- The paper introduces a novel framework that decomposes team rewards into agent-specific language feedback for precise credit assignment.
- It operationalizes a centralized training and decentralized execution paradigm, enabling effective policy evolution and emergent role specialization.
- Experiments on strategic games and language tasks demonstrate significant performance gains and improved coordination over baseline methods.
LangMARL: Natural Language Multi-Agent Reinforcement Learning
Introduction and Motivation
Multi-agent systems (MAS) based on LLMs have showcased substantial collaborative potential across domains such as strategic games, coding, and reasoning benchmarks. However, current LLM-based MAS architectures lack mechanisms for fully autonomous, adaptive coordination, chiefly due to an unaddressed multi-agent credit assignment bottleneck: global team rewards provide only coarse, ambiguous learning signals, making it difficult for individual agents to optimize their policies with respect to their specific contributions. Prior approaches primarily rely on naïve monolithic reflections or global prompt rewrites that ignore individual causal roles, resulting in inefficient learning and frequent coordination collapse.
LangMARL addresses these deficiencies by extending core principles from classical cooperative multi-agent reinforcement learning (MARL) into the natural language space, with a focus on structured, agent-level credit assignment. By operationalizing the "centralized training, decentralized execution" (CTDE) paradigm for LLM agents, LangMARL decomposes team rewards into actionable, agent-specific language feedback, thus enabling effective policy evolution and robust emergent coordination strategies.
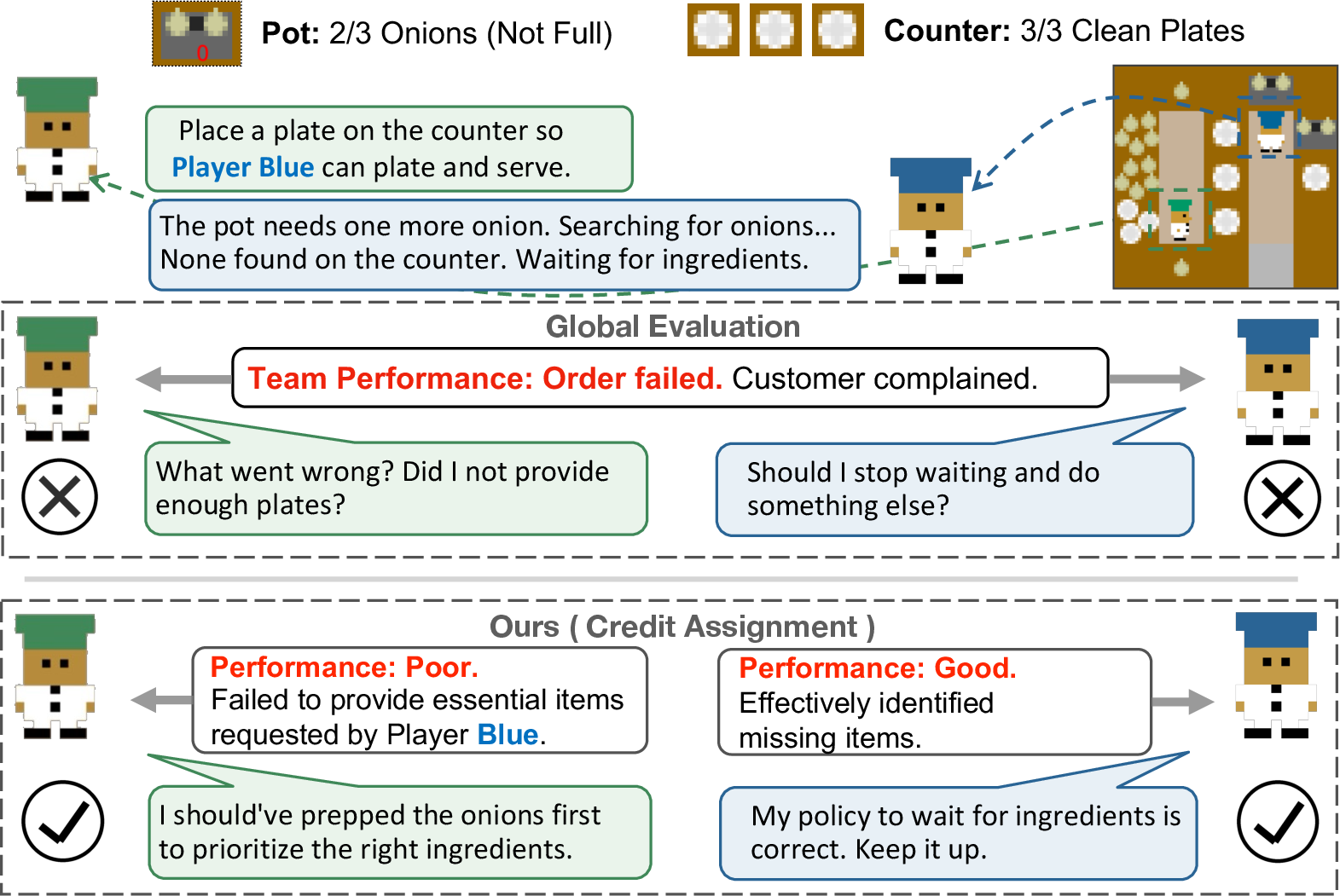
Figure 1: Challenges in multi-agent credit assignment. Unstructured global evaluation obscures individual agent contributions; LangMARL decomposes joint performance into agent-specific credits.
