- The paper introduces MMAE, integrating teacher-student self-distillation with flow-mixing to overcome isolated, byte-level limitations in conventional MAEs.
- MMAE employs a packet-importance aware masking strategy that dynamically targets semantically rich regions, thereby reducing reconstruction losses.
- Empirical results on diverse datasets demonstrate that MMAE outperforms state-of-the-art models with notable improvements in F1 scores and computational efficiency.
Mean Masked Autoencoder with Flow-Mixing and Self-Distillation for Encrypted Traffic Classification
Introduction
Encrypted traffic classification presents unique challenges due to the increasing adoption of sophisticated encryption schemes, highly dynamic application semantics, and the obfuscation of payload content. Recent advances in self-supervised representation learning, particularly Masked Autoencoders (MAEs), have demonstrated enhanced flexibility in feature extraction from raw traffic. However, conventional MAEs are inherently limited by their isolated, byte-level reconstruction strategies, resulting in under-exploited multi-granularity information. This work introduces Mean Masked Autoencoder (MMAE), which synergizes teacher-student paradigm, cross-flow mixing, and adversarial masking based on packet importance to advance encrypted traffic classification.
Motivation and Limitations of Standard MAEs
Standard MAEs reconstruct randomly masked bytes within individual flows, which only weakly captures the hierarchical and multi-scale nature of network traffic semantics. Empirical evaluation demonstrates that introducing a self-distillation teacher, providing unmasked flow-level supervision, enhances the rate and extent of loss minimization during pre-training, as exhibited by systematically lower reconstruction losses compared to the vanilla MAE.
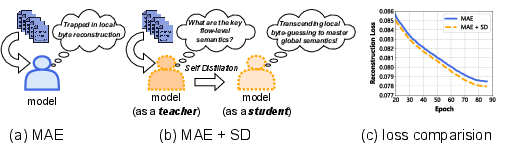
Figure 1: Comparison of reconstruction loss during pre-training between MAE and its variant with Self-Distillation strategy (MAE+SD). By introducing flow-level semantics via SD, the loss is consistently lower.
These findings substantiate that simply relying on random byte masking within isolated flows is insufficient for harnessing contextual dependencies intrinsic to network traffic, thereby necessitating a paradigmatic shift toward cross-flow, multi-granularity learning.
MMAE Framework and Architectural Innovations
MMAE is predicated upon a teacher-student dual MAE architecture, where the teacher branch (an exponential moving average copy of the student) provides unmasked flow-level semantic supervision. The core training signal combines the typical reconstruction loss with a semantic alignment loss (forcing the student's unmixed representation to be similar to the teacher's global view) and a mask prediction loss for guiding dynamic masking.
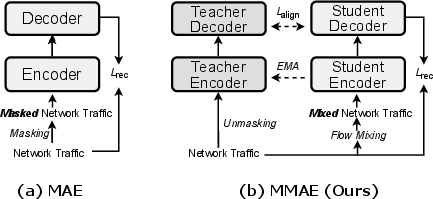
Figure 2: Comparison of pre-training paradigms: (a) Standard MAE with random masking in a single flow; (b) MMAE with teacher-student, flow-mixing, and self-distillation.
Flow-Mixing (FlowMix) Strategy
To break the information bottleneck intrinsic to single flows, MMAE introduces FlowMix, which generates challenging pretext tasks via cross-flow patch mixing. It utilizes a Statistics-based Flow Matcher (SFM) exploiting 27 physical side-channel features (e.g., inter-packet timing, payload lengths, protocol flags) to pair physically similar flows. Within chosen regions of semantic density, identified by a Packet-importance aware Mask Predictor (PMP), byte patches from a support flow are swapped into the main flow. This engineered interference encourages the student to disentangle overlapping physical attributes and thus learn more robust, discriminative representations.
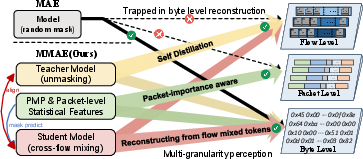
Figure 3: Comparison of hierarchical semantic extraction capabilities: MAE only leverages single-flow, random masking, whereas MMAE integrates cross-flow mixing and packet-level statistical features within the teacher-student framework.
