- The paper introduces a two-stage framework combining low-resolution estimation and super-resolution refinement to accurately construct high-resolution 3D radio maps.
- It leverages hybrid training data by using abundant low-resolution samples and a small fraction of high-resolution labels, significantly reducing data and computational costs.
- Experimental results demonstrate state-of-the-art performance with NMSE=0.0131, SSIM=0.923, and PSNR=32.31 dB, validating its effectiveness in complex urban environments.
DF-3DRME: A Data-Friendly Deep Learning Framework for High-Resolution 3D Radio Map Estimation
Introduction and Problem Statement
Accurate site-specific radio map (RM) estimation is essential for environment-aware wireless applications, including spectrum sharing, localization, and autonomous navigation in 6G and beyond. Classical statistical or empirical propagation models are limited in their ability to capture fine-grained, heterogeneous propagation effects dictated by the 3D geometry, especially in urban and complex environments. Data-driven deep learning (DL) approaches leveraging environment maps (EMs) have demonstrated superior performance, but scale poorly to high-resolution 3D RMs due to the prohibitive cost associated with collecting, labeling, and simulating massive high-resolution datasets.
To address this bottleneck, the paper introduces DF-3DRME, a data-efficient, two-stage learning framework for high-resolution 3D RM estimation based on super-resolution techniques and hybrid training data. The approach relaxes data requirements by leveraging abundant low-resolution RM samples and only a small fraction of high-resolution labels, substantially reducing data acquisition and simulation overhead.
3D Radio Map Modeling
The 3D RM is defined as a discretized tensor across a volumetric region of interest, with each voxel representing the path loss between a transmitter and a potential receiver site. The environment is described by a binary occupancy map encoding structures (e.g., buildings), and the transmitter position is one-hot encoded within the grid. Such a representation generalizes prior 2D radio map approaches to full 3D, enabling modeling of multi-floor, height-aware propagation relevant for scenarios such as UAV networks and urban air mobility.
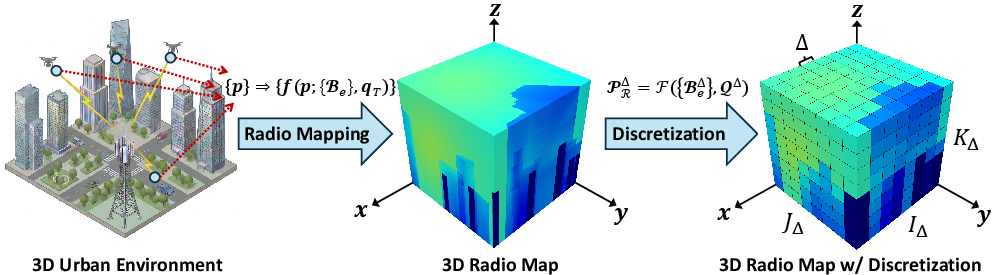
Figure 1: Illustration of a 3D urban environment and the corresponding discretized 3D radio map at grid resolution Δ.
Hybrid Dataset and Data-Efficient Training
The paper proposes a hybrid dataset structure. All environmental instances are available with low-resolution 3D RMs, while only a subset possesses corresponding high-resolution 3D RMs, reflecting practical realities of data availability and cost. The technical challenge is constructing a model that can generalize well to high-resolution 3D RM prediction despite severely limited direct supervision at the target resolution.
DF-3DRME Model Architecture
Stage 1: Low-Resolution RM Estimation (LR-Net)
A compact, three-channel 3D U-Net is trained to predict low-resolution RMs from the EM and transmitter location, efficiently extracting coarse propagation characteristics with strong inductive biases. Inputs are preprocessed via deterministic downscaling and augmented by an explicit line-of-sight (LoS) indicator tensor, computed using a 3D Bresenham traversal algorithm, integrating geometric priors and visibility relationships into the model.