Framework Overview
LangMARL consists of four principal modules, all instantiated in the language domain: (1) Language Policy Actors, with each agent maintaining a separate text-parameterized policy; (2) a Centralized Language Critic that observes joint trajectories and executes structured, causal credit assignment in natural language; (3) a Language Policy Gradient Estimator translating these credits into "language gradients"—semantic update directions; and (4) a Language Policy Optimizer to aggregate multiple language gradients into revised agent policies via LLM-based composition.
This architecture aligns MARL concepts with language-level analogues: the classical policy gradients and value functions correspond to language-driven optimization over discrete natural language policy representations. During training, centralized critic access to global trajectories allows dense, causally informed feedback, while execution remains decentralized and observation-based.
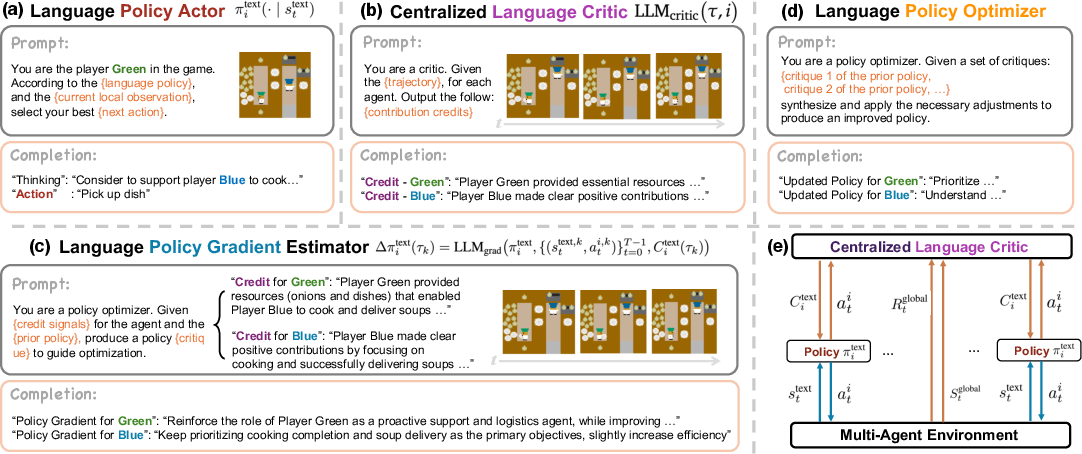

Figure 3: The LangMARL Architecture—conceptual mapping between classical MARL and LangMARL. Language policies, critics, and gradients replace their numeric counterparts in the CTDE loop.
Central Mechanisms: Credit Assignment and Language Policy Optimization
LangMARL's core advancement is the integration of trajectory-level, agent-specific credit assignment with language-space policy optimization. The Centralized Language Critic, instantiated by an LLM, evaluates full episodic trajectories and generates explicit, agent-targeted feedback detailing causal influence on outcomes. These structured credits replace scalar or joint signals, allowing learning to be grounded in precise behavioral attributions.
Subsequently, the Language Policy Gradient Estimator conditions on both agent policies and language credits (as well as observation-action sequences), producing natural-language directives that serve as functional analogues to conventional policy gradients. Multiple such "language gradients" are then aggregated by an LLM-based semantic integrator before the final Language Policy Optimizer composes the new policy text.
Figure 2: System pipeline—decentralized language policy execution, centralized credit assignment, and natural language batch optimization complete the loop.
Empirical Evaluation
Comprehensive experiments on strategic games (Overcooked-AI, Pistonball) and open-ended language tasks (HumanEval coding, HotPotQA, MATH) demonstrate that LangMARL consistently and significantly outperforms both static prompting and baseline self-evolving methods (Reflexion, TextGrad, Symbolic, DSPy, etc.). Notably, LangMARL achieves the highest reward and accuracy across all settings, with pronounced gains in complex, high-coordination domains.
Ablation analyses validate that agent-level credit assignment is pivotal for both policy convergence speed and final performance: ablations that disable individual credit signals and revert to coarse global rewards result in dramatic instability and performance degradation, particularly as coordination complexity increases.

Figure 4: Impact of credit assignment (green: baseline without credit assignment; blue: LangMARL). Explicit credit assignment results in superior convergence and stability.
Furthermore, qualitative studies reveal emergent role specialization. Without explicit prior role differentiation, iterative optimization via central credit assignment leads agents to spontaneously self-organize into complementary functions (e.g., one agent focusing on implementation, another specializing in critique and refinement in collaborative coding scenarios).
