- The paper introduces a unified RL framework using decentralized policies to integrate path planning, target allocation, and scheduling for heterogeneous robot teams.
- The MAPPO-based approach achieves over 90% success rate and near-optimal solve times while maintaining constant inference complexity for real-time applications.
- The study highlights system scalability limitations due to fixed observation encoding and suggests future integration with GNNs for flexible multi-agent coordination.
Collaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO
Problem Overview and Motivation
This work systematically addresses the complexity of planning, allocation, and scheduling for heterogeneous multi-robot systems in the context of real-time exploration and task execution, particularly relevant to extraterrestrial robotics. Traditional methodologies such as graph search, constraint programming, and metaheuristics demonstrate poor scaling and are not suitable for continuous replanning requirements experienced in space robotics. The paper proposes a fully learning-based approach, leveraging the Multi-Agent Proximal Policy Optimization (MAPPO) framework, that unifies path planning, target allocation, and scheduling for teams of robots with diverse capabilities, with an explicit focus on adaptability and computational tractability.
The primary objective is the development and benchmarking of decentralized policies, realized by centralized training, that can coordinate robots with various locomotion and manipulation capabilities to efficiently reach and solve targets with diverse skill requirements. This unification of allocation, scheduling, and optimization within a reinforcement learning (RL) paradigm allows for the pre-computation of policy complexity, shifting computational cost from inference to training, which is critically advantageous for embedded systems with strict runtime constraints.
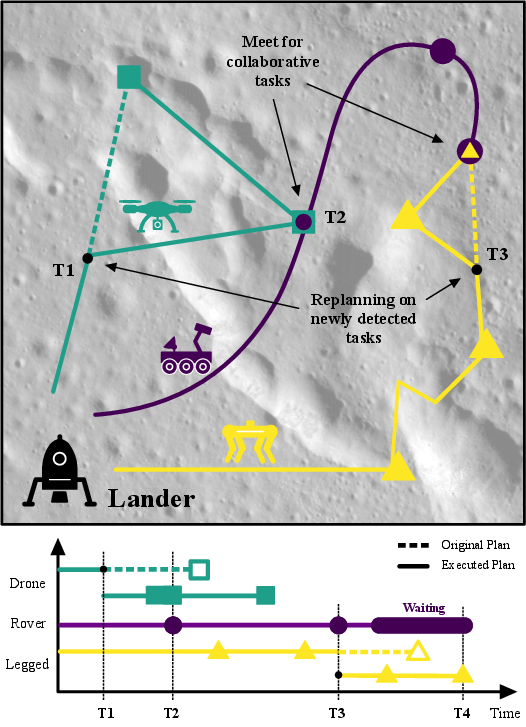
Figure 1: An illustrative plan for a collaborative robot fleet with different physical specializations (flying, walking, driving) dynamically replanning as new tasks are discovered during a mission.
Methodology
The framework consists of a centralized actor-critic MAPPO structure, employing recurrent (GRU-based) network architectures for both actor and critic, enabling long-term temporal dependencies and decentralized execution post-training. The operational environment is a discrete 2D grid, populated by N agents and M targets, with complex interactions mediated by agent skill sets and target requirements (forming AND/OR-type objectives, supporting collaborative and individual task solves).
The observation space for each agent encodes explicit global state information: relative and absolute positions of all entities, agent and target skill sets, and target types, concatenated into fixed-length vectors. While this formulation offers efficient policy learning in fixed-size scenarios, it inherently precludes variable cardinality in team size or target set—a critical limitation discussed later.
Rewards are meticulously designed to balance navigation efficiency (attraction rewards), successful completion of relevant tasks (target rewards), optimization of cooperative efficiency (penalties for irrelevant interactions, team effort, and action costs), and timely completion (solve time and terminal bonuses). Training follows a staged curriculum: initial "bootstrap" training encourages exploration and skill-target matching, followed by "refinement" focusing on path optimality and scheduling. Reward weight tuning is non-trivial and critical to achieving a usable policy.
The complete architecture and operational workflow are summarized as follows:
- Centralized Training, Decentralized Execution: The critic observes the full environment state, while actors receive agent-centric observations; post-training, each robot follows its decentralized policy.