Stage 2: Learned Super-Resolution Refinement (SR-Net)
A specialized 3D super-resolution network (SR-Net) refines the predicted low-resolution RM to target high resolution. SR-Net is implemented with a dual-path encoder, incorporating parallel pathways to process both the (predicted) low-resolution RM and the high-resolution EM, followed by attention-based fusion and a dense feature refinement module using 3D Residual-in-Residual Dense Blocks (RRDBs). Upsampling to the high-resolution domain is performed with 3D voxel shuffle operations rather than conventional trilinear interpolation, enabling the network to learn spatial details adaptively. At each upsampling stage, environmental features are fused back, preserving adherence to the underlying physical structure.
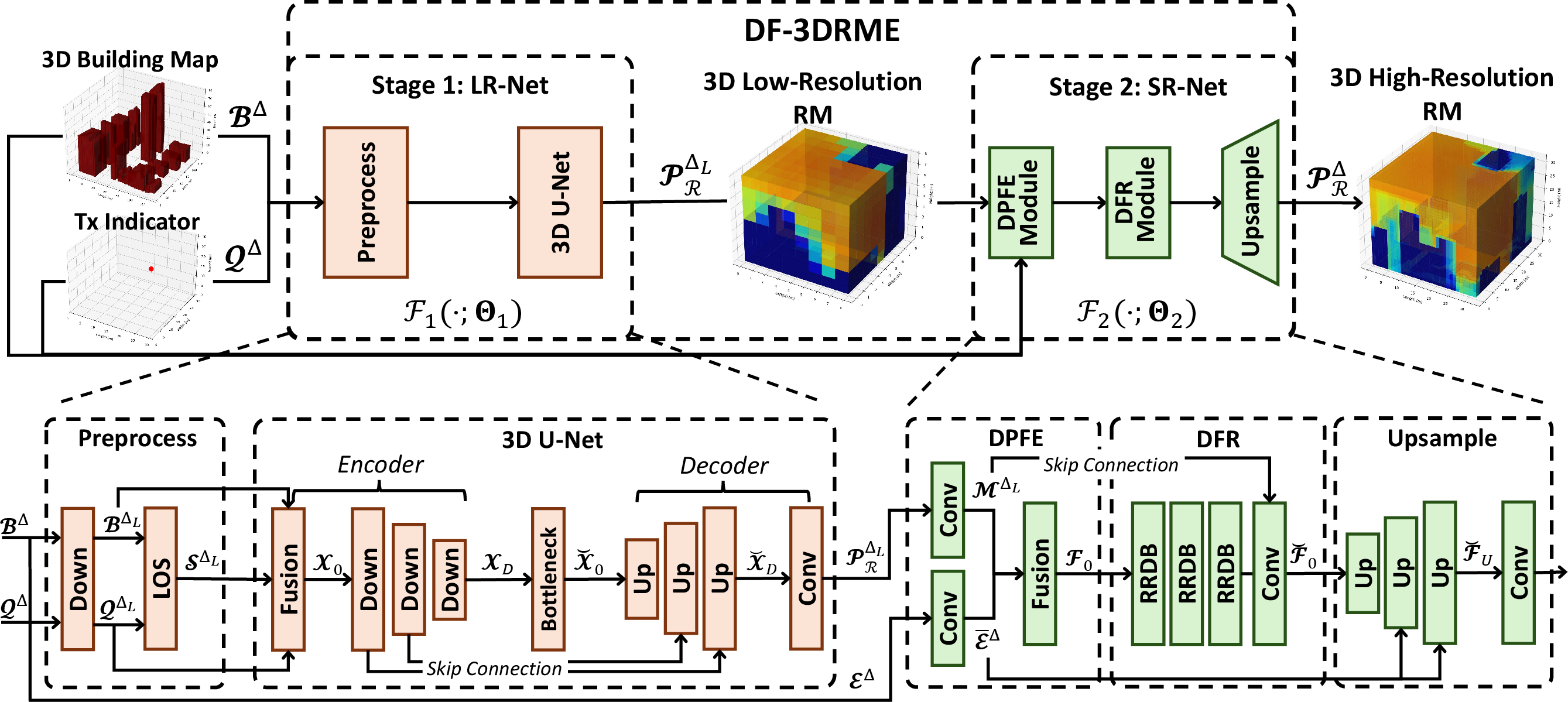
Figure 2: Block diagram of DF-3DRME showing the low-resolution estimation (LR-Net) and super-resolution refinement (SR-Net) stages with respective inputs.
