- The paper introduces language-driven reward specification that outperforms hand-tuned rewards, achieving over 50% improvement on key MARL benchmarks.
- It demonstrates a dynamic adaptation method through iterative refinement, reducing manual tuning and effectively handling non-stationarity in multi-agent systems.
- It proves the benefits of inherent human alignment and interpretability by using natural language inputs, fostering broader stakeholder involvement and scalability.
Language-Driven Reward Specification for Multi-Agent Coordination: Towards the End of Reward Engineering
Motivation and Limitations of Traditional Reward Engineering
Reward engineering in multi-agent reinforcement learning (MARL) is fundamentally constrained by the challenge of translating high-level human objectives into low-level numerical reward functions. The issues are amplified by the combinatorial complexity of credit assignment, intrinsic non-stationarity arising from co-adaptation, exponential scaling in joint action/state spaces, and misalignment between individual and collective incentives. Existing frameworks—centralized training with decentralized execution, emergent communication, inverse reinforcement learning, and preference learning—mitigate but do not solve these problems, demanding substantial domain-specific manual tuning and intervention.

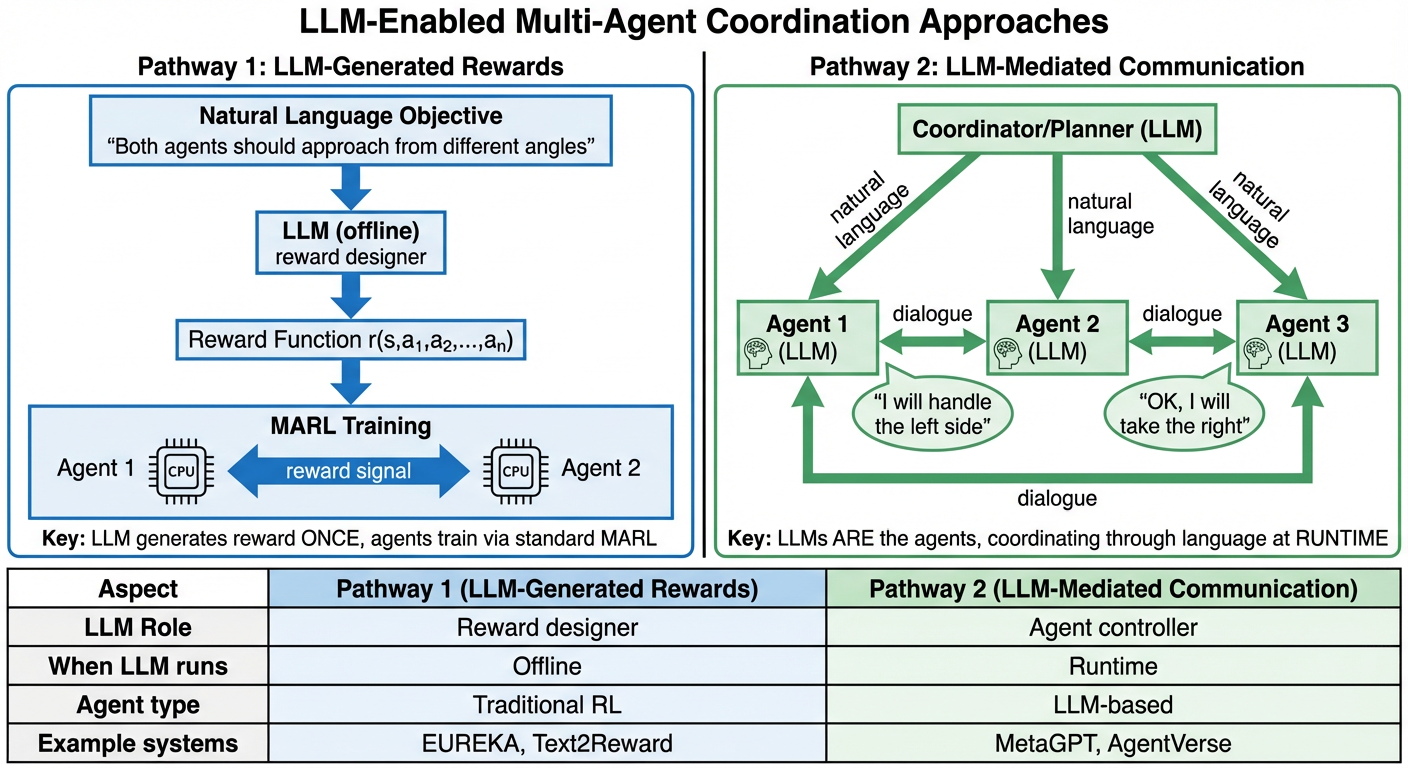
Figure 1: The paradigm shift from reward engineering to language-based objectives, eliminating manual engineering in favor of direct semantic intent.
