- The paper introduces TPC-CMA, a three-phase curriculum that bridges both centroid and distribution gaps in vision-language models to enhance generative capability.
- Empirical analysis shows that addressing the Distribution Gap is a near-perfect predictor of improved zero-shot captioning and joint clustering performance.
- The study reveals a trade-off between alignment and feature expressiveness, enabling controlled adaptation for diverse cross-modal applications.
The Geometry of Compromise: Unlocking Generative Capabilities via Controllable Modality Alignment
Introduction
This paper addresses a foundational limitation in vision-LLMs (VLMs) such as CLIP: the modality gap, a persistent geometric separation between image and text representations in the joint embedding space. While prior work predominantly focuses on global centroid alignment via various post-processing or fine-tuning strategies, the authors argue that such approaches yield only superficial improvements. Through formal decomposition and extensive empirical analysis, they demonstrate that cross-modal interchangeability—central to generative and joint-structural tasks—relies critically on not only correcting centroid offsets but also bridging deeper distributional discrepancies. They introduce TPC-CMA (Three-Phase Curriculum for Cross-Modal Alignment), which explicitly targets both the Centroid Gap and Distribution Gap and leverages a gradient-aware curriculum to stably optimize the balance between alignment and discriminative capacity.
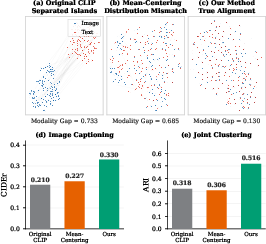
Figure 1: The t-SNE visualization of multimodal features before and after alignment; only TPC-CMA (αtarget=0.5) achieves semantic interleaving required for generative tasks.
A central contribution of the paper is the identification and corroboration of two geometrically distinct sources of the modality gap:
- Centroid Gap (GC): Euclidean distance between the mean vectors of each modality.
- Distribution Gap (GD): The structural discrepancy remaining after aligning the centroids, corresponding to differences in the underlying distributions’ geometry.
Empirical analysis reveals that existing methods such as Mean-Centering effectively eliminate the Centroid Gap (97% reduction), but Distribution Gap remains unchanged and coincides with unimproved downstream performance (e.g., ROUGE-L for captioning). This finding is codified via a quantitative analysis: Distribution Gap is a near-perfect linear predictor for generative cross-modal task quality (e.g., COCO CIDEr, R2=0.986), whereas the traditional “Raw Gap” metric is misleading (R2=0.691).
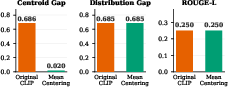
Figure 2: Mean-Centering reduces only the Centroid Gap; the Distribution Gap and task performance (ROUGE-L) remain unchanged.
TPC-CMA: A Principled Alignment Framework
To directly address both forms of the gap, TPC-CMA introduces two synergistic mechanisms combined via a controllable parameter α:
- Negative Reweighting: Diminishes the repulsive force on negative cross-modal pairs, allowing centroids to move closer.
- Intra-modal Geometry Matching: Forces each image (text) embedding to adopt the relative position within the feature space that matches its paired text (image) embedding, thereby reducing the Distribution Gap.
The composite Cross-Modal Alignment (CMA) loss interpolates between the standard CLIP contrastive loss and full intra-modal geometry alignment as α increases, enabling a smooth transition along the alignment-expressiveness spectrum.
Recognizing the instability of abrupt objective switching, TPC-CMA employs a three-phase, gradient-aware curriculum: (1) standard CLIP anchoring, (2) adaptive ramp-up using internal loss dynamics to regulate α, and (3) stabilization at the target alignment strength.
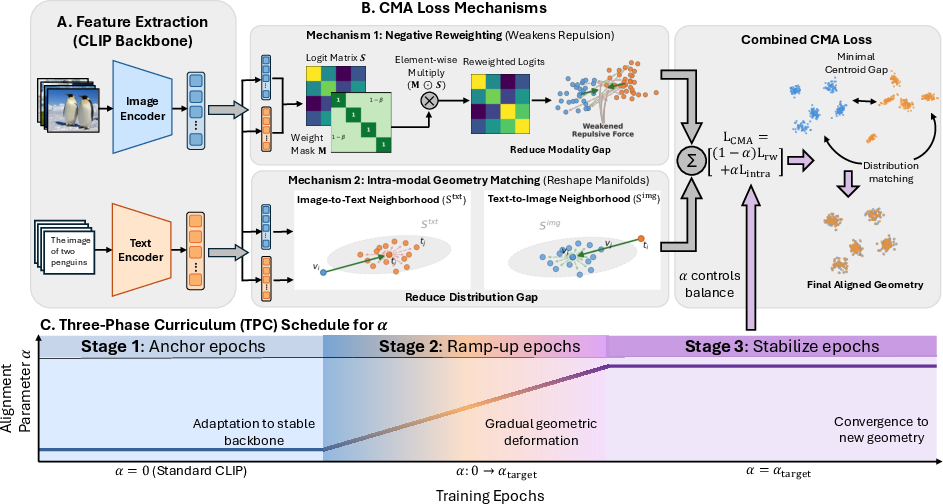
Figure 3: Overview of TPC-CMA, including embedding extraction, composite loss, and three-phase curriculum with gradient monitoring.
