- The paper introduces a novel vision-language framework that generates discrete, high-fidelity 3D-LUTs conditioned on text prompts or reference images.
- It employs a two-stage training strategy combining large-scale generative pretraining with RL-based reward alignment to optimize both aesthetic quality and color fidelity.
- Benchmark results demonstrate AceTone’s efficiency, achieving rapid inference (~1s per image) and superior performance in style transfer and instruction-guided grading.
AceTone: A Vision-Language RL Paradigm for Prompt-Driven, Aesthetic-Aligned Color Grading
Introduction
AceTone presents a unified, generative formulation for multimodal conditional image grading, advancing beyond traditional filter-based or patch-wise recoloring pipelines to enable fine-grained, interpretable, and prompt-driven color transformation. The framework produces high-fidelity, discrete 3D-LUTs conditioned on either text prompts or reference images, integrating visual and linguistic context for stylistically coherent and user-intent aligned grading. The method demonstrates robust generalization across style transfer and instruction-guided grading, with significant performance gains over prior state-of-the-art approaches.

Figure 1: AceTone supports both reference-based and instruction-based color grading, accurately capturing subtle tonal characteristics and following user intent for visually coherent adjustments.
Methodology
AceTone operates in two key stages: (1) a pretraining phase using a large-scale dataset for generative next-token LUT modeling conditioned on image, text, and reference input, and (2) post-training with supervised finetuning and RL-based reward alignment to hone aesthetic and perceptual quality.
Discrete LUT Tokenization
A core technical contribution is the vector-quantized variational autoencoder (VQ-VAE) LUT tokenizer. Given continuous 3×323 LUTs, the tokenizer compresses these into 64 discrete tokens (codebook size 256), enabling highly compact and lossless representation of volumetric color mappings. Tokenizer training employs reconstruction and commitment losses, sustaining color fidelity with an average ΔE=1.38, yielding virtually imperceptible color distortion. This discrete representation bridges generative vision-language modeling with LUT-based color operations.

Figure 2: The tokenizer achieves high-fidelity LUT compression—minimal color shift between images graded with original and reconstructed LUTs, as measured by ΔE.
Vision-Language Modeling and Generative Pretraining
On top of the frozen Qwen2.5-VL-3B backbone, AceTone extends the vocabulary with LUT tokens. The model is generatively pretrained to predict LUT token sequences conditioned on images and instructions. This enables the VLM to learn explicit mappings from visual and textual context to semantically meaningful color transformations.
Post-Training: SFT and RL Alignment
After pretraining, supervised finetuning adapts the model to the tasks of photorealistic style transfer (PST) and instruction-guided grading (IGG). The system leverages curated datasets containing paired images, textual instructions, and 3D-LUTs for both tasks.
Crucially, AceTone incorporates reward-driven RL (via group relative policy optimization, GRPO) for post-alignment. Composite reward functions balance color similarity (ΔE to ground truth) and predicted aesthetic quality (from a DeQA-trained assessor). Reward shaping through RL drives the model to outputs that are both visually faithful and aesthetically preferred, directly addressing the limitations of adversarial or purely regression-based objectives.
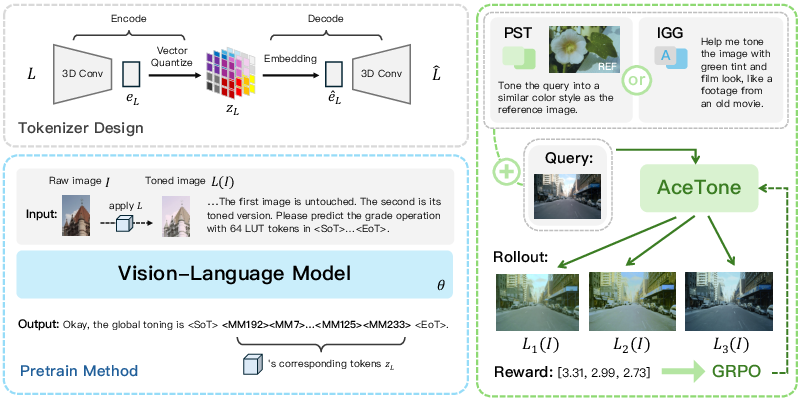
Figure 3: Overview of AceTone framework, including LUT vector quantization, phased VLM training, and GRPO-based RL for reward-driven output alignment.
Dataset and Benchmark Construction
To enable large-scale training and robust evaluation, the authors construct AceTone-800K, a curated dataset integrating:
- Diverse LUT libraries: >10k licensed filters, 34k expert color adjustments, and an 8k LUT fused subset for high coverage and low redundancy.
- Image corpora: From MS-COCO, Adobe-5K, and PPR-10K for style and content diversity.
- Instruction annotation: 800k high-quality, text-guided grading samples, both human and LLM-generated, filtered for directionality and clarity.
Two comprehensive benchmarks, AceTone-BenchTransfer and AceTone-BenchInstruct, are held out for evaluation, supporting ablation and cross-method comparison.
Experimental Results
AceTone sets a new standard across both text-guided and reference-guided color grading tasks.
Quantitative Performance:
On PST-50 and AceTone-Bench[Transfer], AceTone achieves a DeQA aesthetic score of up to 3.57 and LPIPS as low as 0.09, outperforming Neural Preset, ModFlow, and SA-LUT baselines by large margins in both perceptual and color fidelity metrics. In instruction-guided grading, LPIPS is reduced to 0.22 (from 0.31–0.44 for prior works) and AceTone attains the top user and model-assessed ranking.
Efficiency & Deployment:
AceTone matches or exceeds all competitive methods in inference speed (~1s per image), with further acceleration available via optimized VLM decoding.
Qualitative Analysis:
Example outputs confirm AceTone’s capacity to avoid color banding, over-saturation, and hue artifacts, faithfully following a broad array of user instructions and reference styles.

