- The paper presents a novel benchmark where the Connections game quantifies AI agents’ social reasoning through dynamic wordplay and incremental clue revelation.
- The paper demonstrates that agent performance is shaped by variations in semantic networks and iterative discourse alignment, highlighting key challenges in LLM inference.
- The paper reveals that current AI agents struggle with proactive social exploration, underscoring the need for improved adaptive multi-agent interaction strategies.
Improvisational Wordplay Games for Benchmarking Social Intelligence in AI: The "Connections" Paradigm
Introduction
This paper presents a formal analysis of improvisational wordplay games, focusing on the game "Connections", as a novel and rigorous benchmark for evaluating the social intelligence of AI agents, particularly LLMs. The authors argue that standard LLM evaluation—centered on deductive, factual, or semantic capabilities—neglects the subtlety of reasoning required for collaborative human interactions that rely on theory-of-mind, social awareness, and the adaptive modeling of other agents’ cognitive states. Connections, as formulated here, operationalizes these desiderata by structuring gameplay around incremental revelation, ambiguous clues, and intentional information obfuscation, thereby compelling agents to reason about the semantic and social perspectives of their co-players.
The Connections game is formalized as an n-agent system, involving a Setter (who chooses a target word) and Guessers (who aim to reveal the word through clues and guesses constrained by incremental letter revelation). Each agent maintains its own vocabulary and semantic embedding function Φj, underpinning the premise that semantic proximity and knowledge vary across agents due to experience, background, and learning history.
A critical aspect is that agents find clues whose semantic associations (Φj(w)⋅Φj(p)) are neither too evident (leading to instant setter blocking) nor too opaque (making them inaccessible to co-guessers). This optimization is probabilistically driven: as the number of guessers increases, the optimal semantic closeness for clues becomes less stringent, following p∗=1−(1/n)1/(n−1) for clue success probability.
Additionally, the framework models gradual discourse alignment, whereby agents revise their internal models of co-players’ semantic networks via a gradient ascent/descent learning process on their discourse vectors. This mimics human-like adaptation in social games, yielding a functional approximation for an agent tracking latent cognitive states of others over repeated interactions.
Cognitive and Semantic Dynamics
The epistemic structure of Connections highlights the role of semantic networks in collaborative reasoning tasks. The absence of monotonicity—in which more "powerful" semantic networks do not strictly dominate weaker ones—mirrors human negotiation and communication phenomena, where diverse agents may outperform by leveraging uncommon associations or exploiting personal, domain-specific, or contextually privileged knowledge.
Three principal clue types are delineated:
- Knowledge-based clues target shared factual or domain knowledge, maximizing efficiency when overlap exists.
- Personal clues exploit shared agent experience or idiosyncratic background, a region where current LLMs—absent persistent memory and world experience—are fundamentally limited.
- Associative clues leverage broad co-occurrence, but risk setter blocking in symmetric agent scenarios.
Collectively, these mechanisms probe the agent’s capacity to both anchor and modulate semantic reference frames in the presence of heterogeneous models—a capability minimally addressed in current LLM benchmarks.
Experimental Analysis
Experiments utilize GPT-4o-powered agents, configuring triads of Setter and Guessers across diverse word initializations. The evaluation metrics comprise number of successful letter reveals, frequency of incorrect guesser responses, and setter-blocked clues, benchmarked across multiple challenging target words. As evidenced in the gameplay logs and summary statistics, agents demonstrate clear sensitivity to prefix length distributions (e.g., fewer eligible candidates for "X" than "C"), and their performance is shaped by the growing constraint as more word letters are revealed.
A key empirical finding is the excessive prevalence of Setter-blocked clues, a consequence of using identical or near-identical underlying semantic representations for all agents. This symmetry reduces the effectiveness of associative and knowledge-based clues, as the Setter’s blocking capacity mirrors the Guessers' generative capacities.
