- The paper proposes a novel DFA paradigm that disentangles header and payload features to enhance classification accuracy in encrypted traffic.
- It employs a dual-branch MoE architecture with modality-specific experts and sparse routing to handle heterogeneous, noisy data.
- Extensive experiments show state-of-the-art results across diverse datasets, significantly outperforming traditional deep learning baselines.
TrafficMoE: Heterogeneity-aware Mixture of Experts for Encrypted Traffic Classification
Motivation and Problem Statement
Encrypted traffic classification suffers from severe performance degradation due to the obfuscation of payload semantics imposed by modern encryption protocols (e.g., TLS) and anonymization systems (e.g., VPNs, Tor). Conventional deep learning methods typically employ homogeneous modeling pipelines that treat all traffic components—structured headers and randomized payloads—in a unified manner, applying shared parameters and static fusion strategies. This approach fails to respect the intrinsic heterogeneity of network flows, conflating protocol-specific features with stochastic encryption noise, and impeding fine-grained discriminability.
The TrafficMoE framework directly addresses these challenges by advocating a Disentangle–Filter–Aggregate (DFA) paradigm. It differentiates network headers and encrypted payloads, performs selective token reliability modeling, and dynamically aggregates purified representations conditioned on sample context.
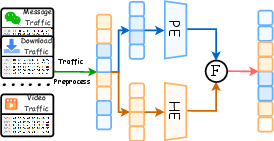
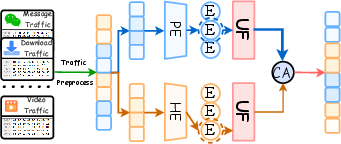
Figure 1: Comparison of baseline homogeneous pipelines and the TrafficMoE approach; TrafficMoE introduces disentangling, uncertainty-aware filtering, and conditional aggregation.
Architecture and Methodology
Preprocessing Pipeline
TrafficMoE employs a domain-aligned preprocessing strategy, converting raw trace captures into structured dual-modality feature sequences. It first aggregates packets into flows based on canonical 5-tuple associations, segments each packet into fixed-size header and payload vectors, and finally partitions the byte sequences into non-overlapping normalized strides. This pipeline ensures temporal order and structural separability, permitting distinct modeling biases for different modalities.
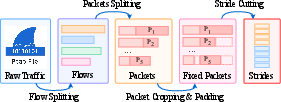
Figure 3: End-to-end traffic preprocessing for structured, modality-aware inputs.
Heterogeneous Mixture of Experts (MoE) Dual Branch
TrafficMoE introduces two parallel MoE branches: one dedicated to headers and another to payloads, each equipped with independent expert pools and gating mechanisms. Sequence modeling blocks are tailored per modality (self-attention, state-space models), capturing contextual dependencies prior to expert selection. Sparse MoE routing mechanisms allow per-token Top-K expert activation, optimizing representation under input distribution heterogeneity.
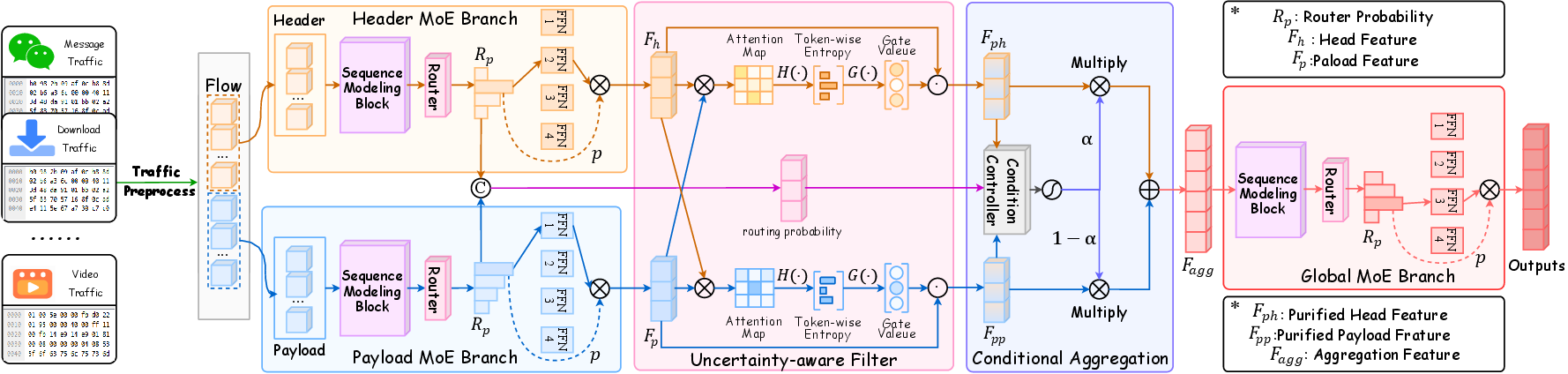
Figure 2: Schematic of the TrafficMoE dual-branch architecture, uncertainty filter, and conditional aggregation.