Paradigm Shift: LLMs as Objective Specifiers
LLMs—such as GPT-4 and its successors—enable a transition from reward engineering to language-driven specification. Instead of constructing reward functions through trial-and-error, researchers and end-users can specify objectives directly in natural language. The LLM translates these objectives into reward code, leveraging domain knowledge encoded in its parameters via pretraining on vast corpora.
Key attributes of LLM-enabled objective specification include:
Three Pillars of Language-Based Objectives
The paper structures the LLM-for-MARL objective paradigm around three interdependent pillars:
Pillar 1: Semantic Reward Specification
Natural language enables specification of objectives that reflect nuanced human intent more robustly than numeric reward vectors. Empirical evidence (EUREKA) suggests zero-shot LLM-generated rewards outperform expert designs on diverse manipulation and locomotion tasks, with average normalized improvements exceeding 50%. Semantic reward forms also exhibit robustness to changes in agent counts, task complexity, and environmental configurations, supporting directly transferable coordination policies.
Pillar 2: Dynamic Adaptation
LLMs facilitate dynamic adaptation through iterative refinement protocols (e.g., CARD's Trajectory Preference Evaluation). Observed behaviors are summarized in natural language and used to refine the reward objective without manual inspection, enabling rapid realignment in response to environment drift, population shift, or objective re-specification. This continuous loop outpaces traditional reengineering and supports robustness in non-stationary, evolving multi-agent systems.
Pillar 3: Inherent Human Alignment
Alignment is achieved by default as language specifications are directly interpretable and modifiable by non-technical stakeholders, not solely reward engineers. Objective verification and debugging proceed at the specification level, not via code review of arcane reward functions. Further, RLVR (Reinforcement Learning from Verifiable Rewards) shows that training LLMs on language-verifiable criteria yields emergent reasoning aligned with human preferences and objectives.
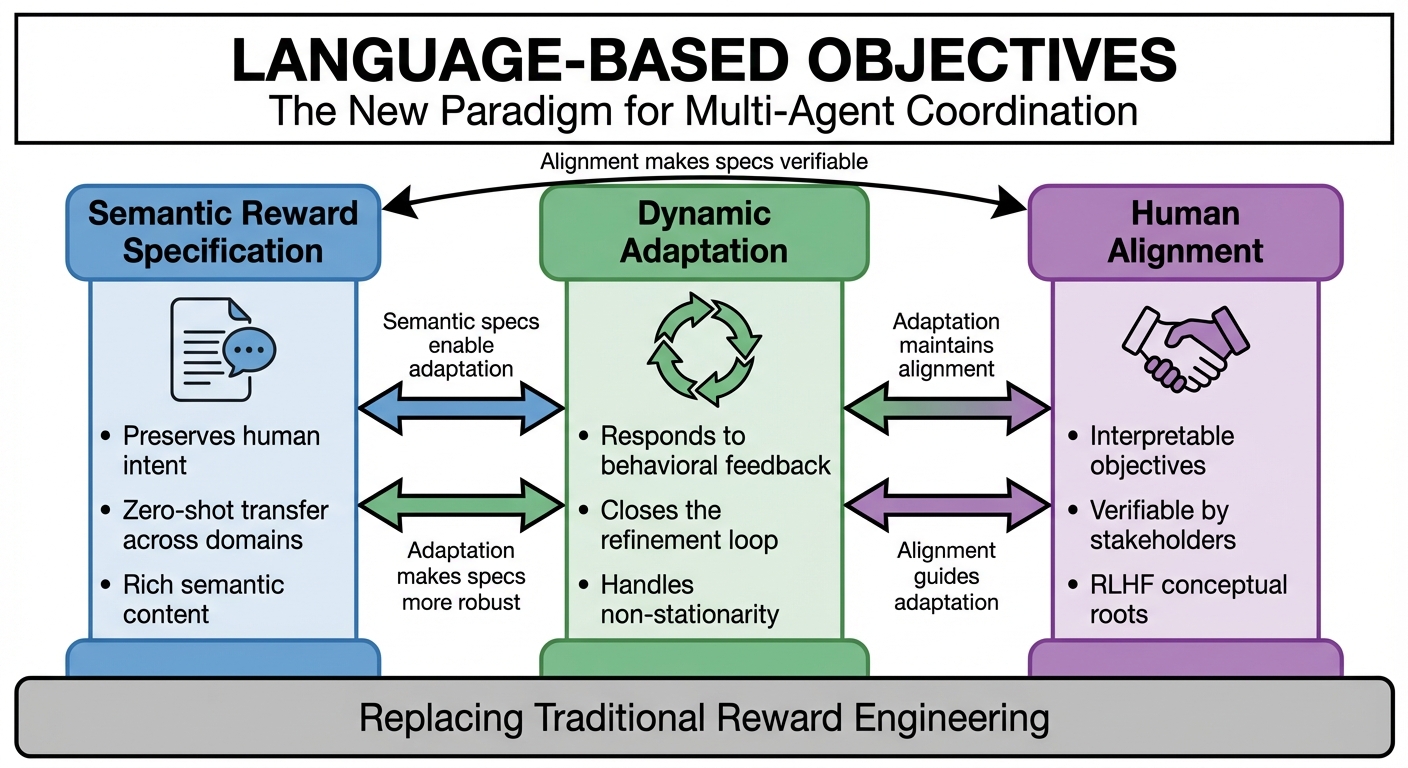
Figure 3: The three interconnected pillars—semantic specification, dynamic adaptation, human alignment—reinforcing scalability, interpretability, and adaptability.
Experimental Validation and Empirical Claims
The proposed experimental agenda investigates the fundamental thesis and pillar claims. Strong/contradictory claims made herein:
- LLM-generated rewards match or exceed hand-tuned rewards on complex MARL benchmarks, reducing reward engineering time by an order of magnitude.
- Language specifications generalize across tasks and domains, requiring zero or near-zero retuning for environment/agent-set variations.
