DYMO-Hair: Generalizable Volumetric Dynamics Modeling for Robot Hair Manipulation
Abstract: Hair care is an essential daily activity, yet it remains inaccessible to individuals with limited mobility and challenging for autonomous robot systems due to the fine-grained physical structure and complex dynamics of hair. In this work, we present DYMO-Hair, a model-based robot hair care system. We introduce a novel dynamics learning paradigm that is suited for volumetric quantities such as hair, relying on an action-conditioned latent state editing mechanism, coupled with a compact 3D latent space of diverse hairstyles to improve generalizability. This latent space is pre-trained at scale using a novel hair physics simulator, enabling generalization across previously unseen hairstyles. Using the dynamics model with a Model Predictive Path Integral (MPPI) planner, DYMO-Hair is able to perform visual goal-conditioned hair styling. Experiments in simulation demonstrate that DYMO-Hair's dynamics model outperforms baselines on capturing local deformation for diverse, unseen hairstyles. DYMO-Hair further outperforms baselines in closed-loop hair styling tasks on unseen hairstyles, with an average of 22% lower final geometric error and 42% higher success rate than the state-of-the-art system. Real-world experiments exhibit zero-shot transferability of our system to wigs, achieving consistent success on challenging unseen hairstyles where the state-of-the-art system fails. Together, these results introduce a foundation for model-based robot hair care, advancing toward more generalizable, flexible, and accessible robot hair styling in unconstrained physical environments. More details are available on our project page: https://chengyzhao.github.io/DYMOHair-web/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
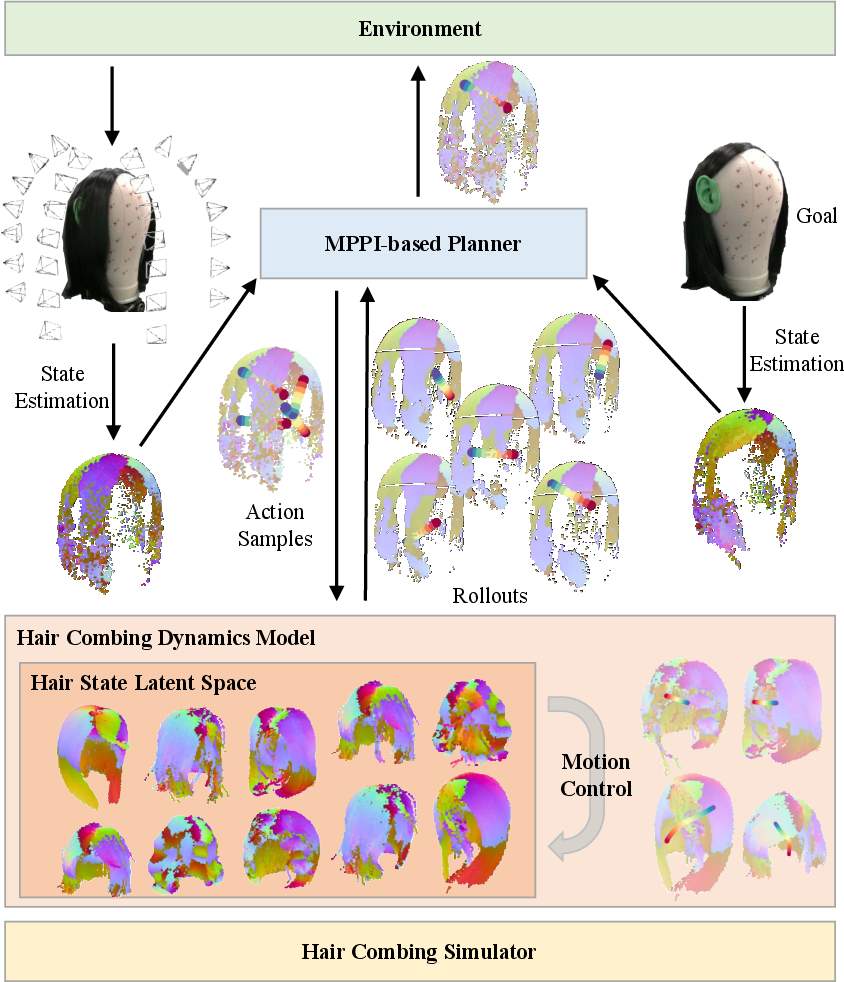
This paper is about teaching a robot to help with hair care, like combing and styling. Hair is hard for robots because it’s made of thousands of tiny strands that move in complicated ways. The authors built a system called DYMO-Hair that can look at hair, predict how it will change when a comb moves through it, and plan the comb’s motions to reach a desired style (a “visual goal”). They also created a fast, realistic hair simulator to train their system without needing tons of real-world data.
What questions did the researchers ask?
They focused on four simple questions:
- How can a robot “see” and understand hair in 3D, including the direction each strand flows?
- How can a robot predict what hair will look like after a combing motion?