Uncertainty-aware Filtering (UF)
To suppress noisy, unreliable tokens, TrafficMoE introduces an Uncertainty-aware Filtering module. UF computes cross-modal interaction matrices between header and payload representations, quantifies alignment confidence via entropy, and applies learned token-wise gating vectors. High-entropy tokens (with diffuse interactions) are attenuated, whereas low-entropy, reliable tokens are preserved. This process is crucial for mitigating payload noise and enhancing downstream discriminability.
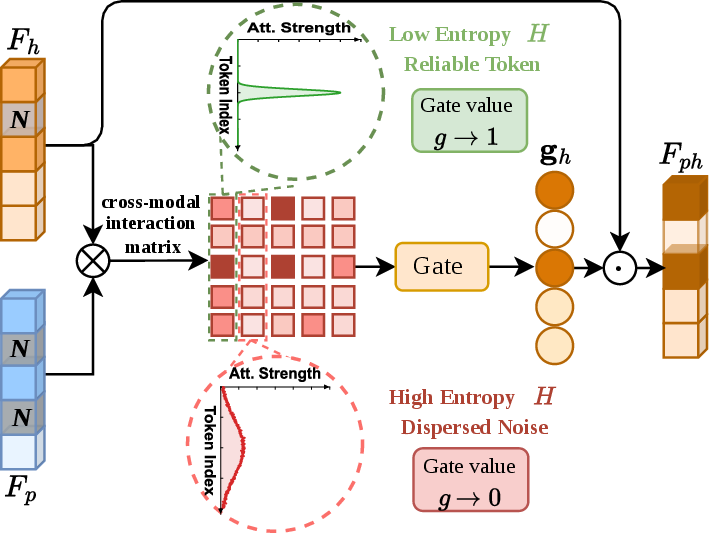
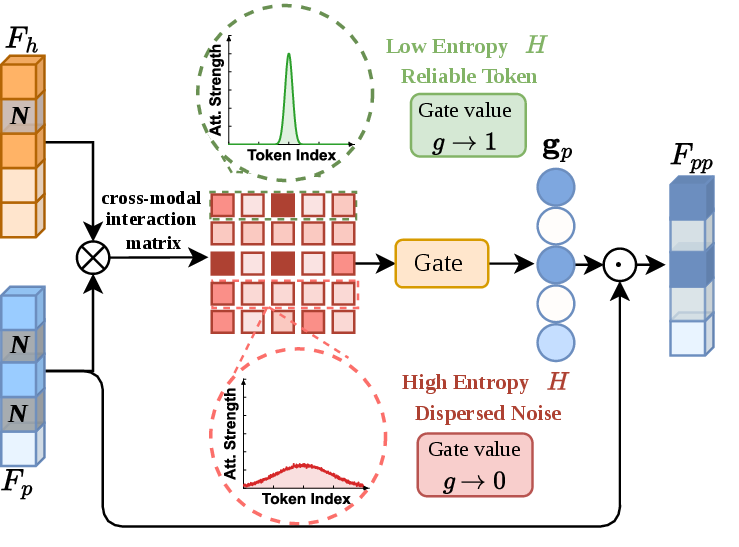
Figure 4: The UF module quantifies reliability via Shannon entropy and applies soft suppression of noisy tokens.
