- The paper introduces a FAN-guided regularizer that transforms the VLA model’s action distribution from narrow and peaked to smooth and unimodal.
- It employs both supervised and reinforced finetuning paradigms, with experiments showing substantial improvements in in-distribution and out-of-distribution tasks.
- The approach boosts sample efficiency and robustness, with FAN-PPO achieving up to 10% enhanced success rates and accelerated convergence on complex manipulation tasks.
Feasible Action Neighborhood Prior for Vision-Language-Action Finetuning
Motivation and Conceptual Foundation
The study addresses a critical mismatch in finetuning paradigms for vision-language-action (VLA) models, which inherit the rigid, exclusive-correctness training protocols of LLMs, ignoring the inherent tolerance of physical action spaces in robotic manipulation. In real-world robotics, actions admit a Feasible Action Neighborhood (FAN) — a region of actions around the optimal choice that produce near-equivalent task progress. This geometric tolerance is entirely absent in linguistic settings, resulting in overfitted models with poor out-of-distribution (OOD) robustness and sample inefficiency.
The paper introduces a FAN-guided regularizer that actively shapes the action distribution of VLA models during finetuning. By imposing a Gaussian prior centered at the model’s own predicted action with adaptive or fixed covariance (depending on whether supervised or reinforced finetuning is used), the approach transforms the policy distribution from a narrow, peaked function to a locally smooth, unimodal form, aligning it with the intrinsic tolerance geometry of physical actions.
FAN Definition
The FAN is formally defined using the Q-function: for a tolerance δ>0, the set Nδ(s) includes actions a such that Q(s,a∗(s))−Q(s,a)≤δ. Crucially, the policy distribution's shape—a proxy for the FAN—is strongly coupled to generalization. Empirical evidence demonstrates that models trained via standard supervised finetuning (SFT) yield peaked distributions (trivial FAN), while reinforcement finetuning (RFT) broadens them, which correlates with improved generalization and robustness.
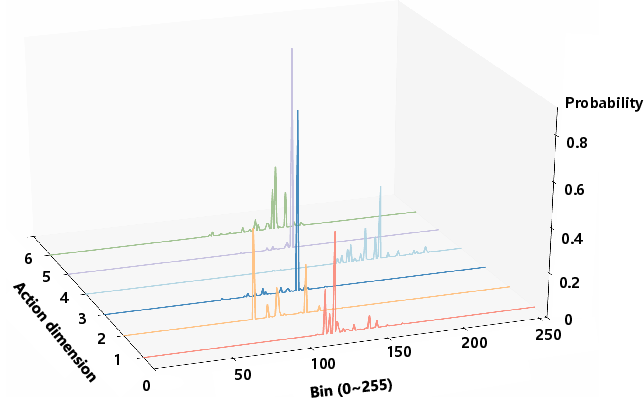
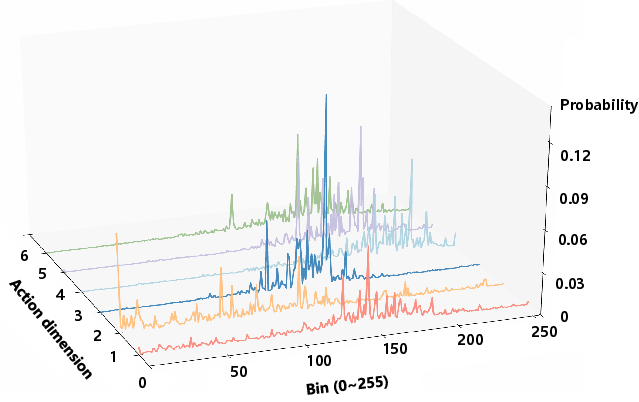
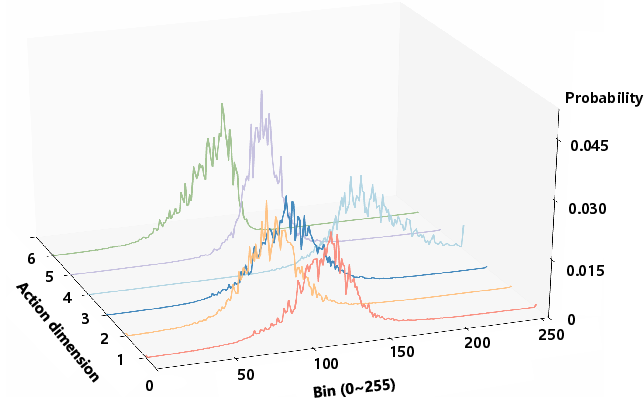
Figure 1: The evolution of policy distribution geometry through SFT, SFT+PPO, and FAN-PPO on a ManiSkill task; FAN-PPO achieves the most robust, Gaussian-shaped distribution.
FAN-Guided Regularization
For SFT, the loss function integrates the FAN regularizer as the KL divergence between the policy and a dynamically constructed Gaussian, where the covariance is set by the variance of the policy. This approach induces smoothing and local unimodality in the action distribution, counteracting overfitting and improving spatial robustness.
