- The paper introduces QUEST, a novel attention mechanism that alleviates instability by ℓ2-normalizing keys while leaving query norms unconstrained.
- QUEST achieves superior performance and robustness across diverse benchmarks including vision transformers, time-series, graph transformers, and language models.
- Empirical results and theoretical insights demonstrate that QUEST mitigates entropy collapse and enhances model interpretability through balanced attention distributions.
Introduction and Motivation
Transformer architectures ubiquitously deploy the scaled dot-product attention (SDPA) mechanism, which combines query, key, and value matrices with a scaling and softmax for modeling dependencies. However, training instabilities persist, especially entropy collapse triggered by unbounded increases in the norms of the query and key vectors, causing attention logits to explode. This phenomenon often leads to degenerate solutions, particularly when models overfit spurious signals present in training data. Mitigation strategies in prior works—such as QK-normalization (QKNorm) of both queries and keys—ameliorate instability but reduce expressivity, as all tokens share the same attention sharpness.
The paper introduces QUERY-modulated Spherical aTtention (QUEST), a formulation in which keys are ℓ2-normalized and queries remain unnormalized; this constrains the latent space for attention computations to a hypersphere, allowing queries to modulate the sharpness of the attention distribution independently. Consequently, QUEST preserves stability, expressivity, and robustness, and serves as a trivial drop-in replacement for standard attention in various domains.
Analysis of Standard Attention and Its Limitations
The main analysis decomposes attention logits as functions of query norm, key norm, and query-key directional similarity. The arbitrary growth of query and key norms drives concentration of attention onto few tokens, typically those corresponding to spurious correlations. This leads to insufficient supervision for non-dominant tokens (contributing little to parameter updates) and cross-amplification between queries and keys, ultimately causing entropy collapse and training divergence. A toy task demonstrates that standard and QNorm attention mechanisms fail reliably in the presence of spurious biased signals, with cross-norm interactions driving the model toward suboptimality.
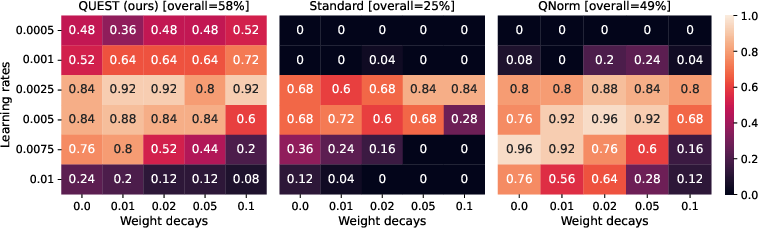
Figure 1: Success rates for different attention mechanisms on the toy example; QUEST demonstrates superior robustness and solution fidelity over standard and QKNorm attention.
The QUEST Attention Mechanism
QUEST attention operates as follows:
- Keys are ℓ2-normalized, constraining them onto a hypersphere.
- No scaling factor is employed (C=1).
- Query norms are unconstrained and hence fully control the sharpness/entropy of the attention.
- The ranking of token importance is thus determined solely by the cosine similarity between unnormalized queries and normalized keys.
- Unlike QKNorm or QNorm, each token independently controls the sharpness of its attention window.
This configuration removes the cross-amplifying feedback between query and key update gradients (see the theoretical gradient analysis in the appendix), eliminating a known source of attention entropy collapse.
Empirical Validation Across Domains
Vision: Classification and Robustness
The authors test QUEST in ViT architectures (Tiny, Small, Base, Large, Huge, and up to 2.4B parameters) with both DeiT and DeiT-3 recipes. Instabilities in standard attention result in frequent divergence for larger ViTs, whereas QUEST consistently converges and outperforms QKNorm, both in Top-1/Top-5 accuracy and in mean corruption error (MCE) on robustness benchmarks (ImageNet-C, IN-A, IN-v2, IN-ReaL).
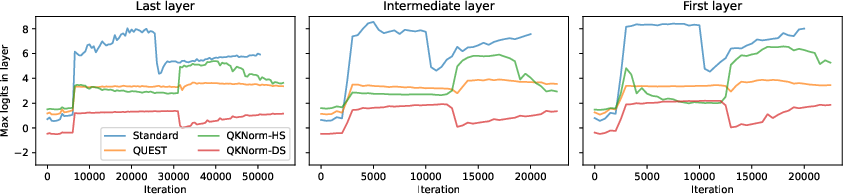
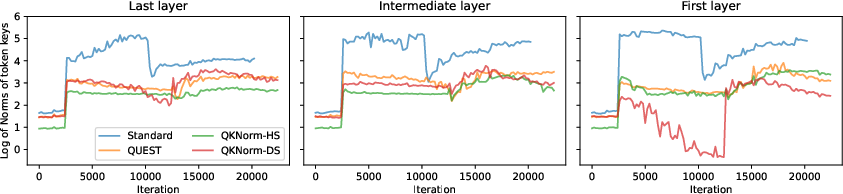
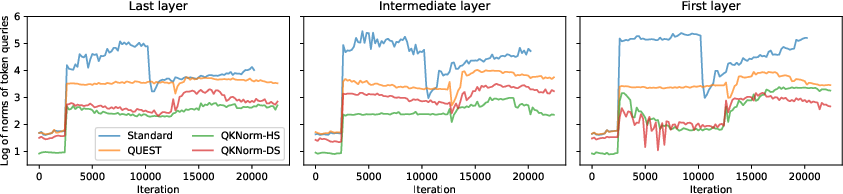
Figure 3: QUEST attention stabilizes the progression of maximal logits and query norms across all layers during training.
Furthermore, adversarial attack evaluations (FGSM, PGD, SPSA, Auto attacks) demonstrate that QUEST yields systematically higher accuracy and lower NLL on perturbed data compared to standard attention and to elliptical attention; QUEST can also be integrated with elliptical metrics to further improve robustness without degrading clean accuracy.
