- The paper introduces self-correction flow matching to align 3D scene motion with 2D frame differences, eliminating the need for external optical flow guidance.
- It employs a disentangled pipeline that separately models static and dynamic regions using specialized tri-plane structures for precise scene reconstruction.
- Experimental results demonstrate significant improvements, including over 2dB PSNR gains on benchmarks, ensuring sharper details and enhanced temporal consistency.
Self-Correction Motion Learning for Monocular Dynamic Scene Reconstruction: An Analysis of ReFlow
Introduction
The problem of high-fidelity, temporally consistent reconstruction of dynamic scenes from monocular video remains a central challenge in computer vision and neural graphics. Recent neural 3D representations have dramatically advanced static reconstruction, most notably with 3D Gaussian Splatting (3DGS). However, existing extensions to dynamic scenes struggle with incomplete scene initialization (particularly for dynamic objects) and rely heavily on external dense motion priors, such as pre-computed optical flow, which introduce complexity and propagate estimator errors. The "ReFlow: Self-correction Motion Learning for Dynamic Scene Reconstruction" framework (2604.01561) proposes a new paradigm, leveraging self-correction flow matching to align 3D scene motion directly with 2D frame differences, removing the dependence on any external motion guidance.
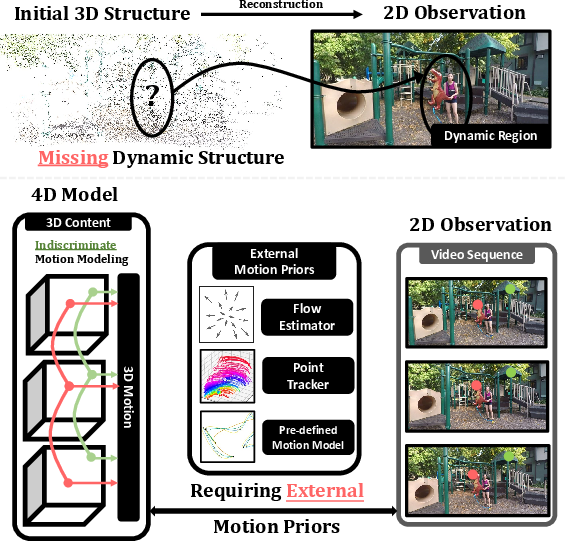
Figure 1: Typical challenges in monocular dynamic scene reconstruction, namely missing dynamic regions in the initial structure-from-motion and tangled initialization for static/dynamic components.
Framework Overview
ReFlow addresses the limitations of prior art through an integrated pipeline comprising three major modules:
- Complete Canonical Space Construction: Utilizes a geometry foundation model for joint initialization of static and dynamic regions, ensuring disentangled, geometrically coherent starting conditions even for fast or complex object motion.
- Separation-Based Dynamic Scene Modeling: Employs dedicated scene representations and feature encodings—distinct tri-plane structures for static and combined spatial-temporal planes for dynamic elements—allowing granular, motion-aware decomposition.
- Self-correction Flow Matching: The core contribution, this module supervises 3D motion via photometric consistency between warped frames, using both Full Flow (object + camera motion) and Camera Flow (egomotion only for static regions), establishing a robust and principled, video-driven objective.
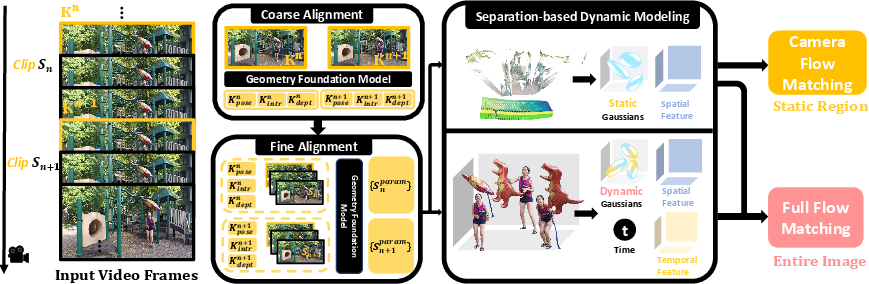
Figure 3: Motivation of Self-correction Flow Matching. The mechanism enforces the consistency between 3D scene flow (explaining 2D visual changes) and image frame differences without requiring external motion priors.