Packet-importance aware Mask Predictor (PMP)
PMP dynamically predicts which tokens contain the highest semantic density by leveraging convolutional encodings of side-channel features (packet sizes/times), token similarity and saliency, producing a low-rank bias injected into the attention mechanism of the student encoder. Mask regions are chosen based on difficulty ranking, with the mask ratio adaptively modulated via curriculum scheduling. This design ensures that the masking process targets non-trivial, information-rich regions, maximizing pre-training informativeness.
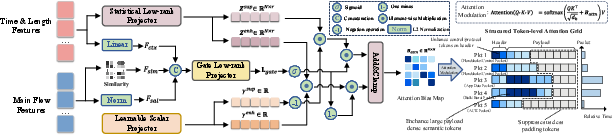
Figure 4: Architecture of the Packet-importance aware Mask Predictor (PMP), leveraging side-channel priors with a token-aware gating mechanism for dynamic, semantically-driven masking.
Teacher-Student Self-Distillation
The teacher processes unmasked main flows and provides global feature guidance via cosine similarity alignment loss, ensuring that—even in the presence of severe adversarial mixing and masking—the student learns feature representations aligned with holistic, unobscured traffic semantics. This mechanism is analogous to momentum distillation in self-supervised vision and LLMs.
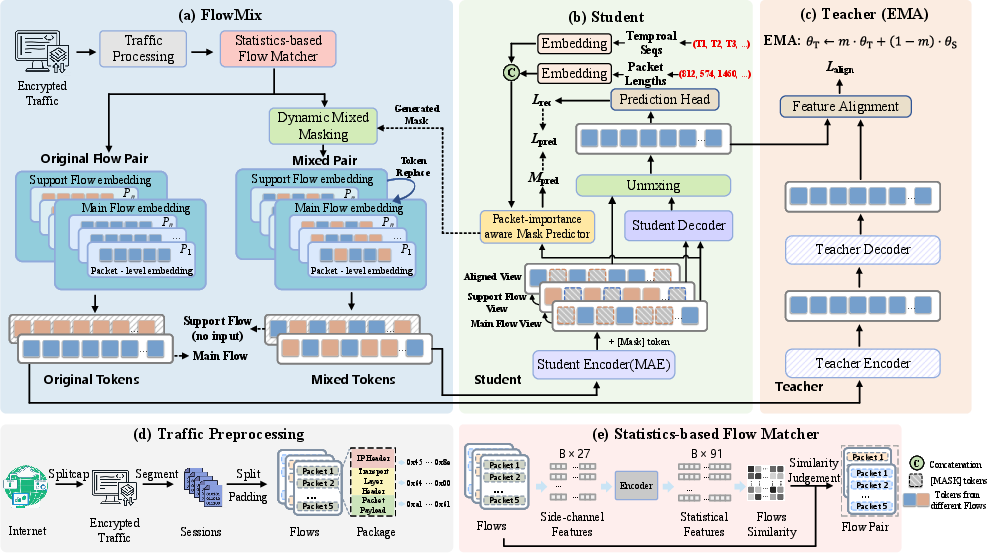
Figure 5: Flowchart of MMAE: includes preprocessing, FlowMix (with SFM and dynamic mask generation), and the teacher-student twin MAEs with cross-flow and packet-importance aware supervision.
Empirical Results and Numerical Highlights
Extensive evaluation is conducted on seven diverse, public datasets spanning cross-platform usage (Android/iOS), malware traffic, and modern encrypted flows (including TLS 1.3). MMAE consistently surpasses existing SoTA baselines—covering classic statistical models, supervised CNNs, Transformer-based, and Mamba-based self-supervised approaches—across all core evaluation metrics (Accuracy, Precision, Recall, Weighted F1).
On CrossPlatform(Android), MMAE achieves an F1 of 0.9893, outperforming ET-BERT and NetMamba by 5.1% and 0.3%, respectively. For CrossPlatform(iOS), it scores an F1 of 0.9881, a 5.9% improvement over YaTC. CICIoT2022 accuracy/F1 is 0.9990, capturing high variability in IoT/malicious flows.
Encrypted and Highly-Adversarial Scenarios
On ISCXTor2016, MMAE achieves a perfect F1 of 1.0000. For the challenging CSTNET-TLS1.3 dataset (TLS 1.3 flows, highly obfuscated), MMAE attains 0.9434 F1, a 1.85% margin over NetMamba, and substantially higher than all Transformer-based and CNN-based competitors.
