SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning (2511.08151v1)
Abstract: Recent advances in LLMs have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning”
Overview
This paper introduces SciAgent, a smart AI “team” designed to solve tough science problems from different subjects—like math, physics, and chemistry—at a very high level. Instead of being built just for one type of test or topic, SciAgent can change how it thinks and works depending on the problem. The big idea is to make an AI that can reason like a skilled scientist across many fields, not just one.
Key Objectives and Questions
The paper focuses on a few simple goals:
- Can one AI system adapt its problem-solving style to handle different subjects and difficulty levels without being rebuilt for each case?
- Can this system organize its thinking like a team—planning, solving, checking, and fixing its work—to reach gold-medal performance on real Olympiad exams?
- Does it work not only in math and physics but also in chemistry and other general science questions?
How SciAgent Works (Methods and Approach)
Think of SciAgent like a well-run science lab with a coach and several specialist teams:
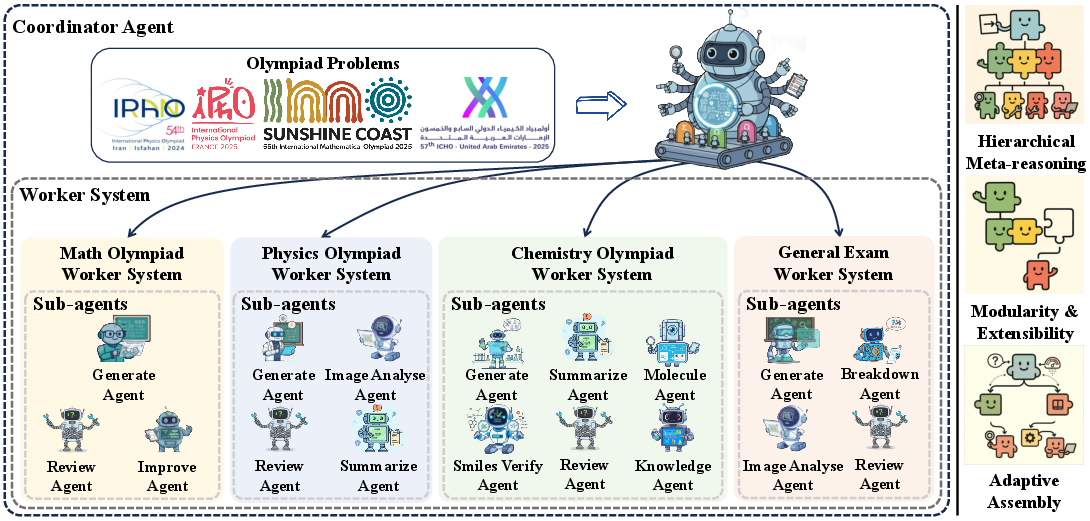
- The “coach” is the Coordinator Agent. It reads the problem, figures out the subject (math, physics, chemistry, or general science), estimates how hard it is, and then sends it to the right specialist team.
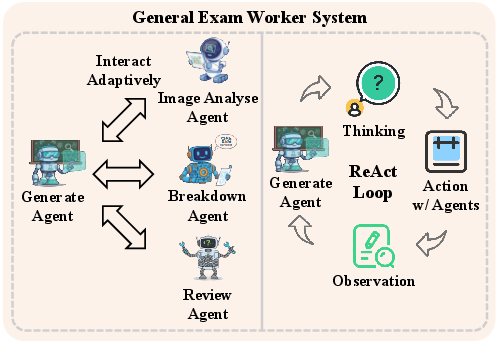
- The specialist teams are called Worker Systems. There are different Workers for different subjects (for example, Math Worker, Physics Worker, Chemistry Worker, and a General Exam Worker). Each Worker knows the typical tricks and tools for that subject.
