- The paper presents a novel neural proposal learning approach that formulates MPPI as a differentiable layer for efficient single-step control.
- It combines sampling-based MPC with end-to-end differentiable policy optimization to reduce computational latency while preserving long-horizon planning.
- Numerical results in autonomous vehicles, quadrupedal robots, and traffic networks show significantly lower tracking errors and improved robustness over traditional MPPI and DPC.
Differentiable Single-Step Model Predictive Path Integral Control via Learned Sampling Distributions
Introduction
The paper "Toward Single-Step MPPI via Differentiable Predictive Control" (2604.01539) presents Step-MPPI, a framework synthesizing sampling-based stochastic model predictive control (MPC) and differentiable policy learning to realize single-step, real-time control with long-horizon performance. By learning a neural proposal for the sampling distribution governing Model Predictive Path Integral (MPPI) updates, Step-MPPI aims to bridge the computational and robustness gaps between gradient-free sampling-based MPC and state-of-the-art differentiable predictive control (DPC). Distinctively, Step-MPPI formulates MPPI as a differentiable layer, enabling end-to-end optimization of the sampling distribution with horizon-spanning objectives and explicit regularization for exploration, supporting robust policy behavior in both in- and out-of-distribution circumstances.
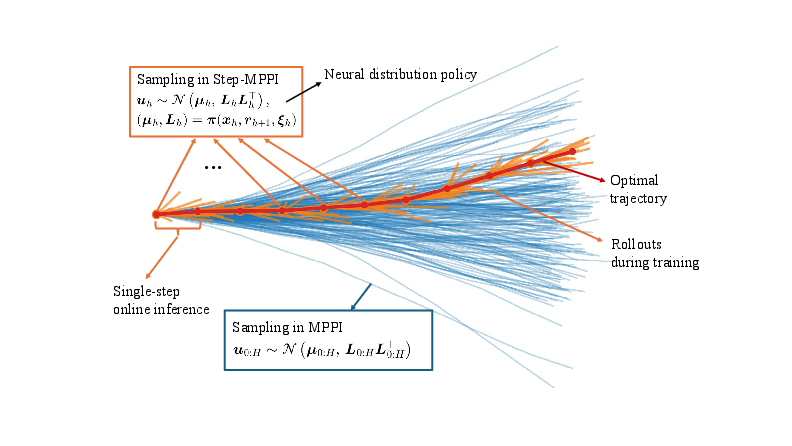
Figure 1: Overview of the operational and training distinctions between Step-MPPI (learned, single-step inference) and conventional MPPI (multi-step rollouts with hand-tuned sampling).
Background and Theoretical Framework
Model Predictive Path Integral (MPPI) Control
MPPI is a sampling-based, derivative-free solver for nonlinear and nonconvex MPC problems. At each horizon, MPPI samples control sequences from a Gaussian distribution, propagates them through dynamics, computes costs, and updates the sampling distribution via importance weighting. For high-dimensional states and long horizons, conventional MPPI suffers from exponential sample complexity and the need for painstaking tuning of the sampling covariance, critically impacting feasibility on embedded hardware.
Differentiable Predictive Control (DPC)
DPC takes a model-based approach, viewing control as solving a parametric optimal control problem (pOCP) and leveraging automatic differentiation to backpropagate horizon-level loss through a differentiable closed-loop policy network. Offline training to minimize task-specific cost enables rapid, single-step online inference. However, DPC is characteristically vulnerable to distribution shift, with poor generalization or constraint violations beyond the training regime.
Synthesis: Step-MPPI
The key insight in Step-MPPI is to treat the proposal distribution for the single-step MPPI update as a learned, state-conditioned neural network, and to optimize it to minimize the long-horizon loss. A regularized, maximum-entropy loss term is included to preserve sample diversity and facilitate exploration, counteracting the collapse of the learned covariance during deterministic policy distillation.

Figure 2: F1TENTH-Gym autonomous vehicle testbed used to evaluate real-time control policies under high-speed, long-horizon tasks.
The Step-MPPI update is formally implemented as follows: At each time step, a neural policy predicts the mean and Cholesky factor (covariance) of a Gaussian proposal, from which K control samples are generated using the reparameterization trick. A single-step forward simulation and cost evaluation for each sample enables softmax weighting to yield the proposal update. The neural policy parameters are then trained via the backpropagation of the multi-step task loss through this differentiable MPPI layer.
