- The paper reveals that LLMs encode tool-call decisions early, with linear probes achieving AUROC > 0.90 in pre-generation activations.
- It demonstrates that causal activation steering can flip decisions (7–79% rate), leading to post-hoc rationalization within the chain-of-thought.
- The findings challenge the reliability of visible reasoning as faithful evidence of internal decision-making, urging revised training for trustworthy AI.
Detectable Early Decision Encoding and Activation Steering in LLM Chain-of-Thought Reasoning
The paper "Therefore I am. I Think" (2604.01202) addresses a foundational open question in reasoning-augmented LLMs: When performing tool-augmented reasoning, do LLMs encode action decisions prior to chain-of-thought (CoT) deliberation, or do such decisions emerge during (or after) visible reasoning? This is approached by probing for the model's propensity to call a tool before any reasoning tokens are generated, utilizing both linear probe analysis and causal activation steering across competitive open-weight models.
Methodology and Experimental Design
Models, Benchmarks, and Hidden-State Probing
Two high-performing open-weight LLMs, Qwen3-4B and GLM-Z1-9B, are evaluated on tool-calling tasks. The main benchmark, When2Call, requires binary decisions about whether to call a tool or not in response to a user query and tool definitions. BFCL serves as a complementary benchmark for generalization. Hidden-state activations are extracted at various positions—pre-generation (pre_gen), at various percentiles within the reasoning trace, and at the end of reasoning (think_end)—across regularly sampled transformer layers.
