- The paper introduces a multi-feature fusion approach that integrates MSCN, CLIP, and MLBP extractors for robust GenAI detection.
- It demonstrates that fusing complementary features improves separation and stability in detecting synthetic images across diverse generative models.
- Empirical results show enhanced accuracy, reduced variance, and superior generalization compared to state-of-the-art detection methods.
Multi-Feature Fusion Strategies for Generative AI Image Detection
Introduction
The proliferation of high-fidelity Generative AI (GenAI) models has escalated the challenge of detecting synthetic images, disrupting established multimedia forensics, authenticity assessment, and content verification protocols. While early detectors based on Natural Scene Statistics (NSS) could reliably identify low-level statistical irregularities, recent diffusion models (e.g., Stable Diffusion, DALL·E 3, Midjourney) have closed this gap, producing samples that are visually and statistically aligned with natural images. The central question addressed in "Multi-Feature Fusion Approach for Generative AI Images Detection" (2603.29788) is whether a single feature space can provide reliability across generator architectures and imaging scenarios, or whether multi-domain fusion is essential for robust GenAI detection.
Multi-Feature Fusion Framework
The paper introduces a modular pipeline that encodes each input image with three parallel extractors: statistical (MSCN), semantic (CLIP), and textural (MLBP) features. These standardized representations are concatenated and passed to conventional classifiers (Gradient Boosting, Random Forest, SVM) for binary discrimination.
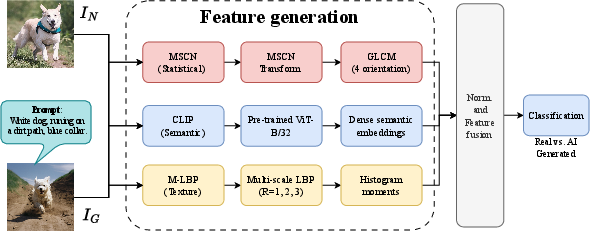
Figure 1: The multi-feature fusion pipeline: MSCN, CLIP, and MLBP feature encoders in parallel, followed by normalization, concatenation, and classification.
MSCN (NSS features): Extracts Haralick statistics from GLCMs derived from mean-subtracted, contrast-normalized images, capturing deviations from natural luminance and contrast statistics.
CLIP embeddings: Provides high-level, semantically rich representations leveraging the CLIP-ViT/B-32 vision-LLM, sensitive to contextual and compositional priors not captured by sole fine-grained patterns.
MLBP: Quantifies local textural patterns at multiple scales via uniform LBP histograms, detecting micro-structure regularities and boundary artifacts often overlooked in other domains.
The central hypothesis posits that the compositional failures of GenAI images occur on orthogonal axes: realistic textures may mask statistical deviations, plausible semantics may coexist with repetitive patterns, or high-level alignment may hide low-level inconsistencies. By fusing representations, classifiers are exposed to manifold deviations inaccessible to any single feature modality.
Feature Analysis and Visualization
The paper provides a targeted illustration of the behavior of MSCN and MLBP features.

Figure 2: Comparative MSCN contrast and MLBP texture maps for natural versus DALLE- and Stable Diffusion–generated images. Synthetic samples exhibit local intensity irregularities ("halos") and excessive textural regularity ("tiling"), in contrast to the stochastic continuity of real images.
This visualization confirms that certain residual artifacts from generation pipelines persist in local contrast statistics and textures, even amid high global photorealism.
Manifold Divergence and Feature Space Dynamics
A core analytical contribution is the empirical examination of the real-vs-GenAI manifold separation in various feature subspaces. The Gaussian Fréchet distance quantifies feature space divergence between natural and synthetic distributions.
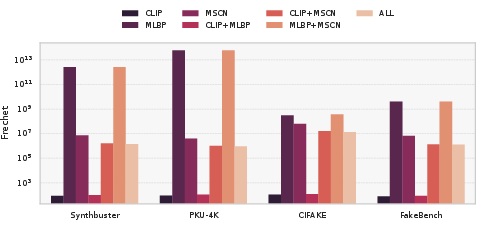
Figure 3: Log-scaled Fréchet distances between natural and GenAI distributions for individual and fused features across multiple datasets. Larger values indicate stronger separability in the corresponding projection.