- How can a robot choose the next comb move to reach a target hairstyle?
- How can we get enough training data when real hair gets tangled and is slow to reset?
How did they do it?
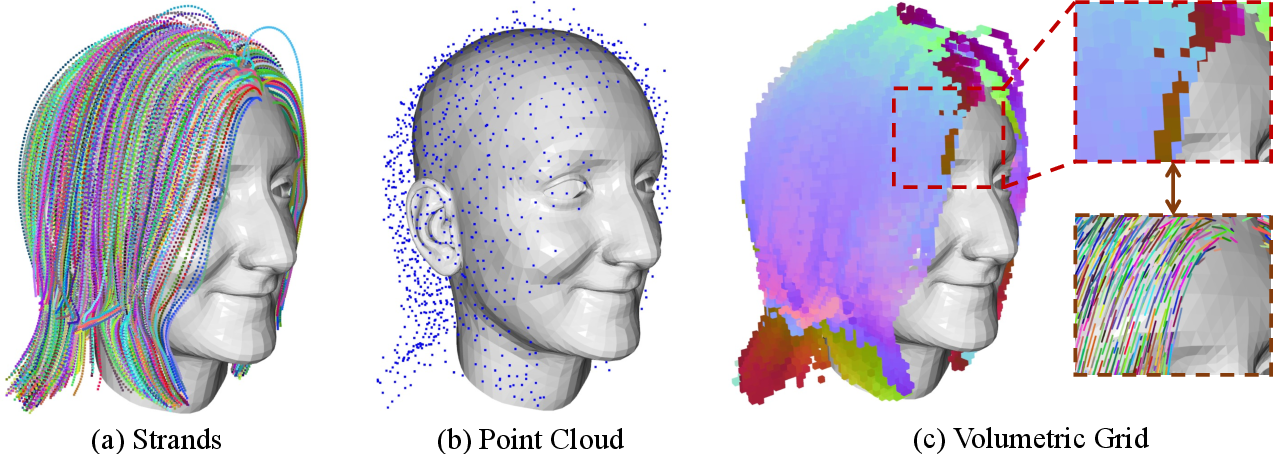
Representing hair in 3D
Think of the hair around a head like a 3D Minecraft world made of tiny cubes called “voxels.” Each voxel stores:
- Whether there’s hair there (occupied or not).
- The direction the hair is pointing at that spot (like arrows that show the flow).
This “volumetric grid” lets the robot capture both the shape of the hair and how the strands are oriented, which is more detailed than just a sparse set of 3D points.
Teaching the model to predict hair movement
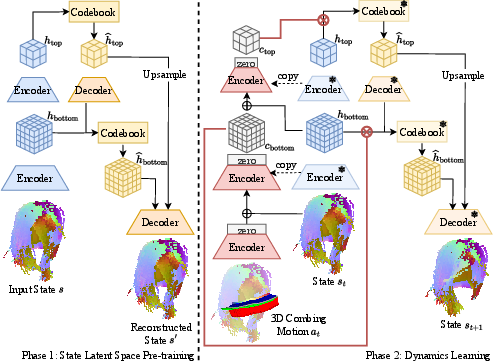
The core idea is a two-step learning process:
- Pre-train a compact “latent space” of hair Imagine compressing a full 3D hairstyle into a short “secret code” that still preserves important details. The team trains a 3D encoder–decoder (similar to VQ-VAE) that learns to represent many different hairstyles in a smaller form. This helps the model generalize to new hair types.
- Action-conditioned state editing Inspired by ControlNet (a way to guide image generation with extra control), the model learns to “edit” the hair’s latent code based on the comb motion. In simple terms, given the current hair and the planned comb movement, the model adjusts the compressed representation to predict the next hair state. To align motion with hair, the comb’s path is turned into a 3D map that marks where the comb touches or comes close—like highlighting the route the comb travels through the hair.
Planning the comb’s moves
They use a planner called MPPI (Model Predictive Path Integral). In everyday terms:
- The planner imagines many possible comb strokes.
- It uses the learned dynamics model to predict how each stroke changes the hair.
- It picks the sequence of strokes that moves the hair closest to the target style.
This repeats in a loop: observe hair, predict outcomes, choose the best next actions, execute, and re-check until the goal is reached.
