- The paper presents DeToxR, a reinforcement learning–aligned LLM designed to enhance diagnostic reasoning for poly-substance intoxication in emergency settings.
- It integrates heterogeneous data—including structured metrics and unstructured narratives—using a GRPO approach that optimizes both F1 performance and output interpretability.
- Empirical results reveal that DeToxR outperforms classical ML models and expert toxicologists in recall and overall diagnostic accuracy while providing transparent reasoning.
DeToxR: Reinforcement Learning–Aligned LLMs for Diagnostic Reasoning in Clinical Toxicology
Introduction
The clinical management of acute poly-substance intoxication in emergency departments is challenged by uncertainty and the necessity to synthesize heterogeneous data sources, including structured medical variables and unstructured textual narratives. Prior computational approaches—ranging from probabilistic logic frameworks to DNNs and GNNs—have been restricted mainly to structured data, failing to exploit the rich, unstructured inputs available in real-world cases. LLMs potentially close this modality gap, yet exhibit suboptimal performance under the ambiguity and class imbalance characteristic of emergency toxicology. This work introduces DeToxR, a reinforcement learning (RL)–aligned LLM utilizing Group Relative Policy Optimization (GRPO), and delivers a thorough empirical and clinical validation for poly-intoxication decision support.
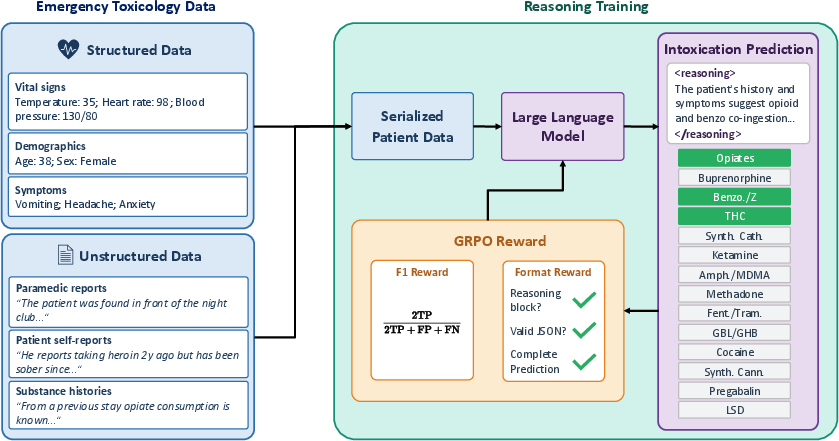
Figure 1: The DeToxR framework fuses heterogeneous emergency data and prompts an LLM for diagnostic reasoning and multi-label toxin prediction, utilizing a GRPO approach with F1 and format rewards.
Methodology
DeToxR formalizes the diagnostic prediction of poly-substance intoxication as a multi-label classification problem across K=14 toxin classes. It serializes all case evidence—demographics, vital signs, binary indicators, symptoms, paramedic and patient histories, physical examination notes, and ECG findings—into a structured Markdown prompt. The prompt integrates both structured and free-text data, accommodating missing values and ensuring explicit representation of all available clinical and non-clinical information. Substance histories, when available, are included as bullet lists; unprocessed text constitutes dedicated prompt sections.
Output Schema and Alignment Objectives
Model outputs consist of a diagnostic reasoning trace, encapsulated within <reasoning> tags, followed by a binary prediction JSON over all substance classes. This structured output supports both clinical interpretability and programmatic evaluation.
The GRPO RL finetuning pipeline explicitly optimizes the model for sample-level F1 score, accounting for both false negatives (missed toxin classes) and false positives (hallucinated poisons), and a format reward enforcing output validity and rationales. The composite reward balances clinical and operational objectives, penalizing both absence and hallucination of key findings—a critical criterion in poly-intoxication contexts.
Reinforcement Learning Procedure
DeToxR employs GRPO with DAPO loss aggregation and sequence-level importance sampling, incorporating LoRA for parameter efficiency. Reward ablations demonstrate the superiority of the F1-based metric over alternatives such as Intersection-over-Union (IoU), emphasizing empirically the necessity for task-specific reward design.