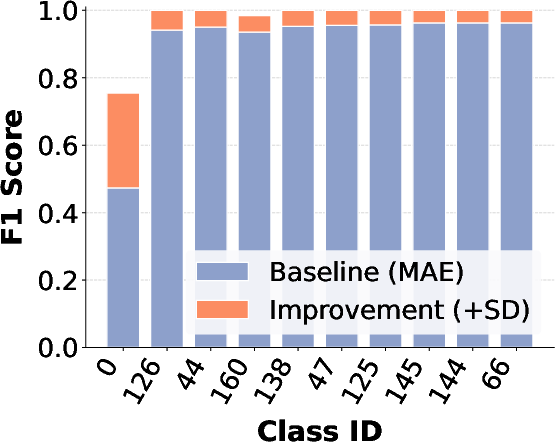
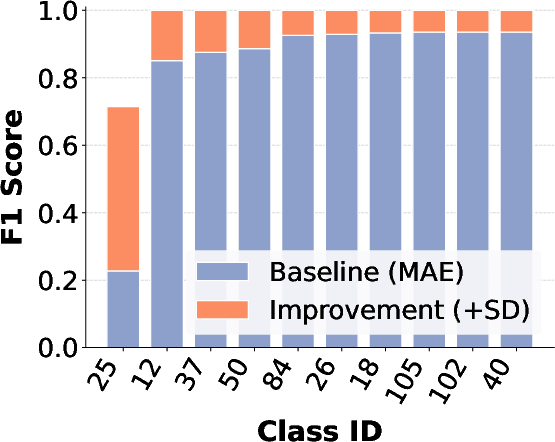
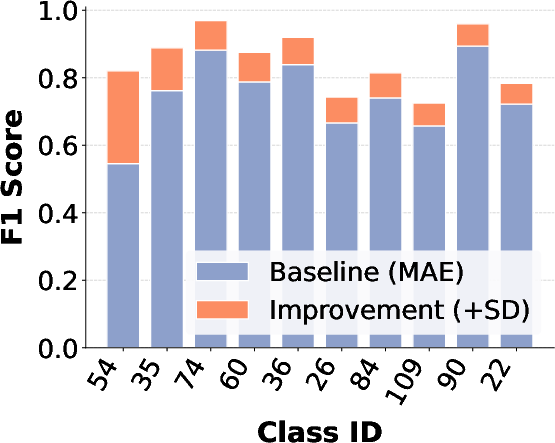
Figure 6: F1-score comparison between MAE and MAE+SD, showing marked improvements for the most challenging classes across three datasets.


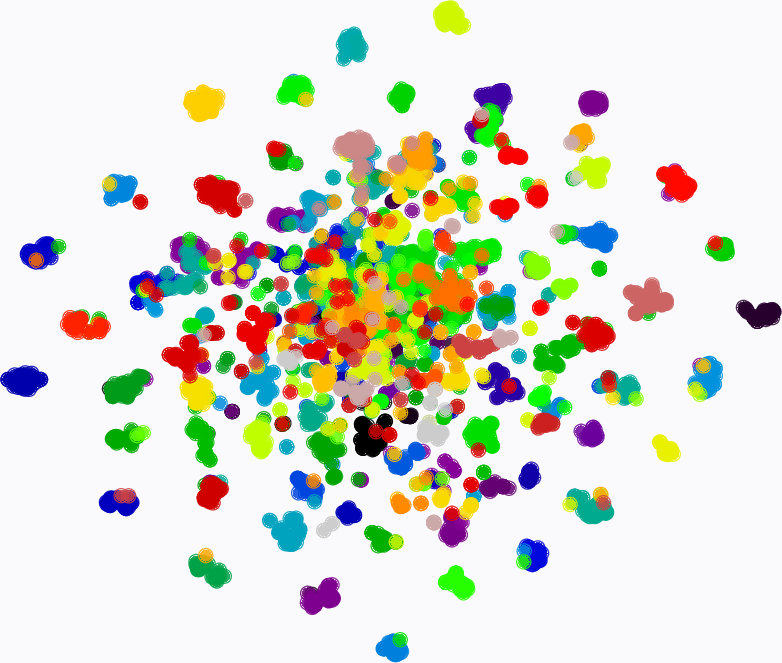
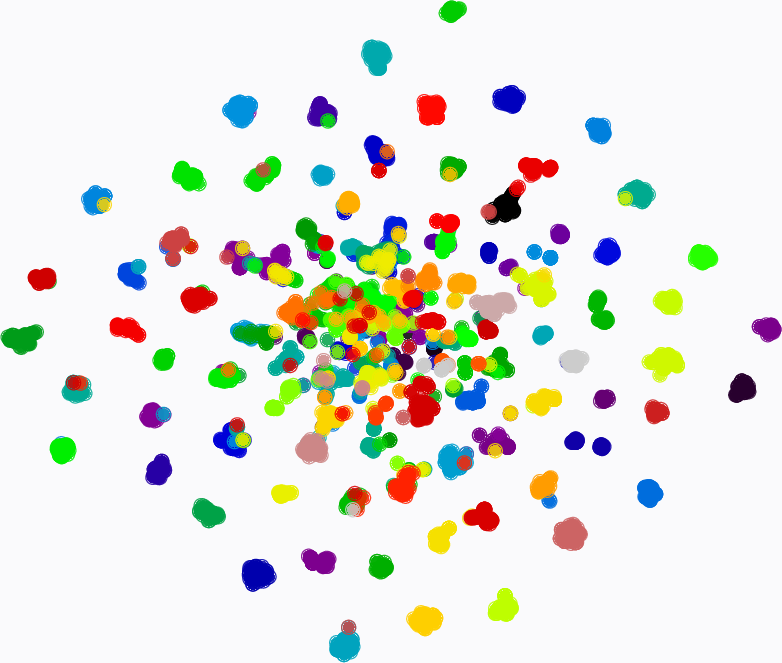
Figure 7: t-SNE visualization: MMAE learns highly discriminative traffic embeddings, achieving much clearer class boundaries relative to pre-trained/fine-tuned MAE baseline.
Ablation Studies
Ablation analysis indicates each module's incremental contribution. Self-distillation (+SD) and dynamic mixed masking (+DMM) increase F1 notably; SFM ensures robust mixing, and PMP confers up to +0.8% F1 improvement (on CSTNET-TLS1.3) by targeting semantically dense regions. Notably, the combination of all components (full MMAE) yields the best separability and overall metrics consistently across datasets.
Efficiency and Practicality