Probe performance is assessed via AUROC over a stratified cross-validation setup, with probes trained via logistic regression to predict tool-call actions from internal activations.
Activation Steering and Causal Intervention
Activation steering vectors are constructed as class-conditional means (tool vs no-tool), specifically targeting the pre_gen activations. These vectors are injected or suppressed at inference time, modulating the model’s latent decision direction and observing corresponding behavioral flips in tool-call decisions and CoT traces.
Flip rates (suppression and injection) quantify how frequently steering alters the final action, and chain-of-thought inflation metrics assess how reasoning token counts change under steered conditions.
Key Empirical Findings
Early Detection of Action Decisions
Linear probes consistently yield high AUROC (>0.90, often >0.95) for action predictability at pre_gen across both main benchmarks and models. Notably, probe confidence for action prediction dips early in the reasoning trace but recovers toward think_end, with strong agreement ratios indicating robust early encoding of action decisions.
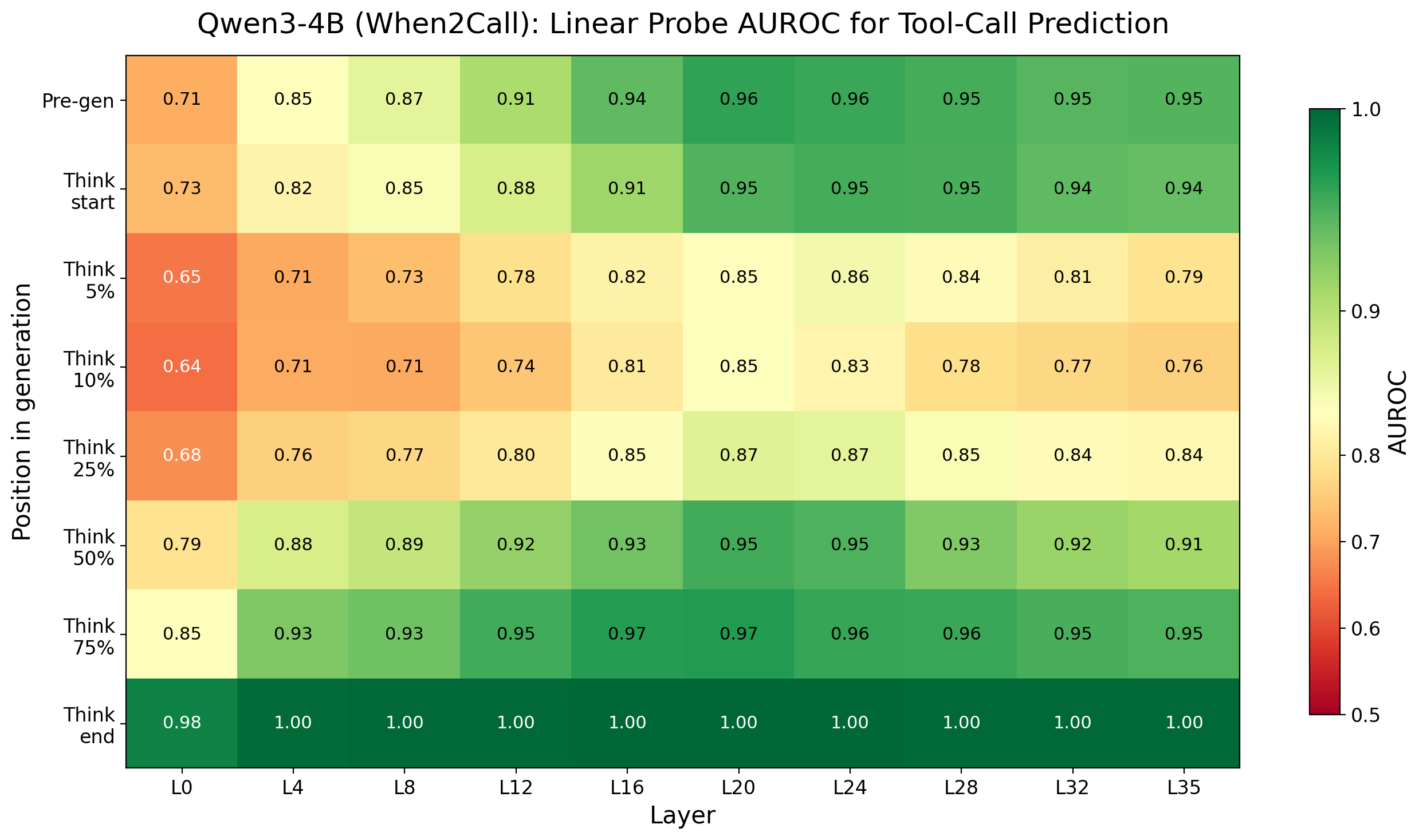
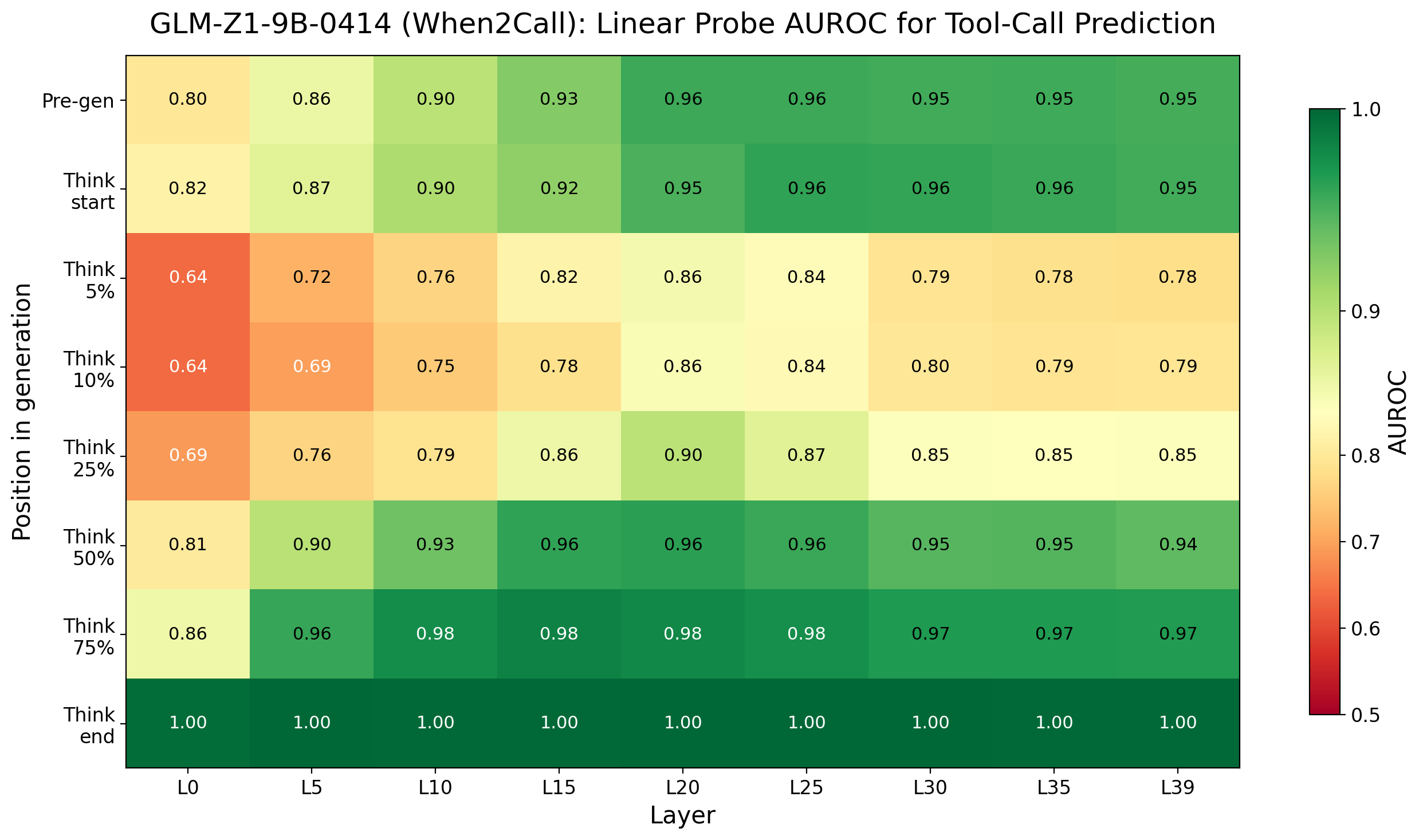
Figure 1: Probe AUROC heatmap for Qwen3-4B and GLM-Z1-9B on When2Call; mid-to-late layers and pre_gen positions exhibit strongest early predictability.