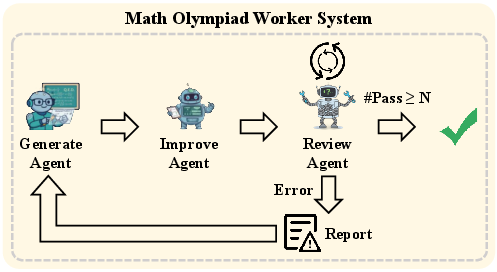
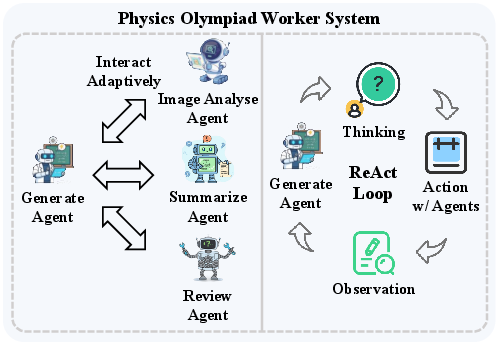
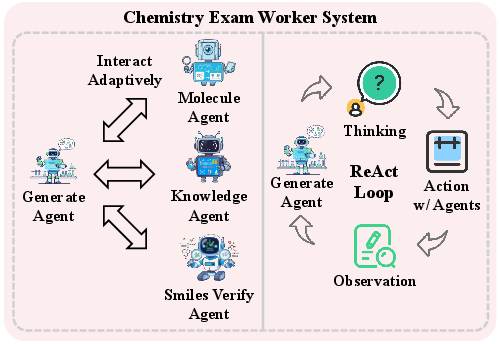
- Inside each Worker are Sub-agents—the “specialists.” Some write the first solution (Generator), some improve it (Improver), some check diagrams or images (Image Analyser), some verify the logic and calculations (Reviewer), and some neatly summarize the final answer (Summarizer). In chemistry, there are extra helpers for understanding molecules and checking chemical formats.
Here’s how the thinking happens:
- Hierarchical planning: The Coordinator decides what kind of reasoning is needed (symbolic math, conceptual physics, or chemical modeling), and the Worker builds a plan.
- Adaptive pipeline: The Sub-agents work together in loops—like a “think–act–check” cycle—where they create a solution, test it, spot mistakes, and fix them. This repeats until the answer is consistent and correct.
- Modularity: New subjects or tools can be added by creating new Workers or Sub-agents without breaking the rest of the system.
Simple analogy:
- Coordinator = team captain who assigns the right specialists.
- Worker Systems = subject-specific squads (math squad, physics squad, etc.).
- Sub-agents = teammates with different skills (solver, checker, visual interpreter, summarizer).
- Reasoning loop = practice–review–improve cycle, just like preparing for a competition.
The system is powered by LLMs, which are computer programs trained to read, reason, and write like a very advanced tutor. The paper mainly uses Google’s Gemini 2.5 Pro, but the setup can work with other LLMs too.
Main Findings and Why They Matter
Here are the main results the authors report, explained simply:
- Math Olympiads:
- IMO 2025: SciAgent scored 36 out of 42—above the average gold medalist score.
- IMC 2025: SciAgent got a perfect 100, matching the top human score.
- Physics Olympiads:
- IPhO 2024: SciAgent scored 27.6/30—higher than the average gold medalist.
- IPhO 2025: SciAgent scored 25.0/30—again above the average gold medalist.
- CPhO 2025: SciAgent scored 264/320—well above the reported gold medalist score.
- Chemistry and General Science:
- SciAgent was tested on problems from the International Chemistry Olympiad (IChO) and a hard, mixed-subject benchmark called Humanity’s Last Exam (HLE). It showed it could handle chemistry tasks (like understanding molecules) and general science questions, though chemistry is still a work in progress.
- Fair scoring:
- The authors used official competition rules and had AI grading checked by human experts to keep scoring accurate.
Why this is important:
- Most previous AI systems were built for one subject or one kind of test. SciAgent shows an AI can learn to coordinate different reasoning styles and still reach elite-level performance.
- It’s a step toward AI that thinks flexibly—like a scientist—rather than just following fixed scripts.
Implications and Potential Impact
If AI can reliably reason across different scientific fields, it could:
- Help students learn problem-solving by showing clear, step-by-step reasoning and self-correction.
- Assist teachers and coaches in creating explanations, checking solutions, and designing practice materials.
- Support scientists with early-stage modeling, calculation, and error-checking across multiple disciplines.
- Push AI research toward systems that “think about thinking”—planning, verifying, and adapting like human teams.
Limitations and next steps:
- Chemistry and biology Olympiad data are harder to compare because public scoring info is limited or temporarily unavailable, so the paper focuses more on math and physics.