Building a hair simulator
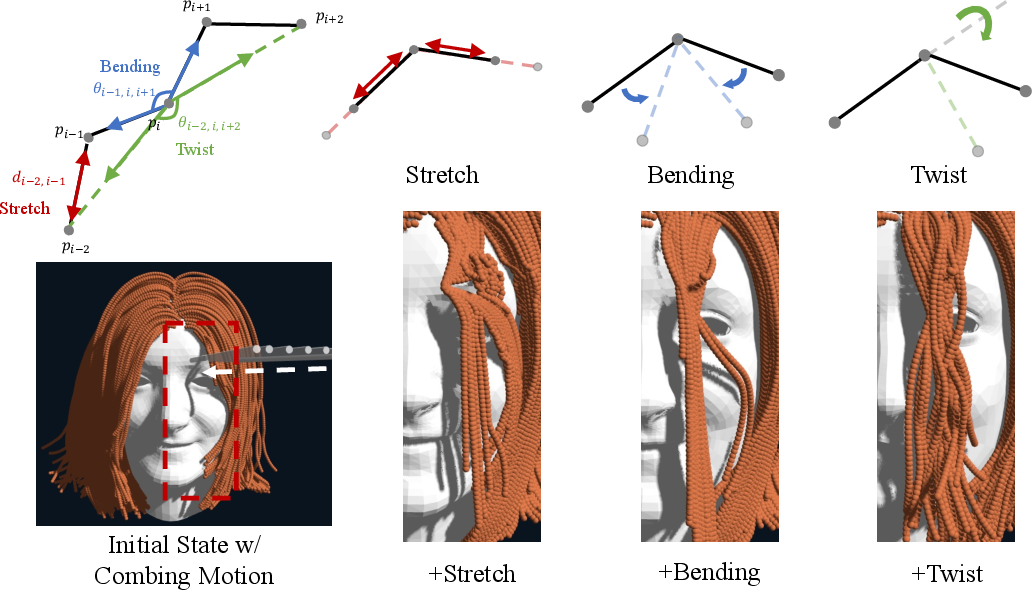
Collecting real hair data is slow and tricky (hair tangles and is hard to reset), so they built a fast GPU-powered simulator to generate training data. They model each strand as a chain of tiny particles (“beads on a string”) and apply three constraints so strands behave realistically:
- Stretch: neighboring beads keep their usual spacing.
- Bending: strands don’t bend too sharply unless pushed.
- Twist: strands keep a consistent twist so they don’t flatten unnaturally.
The simulator also handles collisions and friction (strand–strand and comb–hair contact), producing realistic “combing” motion data to train the model.
What did they find?
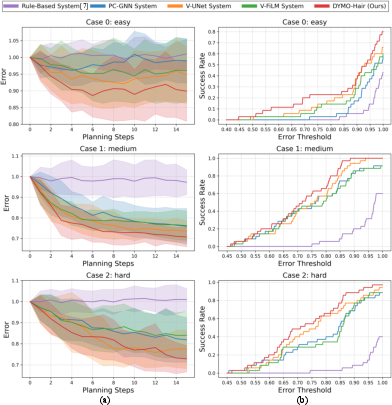
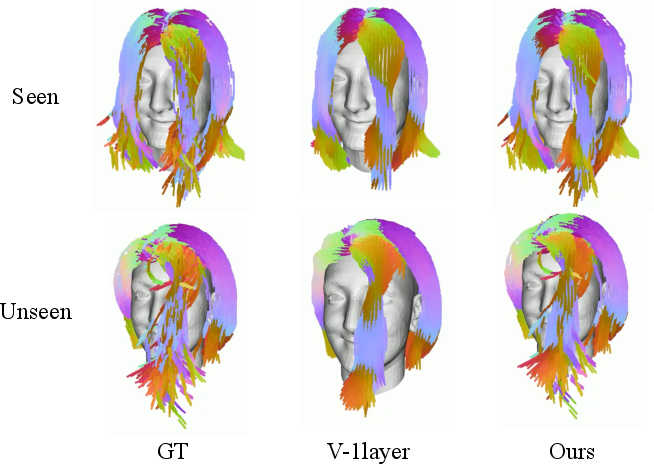
- Their dynamics model predicted hair changes more accurately than other methods, especially for local deformations near the comb.
- In simulated styling tasks on new, unseen hairstyles, DYMO-Hair:
- Achieved about 22% lower final geometric error.
- Reached success about 42% more often than the best previous system.