For RFT, the regularizer is incorporated into trust-region policy optimization schemes (PPO/GRPO), yielding a constrained optimization problem. Here, a fixed covariance is used for stability, and the resulting optimal policy is a geometric mean of the previous policy, the Gaussian prior, and the exponentiated Q-values. This form admits closed-form solutions and provides theoretical insight into the regularizer's interaction with exploration and policy continuity.
Experimental Analysis
Supervised Finetuning (SFT)
Extensive evaluation across the ManiSkill and LIBERO benchmarks shows substantial improvements in both in-distribution and OOD tasks. On ManiSkill, FAN-SFT yields average success rate improvements of +11.7% (in-distribution) and +5.2% (OOD), outperforming OpenVLA baselines and label smoothing alternatives.
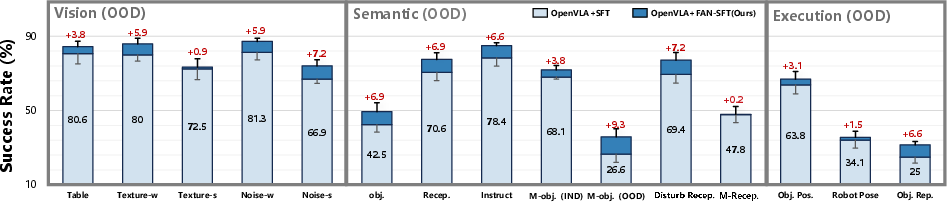
Figure 2: SFT performance with FAN-guided regularization across diverse OOD tasks on ManiSkill.
The method demonstrates consistent gains across vision, semantic, and execution OOD axes, with particular robustness under distractive and noisy conditions. Data efficiency studies indicate that FAN-regularization remains effective across varying dataset scales.
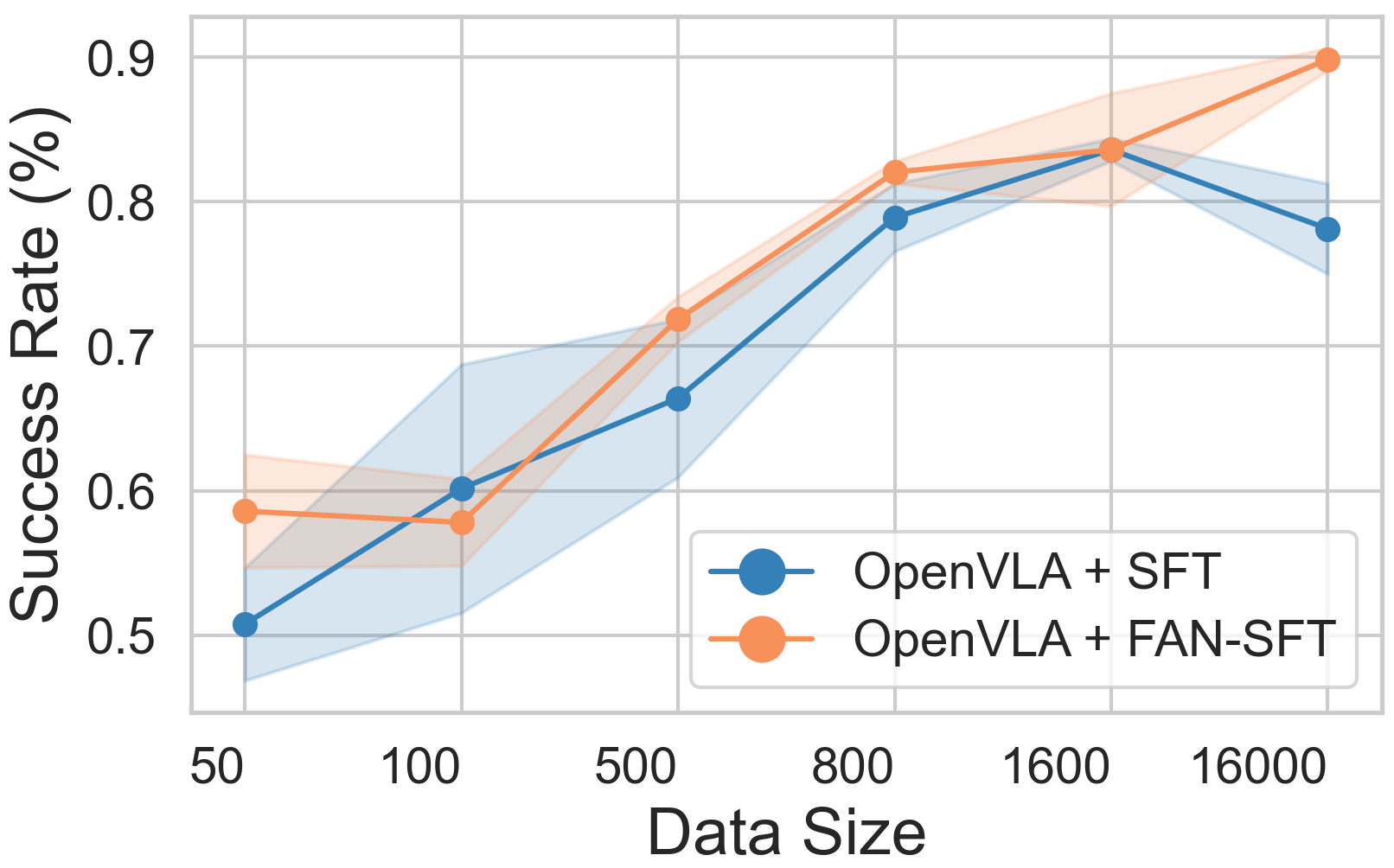
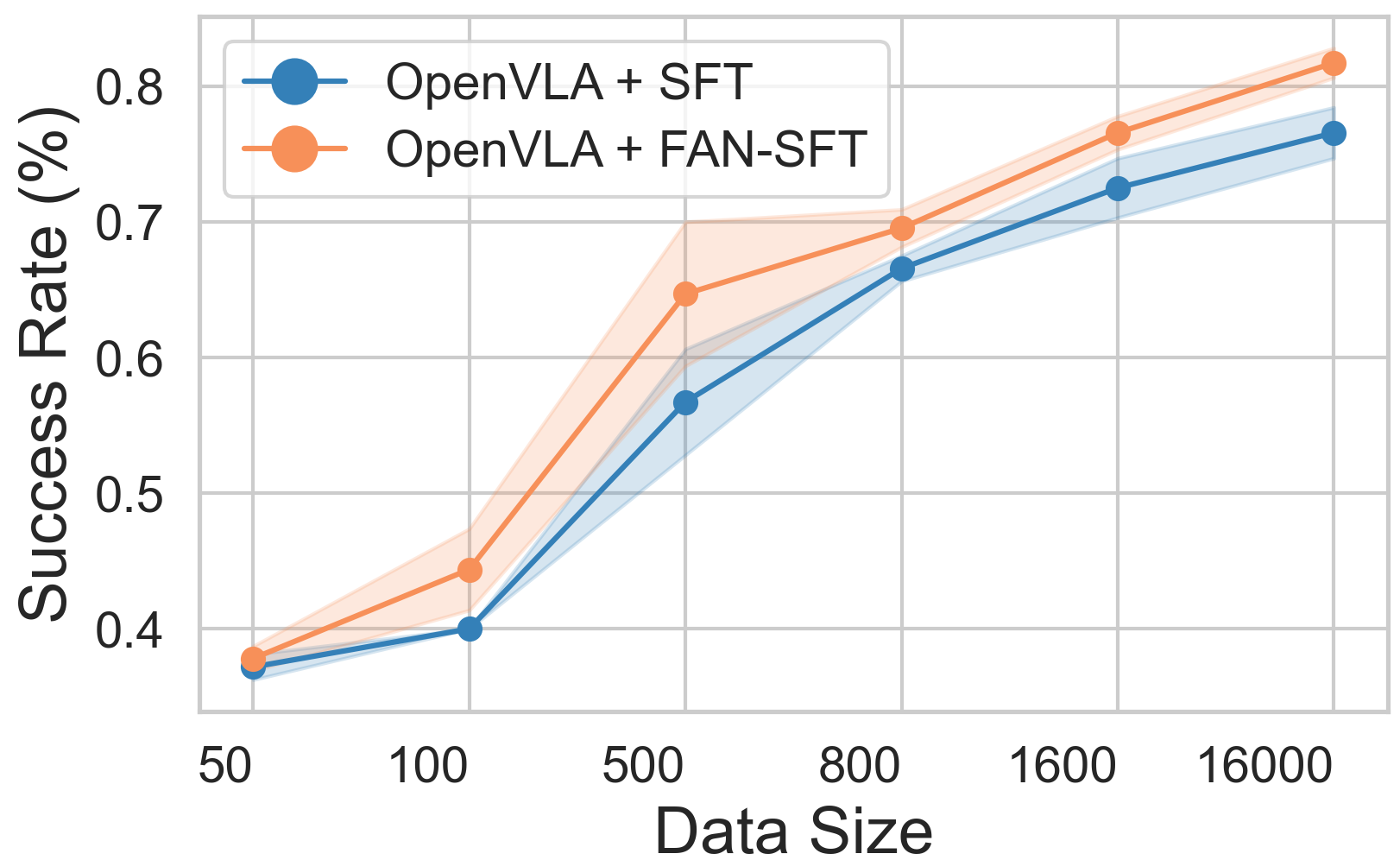
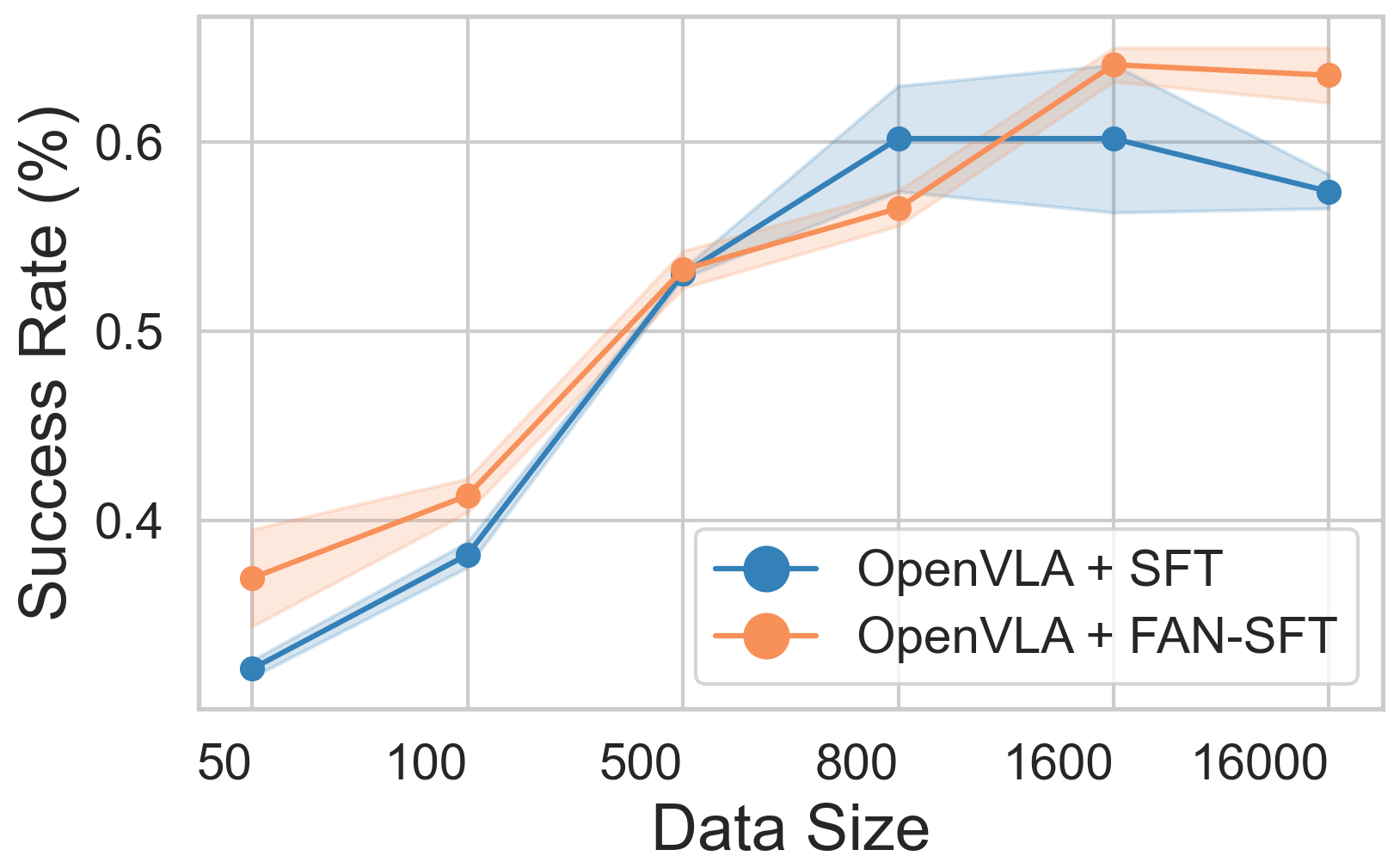
