- The paper demonstrates that optimizing low-dimensional PID gain vectors via MPPI significantly enhances sample efficiency and smoothness in control applications.
- It employs a hybrid model that combines a physics-based system with a neural residual to correct velocity and angular rate errors effectively.
- Experimental evaluations on forklift data show that MPPI–PID outperforms fixed-gain PID and standard MPPI, especially under low-sample conditions.
Model Predictive Path Integral PID Control for Learning-Based Path Following
Introduction
The paper "Model Predictive Path Integral PID Control for Learning-Based Path Following" (2603.29499) proposes a receding-horizon control architecture that integrates Model Predictive Path Integral (MPPI) optimization with PID control, forming the MPPI–PID approach. The method seeks to address discontinuities and sample inefficiency endemic to pure MPPI-based path following, particularly when deployed in industrial scenarios where the PID structure is standard.
The authors provide a comprehensive framework combining theoretical development—anchored by information-theoretic analysis—with empirical validation on a learning-based residual model identified from real forklift operation data. The core contribution is the demonstration that direct optimization of low-dimensional PID gain vectors via MPPI provides smoother, more sample-efficient control compared to direct input-sequence optimization, while retaining performance parity with standard MPPI.
Methodology
Hybrid Model: Physics-Based and Residual Neural Dynamics
The underlying system dynamic model utilized is a hybrid combining a physics-based backbone with a neural network residual, following Universal Differential Equations (UDEs) principles. This architecture corrects model errors in velocity and angular rate states while biasing toward the physical model in data-sparse regions via a state-dependent weighting.
Key properties:
- The mask Mres ensures residual learning is applied selectively to velocity and rotational states.
- The weighting function wres(x) attenuates the neural network’s contribution at low speeds.
In classical PID, input smoothness is induced by the integral/derivative terms, but fixed gains are insufficient for challenging, time-varying tracking tasks. Standard MPPI addresses nonlinearities and non-differentiability, but direct sampling over input sequences leads to high optimization dimensionality and discontinuous control updates.
MPPI–PID shifts the optimization focus from input sequences to PID gain vectors θ, significantly reducing dimensionality and leveraging the smoothness properties of PID structure. At each control timestep, MPPI is used to sample and optimize over gain space, rather than input space.

Figure 1: Overview of the proposed MPPI–PID method showing gain-space sampling and dynamics modeling with a hybrid physical/neural architecture.
Algorithm summary:
- At each MPC step, PID gains are perturbed/sampled.
- The corresponding sequence of inputs and costs is computed using the PID controller with those gains, projected onto feasible sets.
- Gains are updated via a weighted averaging rule equivalent to an information-theoretic KL projection.
- The updated gains are used to generate the applied control input.
Theoretical Analyses
The update law for optimization variables in both MPPI and MPPI–PID is shown to correspond to an information-theoretic KL projection of an exponentially-reweighted proposal distribution. In the small-noise, differentiable case, this yields standard stochastic gradient descent.
A notable theoretical result is the sample efficiency analysis: for an optimization variable of dimension nz and I samples, the effective sample size (ESS) decays exponentially with nz. For typical path-following tasks, the input-sequence space has nuN dimensions (often large), but the PID gain space has only a handful. Thus, for fixed I, the MPPI–PID approach maintains much higher ESS and thus sample efficiency.
Temporal correlation of control input perturbations is analyzed. In MPPI–PID, the sequence of inputs generated by a fixed gain vector has correlated perturbations, leading to smooth transitions in time; by contrast, standard MPPI produces uncorrelated input perturbations, resulting in discontinuous commands. Analytical expressions for the temporal covariance structure corroborate this.
Experimental Evaluation
System Identification
The hybrid model was trained on data from a physical forklift platform, with preprocessing (filtering/interpolation), and validated using R2 on recursive trajectory predictions. The residual model yielded the highest mean R2 (0.9503), outperforming both a pure physics model and a standard NN model.
Path Following: High and Low Sample Regimes
Path following experiments compared fixed-gain PID, conventional MPPI, and MPPI–PID, using a cubic Hermite spline as reference and a receding horizon of 60 steps.