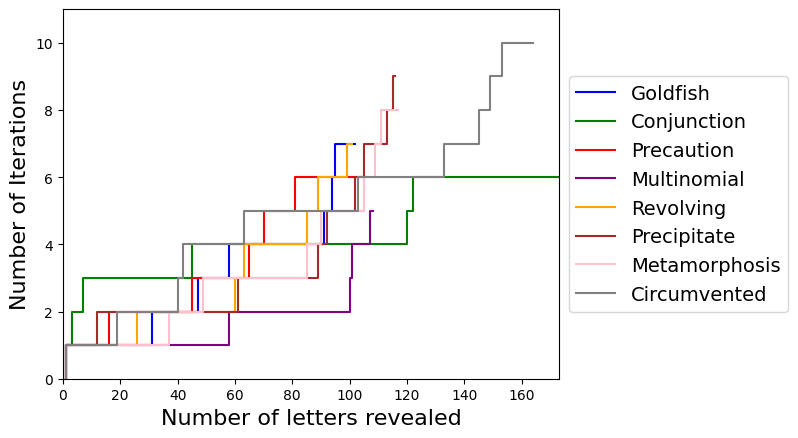
Figure 1: The number of characters revealed per iteration for words requiring prolonged gameplay (over 100 iterations), illustrating the stepwise constraints imposed and the difficulty of word revelation in complex cases.
The figure further indicates that, contrary to human intuition, LLM Guessers can perform many iterations with the word space still highly ambiguous, occasionally making improbable guesses even when the letter space is saturated—an artifact of limitations in LLM generative heuristics and their sampling strategies.
Social Awareness, Priming, and In-Context Adaptation
Priming experiments reveal that explicit in-context manipulation—modifying an agent’s prompts to simulate different cultural backgrounds, professions, or experiences—instantiates divergence in the effective semantic networks of each agent. This yields more realistic, asymmetric gameplay, as agents selectively generate clues in their area of domain expertise or shared context.
However, LLMs show limitations compared to human players. While human agents fluidly explore the semantic overlap with co-players (often implicitly and adaptively), LLM-based Guessers fail to proactively probe or infer the latent semantic idiosyncrasies of other agents unless explicitly instructed. This exposes a deficiency in autonomous social-exploratory behavior, constraining the degree to which these AI agents can exhibit genuine interactive intelligence or achieve epistemic alignment.
Theoretical and Practical Implications
The formalization and empirical study of Connections as an AI benchmark underscore several important implications:
- Theoretical: By isolating tasks that fundamentally require adaptive modeling of other agents’ semantic and cognitive states, Connections provides a testbed for evaluating theory-of-mind and social-cognitive reasoning—a domain where deductive or database-driven reasoning is structurally insufficient.
- Practical: Improvements in LLMs oriented toward this game (e.g., via differentiated fine-tuning, explicit discourse modeling, or meta-learning approaches) translate directly to enhanced performance in multi-agent collaboration, negotiation, and instruction-following in open-ended contexts.
Furthermore, extension to open-word variants (non-fixed setter words) remains an unresolved challenge for current LLMs, as maintaining consistent game state over extended interactions, improvisational adaptation, and memory over arbitrary turns are bottlenecks for deployed AI agents.
Future Directions
The authors outline several extensions, notably games wherein the Setter can improvise and adapt word selection mid-game—demanding models with robust long-context tracking, implicit world-modeling, and dynamic social reasoning. The ability to align or differentiate discourse vectors without explicit priming or architectural constraints (i.e., through interaction alone) is highlighted as a critical open research problem. Success in such benchmarks would mark significant progress toward social and adaptive general intelligence in AI.
Conclusion
This work establishes improvisational games such as Connections as a robust, technically rigorous benchmark for evaluating social intelligence in AI agents. Beyond evaluating isolated semantic and deductive skills, Connections operationalizes the necessity for theory-of-mind, shared knowledge discovery, and adaptive inference of other agents’ cognitive states. The findings elucidate both the current capabilities and critical deficiencies of LLM agents under these constraints, motivating substantial methodological and theoretical development in multi-agent adaptive AI.