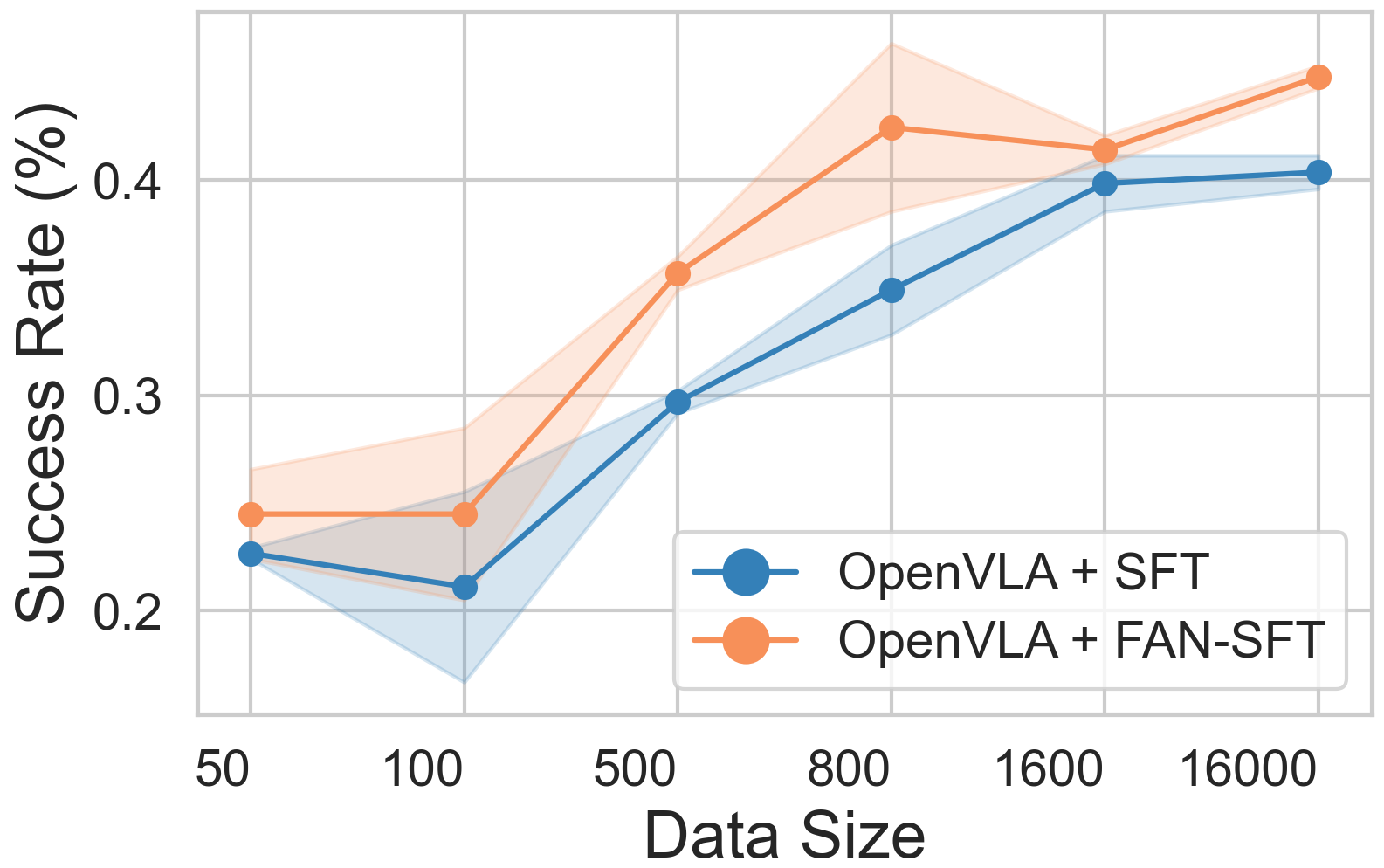
Figure 3: SFT performance as a function of training data size, showing improved generalization for FAN-regularized models across OOD axes.
On the LIBERO-Spatial benchmark, FAN-SFT consistently adapts to spatial perturbations, increasing success rates under position shifts. Qualitative rollouts confirm that FAN-SFT generalizes to unseen spatial configurations, escaping overfitting to seen positions.
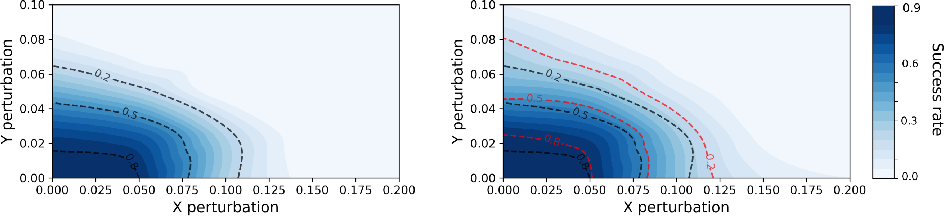
Figure 4: Spatial robustness evaluation on LIBERO-Spatial, with FAN-SFT demonstrating broader success contours under positional perturbations.
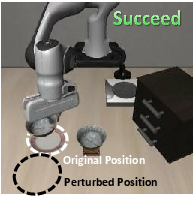

