- The paper's main contribution is the design of HLC, a hybrid mezzanine codec that fuses a dependency-free palette mechanism with co-designed RDO and efficient entropy coding to optimize throughput and compression.
- It introduces a novel Pixel Clustering Engine that enables parallel, dependency-free palette coding using a virtual cluster table, avoiding pipeline stalls with only a minor PSNR loss of 0.121dB on text.
- Experimental results demonstrate HLC’s advantages, including a 5.312dB BD-PSNR gain over JPEG-XS for text content and real-time performance at 4K@120fps with significantly reduced hardware resource usage.
HLC: A High-Quality Lightweight Mezzanine Codec Featuring High-Throughput Palette
Introduction
The "HLC: A High-Quality Lightweight Mezzanine Codec Featuring High-Throughput Palette" (2603.29864) addresses the limitations of current mezzanine codecs in preserving visual quality under bandwidth constraints, especially for screen content with dense text. While distribution codecs achieve high compression efficiency, their computational overhead precludes practical mezzanine use. In contrast, state-of-the-art mezzanine codecs such as JPEG-XS emphasize throughput and hardware simplicity but fail to efficiently compress non-natural content types. The paper proposes HLC, a hybrid codec architecture that fuses a data-dependency-free Palette (PLT) mechanism, a co-designed rate-distortion optimization (RDO), and a data reuse strategy between rate estimation and entropy coding, attaining a superior balance of throughput, hardware resource efficiency, and compression performance across content types.
HLC System Architecture
HLC's pipeline is divided into three primary stages. The coding unit (CU) is fixed at 16×4 pixels, optimizing buffer depth compared to conventional block sizes and facilitating enhanced pipelining. The architectural pipeline integrates PLT, directional prediction (DP), rate control (RC), RDO, and entropy coding (EC) modules, each designed for parallel hardware execution.
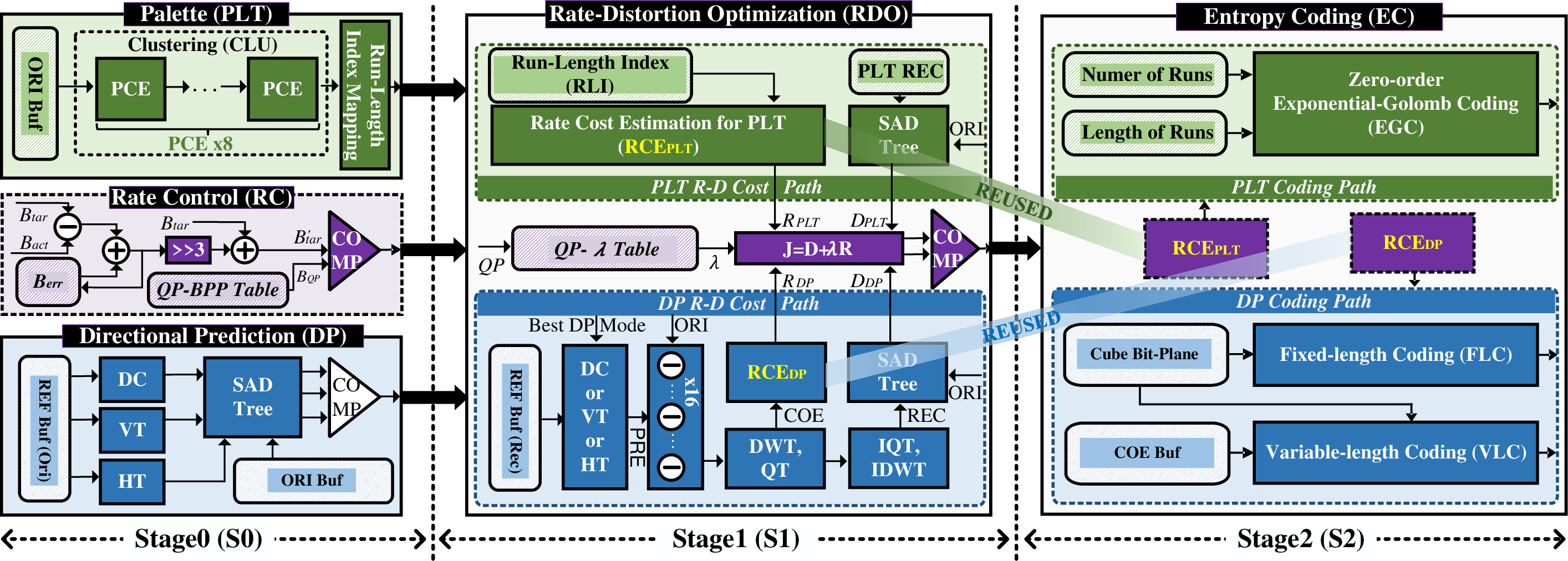
Figure 1: Hardware architecture of HLC, which contains three pipeline stages.
- Stage S0 executes PLT and DP for decorrelating spatial redundancy, with RC managing target bitrate.
- Stage S1 performs RDO, selecting between PLT and DP for each CU, and applies discrete wavelet transform (DWT) with quantization.
- Stage S2 finalizes bitstream generation via a highly parallel entropy coder.
The design leverages co-optimization at both architectural and algorithmic levels to reconcile hardware cost constraints and data rate requirements.