- Dynamic adaptation via LLMs significantly outpaces manual reward revision in restoring coordination after perturbations or objective drift (τ90 as a critical metric).
- Scalability: The reward specification complexity is O(1) with fixed language prompts, compared to O(n) or worse for traditional engineering as the agent number grows.
- Interpretability: Human alignment effects are most pronounced for participants with limited RL expertise, democratizing reward function comprehension and adjustment.
Benchmarks proposed include the Multi-Agent MuJoCo, SMARTS for autonomous vehicles, and resource allocation social dilemma environments—not trivial testbeds where reward engineering is effectively solved.
Challenges and Limitations
Transitioning to language-driven objectives introduces challenges:
- Computational overhead: LLM inference is orders of magnitude slower than direct reward computation; amortization and distillation strategies are necessary for practical deployment.
- Hallucination and mis-specification: LLMs may inadvertently incentivize unsafe or undesirable behaviors. Ensemble critics, formal verification, and constrained templates are recommended for safety-critical systems.
- Ambiguity in language: Specification ambiguity may yield substantial reward function variance; structured and context-rich prompts can mitigate but not eliminate this.
- Scalability: Language-based coordination becomes comms-intensive in large teams; hierarchical and locality-focused reward specification schemes are needed.
- Evaluation/baseline gaps: Lack of standardized MARL benchmarks for language objective alignment, beyond reward maximization.
Implications and Future Trajectories
Practical implications include:
- Reduction of domain-specific reward engineering, freeing resources for more substantive experiment design and reducing bottlenecks in ML deployment pipelines.
- Broader access to reward specification, permitting direct stakeholder involvement and real-time adjustment by non-technical users.
- Improved safety and robustness through interpretable, auditable objectives.
Theoretical developments will likely focus on hybrid reward-language protocols, meta-learning for prompt engineering, and multidisciplinary advances in semantic world model alignment for agents. Long-term trajectories include semantic coordination through implicit, language-derived shared world models, transcending explicit communication.
Conclusion
The paradigm of manual reward engineering in MARL is approaching its practical limits. LLM-driven language objectives provide a scalable, generalizable, and human-aligned alternative, as validated by strong empirical performance and robustness across diverse benchmarks. Significant challenges remain regarding computational cost, ambiguity management, and safety, but the transition to language-based specification promises a new regime for multi-agent coordination, with far-reaching implications for both research and application.