
Figure 3: A rule-based-only reward fails to penalize visually incorrect—yet technically matching—charts, such as those with overlapping text; model-based reward mitigates this issue.
Multi-Turn Self-Correction RL
The two-stage RL comprises:
- Shared-First-Turn Optimization: Fixing the first-turn output and sampling diverse second-turn corrections, allowing the model to learn a space of effective revisions with online-sampled initial code. This approach counteracts behavioral collapse and repetition, as demonstrated by low repeated-code rates.
- Full-Trajectory Optimization: Jointly rolling out first- and second-turn code generations, updating the policy based on the cumulative group-based rewards. Several combinations of turn-wise bonuses and reward hyperparameters were explored to trade off between correction efficacy and overall coding quality.
- Two-Stage Curriculum: Shared-first-turn RL primes the policy for genuine correction, while subsequent full-trajectory RL sharpens both initial and corrective coding. Empirically, this sequence demonstrates superior code diversity, executability, and continuous visual improvement across multiple correction rounds.
Experimental Results
MM-ReCoder establishes new best results on ChartMimic, Plot2Code, and ChartX. With only 7B parameters, it outperforms Qwen3-VL-235B-A22B and matches or surpasses proprietary models (e.g., GPT-4V, GPT-4o) in low-level scoring and text-match metrics.
MM-ReCoder yields a low-level score of 86.5% on ChartMimic (versus 80.9% for Qwen3-VL-235B-A22B), and a text-match score of 63.2% on Plot2Code. It shows robust gains in execution rate and high-level visual fidelity with increased self-correction iterations.
Analysis of Self-Correction Behavior
Quantitative analysis reveals that, for cases in which both turns are executable, competing models often degrade the visual match in the second turn or simply repeat prior code. In contrast, MM-ReCoder improves the low-level chart score in 7.3% of cases (average improvement 0.3%), and only 4.5% of samples exhibit degradation.
Self-correction continues to yield incremental score improvements over multiple turns, although returns diminish after four or five rounds, suggesting practical convergence for iterative correction.
Ablations and Diagnostics
Examination of RL strategy variants reveals that single-stage or improperly ordered strategies yield high repetition rates (>50%) and negligible correction. Two-stage RL is required for substantial iterative refinement—this matches findings for LLMs in related RLHF research, where curriculum is essential for non-trivial reasoning behaviors.

Figure 4: Qualitative self-correction: The model rescales axes and adjusts grid lines in round two.
Qualitative Examples
Numerous qualitative examples demonstrate that MM-ReCoder’s self-correction fixes specific issues: label position, axis scaling, grid lines, color mismatches, runtime errors, and categorical orders. In success cases, the model leverages its “thinking trace” to explicitly identify discrepancies, guiding targeted code modifications.
(Figures 6–12)
Figure 5: MM-ReCoder removes label overlaps from a pie chart in self-correction.
Figure 6: The model removes hatch color in corrective iteration.
Figure 7: Multi-step correction—first a runtime error is resolved, then overlapping chart elements are fixed.
Implications and Future Directions
This work demonstrates that iterative, execution-driven self-correction is critical for aligning MLLMs with human-like coding workflows in multimodal code generation. The combination of a two-stage RL curriculum and multi-granular reward signals enables robust, scalable correction that can be adopted for other vision-to-code domains, including web-code synthesis, SVG generation, or document layout understanding.
The theoretical implications extend to RLHF regimes for multimodal architectures, where curriculum and reward shaping are pivotal for fostering non-trivial reasoning and self-improvement. Future work should consider extension to longer rollouts, hierarchical correction strategies, reward model alignment, and integration with code verification and abstraction.
A natural avenue for progress involves compositional task generalization (e.g., web layout + chart code), adversarial feedback, and scaling correction to more complex multimodal authoring tasks.