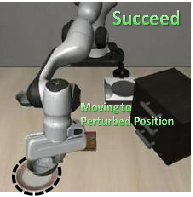
Figure 5: Trajectory rollouts reveal FAN-SFT adaptivity to target location perturbations, unlike vanilla SFT.
Reinforced Finetuning (RFT)
FAN-guided regularization in PPO and GRPO settings yields improved stability, sample efficiency, and generalization. On ManiSkill, FAN-PPO increases success rates by up to 10% in execution OOD scenarios, with accelerated convergence requiring only one-third the training steps to reach 90% success, compared to baselines.
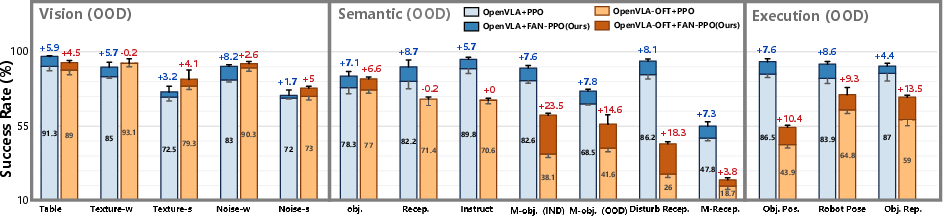
Figure 6: Comparative task-level performance for OpenVLA(-OFT) with FAN-PPO versus conventional PPO on OOD tasks.