Training Strategy and Loss Functions
A three-phase training protocol is developed:
- Stage 1 Pretraining: LR-Net is trained on the abundant low-resolution dataset.
- Stage 2 Pretraining: SR-Net is trained on high-resolution data using ground truth low-resolution RMs as input.
- Fine-Tuning: SR-Net is further fine-tuned using the outputs from the frozen, pretrained LR-Net as input.
A composite loss is employed: MSE for voxel-wise accuracy, ℓ1 for edge/structure sharpness, and a tailored perceptual loss based on VGG16 feature similarity across altitude-wise slices, to promote both reconstruction fidelity and perceptual quality.
Experimental Results
Quantitative Metrics
On a large-scale 3D RM dataset derived from real-world urban footprints (Berlin, Paris, LA, NY), DF-3DRME achieves state-of-the-art results with as little as 4% of environments having high-resolution RMs:
- NMSE: 0.0131 (significantly lower than trilinear interpolation or single-stage U-Net alternatives)
- SSIM: 0.923 (best perceptual and structural similarity)
- PSNR: 32.31 dB (highest among compared baselines)
These results are achieved while reducing high-res data requirements by over an order of magnitude, validating the sample efficiency of the two-stage, data-friendly approach.
Visual Results
High-resolution RM visualizations illustrate that DF-3DRME preserves fine-grained propagation effects (notably sharp shadow boundaries and LoS/NLoS transitions), outperforming both learned and interpolation-based baselines which produce over-smoothed or structurally inconsistent results.
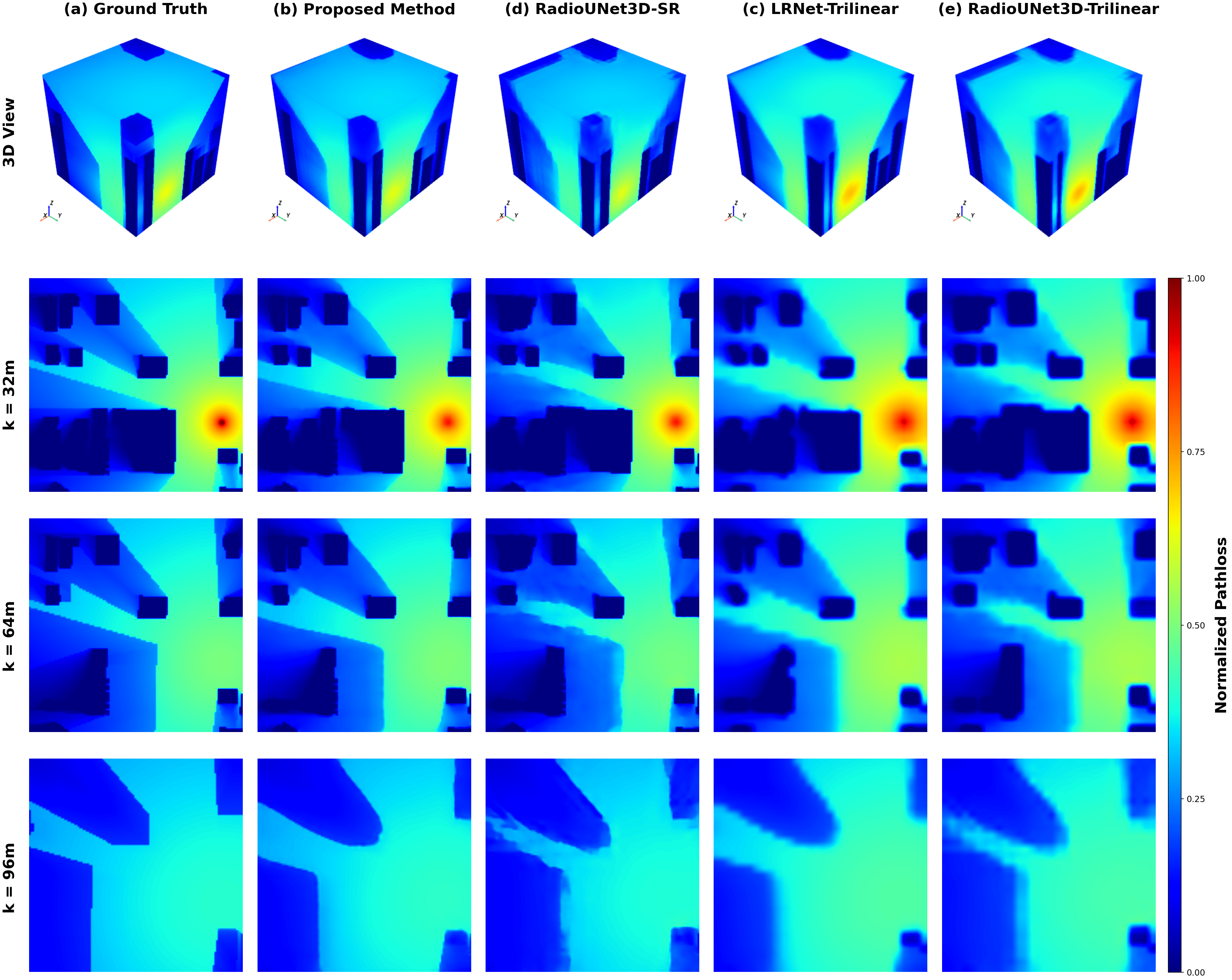
Figure 3: The proposed method yields high-resolution 3D radio maps closely matching ground truth, outperforming learned and trilinear upscaling baselines especially at preserving spatial details and LoS/NLoS boundaries.
Computational Efficiency