Figure 4: AceTone delivers coherent style transfer and instruction-guided grading, outperforming prior methods in color adaptation and visual appeal.
Tokenizer Compactness:
At only 4M parameters, the tokenizer supports efficient deployment and real-time performance.
Reward and Ablation Studies:
GRPO-based RL is demonstrated as essential for consistently increasing output quality after SFT, with color similarity and aesthetic rewards producing the highest perceptual and aesthetic metrics.
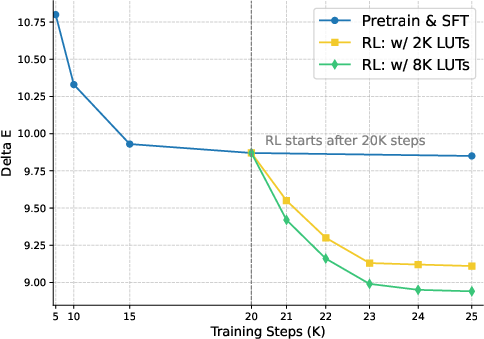
Figure 5: Training performance curve, highlighting quality improvements through phased training and RL.
Implications and Limitations
Practical Impact
AceTone’s discrete LUT formulation and vision-language interface enable several practical advances:
- Prompt-driven post-production: Seamless editing via text or image reference is deployable in professional and consumer workflows.
- Modular integration: LUT outputs can be directly cascaded in standard editing pipelines, supporting non-destructive color transformation for both photo and video.
- Dataset augmentation: Generating stylistically diverse, high-fidelity image variants supports downstream tasks in computational aesthetics and domain adaptation.
Theoretical Considerations
The work establishes the effectiveness of discrete tokenization for dense volumetric transformations, integrating the strengths of generative VLMs and RL reward modeling for controllable, interpretable image synthesis. The LUT+VLM paradigm offers a bridge between symbolic color operations and deep multimodal representations.
Limitations and Future Directions
AceTone exhibits reduced performance under conditions where global LUTs cannot address local, non-linear illumination or texture-variant scenes. The quality of instruction-based grading is limited by the coverage of annotated instructions and the VLM’s inherent perceptual understanding, particularly under ambiguous or culturally-dependent prompts.
Potential research directions include:
- Fine-grained, spatially-adaptive LUTs or transformer-based local color operations
- Enhanced semantic instruction annotation with human-in-the-loop or culturally adaptive understanding
- Extension to video grading with temporal coherence
- Adversarial robustness and generalization across domain shifts in acquisition or display
Conclusion
AceTone delivers an authoritative advance in multimodal, prompt-driven conditional image grading, achieving interpretable, high-fidelity color transformations through a novel LUT tokenization paradigm and reward-aligned vision-language modeling. Its rigorous benchmark evaluations and open-source assets provide a robust foundation for future research in language-driven aesthetic manipulation and computational color science. The work sets the stage for interactive, interpretable, and user-centric AI-driven image editing across creative industries.