Empirical Results and Pareto Frontier Analysis
TPC-CMA is comprehensively benchmarked on discriminative (classification, retrieval), generative (captioning), and structural (joint clustering) tasks across standard datasets (CC3M, COCO, ImageNet, CIFAR-100, Food-101, etc.). The protocol consistently establishes a Pareto frontier dominating all prior baselines by enabling continuous control over the trade-off between cross-modal alignment strength and discriminative performance.
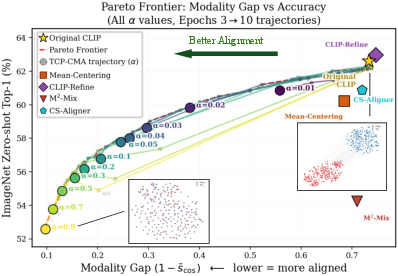
Figure 4: Pareto frontier analysis shows TPC-CMA envelops all prior baselines in the gap-accuracy plane.
At strong alignment (αtarget=0.5):
- Gap reduced by 82.3% (0.733 → 0.130).
- ARI for joint clustering improves from 0.318 to 0.516.
- Zero-shot captioning (CIDEr) increases by 57.1% over original CLIP.
At mild alignment (GC0) the accuracy drop remains minimal (4.8%), suggesting that TPC-CMA preserves or improves discriminative performance in the low-alignment regime while unlocking generative and clustering capabilities as the distribution gap closes.
Distribution Gap as the True Predictor of Cross-Modal Interchangeability
Empirical results reinforce that the Distribution Gap, not Raw Gap or Centroid Gap, is the key determinant of performance on generative and clustering tasks. As illustrated, CIDEr for DeCap zero-shot captioning tracks the Distribution Gap almost perfectly across all protocol variants.
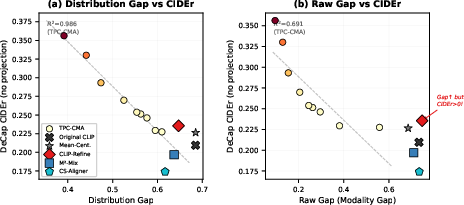
Figure 5: Distribution Gap is a near-perfect predictor of CIDEr; Raw Gap fails to capture this relationship.
Spectral Analysis: Limitations and the Alignment-Expressiveness Trade-off
The authors identify an intrinsic tension between maximal cross-modal alignment and feature expressiveness. At large GC1, the effective rank of the feature space collapses, compressing the representation and diminishing discriminative utility. The cross-modal Fusion Index quantifies the overlap between modality-specific subspaces, peaking at moderate GC2 and declining as aggressive alignment reduces complementarity. This spectral analysis explains the necessity of controllable, rather than fixed, alignment: different downstream use cases require distinct operating points.
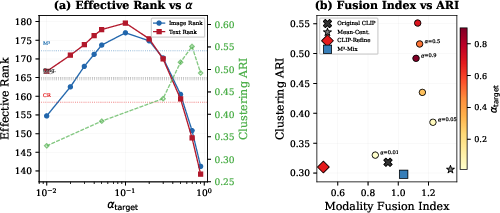
Figure 6: Effective feature space rank dynamics and Fusion Index trade-off as a function of alignment strength.
Comparative and Ablative Analysis
TPC-CMA is compared against leading methods: Mean-Centering, AlignCLIP, MGC3-Mix, CLIP-Refine, and CS-Aligner. None simultaneously reduce both gap components or allow for controllable adjustment. Component ablations confirm the indispensability of both Negative Reweighting and Intra-modal Geometry Matching, as well as the necessity of the curriculum for stable, high-quality adaptation. Notably, constant or abrupt alignment (no curriculum) leads to catastrophic loss of discriminative content even if raw gaps are minimized.
Implications and Future Directions
The strong empirical evidence for the Distribution Gap hypothesis reframes the understanding of modality gaps and alignment in VLMs. Practically, TPC-CMA enables a single fine-tuned model to address the full spectrum of cross-modal applications, from zero-shot classification to captioning and joint clustering, with user-controlled trade-offs.
Theoretically, the analysis motivates future inquiry into alignment protocols that avoid rank collapse, perhaps through explicit rank or diversity-preserving objectives, and automated selection of GC4 tailored to task requirements. The decompositional approach and curriculum design are modality-agnostic, suggesting seamless scalability to audio-text, video-text, and other multimodal foundations.
Conclusion
This work provides compelling geometric and empirical evidence that true cross-modal compatibility in VLMs requires distributional as well as centroid-level alignment. TPC-CMA delivers a rigorous, generalizable, and practically effective protocol for fine-tuning large contrastive pre-trained models to bridge this gap. By exposing and controlling the fundamental alignment–expressiveness trade-off, the framework not only clarifies the nature of the modality gap but also sets the stage for future advances in generative, structural, and discriminative cross-modal learning.