Analysis shows that, relative to direct high-resolution single-stage models, DF-3DRME reduces computation, memory, and inference time by approximately 4-fold, with resource requirements comparable to or better than other two-stage learned baselines.
Data Scaling and Ablations
- High-Resolution Data: Near-optimal NMSE is achieved with only 20 high-res environments (3.86% of total), beyond which gains saturate.
- Low-Resolution Grid Size: As low-res grid size increases, performance degrades for all methods, emphasizing the importance of not excessively coarsening low-res RMs for super-resolution.
- Generalization: The method generalizes well to previously unseen environments and transmitter locations.
Implications and Future Work
DF-3DRME significantly advances practical high-resolution 3D RM construction by reducing data costs and supporting measurement-free inference. Its two-stage, modular architecture is compatible with alternative backbones (e.g., vision transformer-based, diffusion-based, or generative models) for further gains, and the hybrid training paradigm is extensible to other spatial prediction tasks with sparse high-fidelity labels.
Potential directions include:
- Substituting backbones with vision transformer or diffusion models for improved sample efficiency.
- Extending to dynamic or time-varying environments.
- Integrating auxiliary data (sparse measurements, channel context, trajectory data) when available for further accuracy improvements.
Conclusion
DF-3DRME presents a rigorously designed, empirically validated, and computationally efficient framework for high-resolution 3D RM estimation in realistic, data-constrained scenarios. It achieves strong numerical and perceptual performance with limited high-resolution data, substantiating its practicality for large-scale deployment in next-generation wireless networks. The modular design and robust training methodology position it as a foundation for continued progress in 3D radio map learning and related environment-aware communication tasks.