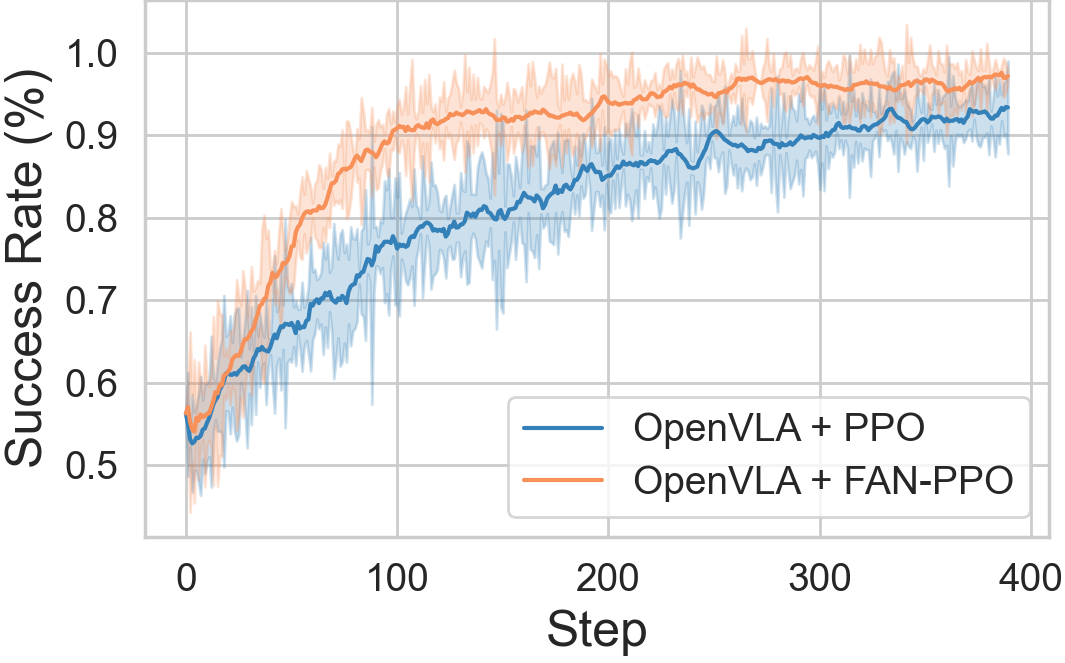
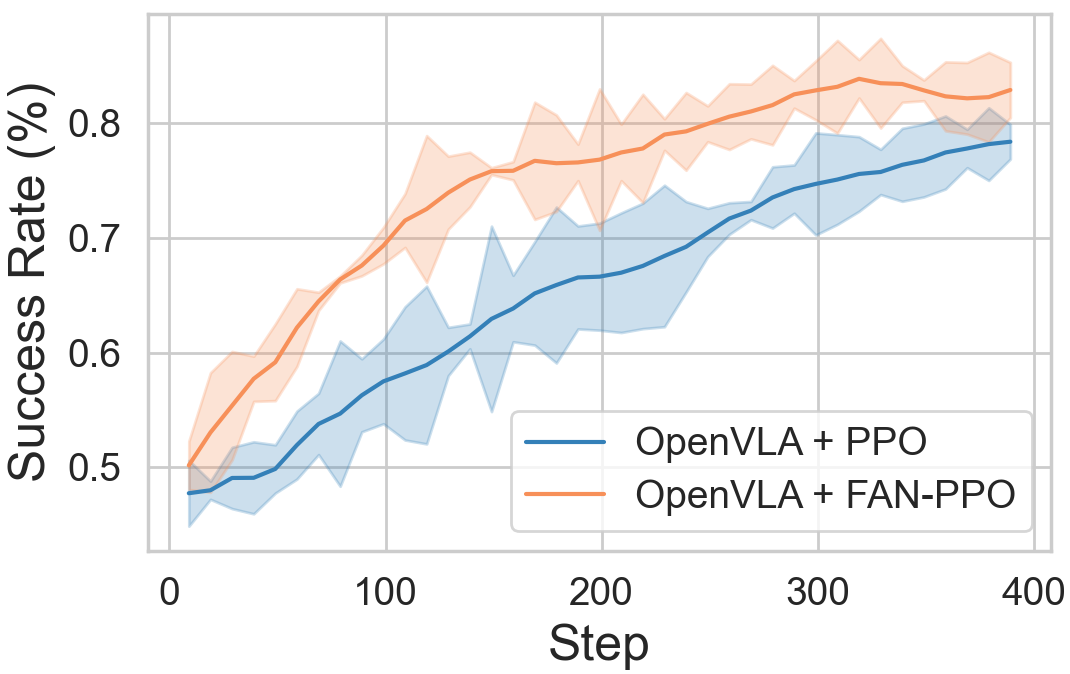
Figure 7: Training dynamics for rollout and evaluation success rates during RFT, with FAN-PPO accelerating convergence.
