- The paper presents a lightweight ColBERT extension that integrates token-level relevance attribution to match LLM-extracted evidence spans.
- It employs a joint training objective combining binary cross-entropy for tokens and KL divergence for document-level signals, enhancing retrieval precision.
- The model achieves a token-level F1 of 64.5 with minimal latency overhead (≈1.12x) while maintaining strong document recall at approximately 97.1%.
Introduction
The task of identifying relevant documents in response to a query—core to information retrieval (IR)—has undergone major advances with the advent of multi-vector dense retrievers such as ColBERT, which leverage efficient bi-encoder architectures. However, for applications that demand explainability or direct evidence, traditional retrieval granularity is insufficient; users and downstream systems often require fine-grained evidence spans (e.g., specific sentences or phrases) that directly answer or support the query. Recent approaches have offloaded this function to LLMs via post-retrieval reranking or span annotation, incurring prohibitive latency and computational cost.
"FGR-ColBERT: Identifying Fine-Grained Relevance Tokens During Retrieval" (2604.00242) introduces FGR-ColBERT, a minimal extension to ColBERT that enables fine-grained, token-level relevance estimation directly within the retrieval process, sidestepping the need for separate heavyweight LLM calls. The model achieves high agreement with human and LLM-provided span annotations, matching the span plausibility of Gemma~2 (27B) at a ~245x smaller parameter count, while incurring negligible impact on retrieval latency (≈1.12x overhead) and recall.
Approach: Integrating Fine-Grained Supervision into ColBERT
FGR-ColBERT modifies the late interaction mechanism of ColBERT. Instead of limiting the aggregation to document-level relevance, the model computes per-token relevance probabilities aligned with span-level cues. Explicitly, both query and document tokens are transformed via a lightweight feed-forward network with residual connections. ColBERT's aggregation is used orthogonally: each document token receives a maximum similarity score with any query token, passed through a sigmoid to yield a token-level relevance probability. This vector serves as a direct implementation of the selection function for evidence span tagging.
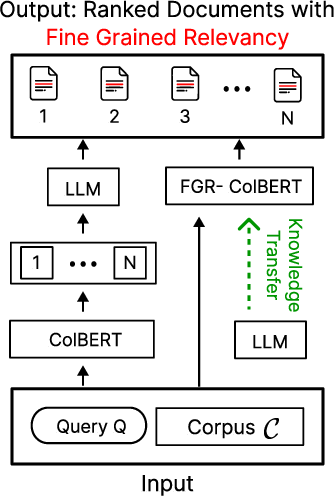
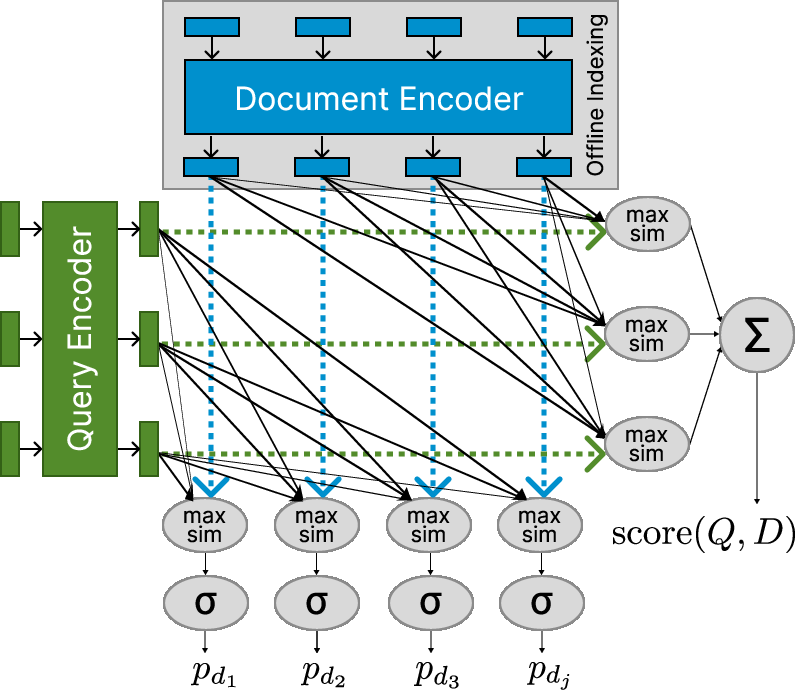
Figure 1: (a) Traditional ColBERT with post-hoc LLM extraction versus FGR-ColBERT's integrated relevance supervision. (b) Late interaction modified for token-level scoring without sacrificing document-level precision.
Training is conducted with a joint objective: document-level distillation loss (KL divergence to a cross-encoder re-ranker) is combined with a binary cross-entropy loss on token-level signals distilled from LLM-labeled evidence spans. Supervision for token-level relevance is applied exclusively to positive (plausible match) instances, intentionally biasing the model towards always producing at least one evidence span per passage.
Dataset Construction via LLM Distillation
Fine-grained annotation at scale is prohibitively expensive if conducted manually. The authors leverage Gemma~2, a 27B LLM with strong alignment to human span annotation, to construct MS-MARCO-Gemma datasets for both training and development. For deeper validation, a smaller set with triple human annotation is compiled from MS MARCO’s dev split.
LLM outputs are supplied as token-level supervision, providing the "ground truth" for the binary cross-entropy span identification head. This design enables effective transfer of LLM capabilities to a much smaller and retriever-aligned model, without the inefficiency of querying the LLM at retrieval time.
Results: Efficiency, Effectiveness, and Relevance Plausibility
Quantitative evaluation demonstrates three main findings:
Qualitative analysis confirms that high token-level scores are assigned to truly relevant evidence phrases, with spurious or irrelevant text receiving appropriately low scores. These fine-grained cues are useful for explanation, post-hoc answer extraction, and explainable AI systems.
Implications and Future Directions
FGR-ColBERT bridges the gap between fast multi-vector retrieval and evidence-oriented inference, directly exposing token-level explanations as a byproduct of retrieval. The approach demonstrates that model distillation from LLMs for fine-grained supervision can be accomplished in lightweight architectures (~110M parameters), making advanced IR systems more deployable in latency-critical or resource-constrained settings.
Potential avenues for future work include:
- Robustness Evaluation: Testing transfer and generalization on heterogeneous benchmarks such as BEIR, to assess the broad applicability of LLM-distilled fine-grained signals.
- Long-context Retrieval: Extending to long-document settings (e.g., with LongEmbed-like architectures) where span identification is more challenging and beneficial.
- Interactive and Explainable QA: Leveraging token-level relevance for answer highlighting, rationale generation, or verdict justification in human-facing applications.
Conclusion
FGR-ColBERT demonstrates that fine-grained, token-level relevance attribution can be achieved efficiently within dense retrieval architectures by distilling LLM supervision, maintaining retrieval effectiveness and incurring low computational overhead. This methodology paves the way for fast, explainable retrieval systems that no longer require expensive post-hoc LLM inference for evidence span identification, and charts a promising trajectory for future work on robust, explainable, and scalable IR.