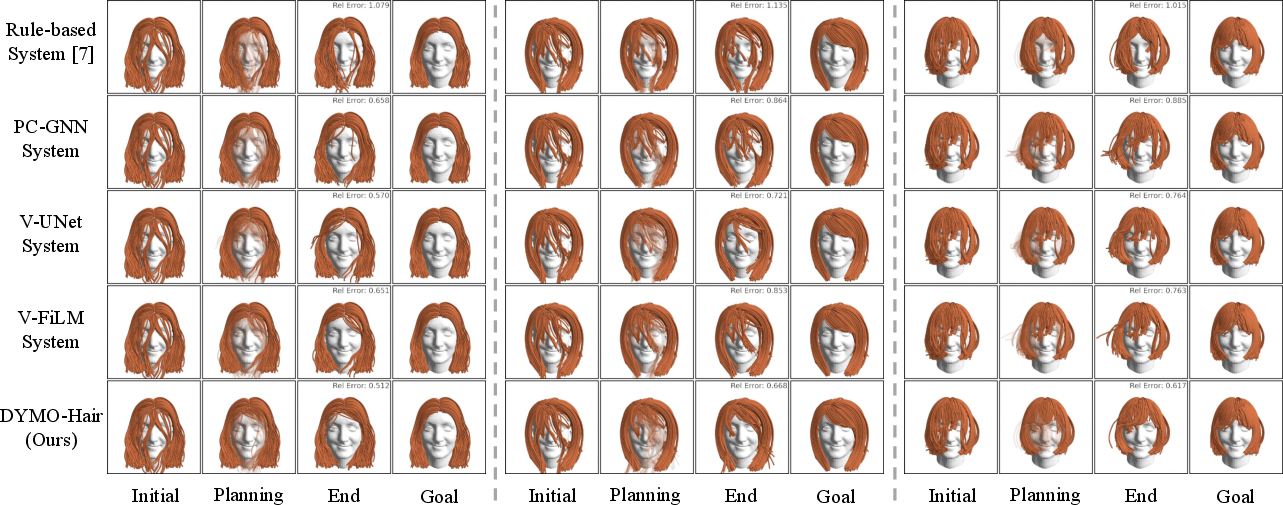
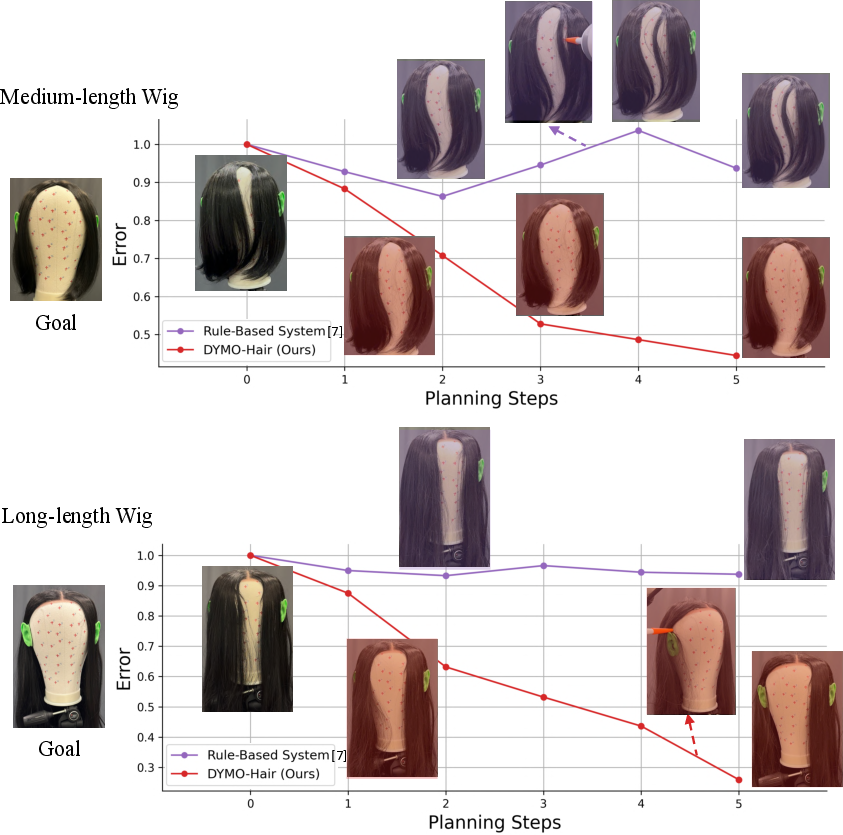
- In real-world tests on wigs, DYMO-Hair worked “zero-shot” (without extra training on those wigs). It succeeded on challenging styles where the older rule-based system failed.
In short, DYMO-Hair was better at understanding and predicting hair movement, and this led to more successful styling both in simulation and the real world.
Why does this matter?
This work is a step toward robots that can help with personal care in a safe, flexible, and dignified way—especially for people with limited mobility. It shows:
- A practical way to represent hair in 3D so robots can understand it.
- A generalizable learning method that can handle different hairstyles and goals.
- A planning approach that chooses smart combing actions, not just fixed rules.
- A fast simulator that makes training possible at scale.
Future improvements could add more safety checks around the face, estimate the head’s position on the fly, and use softer, more human-friendly tools. But even now, DYMO-Hair lays the groundwork for robots that can style hair in real, everyday environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Real-world validation scope is narrow: only two wigs, no tests on human subjects, and limited hairstyle diversity. Evaluate on a broader spectrum of hair types (straight, wavy, curly, coily), lengths, densities, and with hair products (oils, gels), wetness, accessories (pins, bands), and protective styles (braids, locs).
- Assumption of a static, perfectly calibrated mannequin head. Develop online head pose and geometry estimation, handle head motion, and test robustness to miscalibration and registration errors between goal and current states.
