- The paper introduces a two-stage pre-training approach that leverages 3D Gaussian-centric representations to improve scene geometry and semantic understanding.
- It decouples perception/forecasting and planning by using dual latent models, effectively addressing query permutation and temporal consistency issues.
- Experimental results demonstrate significant improvements in semantic occupancy, forecasting accuracy, and motion planning, outperforming baseline models.
Dual Latent World Models: Holistic Gaussian-centric Pre-training for Autonomous Driving
Motivation and Context
Holistic scene understanding for autonomous driving mandates an expressive, efficient, and temporally coherent representation to serve perception, forecasting, and planning pipelines. While Bird's Eye View (BEV) and query-based architectures realize efficiency, they lose geometric granularity. Recent advances pivot to sparse, explicit 3D Gaussian-centric representations, which provide a quantization-balanced alternative but critically depend on annotated supervision and lack a unified, self-supervised pre-training methodology appropriate for multi-task downstream integration.
This work addresses challenges in pre-training for Gaussian-centric driving models by introducing the DLWM (Dual Latent World Models) paradigm—a two-stage, holistic strategy enabling geometric and temporal self-supervised pre-training and providing explicit task-oriented temporal models. The decoupling of perception/forecasting (Gaussian flow) and planning (ego-trajectory) is a key design distinction, directly addressing the latent permutation ambiguity of Gaussian queries across timeline as well as the distinct requirements of predictive modeling in both occupancy and planning tasks.
DLWM Architecture and Methodology
The approach consists of two pipeline stages:
- Stage 1 (Gaussian Representation Learning): Self-supervised learning reconstructs scene geometry and semantics from multiview imagery via 3D Gaussian splatting. Supervision is constructed using LiDAR-derived (sparse) and foundation-model-generated (pseudo-dense) depth and semantic signals, bypassing manual annotation. Gaussian queries contain geometric (mean, covariance, opacity) and semantic attributes refined using image cross-attention and temporal sparse convolution for context encoding.
- Stage 2 (Dual Temporal Latent World Models):
- Gaussian-flow-guided Latent Model: For semantic occupancy and dynamic forecasting, a learnable, frame-to-frame Gaussian flow field predicts feature evolution, aligned by ego-motion transformation, with supervision in the BEV rasterized latent space for regional correspondence (mitigating query permutation ambiguity).
- Ego-planning-guided Latent Model: For planning, fused latents are conditioned on predicted ego waypoints through motion-aware normalization and query cross-attention, with a dedicated loss for trajectory imitation and latent BEV consistency.
The resulting pre-trained features are then fine-tuned for semantic occupancy, 4D forecasting, and planning.
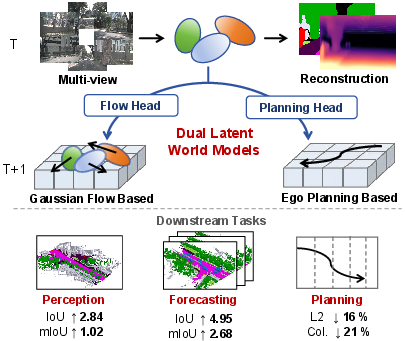
Figure 1: Illustration of the DLWM pipeline, linking pre-training with improved downstream task performance.
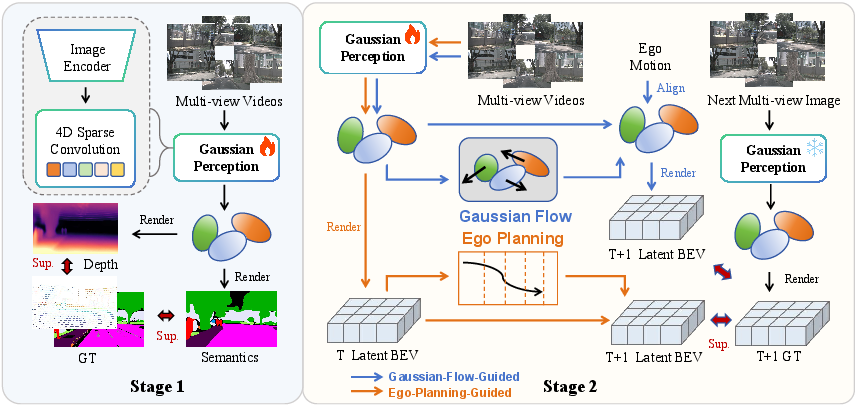
Figure 2: Detailed data pipeline of DLWM, showing Stage 1 for geometric-semantic feature learning and Stage 2 for dual temporal latent prediction modules.