Explainability and Attention Distribution
Class activation mapping (AG-CAM) applied to models trained with QUEST produces attention maps that cover object instances more homogeneously, as opposed to standard attention that concentrates on a few salient parts—enhancing both interpretability and robustness.
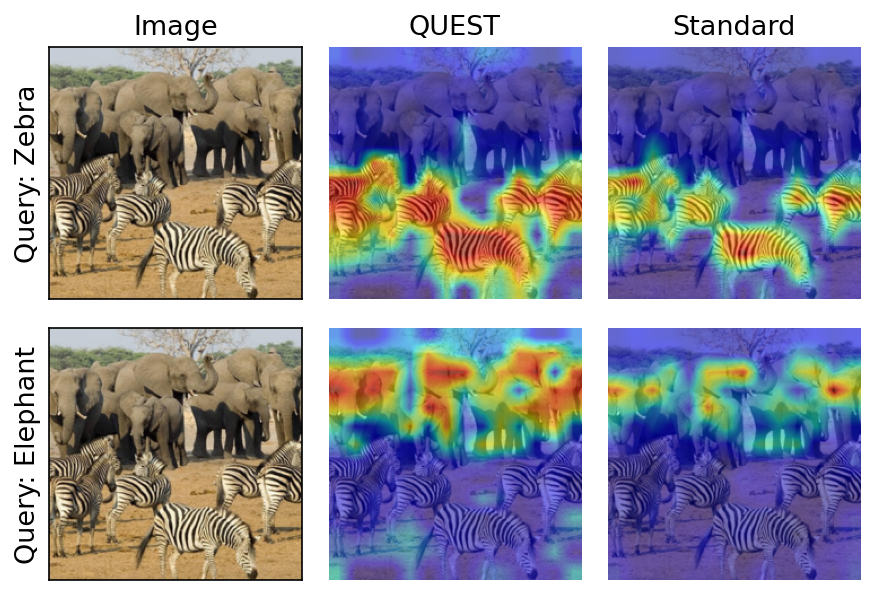
Figure 4: QUEST demonstrates improved multi-object coverage in class activation maps compared to standard attention.
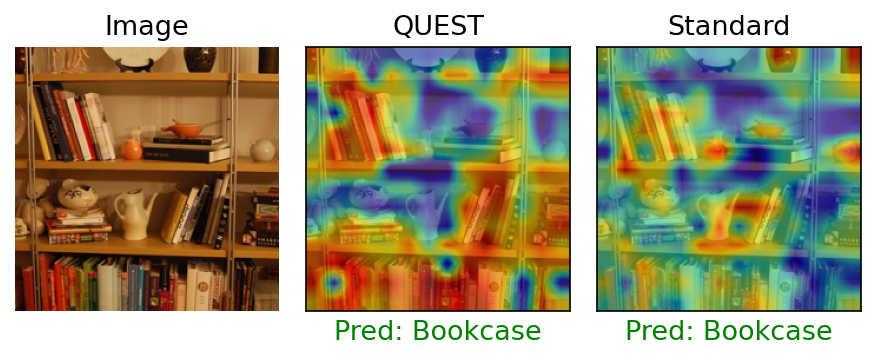


Figure 6: QUEST attention highlights all object instances of the "Bookcase" class, outperforming standard attention.
Other Modalities: Time-Series, Graphs, Language
- Time-Series: On the UEA classification suite, QUEST often achieves higher or equal accuracy to standard attention and QKNorm, with an average performance exceeding strong baselines such as Crossformer.
- Graphs: QUEST produces significant gains on long-range dependency benchmarks in graph transformers, improving AP, F1, and MRR without loss on standard tasks.
- Language Modeling: On WikiText-103 benchmarks, QUEST-attended models have marginally improved perplexity and robustness to word corruption (Word Swap Attack) compared to both standard and QKNorm attention.
- Pointcloud Segmentation: QUEST shows higher mIoU across standard tasks compared to previous attention variants.
Theoretical Insights
The paper rigorously analyzes reverse attention gradients and the mechanisms by which unbounded query and key norms synthesize positive feedback, leading to instability. By ℓ2-normalizing only the keys, QUEST ensures that the gradient contributions to both queries and keys remain decorrelated in norm, allowing the model to leverage the full expressivity of independent sharpness but without the risk of runaway logit growth.
Implementation
QUEST requires only a trivial modification to the attention mechanism: ℓ2-normalize the keys before the dot-product, then proceed as usual. This makes QUEST readily applicable as a drop-in replacement to standard attention layers.
Implications and Future Directions
QUEST advances stable and robust training of transformers—especially large ViTs and long-horizon models—while remaining compatible with orthogonal architectural or optimization improvements. By tightly coupling norm constraints with expressivity, QUEST opens directions in geometric latent space design, and naturally invites further exploration (e.g., Riemannian optimizers on the unit sphere, integration with non-Euclidean metrics).
QUEST's effect on attention distributions increases coverage and balance across relevant input tokens, thereby enhancing not only robustness to data shifts/adversarial corruption but also the reliability of model explanations, as evidenced by improved CAMs. The findings motivate the further study of hyperspherical and hybrid metric spaces in next-generation attention layers.
Conclusion
The paper delivers a well-grounded, empirically evidenced, and theoretically sound attention alternative—QUEST—that mitigates training instability in transformers without losing attention expressivity or scaling behavior. It demonstrates broad domain applicability and readily integrates into both discriminative and robust training regimes, even improving state-of-the-art robust attention designs. Future work may explore more elaborate geometric and metric-based attention spaces, as well as extend these insights to other softmax-free or linear attention approaches.

