- The paper introduces Murphy, a multi-turn RLVR algorithm that integrates iterative feedback and temporal credit assignment to improve self-correcting code generation.
- It leverages candidate rollouts, test suite evaluations, and effective pruning strategies to propagate rewards across refinement chains, yielding notable accuracy gains.
- Murphy bridges the gap between training- and inference-time interactions, outperforming single-turn methods while maintaining computational efficiency.
Murphy: Multi-Turn Reflective RLVR for Self-Correcting Code Generation
Introduction and Motivation
Murphy introduces a multi-turn extension of Group Relative Policy Optimization (GRPO) for reinforcement learning with verifiable rewards (RLVR) in code generation tasks. While agentic scaffolds for code generation allow LLMs to iteratively refine outputs via execution feedback at inference time, the dominant RLVR frameworks—including GRPO and its extensions—are inherently single-turn, i.e., they update model parameters solely based on terminal (single-shot) responses without capturing the iterative nature of agentic refinement. This paper proposes Murphy as an end-to-end RLVR algorithm that explicitly incorporates multi-turn, environment-driven feedback during policy optimization, seeking to close the gap between inference-time agentic chains and feedback-aware fine-tuning for improved model self-correction and grounded reasoning.
Methodology
Murphy generalizes GRPO to multi-turn settings through two principal innovations: (1) a feedback-conditioned multi-turn rollout mechanism and (2) structured temporal credit assignment over refinement trajectories.
During training, for each input prompt, Murphy generates G candidate responses and evaluates each against a test suite, yielding both quantitative (test pass rates) and qualitative (error traces, failed cases) feedback. For failed generations, feedback is concatenated with the original prompt and prior attempt, and the model is re-invoked to produce another G responses, iterating for a fixed number of turns. The process constructs a feedback-conditioned rollout tree per prompt—each trajectory representing sequential attempts at self-improvement (Figure 1).
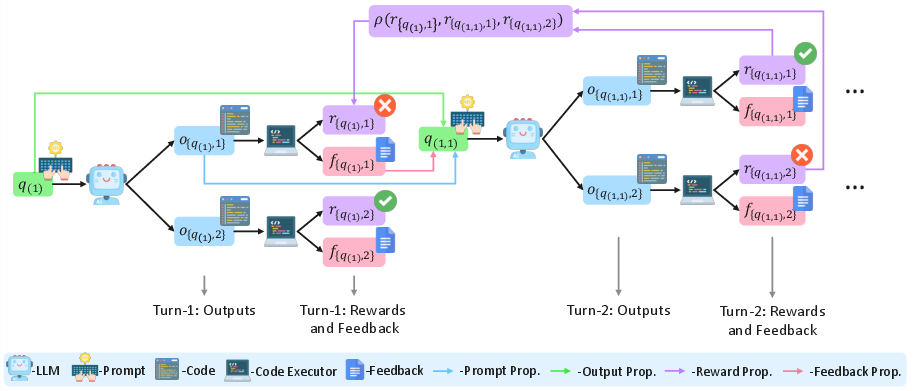
Figure 1: Overview of Murphy's multi-turn, feedback-driven rollout process and credit assignment for code generation.
After all refinement attempts, Murphy propagates terminal rewards backward through the rollout tree using either maximum (MaRS) or mean (MeRS) reward criteria, ensuring that intermediate decisions contributing to ultimate success are credited appropriately. The optimization objective applies the GRPO-style group-relative advantage but now over temporally adjusted pseudo-rewards, regularized by a token-level KL constraint against the reference policy, across all nodes in the rollout tree.
Murphy further addresses the computational overhead induced by exponential trajectory growth through pruning strategies: Intra-group pruning (pruning within each rollout subtree) and Inter-group pruning (pruning across groups/prompts), retaining only promising paths for subsequent gradient updates. This results in substantial reduction in compute and memory requirements with minimal performance tradeoff.
Experimental Results
Murphy was evaluated on code generation across three open-source benchmarks (HumanEval, MBPP, BigCodeBench-Hard) and two model families (Qwen3, OLMo2) spanning 1.7B-7B parameters. All models were fine-tuned on 1K KodCode samples and assessed under Reflexion-style inference, both single-turn and tri-turn, reporting pass@1 accuracy.
Key findings include:
- Murphy achieves up to 8% absolute gains over compute-equivalent GRPO baselines on pass@1 in multi-iteration (tri-turn) evaluation. For Qwen3-1.7B, Murphy reaches 86.6% (tri-turn HumanEval), compared to 82.1% for GRPO (Table 1).
- In single-turn (no feedback/refinement) settings, Murphy is competitive or superior, indicating that multi-turn feedback optimization does not compromise one-shot performance.
- Pruning (especially Inter-group) preserves peak performance while halving update counts, ensuring scalability for larger S (number of turns).
- The MaRS criterion (maximum reward propagation) consistently dominates MeRS (mean reward), particularly in sparse reward regimes typical of code tasks.
- Murphy outperforms naive multi-turn RLVR variants lacking explicit credit assignment, as well as recent RLVR methods that depend on auxiliary verifier models or PPO-style critics.
Theoretical and Practical Implications
Murphy establishes that incorporating structured, intermediate environmental feedback into RLVR training enables LLMs to internalize the iterative reasoning process central to agentic frameworks. The alignment between training- and inference-time interaction patterns leads to models that both demonstrate improved self-correction under feedback and require less reliance on inference-time scaffolding.
From a theoretical standpoint, Murphy’s temporal credit assignment realizes a form of multi-step advantage estimation akin to TD(λ) while leveraging empirical group statistics, bypassing the need for value networks. This architecture-minimal approach avoids verifier LLMs or value critics, yielding simplicity and efficiency conducive to broader RLVR adoption in code LLMs.
Practically, Murphy’s feedback-aware training is compatible with off-the-shelf LLMs and scalable via pruning and system-level optimizations (e.g., vLLM, paged attention). The integration of both quantitative and qualitative feedback ensures extensibility beyond code—potentially to mathematical proof generation, reasoning chains, or sequential decision tasks—where verifiable reward signals can be computed.
Limitations and Areas for Future Work
While Murphy reduces the sample complexity associated with multi-turn RLVR via pruning schemes, training remains more resource-intensive than single-turn baselines, especially as S increases. The current instantiation presupposes dense, reliable feedback (e.g., explicit unit tests); its generalization to domains with sparser, noisy, or structured feedback warrants careful engineering of reward signal propagation. The method’s capacity for deeper refinement chains (beyond two or three turns) and its effect on hallucination or reward hacking behavior have yet to be exhaustively characterized.
Future work should explore adaptive trajectory selection (e.g., bandit-driven pruning), the use of learned meta-policies to guide feedback aggregation, and joint training with inference-time search or self-consistency mechanisms. Extension to fully agentic RL settings—where models control both generation and environment interaction policies—represents a natural next step for Murphy-style RLVR.
Conclusion
Murphy represents a concrete advance in RLVR for agentic code generation, providing an efficient and effective means for LLMs to learn iterative self-correction from feedback. By explicitly propagating rewards across multi-turn refinement chains and employing computationally efficient pruning, Murphy delivers consistent empirical gains over single-turn GRPO across diverse open LLMs. This establishes a foundation for feedback-aware RLVR applicable to a broader spectrum of reasoning-centric, verifiable LLM tasks.