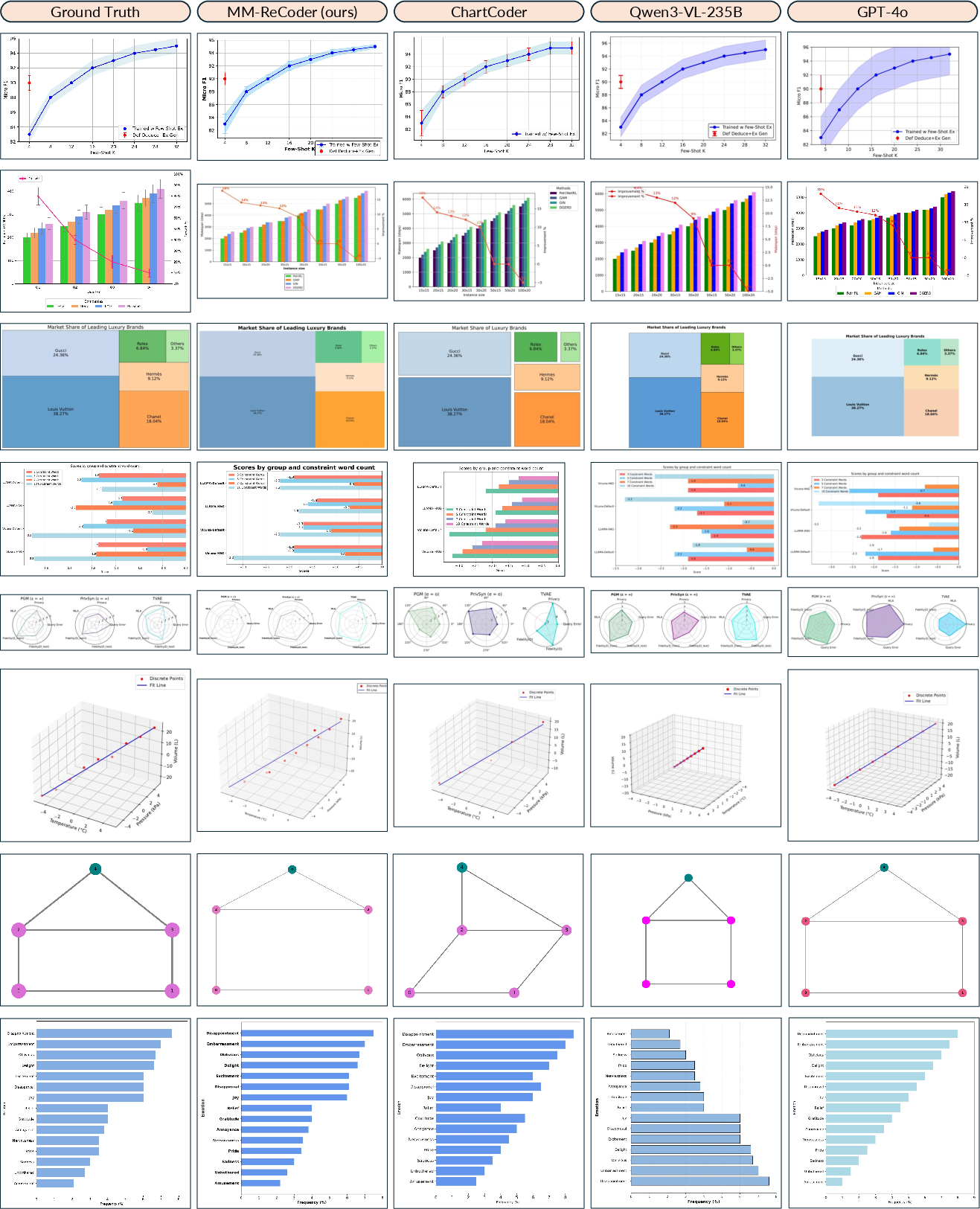
Figure 8: Comparison of MM-ReCoder with baselines. MM-ReCoder achieves better color, textual, and style fidelity across a variety of chart types.
Conclusion
MM-ReCoder advances chart-to-code generation by introducing RL-powered, iterative self-correction in MLLMs. The proposed curriculum—comprising cold start, shared-first-turn RL, and full-trajectory RL—combined with composite reward modeling, achieves superior accuracy and visual fidelity when compared to both open-source and proprietary alternatives. This approach sets a new benchmark for iterative, execution-feedback-driven code generation in multimodal domains and offers a scalable template for future models requiring non-trivial, feedback-aware reasoning and policy improvement.