- The paper introduces R-SVGP, an inverse-free framework that replaces matrix inversions with efficient matmul operations.
- It proposes specialized natural gradient updates and preconditioning to enhance convergence and numerical stability.
- Empirical results demonstrate up to 2.5× faster convergence and competitive accuracy on both regression and classification tasks.
Authoritative Summary of "Inverse-Free Sparse Variational Gaussian Processes" (2604.00697)
Introduction and Motivation
Sparse variational Gaussian processes (SVGPs) remain at the forefront of scalable Bayesian nonparametric modeling, but training them involves computational bottlenecks, particularly due to matrix inversions and Cholesky decompositions. Such operations are ill-suited for low-precision, massively parallel hardware typical in modern deep learning ecosystems. The paper addresses this by introducing a practical inverse-free SVGP framework, termed R-SVGP, which replaces all matrix inversions with matmul-based objectives and updates, enabling efficient exploitation of hardware acceleration.
Parameterization and Inverse-Free Bounds
The SVGP framework approximates the GP posterior using inducing points Z∈RM×D with variational distribution q(u), yielding an ELBO involving predictive means, variances, and KL divergences. Standard approaches (M-SVGP, W-SVGP, L-SVGP) depend on matrix decompositions. R-SVGP introduces an auxiliary parameter T, intended to mimic K~−1 but optimizes it using only matmuls.
The R-SVGP bound upper-bounds the L-SVGP predictive variance via:
σn2(L)≤knn−knu(2T−TK~T)kun
with a corresponding closed-form KL upper bound. When T=K~−1, R-SVGP recovers L-SVGP, ensuring that nothing is lost in optimality.
Matmul-Only Optimization: Natural Gradient Updates
Optimizing T directly via off-the-shelf methods (e.g., Adam) was empirically unstable. The paper derives a specialized natural gradient (NG) update for T, parameterized via its Cholesky factor L:
∇~ℓA=L[tril(L⊤AL)−21(I+diag(L⊤AL))]
This update avoids any decompositions or inverses, improving both convergence and numerical stability, a critical advance for inverse-free SVGPs.
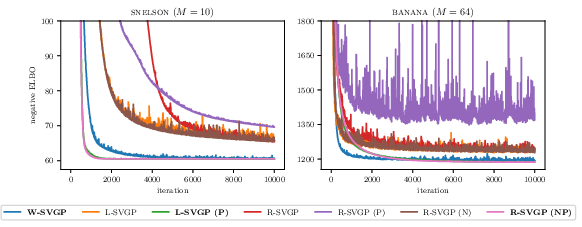
Figure 1: Loss traces on Snelson and banana datasets demonstrating stable convergence for NG-updated R-SVGP variants, matching Cholesky-based baselines.
Preconditioning and Practical Optimization
The paper identifies that L-SVGP parameterizations inherently suffer from slow convergence compared to W-SVGP. Through inducing mean preconditioning, using a preconditioner q(u)0 in R-SVGP, the model recovers stability and performance parity with W-SVGP, while remaining inverse-free. This preconditioner is the equivalent of a single Newton-Schulz iteration for q(u)1.
Moreover, the authors propose simple heuristics for step-size schedules, stopping criteria (e.g., normalized residuals), and trace estimation. The R-SVGP bound evaluation leverages Hutchinson’s method for unbiased trace estimation, lowering the evaluation cost to quadratic in q(u)2.
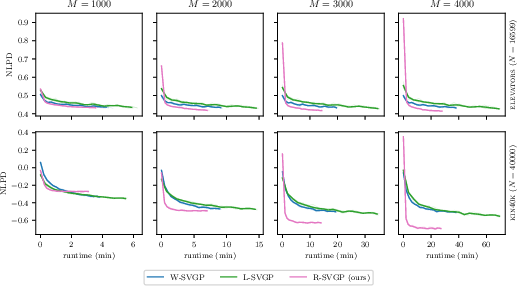
Figure 2: NLPD/runtime on elevators and kin40k datasets across inducing point counts, highlighting R-SVGP’s competitive training efficiency.
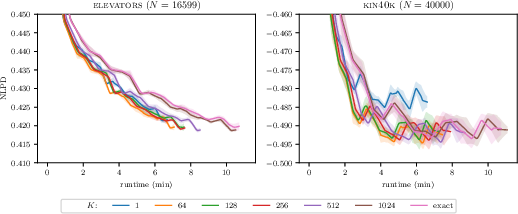
Figure 3: NLPD/runtime with varying Hutchinson probe counts q(u)3 substantiating the runtime-accuracy tradeoff for trace estimation.
Empirical Results: Efficacy and Efficiency
Experiments were conducted on toy, UCI regression and classification datasets, as well as complex models (deep GPs, convolutional kernels). Key findings:
- Efficacy: R-SVGP using NG updates and preconditioning matches or exceeds L/W-SVGP performance on both regression and classification tasks.
- Efficiency: With well-tuned heuristics, R-SVGP exhibited up to q(u)4 faster convergence compared to L-SVGP and up to q(u)5 speedup over W-SVGP, especially for large q(u)6.
- Generality: R-SVGP acts as a drop-in replacement for deep, multi-output, and convolutional GP models, retaining predictive performance even where variational flexibility is somewhat reduced.
Theoretical and Practical Implications
By eliminating decompositions and leveraging matmul-only computations, R-SVGP resolves the hardware mismatch hitherto limiting SVGP efficacy on accelerators, especially in low-precision regimes. The framework opens the possibility for further advances:
- Fully inverse-free parameterizations targeting W-SVGP (rather than L-SVGP) could offer both flexibility and performance, and remain an active direction.
- Randomized matmul techniques may further reduce NG update costs.
- Deep and complex models (e.g., large-scale Bayesian deep learning) may benefit from the reduced memory and improved runtime of R-SVGP.
Conclusion
The paper introduces the first practical, stable, inverse-free SVGP, R-SVGP, which achieves competitive statistical and computational results with matmul-only operations. Its integration into both standard and sophisticated SVGP architectures marks a significant advance in scalable Bayesian inference on modern hardware. Future work includes expanding flexibility, tuning for deep models, and exploiting extreme low-precision regimes for maximal speedup.