Stronger manifold separation correlates with improved discrimination metrics, yet not all distributional shifts align with axes discriminative for classification. A combined scatter/correlation analysis between Fréchet distance and MCC demonstrates robust Spearman correlation within each dataset but also highlights that some features yield weak practical separation despite large statistical differences.
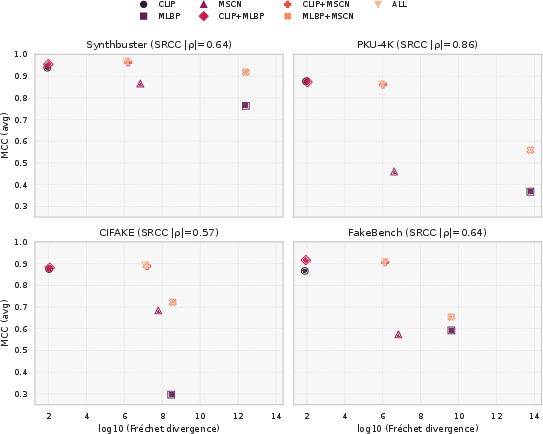
Figure 4: MCC vs. log10 Fréchet divergence for all feature configurations. Spearman ∣ρ∣ summarizes the observed correlation between feature-space manifold separation and practical detection performance.
This supports the assertion that detection efficacy depends heavily on both the breadth of divergence and its alignment with decision-critical axes, strengthening the argument for orthogonal fusion.
Embedding Space Visualization
Applying t-SNE on CIFAKE samples, the paper illustrates improvement in cluster separability as more complementary features are fused.
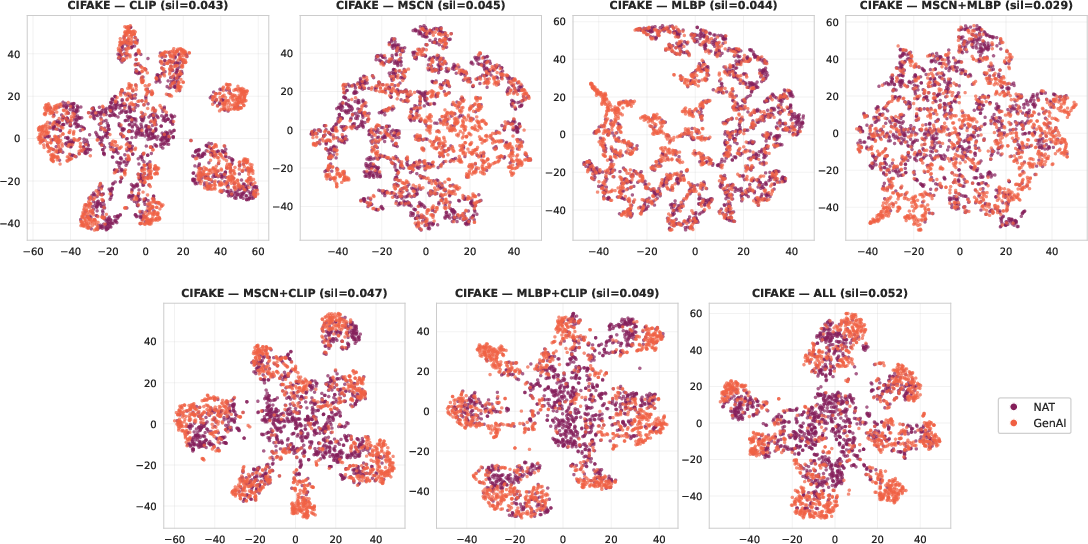
Figure 5: t-SNE projections for all feature combinations on CIFAKE: individual features yield overlapping real/GenAI clusters, while full fusion produces more distinct and compact class clusters.