- Exclusive reliance on synthetic pre-training. Collect and integrate real-world combing sequences to quantify sim-to-real gaps, perform parameter identification to calibrate simulator friction/stiffness to physical measurements, and evaluate domain adaptation (e.g., fine-tuning, domain randomization).
- Simulator physics fidelity is unvalidated against real hair mechanics. Measure and match strand-level torsional stiffness, anisotropic friction (cuticle directionality), inter-strand adhesion, humidity effects, and static electricity; compare heuristic twist constraints against Cosserat/rod models and hybridize where needed.
- State representation limits: a fixed 64×64×128 grid (~5 mm voxels) may miss fine-scale structures and topological events (knots, crossings). Conduct resolution ablations, add uncertainty-aware upsampling, and consider augmentations (e.g., local curvature, thickness, density) or sparse volumetric/implicit representations that preserve strand topology.
- Orientation symmetry handling (treats v and −v as equivalent) discards root-to-tip directionality that may matter for combing efficacy. Investigate signed orientation and root anchoring, and quantify the impact on planning and outcomes.
- Motion encoding approximates contact with a fixed-radius cylindrical prior. Replace with learned or physics-informed contact maps conditioned on local hair density/penetration depth, and study sensitivity to tool geometry, material, and compliance (comb vs brush).
- Perception robustness is not quantified. Benchmark multi-view RGB-D state estimation accuracy, runtime, failure modes under occlusions, specular highlights, dark/low-contrast hair, and variable lighting; analyze error propagation into dynamics and planning.
- Planning objective (strand-level geometric distance) lacks validation against human-perceived styling quality. Develop perceptual/semantic goal metrics and user-centered success criteria; test correlation between geometric losses and subjective assessments.
- No tactile or force feedback is used. Integrate force/torque and tactile sensing to detect entanglement, slip, excessive pulling forces, and contact quality; compare vision-only vs multimodal control.
- Safety and HRI constraints are not enforced. Incorporate real-time safety constraints (e.g., eyes/skin exclusion zones, force thresholds), compliance control, and user-in-the-loop interaction; perform safety evaluations and user studies.
- Limited evaluation against baselines, especially in real-world settings. Compare to additional learning-based systems, report ablations of key components (latent codebook sizes, fusion mechanisms, motion encoding design), and quantify each component’s contribution.
- Metrics may obscure failure cases. Orientation error ignores points >2 cm, potentially masking large deviations; add metrics that capture topological errors (strand crossings/knots), volumetric overlap over time, and assess distribution tails beyond 90th percentile.
- Computational performance is not reported. Provide end-to-end cycle times (perception, dynamics inference, MPPI planning), memory/compute footprints, rollout counts, and real-time feasibility on robot hardware; investigate speed–accuracy trade-offs.
- Generalization to long-horizon transformations and complex goals is underexplored. Evaluate tasks requiring coordinated front/side/rear styling and multi-step semantic objectives; consider hierarchical planning or curriculum strategies.
- Detangling and knot resolution are not addressed. Extend the system to entanglement-aware manipulation with specialized sensing, dynamics modeling of topological change, and recovery strategies.
- Tool design space is limited (simple cylinder). Systematically study tool shapes, stiffness, bristle configurations, compliant/soft end-effectors, and their impact on contact modeling and success rates.
- Goal specification assumes geometrically aligned 3D targets. Explore natural-language or single-image goals, automatic goal-to-state registration, and methods robust to misalignment and partial goal specification.
- Uncertainty is not modeled. Quantify uncertainty in state estimation and dynamics predictions, and incorporate risk-aware MPC (e.g., ensembles, Bayesian models, chance constraints) to improve robustness.
- Scalability of the latent space and ControlNet-style fusion is unexamined. Analyze codebook sizes, quantization errors, editing stability, and catastrophic forgetting; test alternative latent models (e.g., diffusion, implicit fields) and fusion operators.
- Hair–scalp/head interactions are simplified. Model scalp compliance and friction, ear/face occlusions, and accessories; encode head geometry in state/planning, and evaluate how these factors affect manipulation.
- Dataset diversity and balance are limited (10 training hairstyles, primarily neat-state pre-training). Expand to messy/deformed states distribution, cross-ethnic and texture diversity, and report how dataset composition affects generalization.
- Robustness to dynamic environments is untested. Assess performance under camera motion, head motion, environmental perturbations (fans, vibration), and presence of clothing/collars that interact with hair.
- Error analysis of failure modes is missing. Provide qualitative and quantitative breakdowns (e.g., missed contacts, over-smoothing, strand misalignment, topological artifacts) to guide targeted model and system improvements.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s current capabilities (volumetric hair representation, ControlNet-style dynamics learning, MPPI-based planning, and the strand-level PBD simulator) with minimal additional R&D.
- Robotics R&D and benchmarking (academia; robotics/software)
- Use the DYMO-Hair simulator and datasets to benchmark deformable-object dynamics models and planners under contact-rich, strand-like dynamics.
