- The paper introduces Think-Anywhere, a novel protocol that interleaves dynamic reasoning blocks within code synthesis for enhanced adaptability.
- It employs a two-stage training protocol combining supervised fine-tuning and RLVR, achieving state-of-the-art performance on multiple code benchmarks.
- Empirical results demonstrate improved code correctness, efficiency, and cross-domain generalization by injecting reasoning at critical decision points.
Think Anywhere in Code Generation: An Expert Synthesis
Motivation and Context
The integration of explicit reasoning stages—such as Chain-of-Thought (CoT) prompting—has driven notable improvements in code generation with LLMs. However, these approaches rely heavily on "upfront thinking," wherein all reasoning occurs prior to code synthesis. This design is misaligned with real software development, where complexity and the need for additional reasoning emerge intermittently throughout code implementation. Furthermore, upfront thinking fails to dynamically allocate computational resources, resulting in inefficient or insufficient reasoning. Addressing these limitations, this paper introduces Think-Anywhere—a novel and flexible reasoning protocol allowing LLMs to invoke in situ reasoning blocks at arbitrary token positions during code output, thereby making deliberation on-demand and task-adaptive.
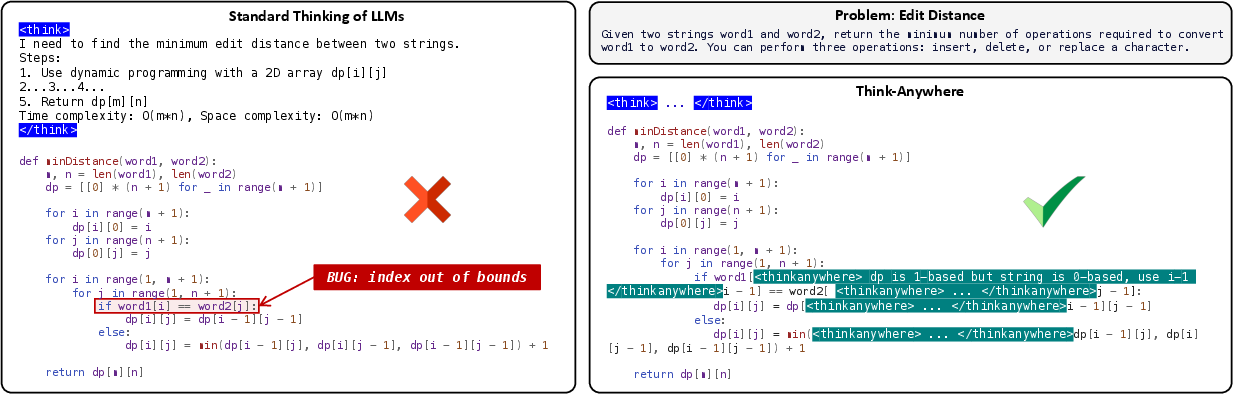
Figure 1: Think-Anywhere permits the model to insert reasoning blocks at any stage during code synthesis, illustrated by interleaving <thinkanywhere> sections with executable code.
Methodology
Unlike CoT and other upfront reasoning paradigms, Think-Anywhere dynamically alternates between code and inline reasoning blocks (enclosed in <thinkanywhere>...</thinkanywhere> tags). The final code is rendered by stripping all reasoning blocks, preserving validity.
Training Protocol
Two-stage training underpins Think-Anywhere:
- Cold-start Supervised Fine-Tuning: Using data synthesized with strong reasoning LLMs, code samples are constructed where reasoning blocks are positioned wherever intermediate deliberation is expected. The model learns to generate code interspersed with
<thinkanywhere> content via a structured training template.
- Reinforcement Learning from Verifiable Rewards (RLVR): RLVR using Group Relative Policy Optimization (GRPO) enables the model to autonomously discover optimal, context-dependent reasoning stop-points. The hierarchical reward comprises code correctness (via test case execution) and structural adherence (proper ordering and placement of reasoning blocks).
A notable variant, Think-Anywhere*, encodes control triggers as dedicated tokens with semantically initialized embeddings, mitigating semantic ambiguity.