Experimental Results
Quantitative Benchmarking
Evaluation uses a dataset of 870 real-world poly-intoxication cases. Baselines span history-only heuristics, classical ML models (MLP, XGBoost), zero-shot and SFT-finetuned LLMs, and the full DeToxR pipeline.
DeToxR achieves micro-F1 of 63.7% and macro-F1 of 59.9%, surpassing all classical and parametric baselines, as well as advanced zero-shot LLMs (which cluster below 53% micro-F1). Compared to SFT-finetuned LLMs on matched architectures, DeToxR demonstrates a substantial F1 and recall improvement (micro-recall: 63.9% vs. 52.3%), at a modest cost to precision. This validates the clinical utility of RL-aligned objectives over standard supervised protocols in sparse, heterogeneous, and multi-label domains.
Clinical Expert Comparison
In head-to-head validation, DeToxR outweighs an experienced clinical toxicologist in identifying correct poisoning labels (micro-F1: 0.644, macro-F1: 0.488 vs. expert micro-F1: 0.473, macro-F1: 0.398). DeToxR identifies correct toxins in 19 cases missed by the expert, while missing only 3 that the expert found. The toxicologist’s higher precision reflects a conservative diagnostic style, whereas DeToxR’s higher recall captures the critical need for sensitivity in emergent care, albeit at a minor increase in false positives.
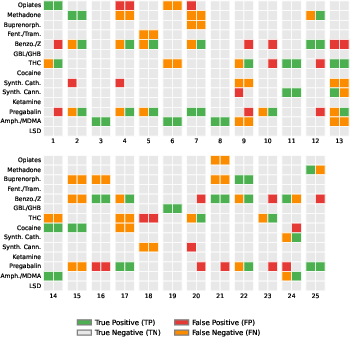
Figure 2: Side-by-side case results for DeToxR and an expert toxicologist over 25 randomly sampled cases; DeToxR demonstrates higher recall and perfect agreement in more cases.
Reward and Architecture Ablations
Switching from F1 to IoU reward formulations results in a performance drop (micro-F1: 61.1% vs. 63.7%), underscoring the impact of reward engineering. Extending the GRPO protocol to alternative LLM backbones (e.g., Llama 3.2 3B) produces similar performance improvements over the base models, demonstrating the transferability of the RL alignment strategy independent of LLM family.
Qualitative Analysis of Model Reasoning
Inspection of model-generated reasoning traces reveals high-fidelity clinical argumentation, including accurate identification of supporting evidence and pathophysiological rationale. Occasional hallucinations, where model rationales invent clinical findings not present in the input to support predictions, echo limitations familiar in generative LLMs, even under RL penalization schemes.
Implications and Future Directions
The successful integration of RL-aligned LLMs into emergency toxicology establishes several theoretical and practical precedents. Technically, it demonstrates that sequence-level, task-aware RL finetuning (here via GRPO with a domain-focused F1 prize) instills diagnostic behavior outperforming both domain-expert heuristics and generic SFT-LLMs, particularly in settings of multi-modal, sparse, and high-stakes data. The inclusion of unstructured, non-medical text elevates result synthesis beyond the restrictive boundaries of prior ML applications constrained to structured variables.
Practically, DeToxR implies immediate pathways for LLM-based clinical decision support systems capable of fusing incomplete histories, sensor data, and free-form narratives. Such systems are naturally extensible to other diagnostic domains marked by data heterogeneity and the demand for transparent, auditable reasoning.
Given the observed hallucination tendencies, future research should prioritize tighter integration of reward signals penalizing unsupported rationales, possibly through attribution-based or retrieval-verified reward components. Larger-scale clinical validation with diverse cohorts, as well as multi-expert consensus evaluations, will be essential for credentialing such systems for routine use. Notably, the RL-finetuning paradigm can be systematically explored beyond toxicology—for instance, in multi-pathology differentials, rare disease detection, or cross-disciplinary triage.
Conclusion
DeToxR represents a substantive advance in clinical AI, leveraging RL-based finetuning to operationalize LLMs for poly-toxicology diagnosis by unifying heterogeneous narratives with structured data. Its empirical dominance over established ML benchmarks and clinical practitioners establishes a new standard for decision support in high-uncertainty medical environments. The generality of the GRPO-based RL alignment invites rapid adoption and exploration in other demanding, multimodal, and safety-critical domains.