- Establish lab exercises and courses on model-based control for deformable objects, using the voxel occupancy+orientation field and MPPI planner as reference pipelines.
- Potential tools/products/workflows: DYMO-Hair SDK for ROS; Genesis-based hair-combing simulation package; pre-trained weights; evaluation scripts; open datasets with occupancy+orientation labels.
- Assumptions/dependencies: Access to GPU hardware; familiarity with Genesis or equivalent simulators; multi-view RGB-D cameras for reconstruction.
- Wig manufacturing and retail automation (industry; retail/manufacturing/robotics)
- Automate repetitive wig restyling and display preparation in boutiques and e-commerce studios.
- Consistent pre-styling before packaging, and auto-recovery of showroom wigs after try-ons.
- Potential tools/products/workflows: Workcell with a 6-DOF arm, the provided planner, voxel-state perception pipeline, and a standardized cylindrical or brush-like end-effector.
- Assumptions/dependencies: Accurate calibration and fixture of mannequin/wig stands; well-lit controlled environments; styles similar to those seen in pre-training.
- Cosmetology education and training simulators (academia/industry; education/VR-AR/software)
- Use the simulator to demonstrate strand-level deformation, tool trajectory effects, and “what-if” scenarios without requiring human subjects.
- Potential tools/products/workflows: Instructor dashboards, parameterized scenarios (e.g., messiness levels), motion libraries; integration with XR displays.
- Assumptions/dependencies: Acceptance that simulated twist is an approximation; alignment between simulated tools and classroom tools.
- Assistive robotics prototyping with wigs/mannequins (healthcare; robotics)
- Pilot demonstrations in clinics and rehab centers to validate goal-conditioned hair manipulation as a precursor to human trials.
- Potential tools/products/workflows: Fixed-head mannequin stations; low-force end-effectors; multi-view RGB-D setup; MPPI planning with geometric exclusion zones around eyes/ears.
- Assumptions/dependencies: Current system assumes privileged head pose and precise calibration; best suited for supervised environments and non-human subjects today.
- Content creation and hair physics pretraining (media/gaming; software)
- Generate synthetic datasets of hair states and dynamics to pretrain networks for VFX and real-time avatars, especially for local deformation priors around comb/brush tools.
- Potential tools/products/workflows: Dataset generation scripts; export to DCC and game engines; volumetric-to-mesh conversion utilities.
- Assumptions/dependencies: Artists/TDs accept voxel+orientation field as an intermediate representation; domain gap to photorealistic pipelines is acknowledged.
- Robotic brushing/cleaning on fibrous media proxies (industry; robotics)
- Transfer the dynamics-planning stack to proxy tasks that mirror localized, strand-like deformation (e.g., grooming fiber mats, maintaining plush displays).
- Potential tools/products/workflows: Re-train dynamics on synthetic proxies; safety cages; simple cylindrical tools.
- Assumptions/dependencies: Similar localized contact behavior; acceptable performance with current perception stack.
- Quality control of styled hairpieces (industry; manufacturing/software)
- Use orientation-field deviations as a quantitative metric for pass/fail QC of style patterns on wigs or extensions.
- Potential tools/products/workflows: Multi-view capture booth; occupancy+orientation reconstruction; threshold-based deviation reports.
- Assumptions/dependencies: Goal state alignment; stable lighting; per-product goal libraries.
- Methodological transfer to other deformables research (academia; robotics/software)
- Apply “action-conditioned state editing” in a pre-trained volumetric latent space to ropes/yarns/cable harnesses where point-wise correspondences are impractical.
- Potential tools/products/workflows: Drop-in replacement of state encoders with rope/cable voxelizers; keep MPPI backbone.
- Assumptions/dependencies: Sufficiently rich synthetic data for each new class of deformables; similar local-deformation statistics.
- Safety and HRI pre-compliance studies (policy/industry; standards/safety)
- Use the system as a controlled testbed to design and test exclusion-zone planning costs near eyes and face; evaluate low-force end-effectors.
- Potential tools/products/workflows: Safety-cost modules that penalize tool poses; soft-tip tool kits; data logs for human-subjects IRB protocols.
- Assumptions/dependencies: No human contact at this stage; mannequin-only tests; well-defined geometry of restricted regions.
- Multi-view 3D perception pipelines for grooming tasks (industry/academia; software/robotics)
- Adopt occupancy+orientation reconstruction as a robust alternative to sparse point clouds for tasks requiring local-flow cues.
- Potential tools/products/workflows: Multi-view capture scripts; calibration utilities; voxel fusion libraries.
- Assumptions/dependencies: Multiple RGB-D viewpoints; stable rigs; rigorous calibration.
Long-Term Applications
These use cases require further research, safety validation, productization, or domain adaptation (e.g., face/eye safety, force control, broader hair types, online head estimation, personalization).