- Future work will improve the chemistry and biology Workers, expand tools, and test more diverse problems to make SciAgent even more general and trustworthy.
In short, SciAgent is like a smart captain leading a multi-subject team, able to change strategies and work styles to solve tough problems—and it’s already performing at gold-medal levels in several real competitions.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it:
- Evaluation relies on AI-based grading with post hoc “human verification”; design and report a fully independent, double‑blind human scoring protocol, inter‑rater reliability (e.g., Cohen’s κ), and discrepancies between AI and human graders.
- No contamination control for LLM training data; establish provenance checks to ensure problems post-date model training, use leak‑resistant splits, and add retrieval‑blocked, newly authored tests to validate true generalization.
- Results are single‑run; report robustness across seeds, sampling temperatures, and agent iteration budgets (mean, variance, confidence intervals) to assess stability and reproducibility.
- Compute and efficiency are unreported; measure wall‑clock time, token usage, tool‑call counts, memory footprint, and monetary cost per problem, and analyze how these scale with difficulty and modality.
- Absence of ablation studies; isolate contributions of the Coordinator vs. Worker vs. Sub‑agents, ReAct vs. reasoning‑review loops, number of review passes (), and specific tools to quantify where gains originate.
- Coordinator routing accuracy is not evaluated; quantify domain/modality misrouting rates, their impact on score, and whether routing improves via learning (e.g., RL, bandits) rather than heuristic rules.
- Formal verification is limited; integrate theorem provers (Lean/Coq), symbolic checkers (SAT/SMT), and physics verifiers (dimensional/unit consistency) and measure effects on correctness and partial credit.
- Physics evaluation covers theory only; design benchmarks that include experimental reasoning, uncertainty propagation, error analysis, and data noise to reflect full IPhO/real‑lab conditions.
- Chemistry Worker lacks quantitative benchmarking; build an open, rubric‑aligned dataset with accessible baselines (e.g., reaction prediction, stoichiometry, spectroscopy interpretation) and report accuracy, validity of SMILES, and mechanism plausibility.
- Biology capability is anecdotal; develop a dedicated Biology Worker (histopathology, genetics, systems biology) and, post blackout, conduct quantitative evaluation on IBO‑style tasks with image analysis metrics.
- Image Analyser Agent is underspecified; report OCR accuracy, diagram parsing reliability, unit recognition, graph reading, and robustness to varied image quality and formatting.
- Toolchain transparency is limited; document all external tools (CAS, solvers, plotting, simulators), code execution environment and sandboxing, and quantify tool correctness and failure rates.
- Long‑context and memory handling are unclear; implement and evaluate memory folding, episodic retrieval, and context management strategies to prevent saturation (especially in math proofs).
- Generalization beyond Olympiad formats is untested; add tasks in experimental design, paper comprehension, data analysis, and open‑ended research reasoning to test domain transfer to real scientific workflows.
- Safety, bias, and misuse are not addressed; establish guardrails for chemical synthesis recommendations, biological image interpretations, and high‑stakes outputs, with an error‑escalation/abstention policy.
- Comparative baselines are sparse; run head‑to‑head against strong single‑agent systems and contemporary multi‑agent frameworks under identical conditions to contextualize gains.
- Domain extensibility claim lacks empirical demonstration; add a truly new domain Worker (e.g., geology or astronomy) with minimal manual engineering and measure the integration overhead and performance lift.
- Human‑like constraints are not considered; evaluate under time limits, restricted tools, and resource caps to reflect Olympiad conditions and to compare fairly to human performance.
- Handling of ambiguous, incomplete, or noisy problems is untested; assess meta‑reasoning for assumption management, problem clarification, and uncertainty resolution.
- Adaptive pipeline assembly lacks algorithmic detail; specify policies for agent instantiation/termination, feedback thresholds, and stopping criteria, and evaluate learned vs. heuristic assembly strategies.
- Coordinator learning is unspecified; explore data‑driven routing (supervised or RL), measure sample efficiency, and test whether learned policies outperform static heuristics.
- Dataset selection and coverage transparency are limited; publish the full task lists, selection criteria, and a randomized sampling protocol to mitigate cherry‑picking concerns.