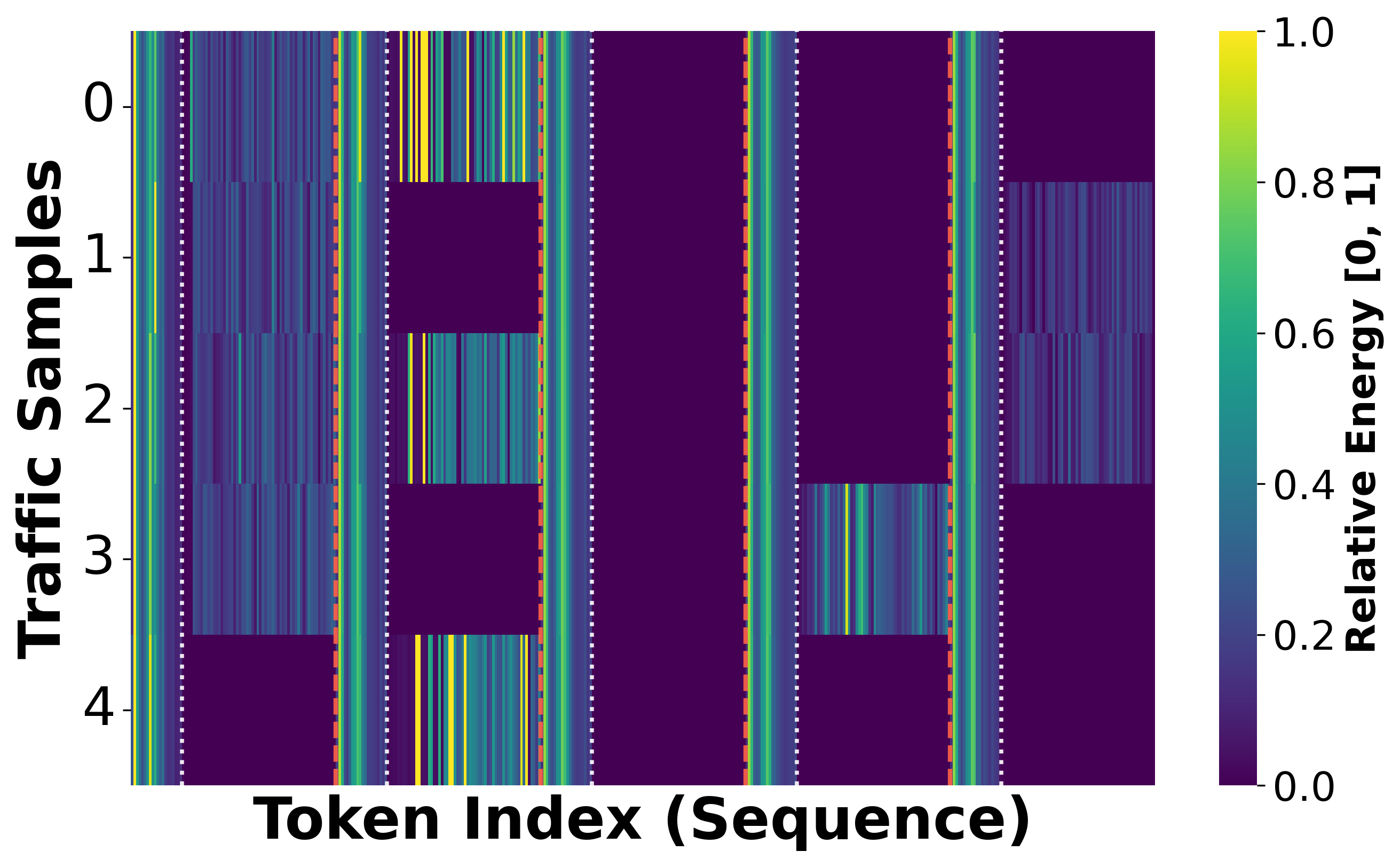
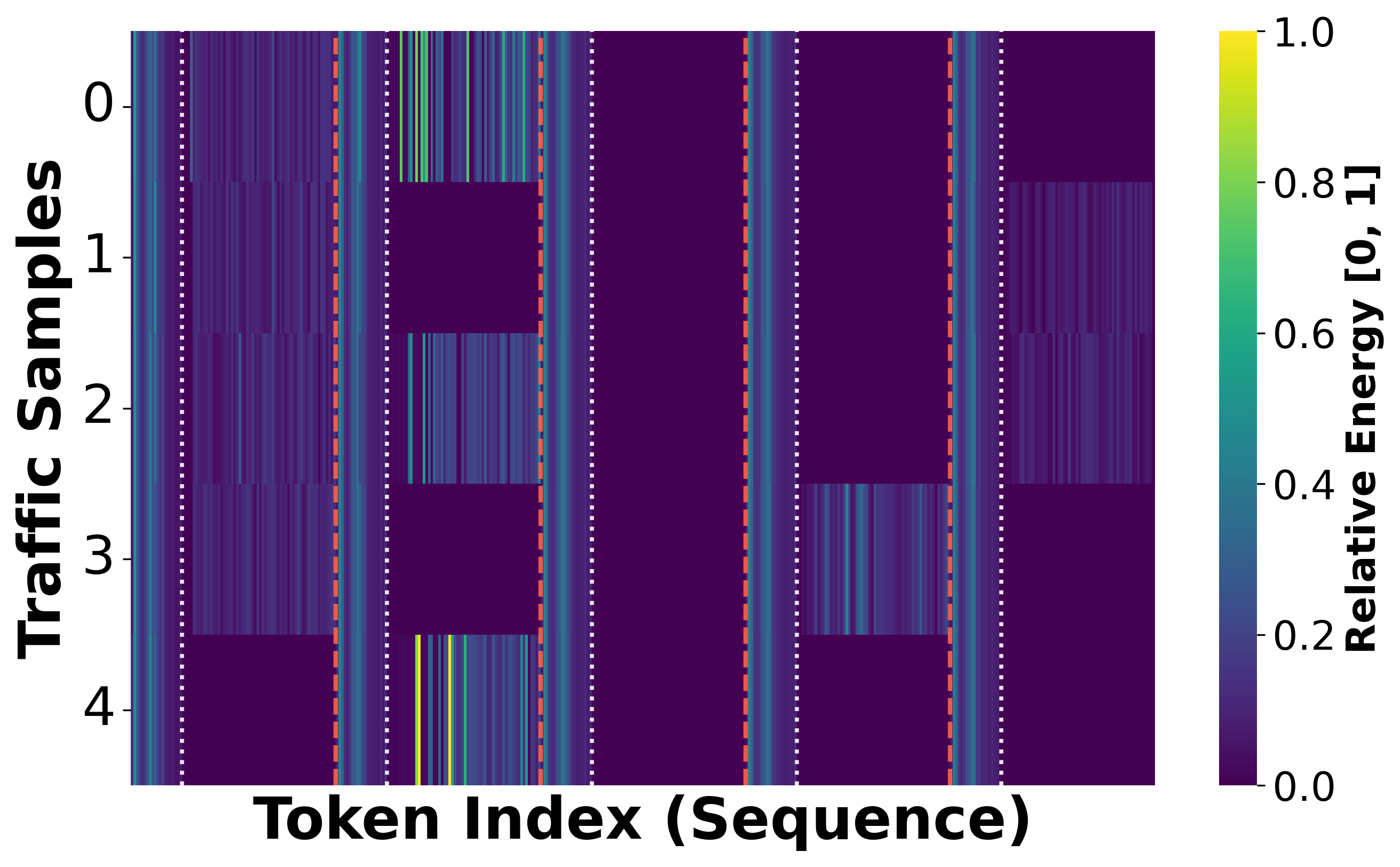
Figure 6: Visualization of feature magnitudes before and after UF; high-energy noise in payloads is suppressed post-filtering.
Conditional Aggregation (CA)
Rather than statically fusing representations, TrafficMoE's CA dynamically aggregates purified header and payload features by leveraging the MoE routing probabilities as implicit contextual descriptors. Linear projections produce a sample-specific conditional descriptor, modulating the contribution of each modality through learned, context-adaptive weighting. This approach enables the model to flexibly emphasize protocol or payload evidence contingent on traffic instance characteristics.
Global MoE Refinement
A global MoE branch post-processes the contextually fused features, refining the unified representation through sparse expert specialization. This design enforces architectural symmetry and allows for high-level recombination and abstraction of already-aggregated features, supporting both supervised and self-supervised objectives.