- In-home assistive haircare robots (healthcare/consumer; robotics)
- Fully autonomous hair brushing/styling for people with limited mobility, integrated with soft, compliant end-effectors and force/vision feedback.
- Potential tools/products/workflows: Voice/GUI goal specification (style templates); online head pose estimation; eye/skin safety constraints; personalized hair models.
- Assumptions/dependencies: Regulatory approval for head-near interaction; robust perception in uncontrolled lighting; generalization to diverse hair types (coils, wet hair, products).
- Salon co-robots for stylists (industry; robotics)
- Robots assist with sectioning, detangling, blow-drying trajectories, and maintaining desired flow orientations while a human focuses on cutting/coloring.
- Potential tools/products/workflows: Multi-tool end-effectors (brush/blow-dryer); joint human-robot planning interfaces; appointment-specific style libraries.
- Assumptions/dependencies: Richer action spaces (temperature/airflow); advanced force and slip sensing; ergonomic HRI and liability frameworks.
- Hospital and elder-care deployments (healthcare/policy; robotics)
- Certified grooming systems to reduce caregiver burden while preserving dignity and hygiene of patients/residents.
- Potential tools/products/workflows: FDA/CE pathways; facility integration (sanitation, scheduling); remote monitoring; EMR-linked care routines.
- Assumptions/dependencies: Strict safety and infection-control standards; reimbursement codes; robust handling of cognitive/mobility variability.
- Pet grooming automation (consumer/services; robotics)
- Adapt dynamics modeling and planning to animal fur (varied fiber densities and compliance) for brushing/detangling tasks.
- Potential tools/products/workflows: Fur-specific simulators; animal-safe end-effectors; reward-motivated HRI.
- Assumptions/dependencies: Behavior unpredictability; humane standards; broader sim realism; diverse coat types.
- Personal styling assistants with interactive goals (consumer; AR/VR/robotics)
- User selects a target look in AR; the robot plans and executes steps, with real-time user feedback loops and “undo”/“redo” style edits.
- Potential tools/products/workflows: AR try-on apps tied to robot goals; teleoperation fallback; skill libraries (e.g., parting, smoothing, volume control).
- Assumptions/dependencies: High-quality, privacy-preserving multi-view capture; personalization and hair-history memory; latency constraints.
- Standardization and certification for head-near robotics (policy; standards/safety)
- Develop safety norms, test protocols, and certification criteria for near-face, contact-rich manipulation (force limits, exclusion zones, fail-safes).
- Potential tools/products/workflows: Standard test wigs/mannequins; benchmark scenarios; compliance testing suites.
- Assumptions/dependencies: Consensus across standards bodies; insurer acceptance; incident reporting frameworks.
- Expanded deformable manipulation in manufacturing (industry; robotics)
- Apply volumetric state editing to fiber alignment in composites, cable routing in harness assembly, or controlled fiber layup.
- Potential tools/products/workflows: Domain-specific simulators; path planners with extrusion/placement controls; quality sensors integrating orientation fields.
- Assumptions/dependencies: Accurate domain simulators; integration with existing MES/QA systems; custom tooling.
- Real-time avatar hair with physics-aware editing (media/gaming; software)
- Use the latent volumetric space and action-conditioned editing for interactive, physically plausible hair edits in VR/AR avatars and digital doubles.
- Potential tools/products/workflows: Game-engine plugins; neural operators that map controller gestures to hair edits; latency-optimized inference.
- Assumptions/dependencies: High-performance inference on consumer devices; perception-free or monocular estimation; artist-in-the-loop tuning.
- Consumer countertop grooming stations (consumer/healthcare; robotics)
- Compact, safe devices mounted near a mirror that perform prescribed styling routines for users with limited mobility.
- Potential tools/products/workflows: Enclosed, soft actuation; pre-validated routines; simple UI to choose and adjust goals.
- Assumptions/dependencies: Strong safety guarantees; quiet operation; reliable self-calibration to user head pose.
- Data governance and privacy frameworks for at-home grooming robots (policy; privacy)
- Policies for secure storage and processing of hair/face multi-view data, on-device inference, and consent-based goal libraries.
- Potential tools/products/workflows: Privacy-preserving reconstruction pipelines; on-device models; auditable data logs.
- Assumptions/dependencies: Clear consent mechanisms; regional data-protection compliance (e.g., GDPR/CCPA); user education.
- Smart tool ecosystems (industry; robotics/sensors)
- Sensorized brushes/combs that feed force, vibration, and slip into the dynamics model to improve prediction and safety.
- Potential tools/products/workflows: Tactile arrays; brush-embedded IMUs; closed-loop planners fusing vision and haptics.
- Assumptions/dependencies: Robust sensor integration; calibration with volumetric states; durability and hygiene management.
Notes on cross-cutting dependencies and risks:
- The current system assumes precise calibration, static head pose, and multi-view RGB-D capture; moving targets and uncontrolled lighting require robust online estimation.