These results both visually and quantitatively (via silhouette scores) validate the fusion hypothesis: distinct subspaces are required to reliably expose generators’ diverse failure modes.
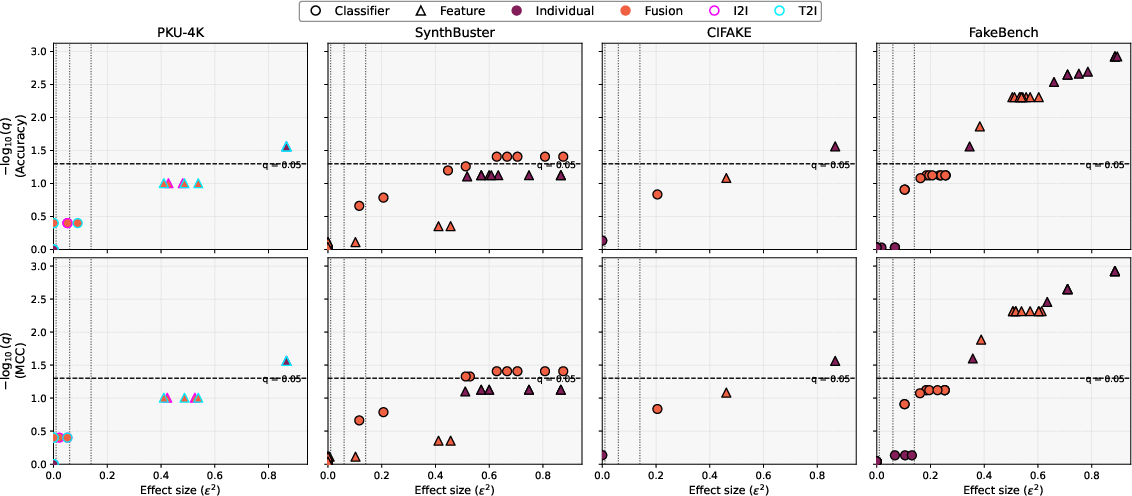
Robustness, Generalization, and Statistical Analysis
Synthbuster, PKU-4K, CIFAKE, and FakeBench are utilized for comprehensive evaluation. CLIP dominates single-feature performance on all datasets, but is not universally sufficient: low-level (MSCN) and texture-based (MLBP) cues compensate in cases of semantic conformity. Fusion configurations (particularly ALL and CLIP+MSCN/CLIP+MLBP) consistently yield higher Accuracy and MCC, demonstrating robust cross-generator and cross-dataset generalization.
The statistical tests (Kruskal–Wallis, effect size, FDR correction) reveal:
Correlation analysis between Accuracy and MCC further demonstrates that fusion yields more balanced, stable decision-making compared to the higher volatility of single-feature approaches.
Generalization in Mixed-Model and Heterogeneous Scenarios
Evaluating on random mixtures of images from diverse generative models, the fused feature configurations maintain superior accuracy and reduced variance, whereas individual features frequently falter under such distribution shifts. Semantic (CLIP) features enable the highest single-feature robustness, while fusion with statistical and texture cues consistently enhances deployment reliability.