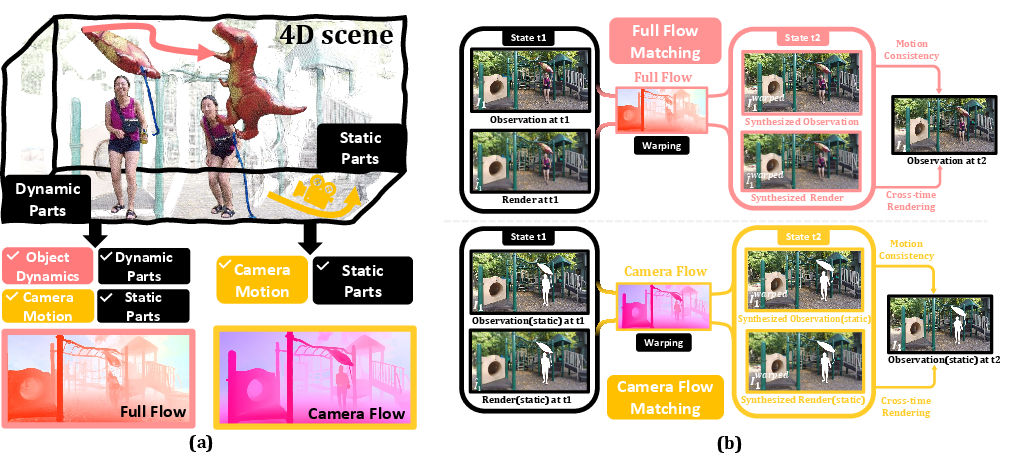
Figure 2: The self-correction flow matching mechanism. Region-specific (dynamic vs. static) flow constraints are imposed: full flow for the complete scene, camera-only flow for static regions.
Canonical Space and Scene Disentanglement
Unlike prior approaches that perform initialization using generic Structure-from-Motion (SfM) (which cannot robustly separate or fully capture dynamic content), ReFlow leverages a state-of-the-art geometry foundation model to regress per-pixel 3D coordinates across both static and dynamic regions. This model is optimized via a hierarchical, global-to-local graph alignment, ensuring stable and consistent geometric priors for all scene components. Subsequent separation into static and dynamic point sets is critical for region-specific modeling and downstream motion learning.
Dynamic content is represented using both spatial and temporal feature planes, allowing flexible deformation through time, while static background employs only spatial features for time-invariant modeling. This separation is the prerequisite for enforcing targeted motion constraints.
The self-correction module introduces a dual-constraint mechanism:
- Full Flow Matching: Computes the full optical flow induced by both scene and camera motion, then warps source frame I1 to match target frame I2, penalizing discrepancies through a combined L1/SSIM loss. The projection from 3D Gaussians into the 2D plane leverages the learned deformation field, integrating both geometric and photometric information.
- Camera Flow Matching: For static regions, a separate flow is computed using only camera trajectory (egomotion), enforcing the expectation that static elements should exhibit no residual motion beyond this transformation. Discrepancies are penalized analogously and only within the static mask.
This fully differentiable warping-based loop establishes a self-supervised learning signal: the only way for the model to minimize image-space misalignment is to correctly estimate 3D motion that actually explains the observed frame-to-frame changes.
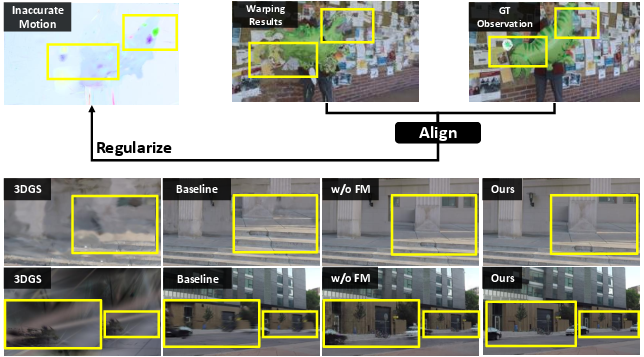
Figure 4: The effect of self-correction flow matching. Incorrect 3D motions produce warping artifacts (yellow boxes), which the learning signal directly penalizes, leading to increasingly detailed and correct reconstructions.