- Unified Allocation and Planning: No separate assignment or task split heuristics are required, as both allocation and motion emerge from policy optimization.
- Replanning via Observation Buffering: The system accommodates new (dynamic) targets by buffering solved targets' observation slots with new incoming objectives.

Figure 2: The end-to-end workflow, including the interaction of execution and training blocks, data flow distinctions, and environmental visualization depicting agent and target placements with skill annotations.
Experimental Evaluation
The framework is quantitatively evaluated on grids with three agents and 5–7 targets, each with randomly assigned heterogeneous skills and collaborative (AND) or individual (OR) completion requirements. Policies are compared against exhaustive search (ES) baselines that guarantee optimality but are non-tractable with larger problems.
Policy Quality Relative to Optimality
- Success Rates: Policies solve over 90% of environments with 5–7 targets.
- Solution Optimality: RL policies achieve up to 86% of the optimal solve time and up to 92% of the optimal team effort (minimizing aggregate agent movement).
- Scalability Limitations: Solution optimality degrades gradually with increasing number of targets due to increased combinatorial search space and fixed observation bottlenecks.
Inference and Runtime Complexity
Inference time of the trained (MAPPO) policy is constant—independent of the number of entities—since it is dictated by neural network forward passes. By contrast, ES approaches demonstrate exponential scaling in inference time as targets and agents increase, rapidly becoming impractical for online (real-time) planning.
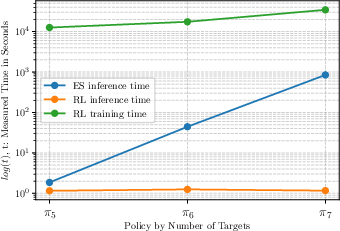
Figure 3: Inference and training time scaling with respect to the number of solved targets, illustrating the exponential trajectory for ES and the constant complexity for RL inference.
Online Replanning
The approach supports online replanning by dynamically populating the available observation buffer with new targets as previous ones are solved. Empirical evaluation reveals no statistically significant difference in performance for policies explicitly trained for replanning versus those that are not, affirming the robustness of the underlying attention and scheduling mechanisms.
Limitations and Future Directions
The fixed-size observation encoding, while well-suited for predictable, bounded problems, limits scalability with larger teams or variable task sets. This creates an inherent trade-off between operational flexibility and computational tractability. The paper notes that recent advances in graph neural network (GNN)-based observation encodings could offer a mechanism to scale to arbitrary numbers of agents or tasks, but integrating these into actor-critic RL frameworks brings algorithmic and stability challenges, especially for decentralized execution under partial observability.
Reward engineering is identified as a critical and delicate process; the system demonstrates sensitivity to the weightings, especially as the problem dimensionality increases, necessitating careful curriculum design and possible automated reward tuning methods.
Implications and Prospects for Robotics and AI
The results reinforce that significant computation can be front-loaded into offline training to enable rapid, near-optimal real-time planning in constrained environments, a property highly beneficial in embedded and space robotics, where communication latency and computational power are primary limiting factors. The demonstrated approach presents a template for future frameworks seeking to unify planning, allocation, and scheduling for complex robotic teams.
The principal theoretical implication is that, with sufficient observation and reward design, emergent cooperation and division of labor can be induced without explicit centralized planners or assignment solvers.
Promising future directions include:
- Integration with Variable-Cardinality GNNs: Enabling arbitrary team and target sizes for domain transferability and increased robustness.
- Incorporation of Partial Observability: Extending the approach to problems where agents can only observe local (rather than global) state, introducing realistic communication and sensing constraints.
- Task Generalization via World Models: Employing latent state autoencoding (e.g., DreamerV3-style world modeling) can further abstract and compress the planning problem for large-scale environments.
Conclusion
This work demonstrates a unified, RL-based framework for collaborative path planning and task scheduling in heterogeneous multi-robot teams, achieving near-optimal solutions with constant real-time inference. The empirical analyses underline both the practical feasibility for embedded real-time robotics and the standing open questions about reward shaping, scalability, and observation design. Addressing the variable input bottleneck and partial observability remain critical next steps for robust deployment in large, adaptive, and decentralized systems.