For the chunk-based OpenVLA-OFT, FAN-PPO maintains performance gains, particularly pronounced in OOD tasks with semantic and spatial challenges.
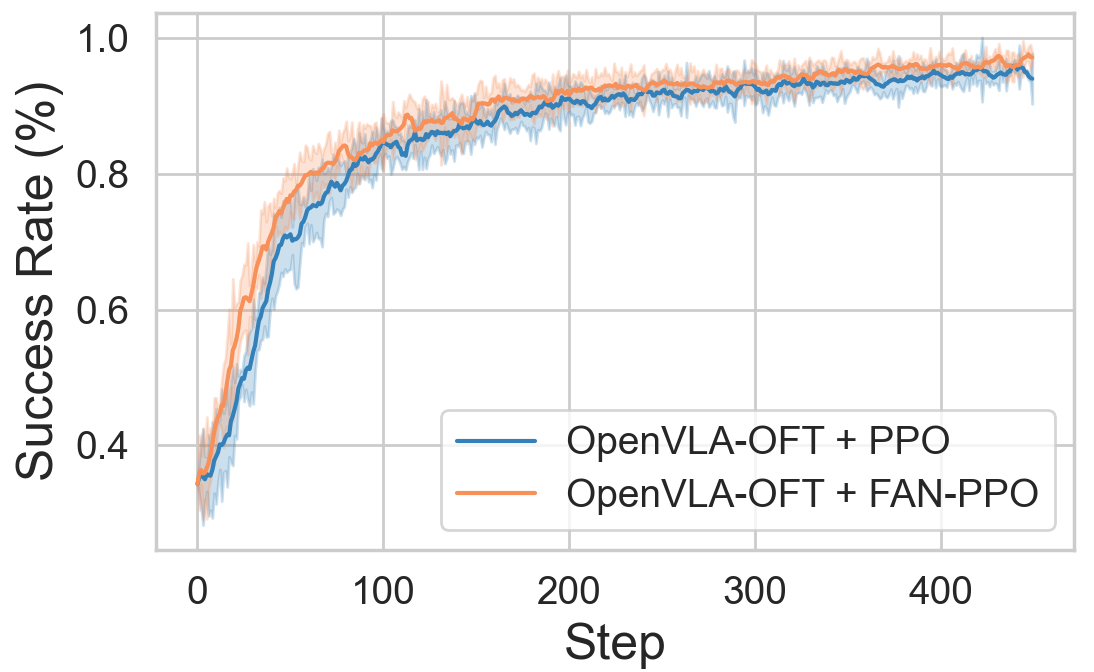
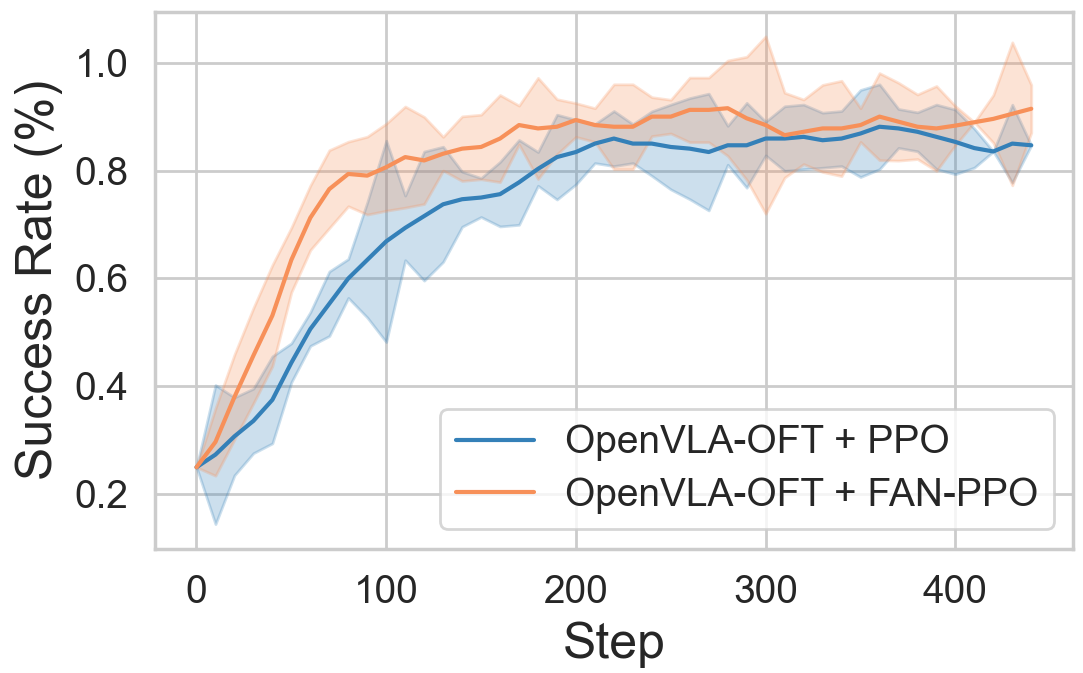
Figure 8: Training curves for OpenVLA-OFT reveal consistent sample efficiency gains under FAN-regularization.