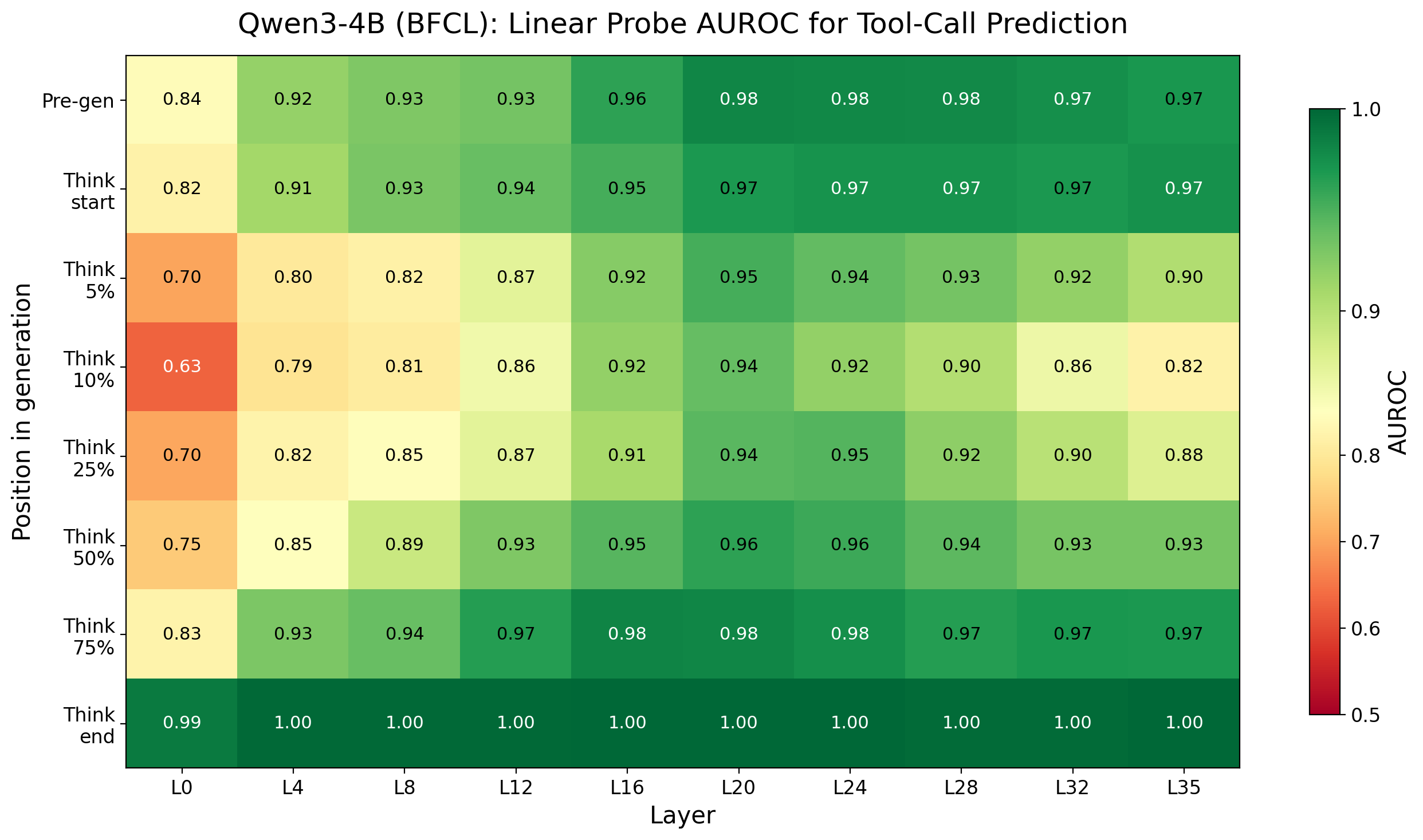
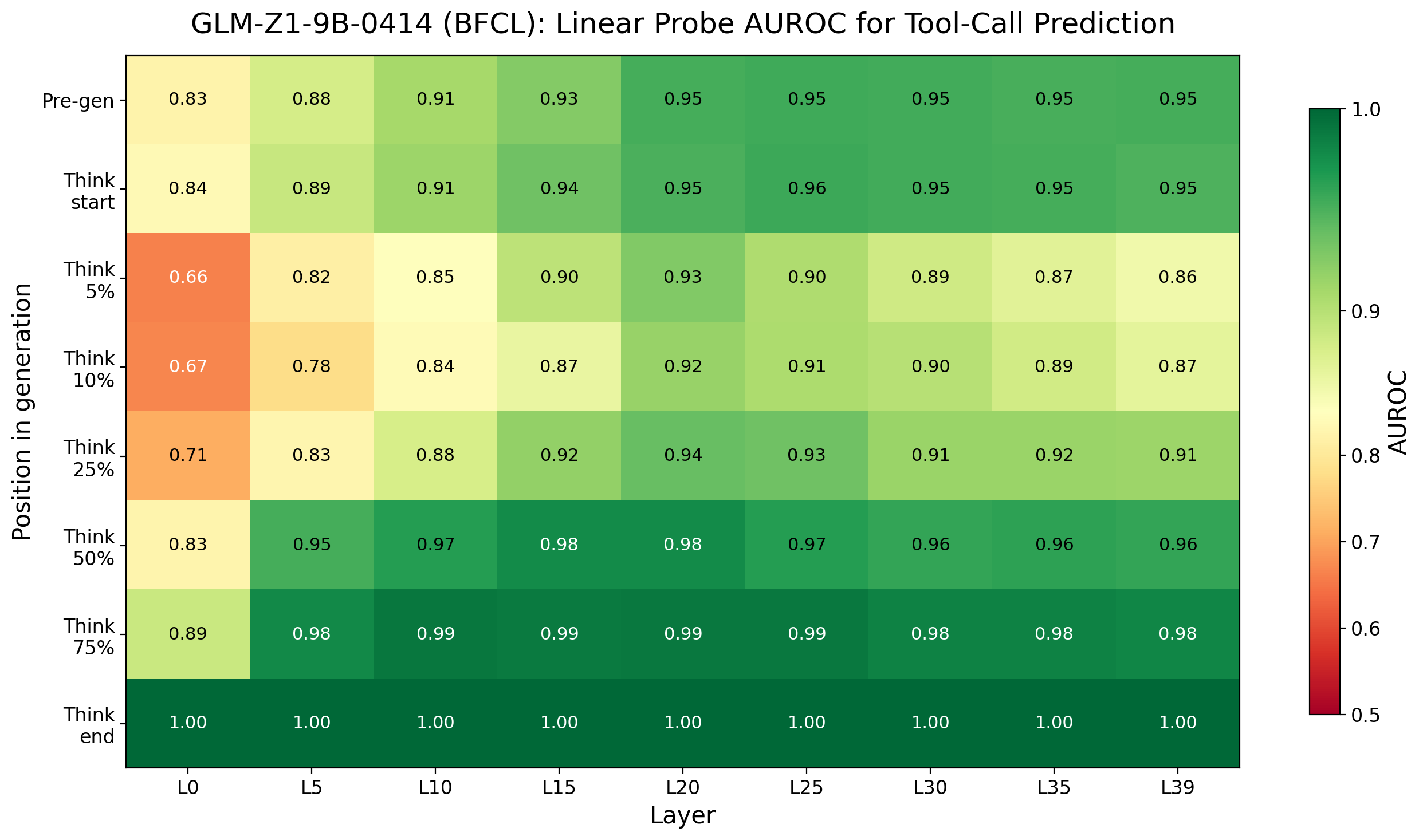
Figure 2: Probe AUROC heatmap for Qwen3-4B and GLM-Z1-9B on BFCL, showing similar early detection and trace dip patterns.