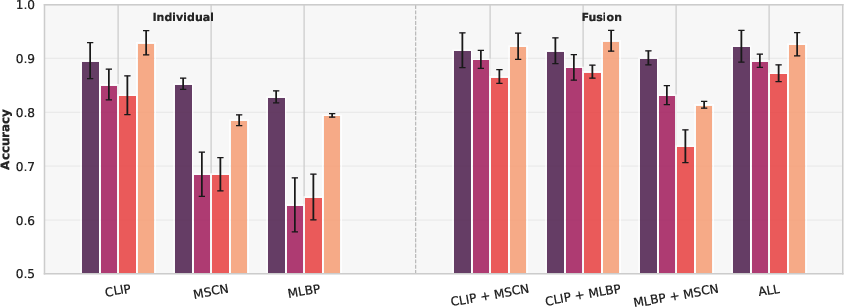
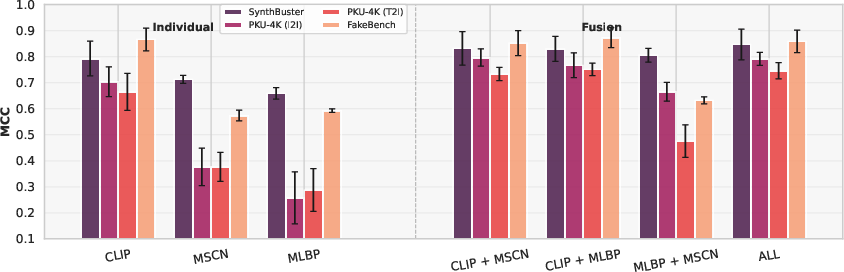
Figure 7: Grouped bar-plots of Accuracy and MCC for individual and fusion features on mixed-generator settings. Fusion significantly enhances mean performance and reduces inter-classifier variance.
Benchmarking Against State-of-the-Art
The framework surpasses established detectors—CNNDetection, PatchForensics, DMImageDetection, and Synthbuster—on all considered benchmarks. Competing methods exhibit strong dataset dependency or focus on restricted artifact types, leading to poor cross-domain generalization. Fusion-based approaches, particularly integrating CLIP, establish consistent superiority.
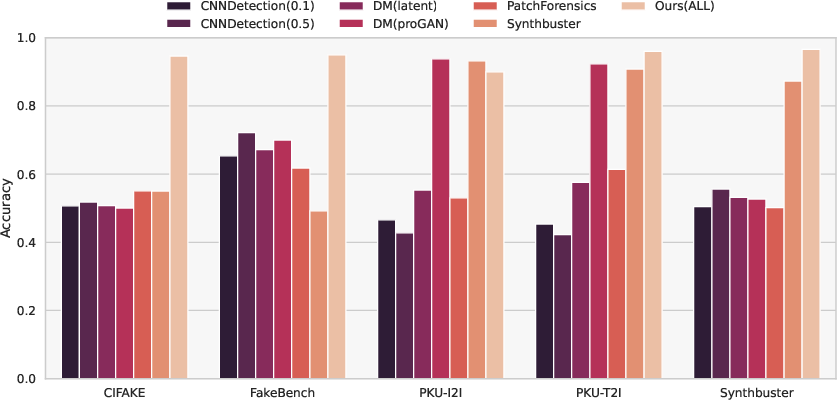
Figure 8: Comparative bar-plot of detection accuracy across SOTA baselines on multiple benchmarks. The proposed fusion-based approach outperforms all competitors in every regime.
Implications and Future Directions
The empirical findings underscore that GenAI detection, as of current generative capabilities, is inherently representation-centric. While classifiers can fine-tune boundaries, their efficacy is bottlenecked by the capacity of feature spaces to expose diverse generative errors. Fusion is neither naive stacking nor mere redundancy: it exploits explicit complementarity, robustly reducing sensitivity to generator, domain, and classifier choice.
This architecture points towards a future in which:
- Adaptive and context-sensitive fusion, potentially leveraging attention or sample-dependent weighting, could yield further boosts in unseen generator scenarios.
- End-to-end differentiable optimization of fused representations may reduce overhead of manual preprocessing and benefit from task-driven joint learning.
- Video and spatio-temporal extensions will be essential as generative content pipelines evolve beyond single images.
The reliance on pretrained models introduces biases from the source training sets, and some generator families (e.g., VQ-Diffusion) still lead to performance dips, indicating room for ongoing work on transferability and bias mitigation.
Conclusion
A systematic investigation of multi-feature fusion for GenAI image detection establishes the necessity of integrating statistical, semantic, and textural cues. The fusion architecture yields higher accuracy, greater robustness, and reduced representation variance compared to all state-of-the-art baselines and single-domain methods, providing a principled foundation for future general-purpose, domain-agnostic detectors—critical as generative models continue to advance in realism and diversity.