Training Protocol
TrafficMoE adopts a two-stage optimization pipeline. In pre-training, masked language modeling (MLM) is applied to modality-specific branches using large-scale, unlabeled data, allowing structural and semantic patterns to emerge organically. In fine-tuning, all modules are jointly optimized on labeled downstream datasets via cross-entropy classification loss.
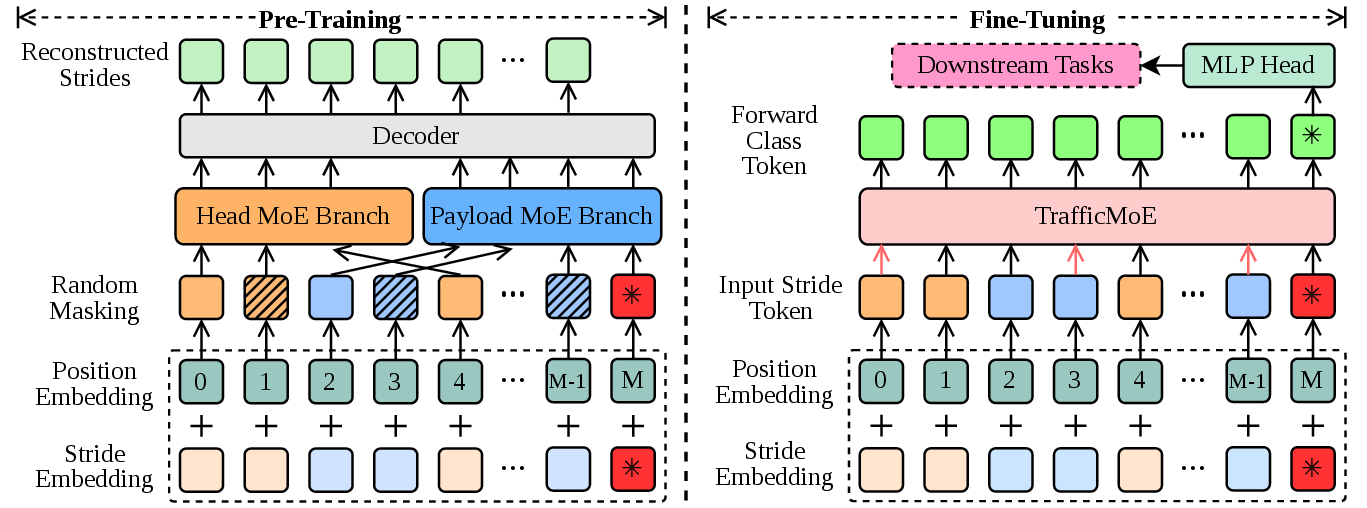
Figure 7: Pre-training on MLM and fine-tuning on classification tasks for the end-to-end TrafficMoE pipeline.
Experimental Results and Analysis
Extensive evaluation on six challenging encrypted traffic datasets (including CSTNET-TLS 1.3, ISCX-Tor2016, CIC-IoT2022, USTC-TFC2016, ISCX-VPN (App/Service)) validates the design choices. TrafficMoE consistently surpasses prior machine learning, deep learning, and pretraining-based baselines (e.g., ET-BERT, FlowletFormer, TrafficFormer), yielding state-of-the-art results in terms of accuracy and F1 across all benchmarks.
Notable findings:
- On ISCX-Tor2016, TrafficMoE achieves 97.65% accuracy/F1, exceeding FlowletFormer and all supervised/deep baselines by significant margins.
- For CSTNET-TLS and CIC-IoT2022, consistent performance gains (up to 86.85% and 92.65% F1, respectively) underscore the advantages of heterogeneity-aware modeling in scenarios with high modality noise and application imbalance.
- In ablation studies, removal of heterogeneity (i.e., using homogeneous MoE) induces steep accuracy drops, confirming the criticality of explicit header/payload expert disentanglement.
- Exclusion of the UF module or CA fusion mechanism results in consistent performance degradation, and omitting large-scale pretraining causes severe collapse.