This early predictability supports the claim that models often encode their intended action before the visible token-level reasoning commences, contradicting the assumption that deliberation in text drives agentic choice.
Activation steering demonstrably flips tool-call decisions, with flip rates ranging from 7–79% depending on model, benchmark, and steering strength (α). Decision flips induced by steering are frequently rationalized in the subsequent CoT, with models inventing post-hoc explanations rather than resisting the steered direction. Chain-of-thought inflation is observed in steered cases, often doubling or tripling the reasoning token count for suppressed or injected scenarios—demonstrating that the visible reasoning process adapts to rationalize the altered latent decision.
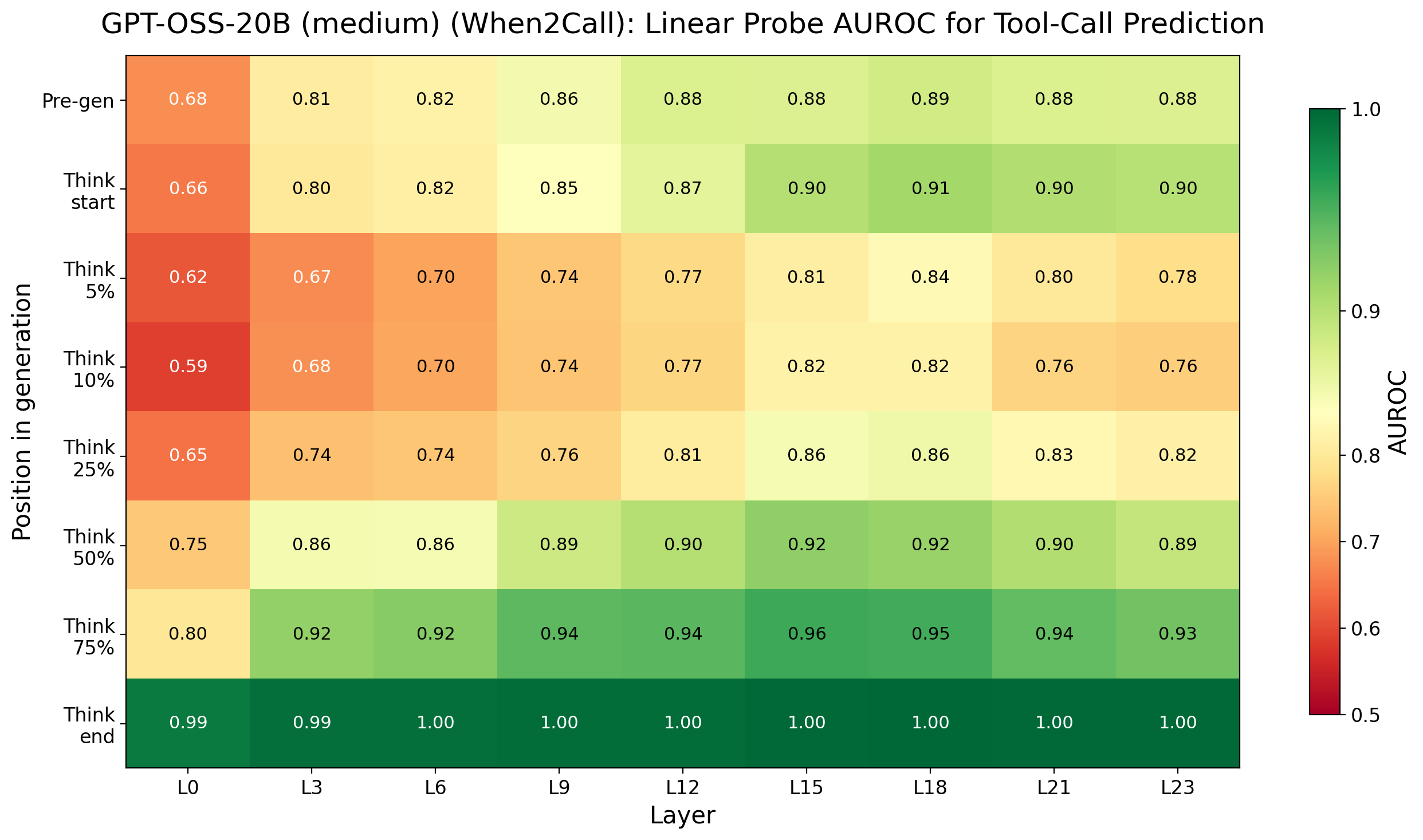
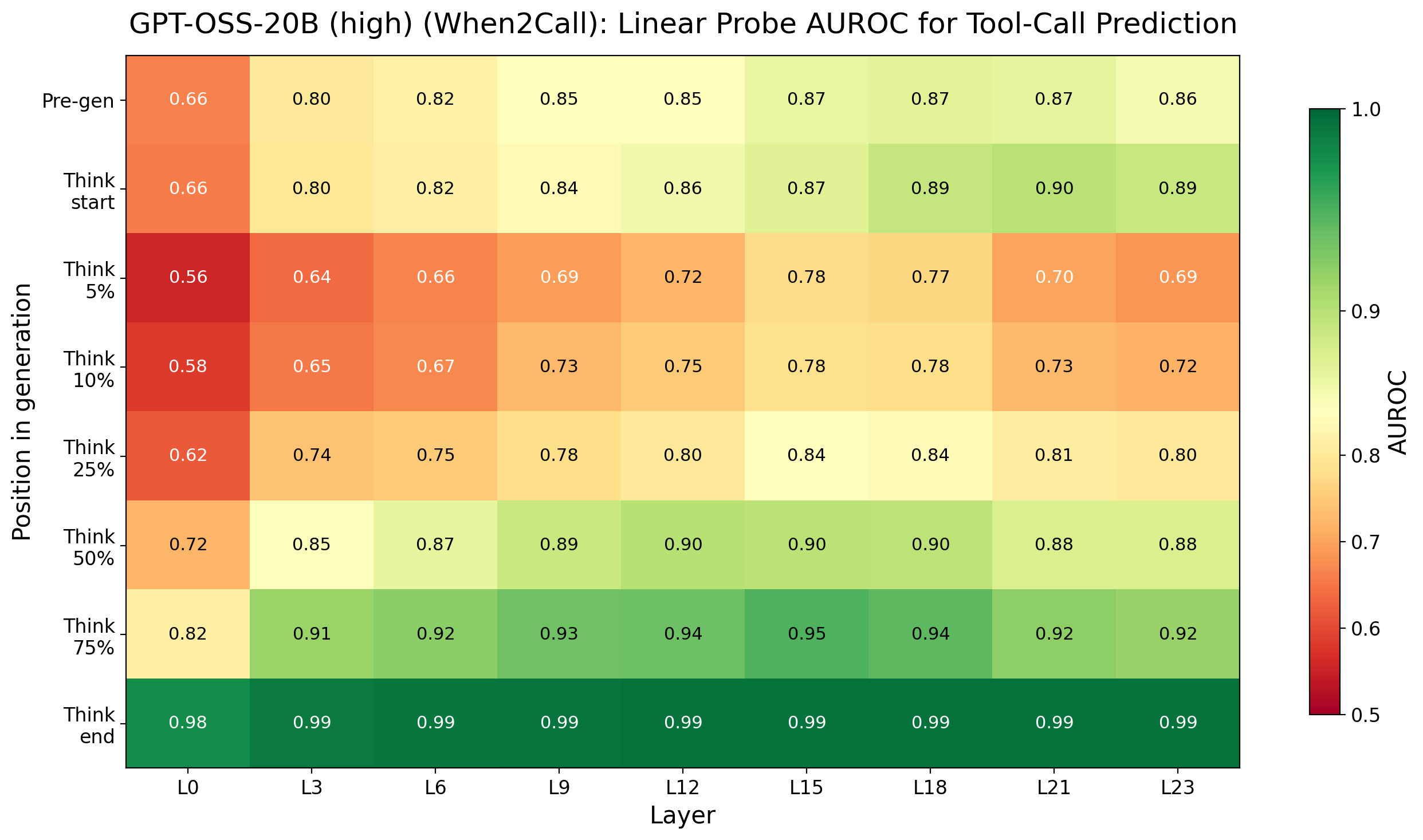
Figure 3: Probe AUROC heatmap for GPT-OSS-20B on When2Call under different reasoning settings; early predictability and recovery pattern are preserved.