- Error taxonomy is missing; provide a systematic analysis of failures (logical gaps, algebraic mistakes, modeling errors, perception errors), their frequencies, and targeted fixes.
- Reproducibility depends on closed LLMs; report performance across open‑weight models (e.g., Llama, Mistral) and quantify the architecture’s dependence on backbone capabilities.
- Multilingual generalization is unaddressed; evaluate on non‑English problem statements and mixed‑language images to test real Olympiad diversity and translation effects.
- Uncertainty calibration is absent; add confidence scoring, verification‑aware abstention, and post‑hoc calibration, and correlate confidence with actual correctness.
- Architectural vs. backbone effects are confounded; run identical agent configurations across multiple LLMs (Gemini, GPT‑5, Llama) to disentangle architecture gains from model strength.
- Inter‑agent communication protocols are opaque; formalize message schemas, critique policies, and escalation rules, and test how protocol variations affect coherence and performance.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging SciAgent’s demonstrated performance and architecture (Coordinator–Worker–Sub-agents, adaptive pipelines, ReAct loops for multimodal tasks, and structured reasoning–review for formal proof-like domains).
- EdTech (education): Olympiad-level STEM tutoring and practice
- Use case: Personalized step-by-step coaching for math and physics; problem decomposition and solution review; competitive exam preparation (IMO, IMC, IPhO).
- Tools/products/workflows: “Olympiad Coach” (Math Worker + Reviewer), “General Exam Tutor” (General Exam Worker).
- Assumptions/dependencies: Access to high-quality LLMs; robust rubric-aligned evaluation; guardrails to prevent answer-only shortcuts; content licensing.
- Academic assessment: Automated grading and formative feedback for STEM coursework
- Use case: Autograding proofs, derivations, and multi-part STEM problems with transparent step-checking and reviewer feedback loops.
- Tools/products/workflows: “STEM Autograder” (Generate–Review–Improve loop); LMS plugin with configurable rubrics; AI-based scoring with human verification (mirroring the paper’s evaluation method).
- Assumptions/dependencies: Instructor-provided rubrics; human-in-the-loop verification for fairness and reliability; data privacy compliance.
- Research co-pilot (academia/industry): Equation derivation, consistency checks, and model validation
- Use case: Assisting researchers and engineers to derive governing equations, check dimensional/units consistency, verify assumptions, and summarize result chains.
- Tools/products/workflows: “Derivation Assistant” for Jupyter/LaTeX; Reviewer Agent for physical consistency; Summarizer Agent for structured outputs.
- Assumptions/dependencies: Integration with CAS tools (e.g., SymPy), domain libraries, and versioned notebooks; proper citation and reproducibility logging.
- Lab data interpretation (industry/academia): Diagram/graph-to-equation workflows
- Use case: Extract quantitative parameters from plots/diagrams; convert visuals to structured equations; compute derived quantities; sanity-check results.
- Tools/products/workflows: “Diagram-to-Equation” using Image Analyser + Generator; Physics Worker ReAct loops; report-ready summaries.
- Assumptions/dependencies: Reliable multimodal perception; calibration to lab data formats; image quality; compute resources for iterative refinement.
- Cheminformatics support (industry): Reaction feasibility pre-screening and structure validation
- Use case: SMILES verification; stoichiometry checks; preliminary mechanism reasoning; flagging inconsistencies before detailed DFT/simulation.
- Tools/products/workflows: “ChemSMILES Validator” (Smiles Verify Agent + Molecule Recognition Agent); “Reaction Sanity Check” (Review + Chemistry Knowledge Agents).
- Assumptions/dependencies: RDKit/cheminformatics integration; access to reaction databases; careful handling of edge cases; not a substitute for experimental validation.
- Technical documentation QA (industry/academia): Proof and calculation verification in manuals, reports, and specs
- Use case: Cross-check derivations, evaluate intermediate steps, ensure internal consistency of technical documentation.
- Tools/products/workflows: “ProofReviewer” (Math Worker reasoning–review loop); structured discrepancy reports and fix suggestions.
- Assumptions/dependencies: Domain coverage and formalization levels; standardized documentation formats; human oversight for sign-off.
- Engineering support (software/energy/robotics): Targeted physics/math problem solving from schematics
- Use case: Circuit analysis (e.g., Thevenin equivalents), mechanical system calculations, parameter estimations from diagrams.