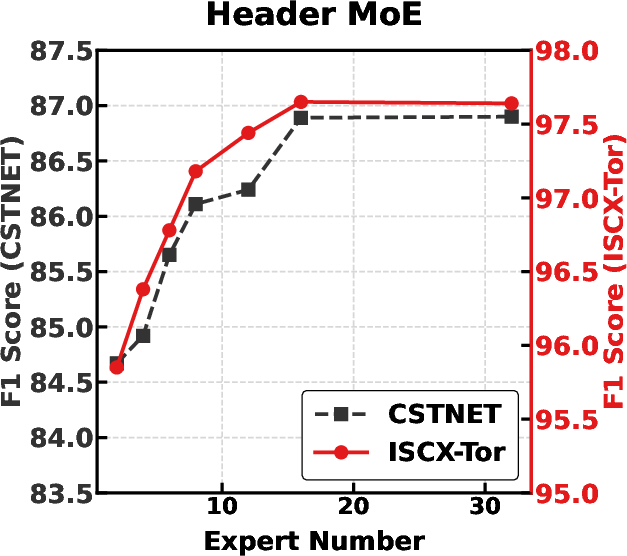
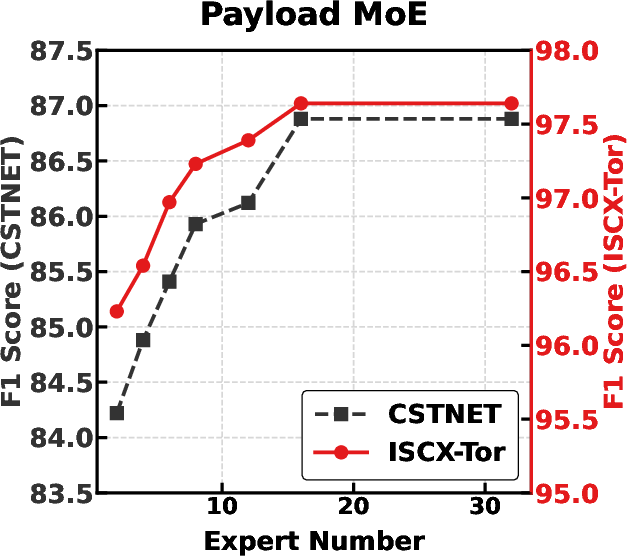
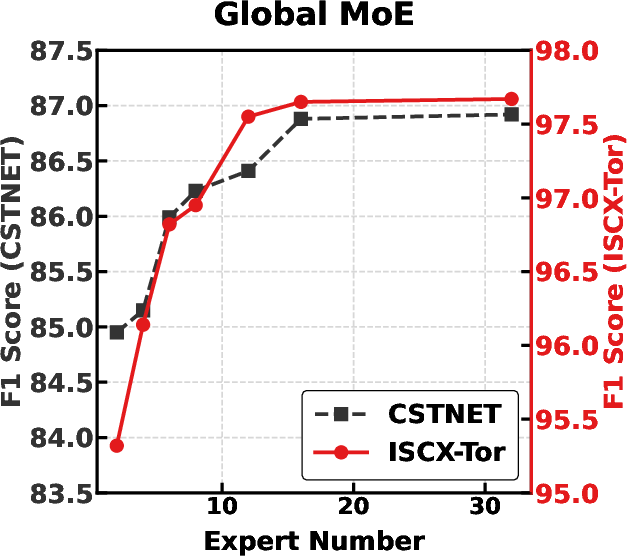
Figure 8: Varying number of experts in Header, Payload, and Global MoE branches illustrates performance scaling and convergence.
Expert Specialization Analysis
TrafficMoE's MoE routing converges to semantically meaningful, class-aligned expert activations, as demonstrated by class-wise expert activation heatmaps during training. Early training stages are marked by undifferentiated routing, but at convergence, expert utilization becomes class-specific and structured, providing interpretability and supporting semantic specialization at both head and payload levels.