Real-World Validation
On a 7-DoF JAKA manipulator setup, FAN-SFT is tested for object placement under spatially perturbed conditions. The regularized model achieves higher robustness across object pose, manipulator pose, and box position shifts, outperforming baselines by a large margin in challenging scenarios.



Figure 9: Real-world evaluation setup for spatial robustness, involving the JAKA robotic platform.
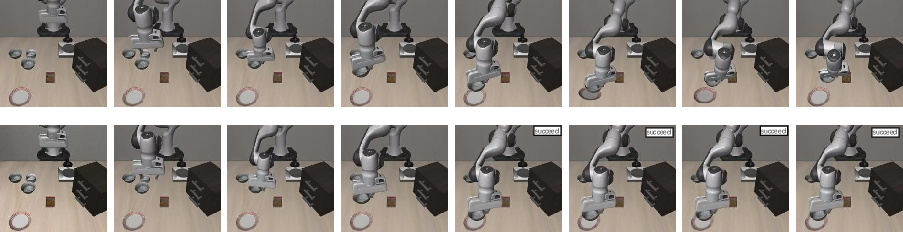

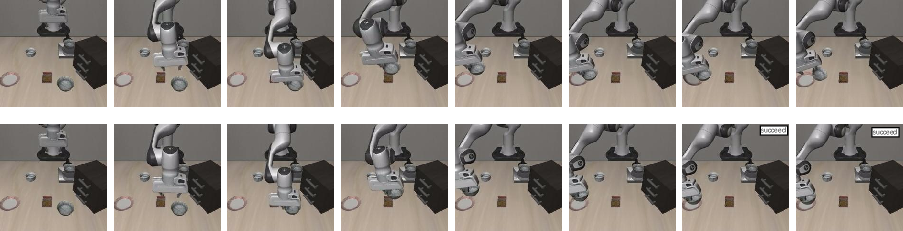
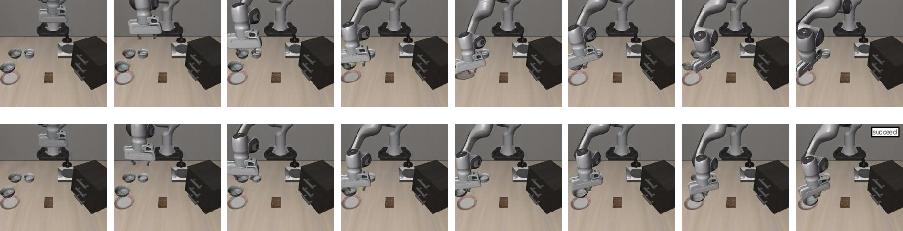
Figure 10: Object placement under x-axis disturbance, with FAN-SFT succeeding where baseline OpenVLA+SFT fails.
Qualitative Analysis
A suite of qualitative trajectory comparisons across in-distribution, vision OOD, semantic OOD, and execution OOD tasks consistently shows that FAN-PPO and FAN-SFT models execute correct, robust actions on perturbed tasks, while baseline policies collapse into failure modes. FAN-guided models generalize smoothly across unseen environments, adapting to new textures, noise patterns, semantic instructions, novel object/receptacle configurations, robot poses, and object repositionings.

Figure 11: Successful trajectories on in-distribution tasks for FAN-PPO vs. PPO.
(Figure 12)-(Figure 13)
Figures 12–25: Qualitative rollouts on OOD tasks demonstrating robust adaptation of FAN-PPO policies across vision, semantic, and execution perturbation classes.
Implications and Future Directions
The introduction of FAN-guided regularization constitutes a principled strategy for mitigating the structural mismatch between language-style VLA training and the continuous, tolerant nature of physical action spaces, enabling robust, sample-efficient adaptation in both simulation and real-world deployments. The approach generalizes across SFT/RFT paradigms, action tokenizations, and model architectures, with minimal overhead and strong empirical support.
Practically, the method advances reliable sim-to-real transfer, spatial generalization, and robustness in manipulation. Theoretically, it frames policy geometry control as central to embodied intelligence, presenting avenues for exploration of alternative priors (e.g., kernel-smoothing, multi-modal distributions), adaptive regularization, and integration with entropy-based objectives. Investigating the interplay between FAN regularization and hierarchical or chunked action representations is likely to yield further gains in manipulation granularity and reasoning depth.
Conclusion
FAN-guided regularization directly addresses the overfitting and poor generalization endemic to language-inspired VLA finetuning. By shaping policy distributions to mirror the local tolerance geometry of physical manipulation, models achieve significant improvements in sample efficiency, task robustness, and OOD generalization. These findings position structured policy regularization as a foundational ingredient in scalable, general-purpose robotic intelligence and warrant consolidation in future architectures and training pipelines.
Reference: "Boosting Vision-Language-Action Finetuning with Feasible Action Neighborhood Prior" (2604.01570).