- Tools/products/workflows: “Physics Assistant” (Generator + Image Analyser + Review); spreadsheet/CAE integration.
- Assumptions/dependencies: Clear schematics; integration with SPICE/CAE tools; confidence thresholds and fallback escalation.
- Helpdesk triage for technical queries (software/enterprise knowledge management)
- Use case: Coordinator Agent routes incoming technical questions to the right Worker (math, physics, chemistry), assembling appropriate pipelines automatically.
- Tools/products/workflows: “Coordinator Router” microservice; domain tagging and adaptive routing; traceable reasoning chains.
- Assumptions/dependencies: Accurate domain inference; safe fallbacks; audit trails; privacy/security controls.
Long-Term Applications
These applications require further research, scaling, integration with external systems, formal guarantees, or policy/regulatory frameworks.
- Autonomous cross-disciplinary scientific co-discovery (academia/industry R&D)
- Use case: Propose experiments, design models, run simulations, and iterate with verification; close the loop with robotic lab systems.
- Tools/products/workflows: “AI Lab Partner” (Coordinator + multi-domain Workers) integrated with ELNs, LIMS, robotics; autonomous hypothesis generation and validation.
- Assumptions/dependencies: Reliable toolchains (simulation, lab automation), safety and ethics protocols, provenance tracking, supervisory controls.
- Machine-checkable formal proofs at scale (academia/software)
- Use case: Convert human-readable proofs into machine-verifiable formats; co-pilot for theorem proving and proof audits.
- Tools/products/workflows: “LeanBridge/IsabelleBridge” integrating Math Worker with formal proof assistants; automated lemma discovery and refactoring.
- Assumptions/dependencies: Robust proof translation; alignment between natural language and formal systems; community-standard libraries.
- Industrial process optimization (energy/chemicals/manufacturing)
- Use case: End-to-end agent pipelines for process design, parameter tuning, safety checks, and optimization using simulation suites.
- Tools/products/workflows: “Process Reasoning Agent” integrated with Aspen/COMSOL/Modelica; Reviewer Agents with constraint/safety verification.
- Assumptions/dependencies: High-fidelity models and plant data; domain-specific simulators; regulatory compliance; continuous monitoring.
- Regulatory-grade STEM assessment and certification (policy/education)
- Use case: Standardized AI-assisted graders for national exams and certifications with interpretability and auditability.
- Tools/products/workflows: “Standards-Compliant AI Grader” with rubric alignment, explainable scoring, bias audits, and human oversight.
- Assumptions/dependencies: Policy frameworks, transparency standards, appeals mechanisms, robust adversarial testing.
- Journal peer-review augmentation (academic publishing)
- Use case: Automated cross-modal verification of derivations, figures, and reported numbers; integrity checks.
- Tools/products/workflows: “Manuscript Consistency Checker” (Reviewer + Image Analyser + Summarizer); integration into editorial workflows.
- Assumptions/dependencies: Access to submission artifacts (data/code/figures), reproducibility standards, author consent.
- Safety-critical engineering design assistance (aerospace/automotive/energy)
- Use case: Co-design with formal verification; multi-agent pipelines produce traceable, testable artifacts for certification.
- Tools/products/workflows: “Design Verifier” integrating Workers with formal methods, simulators, and requirements management tools.
- Assumptions/dependencies: Certification pathways; formal guarantees; high assurance tooling; stringent QA and governance.
- Healthcare and biomed reasoning (clinical/biopharma)
- Use case: Extending chemistry and biology Workers to drug discovery, pathway modeling, and diagnostic reasoning with imaging.
- Tools/products/workflows: “ChemBio Reasoner” with RDKit, bioinformatics suites, and medical imaging analyzers; hypothesis generation and validation.
- Assumptions/dependencies: Regulatory constraints (HIPAA, GDPR), validated medical datasets, clinical oversight, domain-specific evaluation benchmarks.
- Robotics planning with physics-aware reasoning (robotics/automation)
- Use case: Hierarchical task planning informed by physical modeling; perception-to-action pipelines with verification loops.
- Tools/products/workflows: “Physics-aware Planner” combining Image Analyser, Generator, and Review Agents with real-time control stacks.
