- The paper introduces ViTAS, a multi-stage pipeline that selectively uses high-importance visual regions to improve radiology report summarization, achieving a 25.22% BLEU-4 gain over text-only baselines.
- The paper employs an ensemble-guided segmentation and dual Swin Transformer V2 models with bidirectional cross-attention to fuse complementary frontal and lateral chest X-ray features.
- The paper's approach enhances factual alignment and clinical interpretability while reducing noise by filtering irrelevant visual data, setting a new state-of-the-art on the MIMIC-CXR benchmark.
Selective Visual Attention for Multimodal Radiology Summarization: An Expert Analysis of ViTAS
Introduction
The paper "Less Is More? Selective Visual Attention to High-Importance Regions for Multimodal Radiology Summarization" (2603.29901) investigates the efficacy of selective visual input for automated radiology report summarization, challenging prevailing assumptions in multimodal medical NLP: that maximal visual input yields optimal performance, and that multimodal models provide minimal improvement over strong text-only baselines for transforming FINDINGS into IMPRESSIONS. The authors introduce ViTAS, a multi-stage pipeline leveraging ensemble-guided MedSAM2 lung segmentation, dual Swin Transformer V2 processing with bidirectional cross-attention, Shapley-guided patch clustering, and hierarchical tokenization. ViTAS establishes new SOTA on the MIMIC-CXR benchmark, improving numeric accuracy, factual alignment, and expert-rated metrics by focusing exclusively on highly informative pathology-driven visual regions.
Pipeline Architecture and Methodological Advancements
ViTAS expresses a paradigm shift in multimodal medical summarization by systematically filtering irrelevant anatomical regions and optimizing information flow from radiograph to impression.
Chest X-rays, from both frontal (AP/PA) and lateral (L/LL) views, are segmented via a robust ensemble bounding-box MedSAM2 protocol, ensuring pulmonary anatomy localization independent of patient positioning or imaging device variability. Each view is processed separately, with the union of multiple shifted bounding boxes refining volumetric coverage (Figure 1).
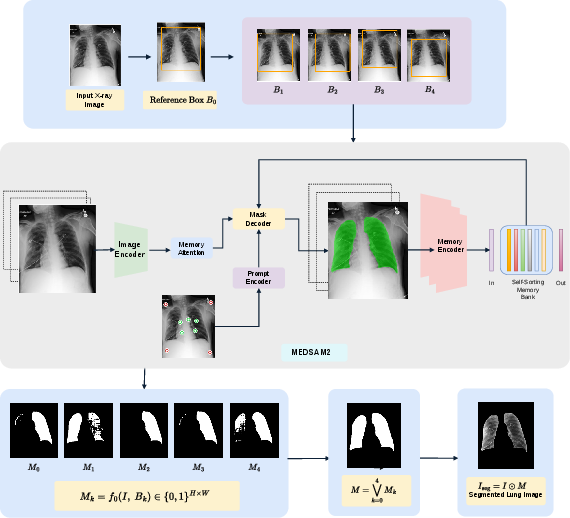
Figure 1: Ensemble-guided MedSAM2 lung segmentation isolates pulmonary regions via robust box unions, discarding non-lung context.
Dual Swin Transformer V2 backbones encode each view, exchanging spatial features through mid-level bidirectional cross-attention. This architecture exploits complementary diagnostic cues inherent in lateral projections—critical for pathologies like consolidation, edema, and pleural effusion (Table: AUROC gains for lateral views)—and manages missing view scenarios using learnable mask tokens (Figure 2).
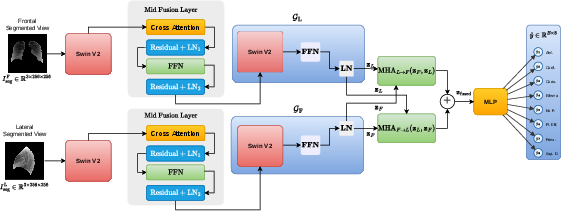
Figure 2: Dual Swin Transformer V2 architecture fuses frontal and lateral features by cross-attention before pathology prediction and downstream integration.
Attention-driven post-hoc interpretability leverages gradient-weighted heatmaps and Shapley-values to quantify both per-patch and per-view pathology relevance. Spatially correlated clusters are extracted via DBSCAN, with adaptive allocation of dynamic patch sets per pathology, preserving view-specific and cluster-level geometric context for the downstream multimodal transformer (Figure 3).