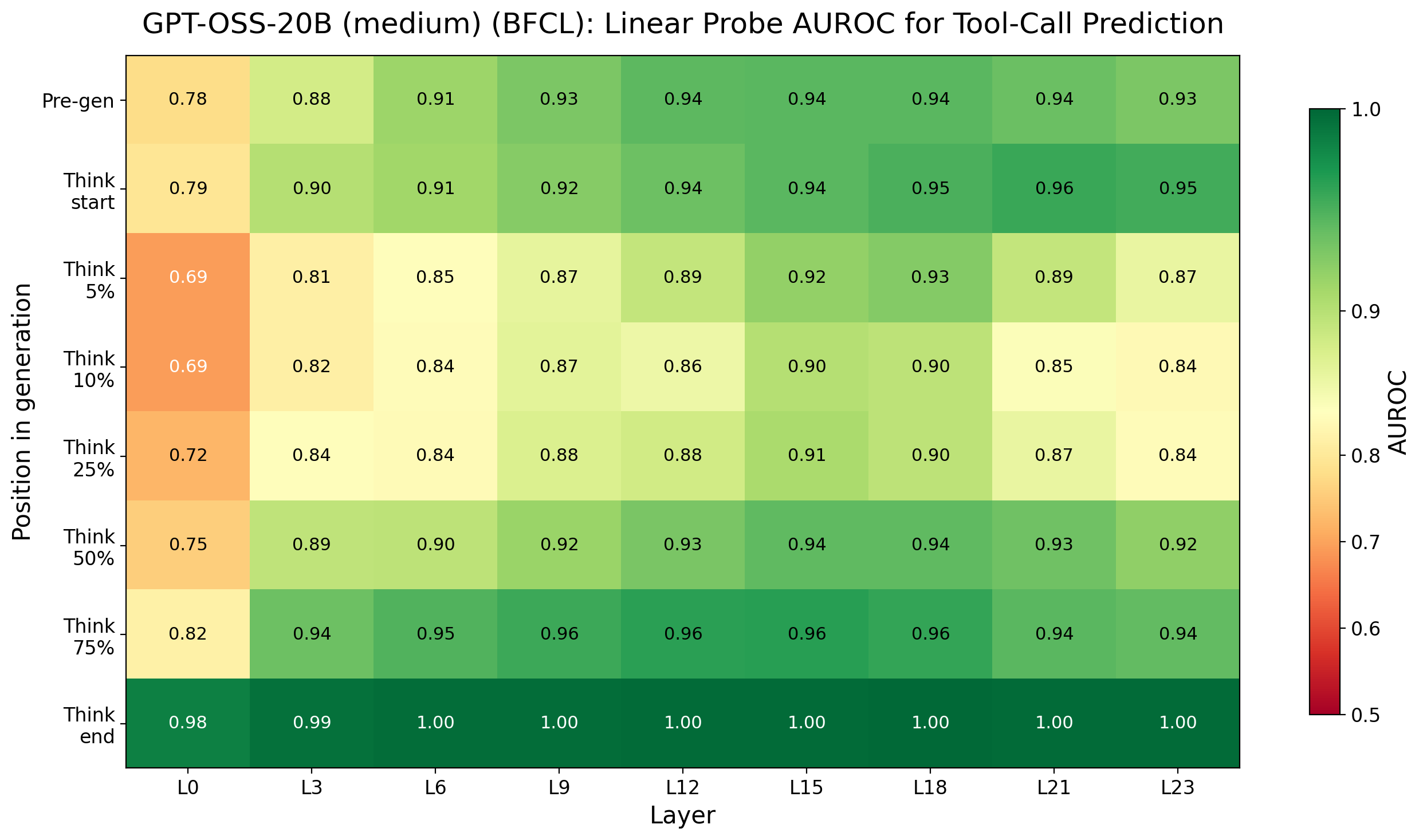
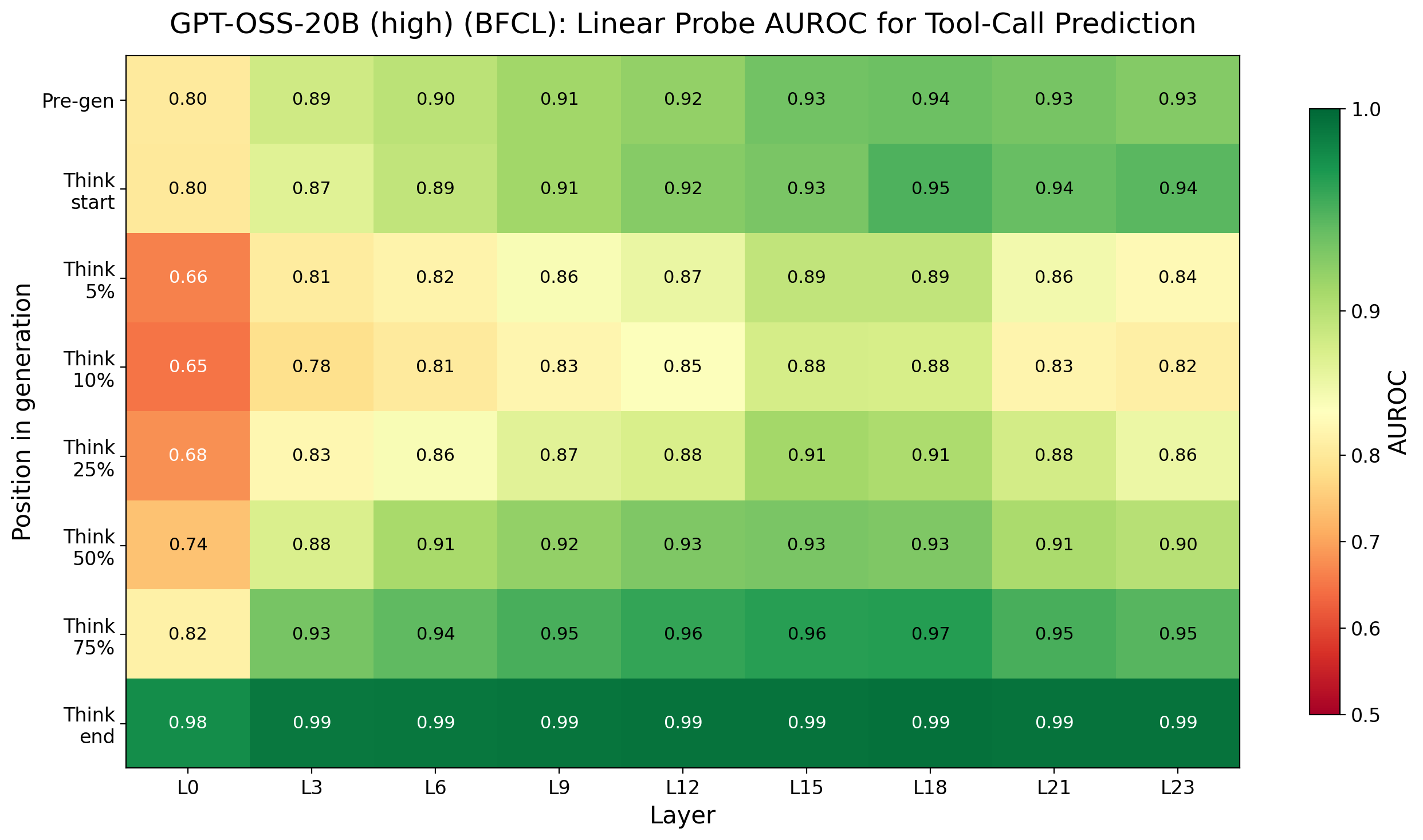
Figure 4: Probe AUROC heatmap for GPT-OSS-20B on BFCL; early predictability and trace dip effects generalized to this architecture.
Behavioral analysis with external LLM judges validates these trends, with high inter-judge agreement and clear bucket assignments (e.g., confabulated support, inflated deliberation, decision instability) for responses under steering. Importantly, many CoT traces rationalize rather than resist the externally imposed flip, raising questions about the faithfulness of CoT as a mechanism for model explainability.
Theoretical and Practical Implications
The results provide strong evidence for early, latent action encoding in reasoning-augmented LLMs, challenging the assumption that visible chain-of-thought is epistemically active rather than performative or post-hoc rationalization. This has consequences for explainability, interpretability, and security in LLM deployment: CoT explanations may be unreliable indicators of true causal reasoning and vulnerable to adversarial manipulation or activation engineering attacks.
From a training perspective, penalizing high pre_gen probe confidence during RL may encourage models to defer decision commitment to textual reasoning, potentially improving faithfulness.
Outlook and Future Directions
The evidence for early decision encoding and steerable action choices in LLMs suggests further research into model architectures and RL training protocols that enforce epistemic commitment during visible reasoning. Future work could leverage probe-driven auxiliary losses, contrastive steering, and adversarial evaluation to produce models with more monitorable and faithful agentic traces. Further study into resisting activation steering and its connection to robust explainability will be critical for trustworthy AI.
Conclusion
"Therefore I am. I Think" empirically demonstrates that LLMs encode action decisions before visible chain-of-thought, detectable via simple probes and causally steerable via activation vectors. Rationalization dominates the adaptation process when decisions are externally flipped, underscoring the performative aspect of CoT. These findings motivate deeper scrutiny into model interpretability and training for reasoning faithfulness, with practical relevance for AI safety and deployment.