- Assumptions/dependencies: Low-latency inference; sensor fusion; robust simulation-to-reality transfer; safety constraints.
- Quantitative risk modeling (finance)
- Use case: Transparent multi-agent math reasoning for portfolio risk, derivatives pricing, and stress testing with reviewer-backed logic checks.
- Tools/products/workflows: “Quant Reasoning Assistant” (Math Worker + Reviewer); integration with data pipelines and compliance auditing.
- Assumptions/dependencies: High-quality market data; explainability requirements; regulatory compliance; domain calibration.
- Persistent, evolving memory for scientific agents (software/knowledge management)
- Use case: Long-horizon learning across problems, retaining patterns, solutions, and tool usage for continual improvement.
- Tools/products/workflows: “SciAgent Memory” service for episodic/semantic recall, curriculum learning, and retrieval-augmented pipelines.
- Assumptions/dependencies: Privacy-preserving storage, catastrophic forgetting mitigation, knowledge curation, version control.
Glossary
- Adaptive pipeline assembly: Dynamically assembling multi-stage reasoning pipelines tailored to a task within a worker. "Adaptive pipeline assembly. Within each Worker, reasoning unfolds through dynamically assembled multi-stage pipelines."
- AgentFrontier’s ZPD Exam: A benchmark that composes tasks solvable with tools but not unaided, to assess agent planning and synthesis. "AgentFrontier’s ZPD Exam dynamically composes tasks unsolved unaided but solvable with tools, directly measuring agentic planning and cross-document synthesis"
- Agentic planning: Strategic decision-making by autonomous agents to achieve goals via tools and information synthesis. "directly measuring agentic planning and cross-document synthesis"
- Autonomous memory folding: Automatically compressing interaction histories into compact memories for long-horizon agents. "long-horizon agents like DeepAgent compress interaction histories via autonomous memory folding"
- Closed-ended, retrieval-resistant questions: Problems designed to have definitive answers that cannot be solved via simple retrieval. "Humanity’s Last Exam curates closed-ended, retrieval-resistant questions that remain hard for SOTA models"
- Co-evolutionary multi-agent frameworks: Agent systems that evolve alongside domain-specific tools to improve performance. "co-evolutionary multi-agent frameworks equip domain tools such as diagram interpreters and verifiers"
- Conceptual modeling: Building abstract representations of systems or phenomena to guide reasoning and derivation. "encompassing symbolic deduction, conceptual modeling, and numerical simulation under a unified architecture"
- Coordinator Agent: The meta-level controller that interprets domain and difficulty and routes tasks to the right specialists. "a Coordinator Agent interprets each problem’s domain and complexity, dynamically orchestrating specialized Worker Systems"
- Coordinator–Worker–Sub-agents hierarchy: A layered architecture separating meta-control, domain specialization, and execution. "We propose a Coordinator–Worker–Sub-agents hierarchy in which the Coordinator performs domain-adaptive routing"
- Critique–revision loops: Iterative cycles where agents critique intermediate results and revise them toward correctness. "structured message passing and critique–revision loops"
- Cross-paradigm adaptation: The ability to transfer reasoning strategies across different scientific domains and problem types. "lack mechanisms for cross-paradigm adaptation"
- Domain-adaptive routing: Selecting and dispatching tasks to domain-appropriate worker systems based on problem analysis. "the Coordinator performs domain-adaptive routing"
- Enantioselective synthesis: Chemical synthesis that preferentially produces one enantiomer over its mirror image. "the enantioselective synthesis of (-)-Maocrystal V"
- Feedback-driven reasoning loops: Cycles where feedback is used to refine and converge multi-stage reasoning. "self-assembling, feedback-driven reasoning loops that integrate symbolic deduction, conceptual modeling, and quantitative computation"
- Generalistic scientific reasoning: A paradigm emphasizing adaptable, cross-domain reasoning without bespoke redesigns. "We introduce generalistic scientific reasoning as a new paradigm for AI in science, emphasizing adaptability across domains and modalities."