Modeling Details
The 3DGS scene is maintained as an explicit set of G={gk}, updated at each timestep. The rendering aggregates Gaussians in depth-order for both image reconstruction and label-free semantic alignment. For temporal evolution, Gaussian Flow predicts per-query displacements, transformed via ego-motion and used for future latent construction. BEV rasterization projects updated queries to dense grid representation for loss computation, ensuring inter-frame consistency.
The planning latent model extracts structured BEV queries, interacts with randomly initialized waypoint queries, and infuses motion context through motion-aware layer normalization, supporting end-to-end imitation of future trajectories.
Experimental Results
Three principal tasks on nuScenes and SurroundOcc evaluations demonstrate the superiority of DLWM:
Semantic 3D Occupancy Perception: Two-stage pre-training yields 21.85 mIoU / 34.61 IoU, surpassing previous state-of-the-art and outperforming strong baselines by >1 mIoU and >2.8 IoU. The advantage is consistent across major classes.
4D Occupancy Forecasting: DLWM reaches 17.77 mIoU / 30.60 IoU (1s–3s horizon), outperforming prior supervised or weakly-supervised methods by wide margins and notably enhancing robustness of temporal predictions for both geometry and semantics.
Motion Planning: The average L2 trajectory error is reduced to 0.46 m, with a corresponding decrease in collision rate. This surpasses prior latent world model-based and explicit pipeline-based autonomous planners using similar input modalities.
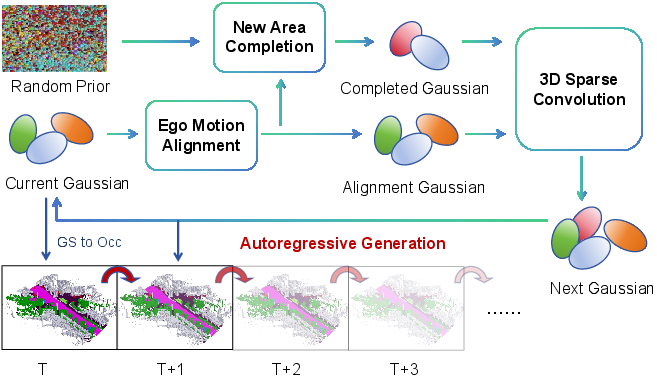
Figure 3: Stream-based 4D occupancy forecasting with Gaussian propagation and completion for evolving scene geometry.

Figure 4: Qualitative comparison—depth and semantic reconstruction accuracy at the current and next frame using predicted vs ground-truth supervision.
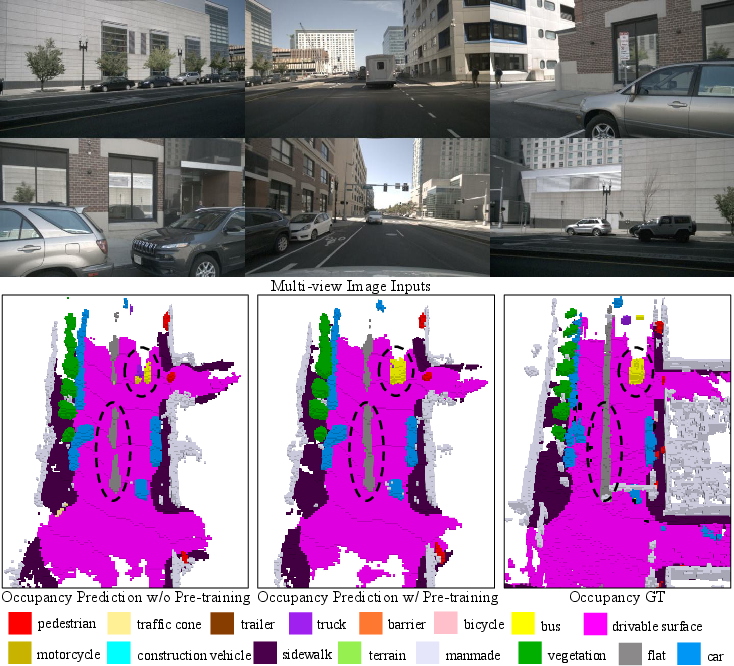
Figure 5: Comparison in 3D occupancy—DLWM yields greater geometric completeness and semantic consistency than both ground truth and non-pre-trained baselines.