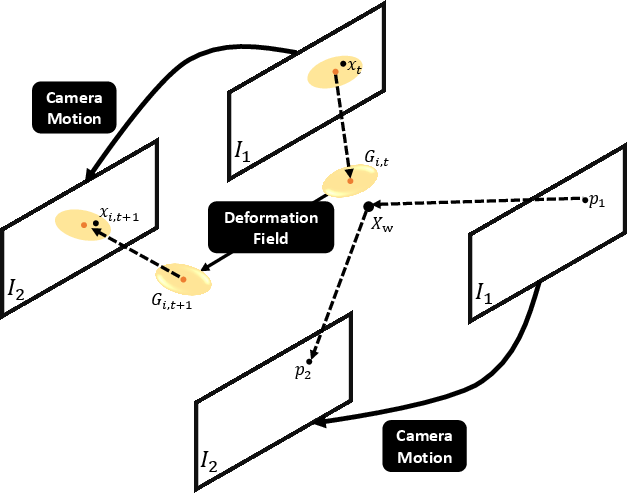
Figure 7: Computation of Full Flow and Camera Flow, illustrating the explicit disentangling of object dynamics vs. camera egomotion in generating 2D flow supervision.

Figure 9: Progression of alignment accuracy during training: as self-correction flow matching converges, warped images increasingly match their target frames.
Experimental Analysis and Strong Numerical Results
ReFlow is evaluated on rigorous public benchmarks (NVIDIA Monocular, Nerfies, HyperNeRF). Across all scenes, it consistently achieves state-of-the-art metrics (PSNR, SSIM, LPIPS), outperforming recent dynamic 3DGS and NeRF-based methods—sometimes by >2dB PSNR on challenging scenes such as Balloon2 and Playground [Table 1]. Qualitative results show more stable background, sharper dynamic object details, and better temporal consistency, especially in the presence of fine, fast-moving structures.

Figure 5: Qualitative comparison on the NVIDIA Monocular dataset, highlighting improved rendering quality and preservation of dynamic scene details by ReFlow.

Figure 6: Qualitative results on the Nerfies-HyperNeRF benchmark, where ReFlow reconstructs subtle scene features and fine temporal dynamics missed by prior methods.
Ablation studies show that each module—complete scene initialization, static-dynamic separation, and both flow constraints—is essential for optimal accuracy. Applying self-correction flow matching even on a naïve static baseline yields an immediate PSNR increase, underscoring the inherent effectiveness of photometric self-supervision.
Implications and Future Directions
ReFlow’s formulation removes the external flow estimator bottleneck, leading to both improved robustness and simplicity. The model learns to align 3D dynamics purely using the raw video signal, avoiding error propagation from noisy, heuristic pre-computed flows. This principled, end-to-end paradigm is more resilient to atypical motion, occlusions, and estimator drift.
In practice, this enables:
- Reliable digitization and relighting of everyday videos—including those captured casually—into editable, temporally consistent 4D assets.
- Rapid, per-scene optimization on modest compute resources, reducing reliance on large-scale pretraining or annotated datasets.
Theoretically, ReFlow demonstrates that direct supervision of 3D motion via image-space photometric consistency constitutes a sufficient signal for learning accurate scene flow. This lays the groundwork for further investigation into self-supervised, video-driven motion learning—potentially integrating foundation models for geometry, semantics, and segmentation to address still-outstanding issues such as topology changes or partial observability.
Next steps include:
- Integration with more robust geometry foundation models as they advance (e.g., for improved handling of topological changes or occlusion logic).
- Extension to real-time settings, joint multi-object modeling, and explicit handling of appearance variations.
- Adapting the self-correction paradigm for generalizable, feed-forward dynamic scene modeling at scale.
Conclusion
ReFlow establishes a new standard for monocular dynamic scene reconstruction by combining rigorous canonical space initialization, static/dynamic decomposition, and self-correction flow matching. Its video-intrinsic, warping-based supervision achieves superior fidelity and robustness across benchmarks without dense flow guidance—simplifying 4D tracking and rendering pipelines and pointing the way toward more general, video-centric 3D scene understanding (2604.01561).