Dependency-Free High-Throughput Palette Coding
Traditional palette-based block coding, as originally implemented in HEVC, is hindered by clustering-stage data dependencies, thwarting parallel hardware realization and scaling inefficiency. HLC's development of a Pixel Clustering Engine (PCE) resolves these issues, supporting scalable, fully pipelined operation at minimal resource overhead.
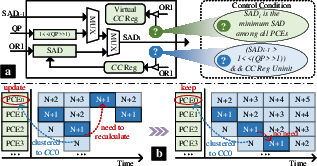
Figure 2: Hardware architecture and pipeline space-time diagram of pixel clustering engine (PCE). (a) Architecture. (b) Space-time diagram.
In conventional clustering, updating cluster centers (CCs) forces pipeline stalls and roll-back. HLC circumvents this by:
- Utilizing a virtual cluster table. During clustering, CCs are fixed (standard CC reg), decoupling assignment decisions from intermediate updates. A separate register (virtual CC reg) accumulates pixel contributions for postprocessing only.
- This architectural choice fully eliminates recursive dependency, as all clustering comparisons reference immutable CC states, enabling concurrent processing of all CU pixels with no flushes or restarts.
The only trade-off is a minor PSNR loss (0.121dB BD-PSNR on text) due to the non-evolving CCs during cluster assignment—a negligible penalty compared with the hardware and throughput benefit.
Run-Length Index Mapping for Palette Indices
Upon cluster table finalization, CU pixels are mapped to cluster indices. This map is then amenable to robust entropy reduction using a directional run-length encoding scheme:
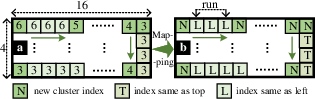
Figure 3: An illustration of run-length index mapping. (a) Pixels of CU represented by corresponding cluster index. (b) Mapping results.
- Each index is mapped to
0 (matches left neighbor), 1 (top), or 2 (otherwise), which transforms spatial structure into symbol runs suitable for efficient coding.
- The resulting run-length index (RLI) sequence compresses spatial redundancy both horizontally and vertically, reducing bitstream size and simplifying downstream coding cost estimation and entropy coding.
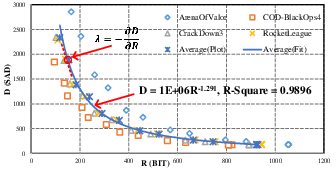
Co-Designed Rate-Distortion Optimization and QP-λ Tuning
Highly efficient palette use introduces another challenge: balancing RD optimization across varied content. HLC integrates a CU-level RDO that arbitrates between PLT and DP modes for every block.
Hardware-Efficient Entropy Coding via RDO Data Reuse
One key innovation is the pipeline-level reuse of RDO-derived statistics within entropy coding:
- Fixed-length stats (e.g., bit-plane values from DP, run counts and lengths from PLT) are directly forwarded from RCE modules into EC, eliminating redundant computation.
- The bitstream then consists of fixed-length headers defining variable-length data, enabling high parallelism and reduced logic utilization.
- For PLT, run lengths are entropy coded using zero-order Exponential-Golomb Coding (EGC), streamlining the hardware data path and further reducing LUT consumption in EC (to 17.4K LUTs).
Experimental Analysis
Quantitative evaluation on KC705 FPGA demonstrates that HLC achieves 4K@120fps real-time performance with only 82K LUTs (encoder), notably half that of a comparable JPEG-XS encoder, and with substantially superior compression performance.
- BD-PSNR gains relative to JPEG-XS are 5.312dB (text), 3.461dB (gaming), and 3.299dB (natural content).
- Against FPGA JPEG-2000, HLC matches or reduces LUT usage, doubles throughput, and achieves 1.7–1.8dB gain on screen content.
- In comparison to an intra-only FPGA HEVC implementation, HLC's throughput is orders of magnitude higher for similar LUT count: HEVC is constrained to 4K@2fps due to entropy coding complexity (versus 120fps for HLC).
Ablation confirms PLT's essential role, with its removal causing a 3.983dB BD-PSNR drop on text content, validating the minimal added hardware cost (24K LUTs) versus its critical quality benefits.
Discussion and Implications
The HLC framework demonstrates that high-throughput, low-resource, and quality-retentive codec architectures are attainable using principled hardware-level innovations such as dependency-free palette coding and data-path optimization strategies that maximize both algorithm and architectural synergy. HLC's architecture is particularly suited for real-time, latency-sensitive use cases in broadcast, medical imaging, and cloud gaming, where high-resolution, high-frame-rate transport of screen and natural content is critical.
Future directions likely include: extending palette mechanisms to support variable block shapes for ultra-high-resolution screens; exploring adaptive RDO-cost modeling responsive to content type or context; leveraging sparse and neural data-driven palette initialization; and integrating video frame prediction to facilitate lightweight inter-frame compression while maintaining random access and frame independence.
Conclusion
The HLC codec (2603.29864) combines a hardware-dependency-free palette mechanism, an analytically tuned RDO, and an aggressive data reuse strategy to address the multidimensional requirements of modern mezzanine coding. The result is a system that, with half the LUTs of JPEG-XS, surpasses it by over 5dB in BD-PSNR for text-heavy content at 4K@120fps. This convergence of efficient algorithm design and parallel hardware-friendly implementation establishes HLC as a viable and impactful solution for the evolving requirements of high-resolution, low-latency image transport and processing applications.