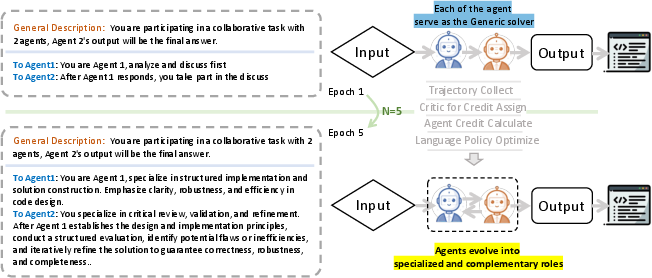
Figure 5: Emergent role specialization. Initial agents are undifferentiated; after credit-driven optimization, functional specialization arises (top: symmetric, bottom: specialized).
Sensitivity and Component Analysis
LangMARL's efficacy is robust to underlying LLM backbone quality and rollout budget. While stronger models (e.g., Gemini-3-Flash, Llama-3.3-70B) yield incrementally better results, performance on strategic and language tasks remains superior to baselines across scales. Increased rollout budgets systematically improve results in low-agent scenarios; in larger systems, the benefit saturates, indicating an optimal frequency for experience collection.

Figure 6: Sensitivity analysis: (a) comparison across LLM backbones; (b,c) effect of rollout volume on HumanEval and Pistonball.
Qualitative Case Studies
Case studies in Overcooked-AI illustrate how the critic correctly diagnoses coordination bottlenecks and generates corrective, agent-specific policy modifications (e.g., instructing Player Green to prioritize timely item delivery). In Pistonball, the critic detects and addresses geometric blockages by assigning corrective language gradients to the culpable agent.
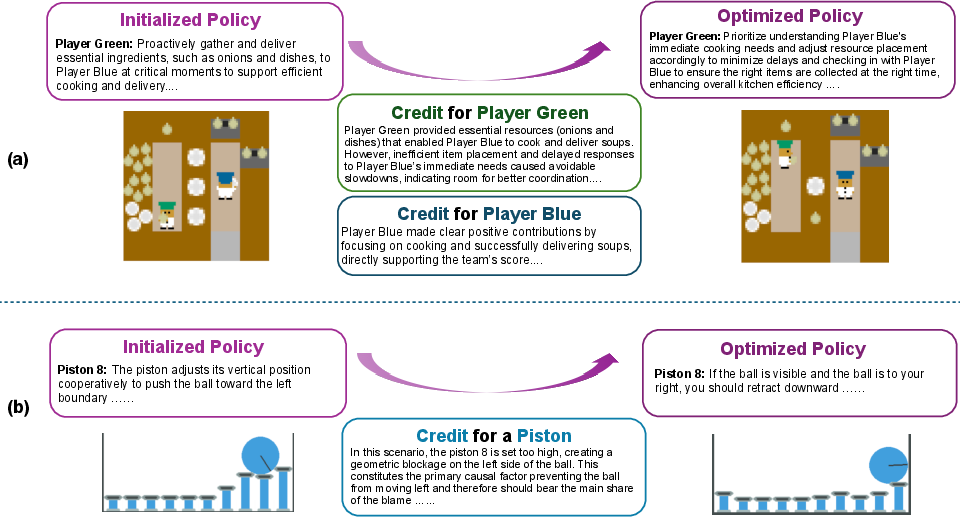
Figure 7: Language-based credit assignment and optimization in action. Targeted feedback leads to concrete behavioral improvements.
Implications and Future Directions
By bridging credit assignment and language-driven optimization, LangMARL sets a new formal foundation for scalable, interpretable, and robust policy evolution in LLM-based multi-agent systems. Practically, LangMARL enables reliable team-level coordination in applications from collaborative planning to autonomous multi-agent software engineering, wherever causal attributions must be disentangled from sparse global feedback. Theoretically, it demonstrates that natural language can act as an effective first-class optimization substrate, supporting complex functional role emergence and structured division of labor.
Future work should extend these ideas along two axes: (1) dynamic agent instantiation for scalable hierarchical team formation and sub-task orchestration, and (2) robust handling of extremely long-horizon, sparse-reward scenarios via hierarchical semantic decomposition and critic specialization. Additionally, study on the interaction between language-based optimization and the internal reasoning capacity of diverse LLM architectures remains an open area.
Conclusion
LangMARL introduces a principled, language-grounded credit assignment framework for multi-agent LLM systems, enabling meaningful policy evolution and robust autonomous coordination. Experiments demonstrate that trajectory-level, agent-targeted credit signals are essential for learning stability, emergent role specialization, and superior generalization across complex domains. The paradigm paves the way for the systematic application of MARL principles in LLM ecosystems, supporting the next generation of intelligent, adaptive, large-scale agentic systems.
(For further details and code, see "LangMARL: Natural Language Multi-Agent Reinforcement Learning" (2604.00722).)