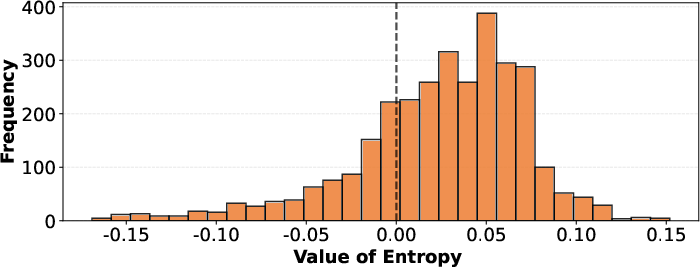
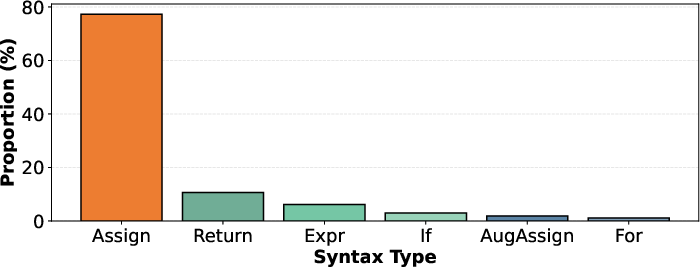
Figure 2: Token entropy increases at positions selected for internal reasoning, highlighting the model’s awareness of complexity spikes.
Empirical Evaluation
Benchmarks and Metrics
Experiments target four code-generation benchmarks: LeetCode, LiveCodeBench, HumanEval, and MBPP, using pass@1 and pass@k as principal metrics. All experiments leverage greedy decoding.
Comparative Results
Think-Anywhere establishes a new state-of-the-art across all benchmarks, outperforming both RL-based post-training methods and alternative, reasoning-focused techniques. Substantial improvements are observed not only over standard baselines but also over advanced RL protocols like GRPO.
Notably, RLVR is essential: ablation studies confirm that supervised fine-tuning alone is insufficient, and that adaptive, RL-driven discovery of reasoning injection points is critical for effective performance.
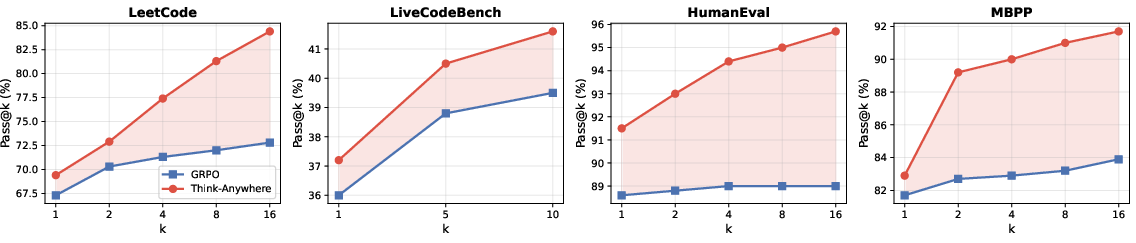
Figure 3: Think-Anywhere delivers higher pass@k rates than GRPO as solution samples per task increase across benchmarks, indicating greater upper-bound capability.
Analysis
- Entropy Localization: Reasoning blocks are invoked precisely at code positions with elevated predictive entropy, correlating with genuine increases in local decision complexity.
- Syntactic Preferences: The model injects reasoning disproportionately in assignments and return statements, matching critical semantic junctures in program logic.
- Efficiency: Despite inserting additional control tokens, Think-Anywhere solutions are more concise overall, as the upfront planning is reduced and excessive, redundant deliberation is avoided.
- Cross-domain Transfer: Trained exclusively on code generation, Think-Anywhere demonstrates substantial gains in unrelated mathematical reasoning tasks, evidencing generalization of the underlying think-on-demand mechanism.
- Model Agnosticism: The approach scales and generalizes effectively across LLM families (Qwen, Llama3, various parameterizations), with especially strong gains in smaller models.
Theoretical, Practical, and Future Implications
Think-Anywhere signals a paradigm shift in how LLM-based code generation—and potentially, other sequential reasoning tasks—can be architected. Theoretical implications are manifold: the learnable allocation of "where to think" aligns with information-theoretic principles, suggesting links to adaptive computation and variable-depth inference protocols. Practically, methods like Think-Anywhere offer interpretability, as explicit reasoning blocks serve as natural loci for inspection, diagnosis, and perhaps future interactive debugging. The framework is extensible to other domains where ill-posed subproblems emerge non-uniformly during generation (e.g., mathematical proof, data-to-text).
Challenges remain in further optimizing when to suppress unnecessary deliberation and how to refine RL objectives for even more targeted and efficient reasoning. Synergies with program analysis and static code evaluation are additional promising directions.
Conclusion
Think-Anywhere establishes a principled and effective protocol for on-demand, token-level interleaved reasoning in generative code LLMs. By leveraging a composite of supervised and RL-driven learning, this approach both improves code correctness and offers an interpretable record of model deliberation. Its strong empirical results, cross-domain generalization, and alignment with real-world cognitive workflows set a new agenda for adaptable, efficient reasoning in LLMs and beyond.