- Glomerular sclerosis: Scarring of the kidney’s glomeruli, identifiable in histopathological analysis. "identify glomerular sclerosis and other lesions"
- Hidden Markov model (HMM): A probabilistic model with hidden states governing observable sequences. "calculates the log probability of a sequence in a hidden Markov model (HMM)"
- Humanity’s Last Exam (HLE): A benchmark of frontier-hard, retrieval-resistant scientific questions. "selected problems from the Humanity’s Last Exam (HLE) benchmark"
- Image Analyser Agent: A specialized sub-agent that interprets visual data such as diagrams and graphs. "a Generator Agent, an Image Analyser Agent, a Reviewer Agent, and a Summarizer Agent"
- International Chemistry Olympiad (IChO): A global competition featuring advanced chemistry problem-solving. "International Chemistry Olympiad (IChO)"
- International Mathematical Olympiad (IMO): A premier international competition in high-level mathematics. "International Mathematical Olympiad (IMO 2025)"
- International Mathematics Competition (IMC): A university-level mathematics competition assessing diverse problem-solving. "International Mathematics Competition (IMC 2025)"
- International Physics Olympiad (IPhO): A global competition focusing on theoretical and experimental physics. "International Physics Olympiad (IPhO 2024, IPhO 2025)"
- LLM evaluator: A LLM used to score and review solutions against official criteria. "an LLM evaluator receives both the official standard answer"
- Meta-control layer: An explicit control mechanism that governs which strategies and workers are invoked. "This explicit meta-control layer enables SciAgent to generalize across domains and difficulty levels"
- Meta-reasoning: Reasoning about which reasoning strategies or toolchains to apply to a given task. "it lacks a mechanism for meta-reasoning—deciding which reasoning style or toolchain suits a given task"
- Modality: The form or type of information and representation (e.g., symbolic, numerical, visual). "problem’s structure and modality"
- Model-agnostic pipelines: Reasoning processes that do not depend on a specific underlying model architecture. "model-agnostic pipelines iterate generation, critique, and repair to attain proof-level soundness"
- Molecule Recognition Agent: A sub-agent that identifies and interprets molecular structures from text or images. "The Molecule Recognition Agent interprets molecular structures from textual or visual data"
- Multimodal: Involving multiple input or representation types (e.g., text and images) in reasoning. "physics problems are inherently multimodal and step-decomposable"
- Numerical simulation: Using computational numerical methods to model and analyze scientific phenomena. "numerical simulation under a unified architecture"
- Parametric vs. tool-augmented competence: Distinguishing model-internal capabilities from those enabled by external tools. "blur parametric vs.\ tool-augmented competence"
- Perceptual grounding: Anchoring reasoning in interpreted perceptual inputs like images or diagrams. "provides perceptual grounding by interpreting visual inputs such as graphs, tables, or diagrams"
- Proof synthesis: Automated construction of mathematically rigorous proofs. "approach mathematical proof synthesis, physical modeling, and general scientific question answering"
- ReAct framework: A reasoning paradigm combining Thought, Action, and Observation in iterative loops. "ReAct frameworks—which combine Thought, Action, and Observation cycles—are widely adopted"
- Reinforcement learning (RL): A learning paradigm where agents optimize behavior via rewards. "ARTIST uses RL to learn when/how to invoke tools"
- SMILES (Simplified Molecular Input Line Entry System): A textual notation encoding molecular structure. "SMILES (Simplified Molecular Input Line Entry System) notation"
- Step-decomposable: A property of problems that can be broken into sequentially solvable steps. "inherently multimodal and step-decomposable"
- Stoichiometric analysis: Quantitative analysis of reactant-product relationships in chemical reactions. "chemical reaction modeling, stoichiometric analysis, and experimental data interpretation"
- Structured message passing: Formalized communication among agents to share intermediate results and critiques. "structured message passing and critique–revision loops"
- Summarizer Agent: A sub-agent that consolidates reasoning outputs into structured answers. "a Summarizer Agent"
- Thevenin’s Theorem: An electrical engineering theorem reducing networks to equivalent sources for analysis. "applies Thevenin’s Theorem to analyze an electrical circuit"
- Toolchains: Ordered sets of tools and processes used to carry out complex tasks. "fixed toolchains that cannot transfer across domains"
- Worker System: A domain-specialized multi-agent subsystem that assembles and manages internal pipelines. "Worker Systems are at the core of SciAgent’s problem-solving capabilities."
Collections
Sign up for free to add this paper to one or more collections.