- Heuristic twist modeling in the simulator may limit fidelity for tightly coiled/treated/wet hair; domain adaptation or data collection from real hair will be necessary.
- Safety near eyes/skin and force control are not solved in this work; human trials demand certified hardware, soft actuators, and formal safety constraints in planning.
- Real-time performance presumes GPU acceleration; embedded deployment needs model compression/optimization.
Glossary
- Action-conditioned latent state editing mechanism: A neural modeling approach where the latent representation of a state is directly modified based on the input action to predict the next state. "relying on an action-conditioned latent state editing mechanism, coupled with a compact 3D latent space of diverse hairstyles to improve generalizability."
- Chamfer Distance (CD): A geometric metric that measures the average nearest-neighbor distance between two point sets, commonly used to compare predicted and ground-truth shapes. "Chamfer Distance (CD) between predicted and ground-truth point clouds, ignoring orientation."
- Codebook: The discrete set of latent prototype vectors used in vector quantization to encode continuous features into discrete indices. "We use exponential moving averages (EMA) to update codebooks progressively during training."
- ControlNet: A conditioning architecture that adds a parallel control branch to a pre-trained model to guide its outputs with external signals. "Following ControlNet~\cite{zhang_2023_controlnet}, the path employs weight copying, zero-convolution, and cross-path feature fusion mechanisms"
- EMA commitment loss: A VQ-VAE training loss that encourages encoder outputs to commit to selected codebook entries while using EMA to stabilize codebook updates. "we adopt the EMA commitment loss from VQ-VAE~\cite{van2017vqvae}"
- Exponential Moving Average (EMA): A smoothing technique that updates parameters using a weighted average emphasizing recent values, often applied to codebook updates. "We use exponential moving averages (EMA) to update codebooks progressively during training."
- Feature-wise Linear Modulation (FiLM): A conditioning method that modulates intermediate features via learned affine transformations based on auxiliary inputs. "uses a FiLM~\cite{perez2018film}-style state-action fusion mechanism"
- Focal loss: A classification loss that down-weights easy examples and focuses learning on hard, misclassified instances to address class imbalance. "we combine the focal loss~\cite{lin2018focallossdenseobject} and the soft Dice loss"
- Genesis: A GPU-accelerated physics simulation framework used here to build an efficient, contact-rich hair-combing simulator. "based on Genesis~\cite{Genesis_2024}"
- Graph Neural Network (GNN): A neural architecture that operates on graph-structured data using message passing to model interactions among nodes. "applies a GNN-based structure"
- Kirchhoff rod model: A physically accurate elastic rod formulation that captures bending and twisting behavior at strand level. "Kirchhoff rod models~\cite{bergou_2008_discrete, kugelsttadt_2016_pbdcosseraterod}"
- Mass-spring model: A physics simulation method where objects are represented by masses connected by springs to model elasticity. "mass-spring models~\cite{rosenblum_1991_hairsimulate, selle_2008_massspring}"
- Model Predictive Control (MPC): A control strategy that optimizes future actions over a receding horizon using a predictive model of system dynamics. "We adopt a Model Predictive Control (MPC) framework,"
- Model Predictive Path Integral (MPPI): A sampling-based MPC method that uses path integral control to optimize action sequences under stochastic dynamics. "using a Model Predictive Path Integral (MPPI)-based planner"
- Position-Based Dynamics (PBD): A constraint-based simulation technique that directly adjusts positions to satisfy physical constraints, enabling stable and efficient dynamics. "position-based dynamics (PBD) method"
- Strand-level Chamfer Distance (CD): A CD variant computed after reconstructing oriented point clouds into hair strand segments to evaluate structural alignment. "3) : strand-level CD, where predicted point clouds with orientations are reconstructed into strand segments"
- UNet: An encoder-decoder convolutional architecture with skip connections, widely used for dense prediction in images and volumes. "uses a UNet-based architecture"
- Vector Quantization (VQ): The process of mapping continuous latent vectors to discrete codebook entries to form compressed representations. "with vector quantization enables compact compression while preserving detailed representation capability."
- VQ-VAE-2: A hierarchical variant of Vector-Quantized Variational Autoencoder that uses multi-level codebooks for richer global and local representations. "analogous to VQ-VAE-2~\cite{razavi2019vqvae2}"
- Volumetric occupancy grid: A voxel-based 3D representation that encodes whether each cell is occupied, often paired with additional fields like orientation. "volumetric occupancy grid with a 3D orientation field"
- Zero-convolution: A training stabilization technique where convolutional layers are initialized with zero weights so they gradually learn to contribute. "zero-convolution; copy: weight copying for initialization;"
- Zero-shot transferability: The ability of a model or system to perform well on new, unseen domains or tasks without additional training. "Real-world experiments exhibit zero-shot transferability of our system to wigs,"
Collections
Sign up for free to add this paper to one or more collections.