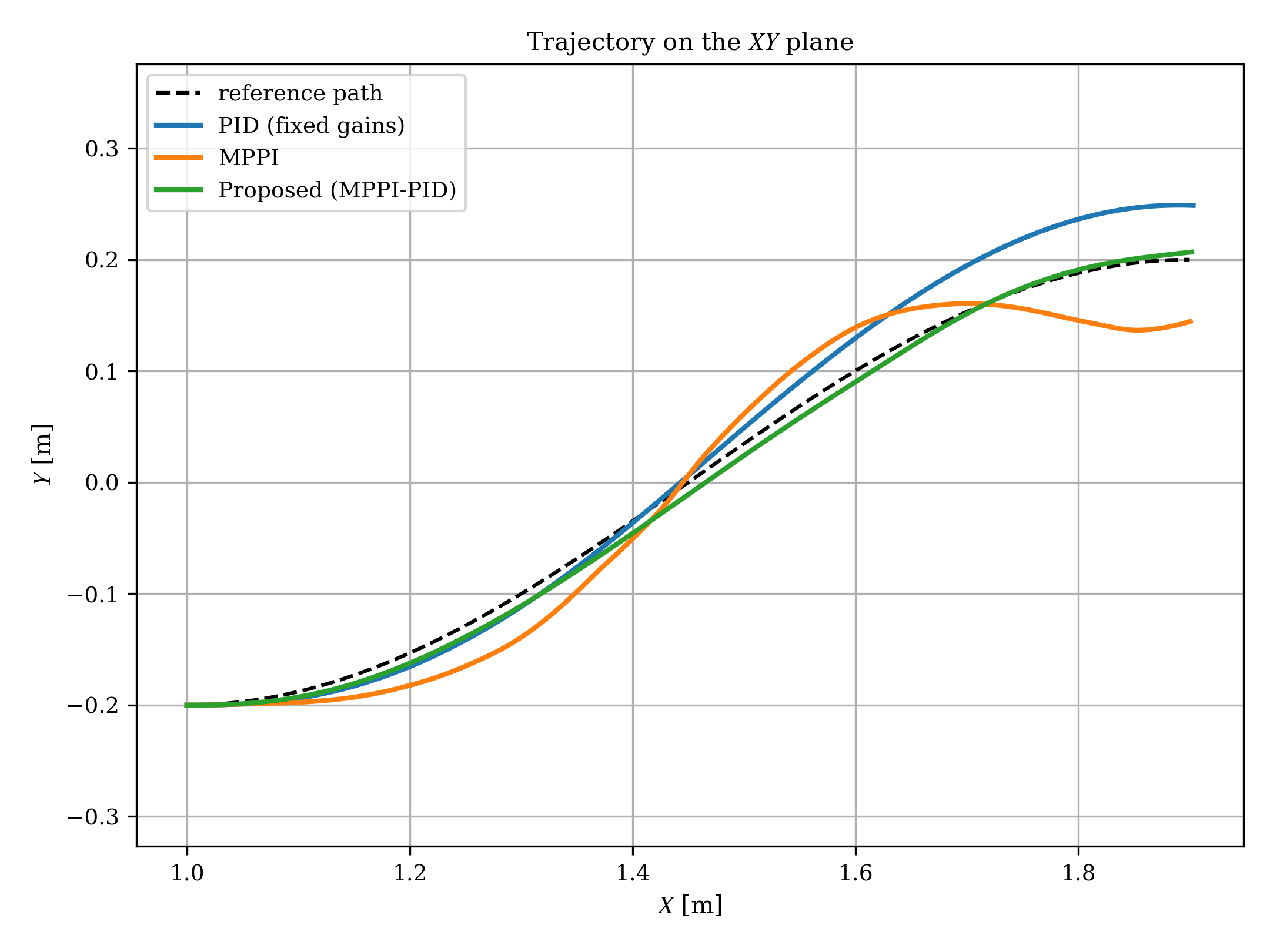
Figure 2: Comparison of planar trajectories in high-sample regime (wres(x)0); the MPPI–PID and conventional MPPI closely follow the reference, while fixed-gain PID exhibits larger deviations.
In the high-sample budget (wres(x)1), both MPPI–PID and conventional MPPI achieved accurate tracking. Fixed-gain PID lacked adaptability, resulting in cumulative path deviation. Temporal profiles of control inputs further show that MPPI–PID produces substantially smaller and smoother increments than conventional MPPI, as anticipated from the theoretical analysis.
Reducing wres(x)2 to 16 revealed stark differences in robustness. MPPI’s tracking deteriorated significantly due to the curse of dimensionality in sample-based optimization, while MPPI–PID preserved both tracking accuracy and input smoothness.
Figure 3: Comparison of planar trajectories with low sample size (wres(x)3); only MPPI–PID maintains close adherence to the reference path, evidencing superior sample efficiency.
Implications and Future Directions
These results highlight the principal strengths of the MPPI–PID framework in settings where online adaptation, sample efficiency, and smooth actuation are critical. The method is particularly compelling for industrial systems where PID control remains dominant, non-differentiable objectives are required, and physical model inaccuracies abound.
Practical implications include:
- Direct drop-in enhancement for existing PID-based deployments via online gain adaptation.
- Applicability to hybrid physical/data-driven models in situations of partial observability or model error.
- Substantially reduced computational requirements in high-dimensional or real-time applications due to superior sample efficiency.
From a theoretical perspective, the information-theoretic interpretation connects MPPI updates to KL projections, facilitating rigorous analysis of convergence and sample complexity.
For future work, extensions could include:
- Empirical validation on full-scale physical platforms.
- Generalization to stochastic and robust control settings with model uncertainty.
- Integration of obstacle avoidance or complex task specifications into the cost function, leveraging the inherent flexibility of MPPI.
Conclusion
The MPPI–PID architecture provides an efficient framework for learning-based path following combining model-based gradient-free optimization with the continuity and industrial compatibility of PID control. By optimizing in a low-dimensional gain space, it overcomes the sample inefficiency and discontinuity issues of direct input-sequence sampling, as verified theoretically and empirically in simulated forklift path-following. The approach offers a promising template for control design in data-driven and hybrid modeling contexts where real-time adaptation and smooth actuation are non-negotiable.