MMAE offers a superior trade-off between computational efficiency and predictive power. Inference throughput reaches ~5,000 samples/sec, with GPU memory requirements being substantially less than large Transformer-based models (by 50% at batch size 64, for example).
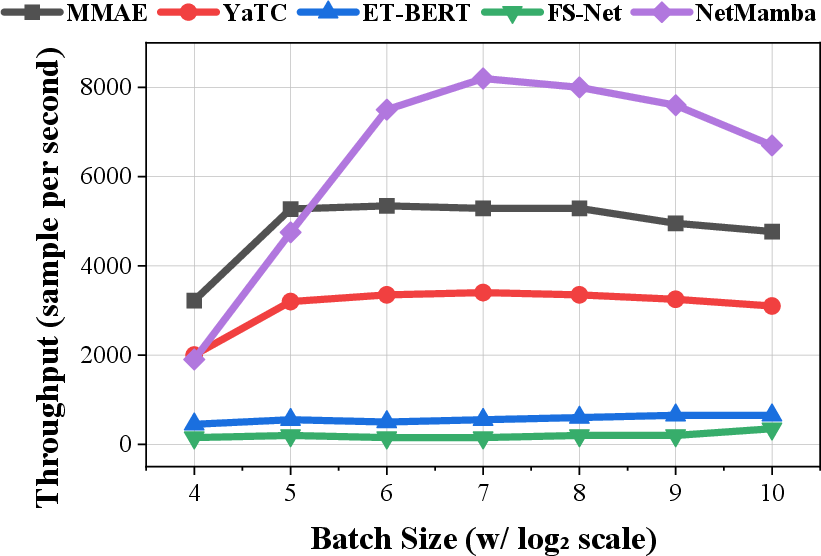
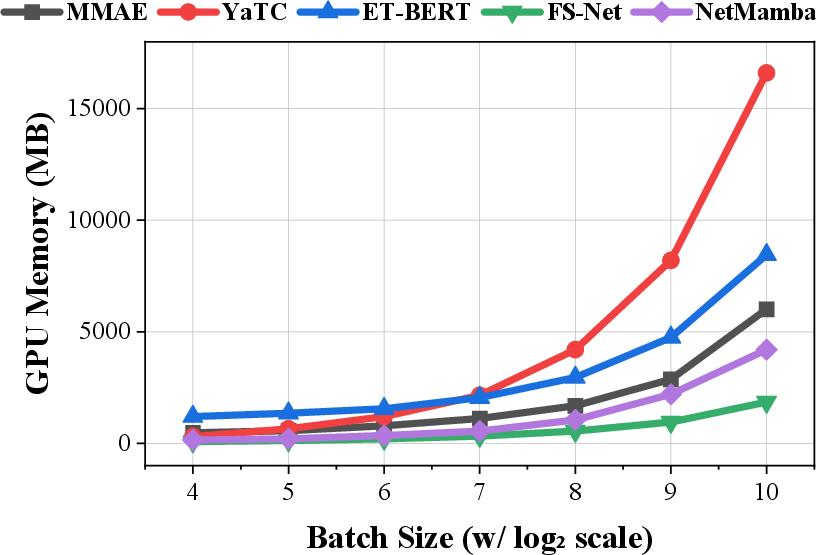
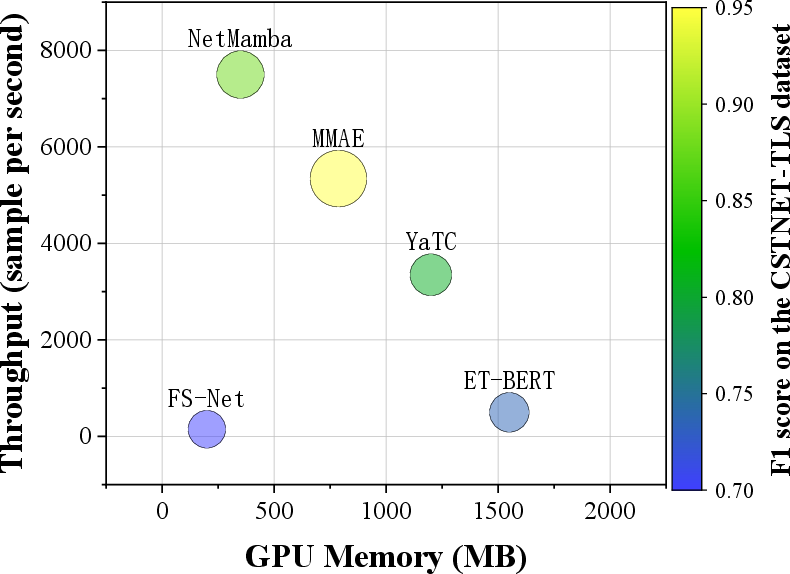
Figure 8: Efficiency evaluation: (a) inference throughput, (b) GPU memory consumption, (c) cost-effectiveness comparison versus contemporary models.
Practical and Theoretical Implications
MMAE’s contributions establish a compelling new design paradigm for traffic classification in adversarial and encrypted environments. The introduction of flow-mixing, packet-importance aware dynamic masking, and teacher-student distillation redefines self-supervised pre-training for traffic data, offering an efficient, generalizable approach for capturing hierarchical context unaddressed by previous pretext tasks. The explicit modeling of physical side-channels (timings, sizes, flags) ensures enhanced robustness—although the design is acknowledged to have some susceptibility against extreme adversarial obfuscation targeting these statistics.
The extension of these ideas invites future work into adversarially robust feature engineering, memory- and compute-efficient pre-training for edge scenarios, and adaptation beyond classification (e.g., anomaly detection, real-time application identification, or QoS inference).
Conclusion
This paper introduces the Mean Masked Autoencoder with Flow-Mixing and packet-importance aware masking within a teacher-student architecture, a significant advancement in encrypted traffic classification. MMAE achieves new state-of-the-art accuracy and robustness across both standard and modern encrypted datasets, generalizing well even under strong protocol diversity and adversarial obfuscation. The model provides a scalable, modular approach to multi-granularity representation learning, and its methodological contributions offer broad avenues for further research in network intelligence and security.