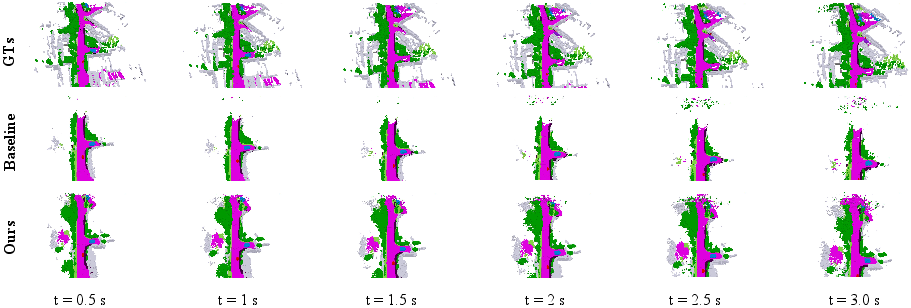
Figure 6: Forecasted occupancy volumes—DLWM delivers temporally and semantically consistent predictions, outperforming baselines across future horizons.
Ablation and Analysis
Substantial module-level and scaling ablations support architectural choices:
- Dense pseudo-depth and semantic supervision both provide gains over sparse losses alone, elevating mIoU by >1 point.
- Explicit temporal pre-training via Gaussian flow latent world modeling drives significant improvements in downstream perception and forecasting, validating the necessity of dual world models as opposed to a unified approach.
- Decoupling occupancy/forecasting and planning latent models (i.e., dual vs unified) is justified by improved learnability and final accuracy (confirmed by supplementary ablation).
- Inference overhead is minimal since pre-training modules are not invoked at test time.
Practical and Theoretical Implications
Practically, DLWM demonstrates that autonomous driving systems can achieve state-of-the-art 3D occupancy and planning strictly from multi-camera input and without human annotation, leveraging a Gaussian-centric representation and a task-decomposed pre-training strategy. The framework is generalizable to future advances in BEV and query-based perception and enables rapid adaptation to new classes or environments via unsupervised updates in the representation module.
Theoretically, this approach resolves prior obstacles in end-to-end latent world modeling for multi-task multi-horizon learning within Gaussian-centric domain. The explicit use of BEV rasterization for temporal supervisory signals but not as the scene representation is critical, circumventing query permutation and sparsity issues. Furthermore, the pipeline advances compositional scene modeling by demonstrating the benefit of explicit dynamic/static decomposition and targeted, task-oriented temporal attention/propagation.
Outlook and Future Directions
Future research should investigate:
- Extending DLWM's principles to multimodal fusion (incorporating LiDAR, radar, etc.) for robustness in adverse conditions.
- Generalizing dual temporal world models to broader classes of pretext tasks (beyond occupancy and planning) and other explicit 3D representations.
- Scaling paradigm to open-world semantics via continual learning or foundation models, given the success of label-free supervision.
- Further probing the limits of purely self-supervised (open-world) driving policy learning via more sophisticated latent world model designs or longer temporal horizons.
Conclusion
DLWM establishes a holistic, self-supervised pre-training methodology for Gaussian-centric autonomous driving. By explicitly decoupling occupancy/forecasting and planning representation learning in dual latent world models, it delivers measurable, consistent improvements in downstream task performance, confirmed both quantitatively and qualitatively. DLWM constitutes a robust foundation for advancing unified scene understanding and decision making in vision-centric driving, informing future developments in geometric representation learning, self-supervised temporal modeling, and scalable multi-task autonomy (2604.00969).