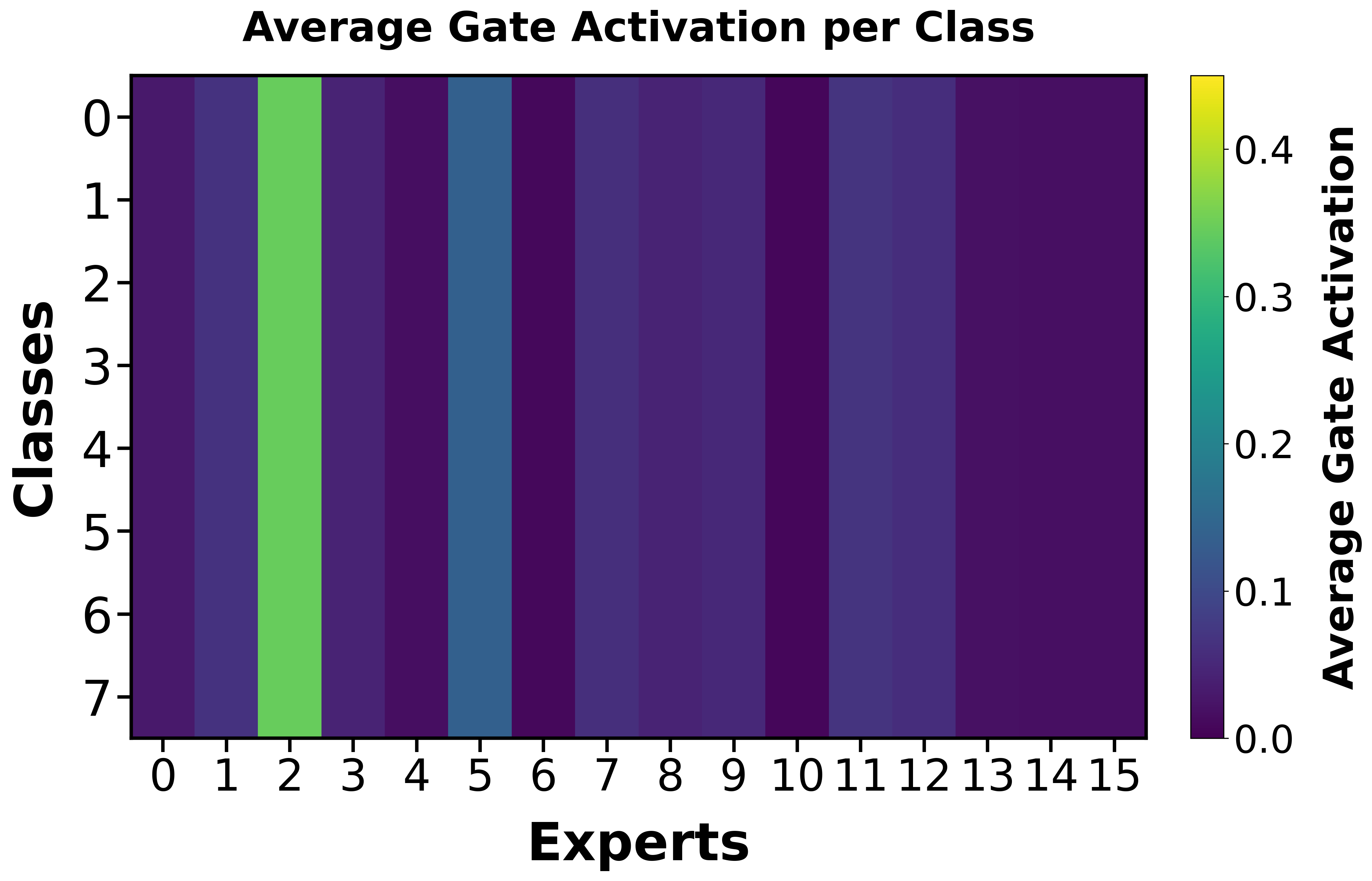
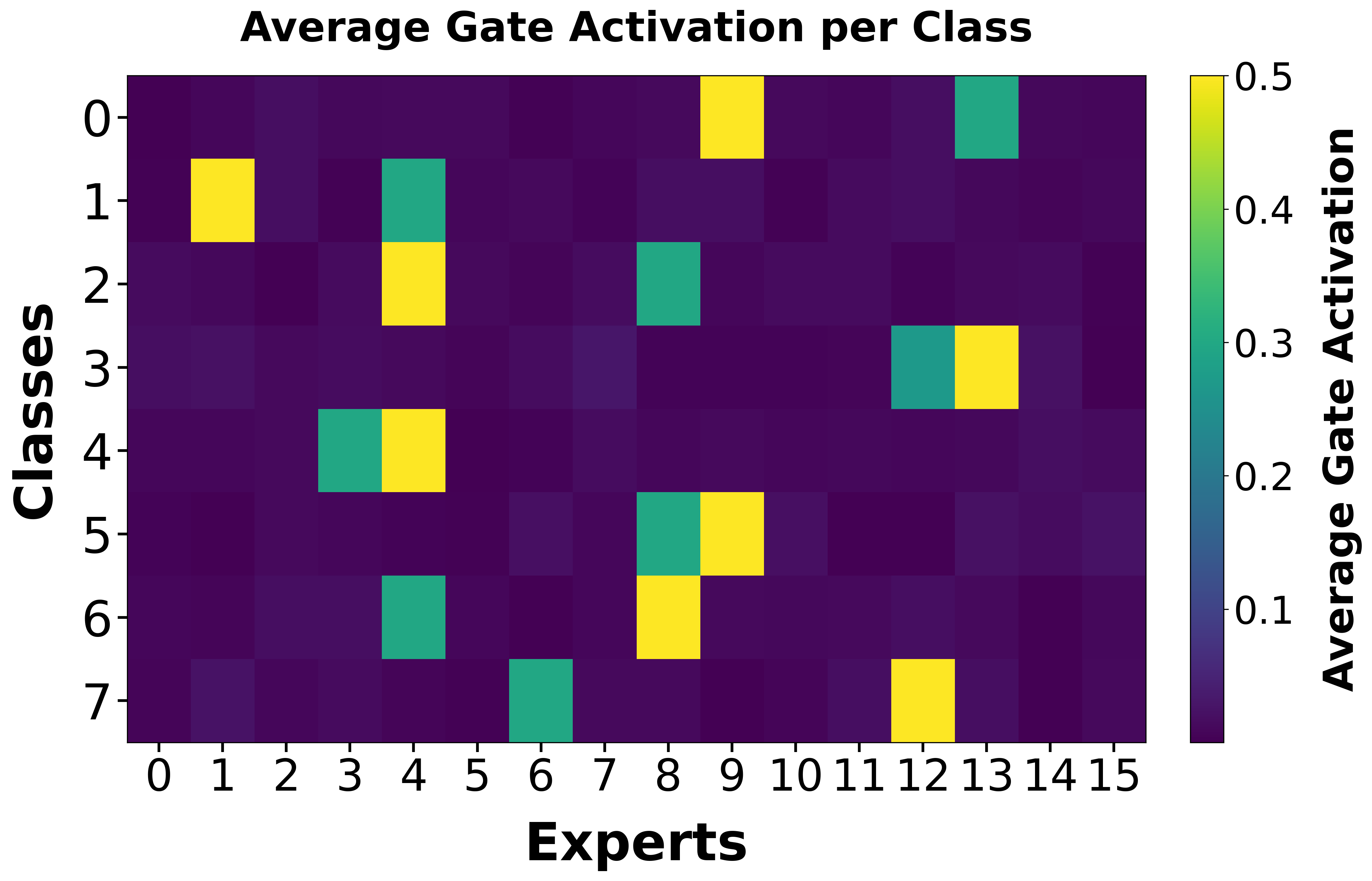
Figure 5: Evolution of expert activation, showing emergence of class-specific routing patterns.
Implications and Future Directions
Practically, TrafficMoE demonstrates robust generalization under encryption and anonymization, delivering high-fidelity encrypted traffic classification without reliance on handcrafted features or large labeled collections. Theoretically, it establishes that modular, context-hierarchical architectures can deconfound protocol structure from encryption noise, and that token-level uncertainty gating is effective for modeling noisy, heterogeneous data distributions.
Several research directions are suggested:
- Incorporating explicit protocol or traffic domain priors in expert routing may improve interpretability and compositionality.
- Adapting the framework for continual or open-world scenarios would address evolving traffic types and adversarial concept drift.
- Exploring advanced uncertainty measures beyond entropy-based estimators could yield further gains in reliability modeling for high-noise modalities.
Conclusion
TrafficMoE provides compelling evidence in favor of modality-specific, context-aware, and reliability-weighted modeling for encrypted traffic analysis. By integrating dual-branch MoE specialization, entropy-based token filtering, routings-aware aggregation, and deep pretraining, the framework achieves robust discriminative power in extremely noisy, heterogeneous environments, setting a new standard for practical encrypted traffic classification (2603.29520).