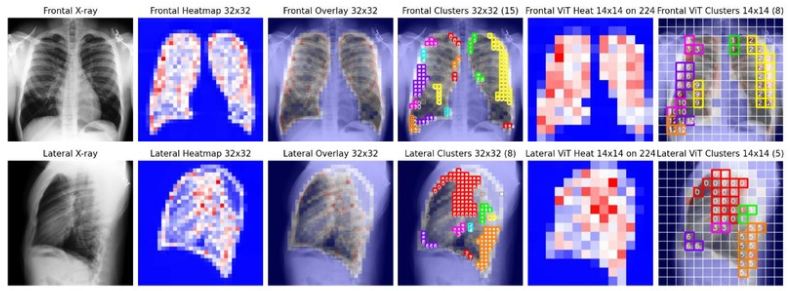
Figure 3: Attention-driven patch selection pipeline for frontal and lateral views; only pathology-dominant clusters inform the T5 multimodal decoder.
Hierarchical tokenization yields structured representations (global, cluster, and dynamic patch tokens), projected to T5 embedding space and concatenated with textual findings. This enables cross-modal fusion at the impression-generation phase, enforcing strict alignment between high-attention image regions and semantically salient textual context.
Quantitative Results and Ablation
ViTAS outperforms both text-only and conventional multimodal models across diverse metrics (BLEU-4, ROUGE-L, BERTScore, CheXbert, RadGraph). Selective attention to pathology-driven patches delivers a BLEU-4 gain of 25.22% over text-only baselines—decisively surpassing full-image multi-view inputs and ROI-only models, contradicting the "more is better" heuristic. Controlled ablation studies on MIMIC-CXR demonstrate plateauing performance when naive patch selection or uncurated image regions are employed, emphasizing the necessity of targeted visual evidence.
Notably, visual noise introduced by non-pathology regions dilutes cross-modal alignment and factual accuracy, and only selective extraction informed by attention/Shapley mechanisms produces measurable improvements in both automatic and clinical entity metrics. This is most pronounced in the FINDINGS→IMPRESSION task, previously believed intractable for multimodal methods.
Qualitative Analysis and Human Evaluation
Qualitative comparison reveals ViTAS's capacity to synthesize subtle radiographic findings into actionable clinical impressions, outperforming full-image and simple ROI baselines. For example, in left lung opacification, the ViTAS ROI-patch model integrates nodular densities and pneumonia context into a concise, expert-matching impression, avoiding the hallucination and loss of detail common to less selective models (Figure 4).

Figure 4: ViTAS ROI-patch model aligns closely with ground truth, capturing both pneumonia and lymphangitic spread—demonstrating superior clinical interpretability.
Human expert evaluation, scored across readability, factual correctness, informativeness, redundancy, and completeness, confirms superior alignment of ViTAS-generated summaries with radiologist expectations. Higher scores in factual accuracy and completeness support the hypothesis that selective visual input enhances clinical utility and trustworthiness.
Practical and Theoretical Implications
ViTAS's methodology compels a reevaluation of multimodal radiology summarization strategies. The demonstrable superiority of pathology-driven visual evidence indicates that future medical vision-LLMs should prioritize interpretability-guided selection over brute-force image inclusion. This has direct practical ramifications for real-world deployment in clinical environments: reduced computational overhead, improved factual stand-alone radiologist confidence, and minimization of hallucination risk.
The theoretical contribution lies in operationalizing Shapley-based view and patch selection—enabling dynamic, pathology-adaptive feature extraction that accommodates anatomical variability and imaging complexity. This framework may generalize to other organ systems, multi-modal imaging modalities, and more granular diagnostic tasks. Extensions include integrating uncertainty quantification, automated error correction in segmentation or attention, and expansion to cross-institutional datasets for robustness evaluation.
Conclusion
ViTAS defines a new standard for multimodal radiology report summarization by deploying selective, interpretable attention to high-importance regions. This strictly noise-aware methodology achieves SOTA on MIMIC-CXR, disproving the assumption that maximizing visual input or relying solely on textual findings are optimal. Both empirical and expert evaluation validate improved factual alignment, clinical interpretability, and summarization quality. The implications extend to future medical AI systems, suggesting a pivot toward relevance-driven, interpretability-aware visual language modeling strategies in clinical NLP and medical imaging.