The paper rigorously derives the Jacobian for the single-step MPPI layer, enabling direct, low-variance policy gradient computation essential for efficient training. This formulation additionally supports end-to-end regularization, including gradient flows through both sampling and dynamic simulation.
Numerical Validation and Results
Autonomous Vehicle Tracking
Step-MPPI is validated on an F1TENTH-Gym car following scenario with a 40-step horizon. MPPI baselines are configured with hand-tuned covariance and $16,384$ samples; Step-MPPI employs $1,024$ samples but uses only single-step lookahead at inference. Numerical results show that Step-MPPI provides reduced cross-track error and smoother trajectory tracking compared to both naive MPPI and DPC policies.
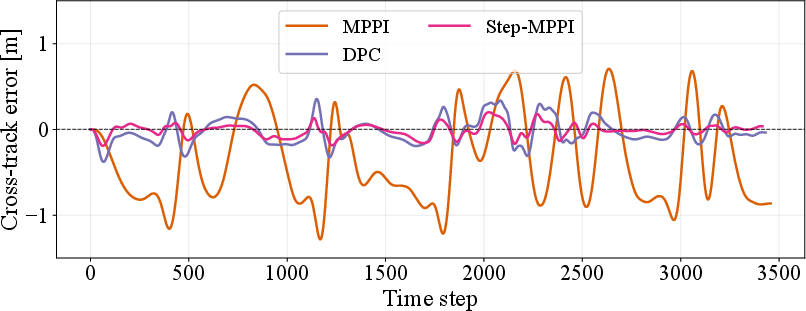
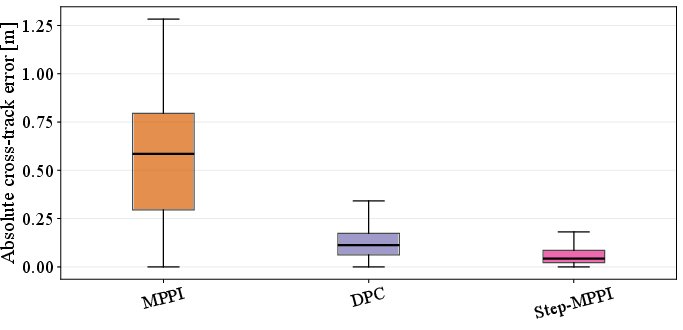
Figure 3: Step-MPPI exhibits lower cross-track error over time, outperforming both classic MPPI and DPC.
High-Dimensional Quadrupedal Loco-Manipulation
A quadrupedal robot under single rigid body dynamics (SRBD) is considered, with Step-MPPI, DPC, and baseline MPPI evaluated over 100 episodes. Step-MPPI achieves a 100% success rate with the lowest tracking errors, outperforming MPPI (83\% success) and DPC (95\%). Variational analysis indicates Step-MPPI's robustness in velocity and orientation tracking under noise and contact planning uncertainty.
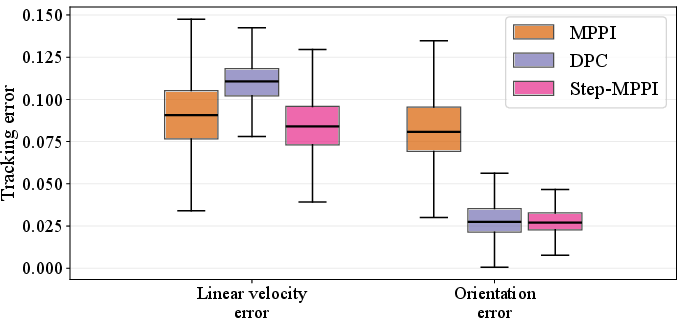
Figure 4: Comparative tracking error distributions in the quadrupedal robot task. Step-MPPI consistently maintains the tightest error bounds.
Urban Traffic Network Control
For a high-dimensional, long-horizon networked traffic management task, Step-MPPI outperforms DPC and MPPI, particularly under out-of-distribution (OOD) initialization. Under severe scenario shift, DPC's final vehicle accumulation increases 75×, while Step-MPPI's grows by only 4.4×, maintaining an order-of-magnitude lower total vehicle hours compared to all baselines.
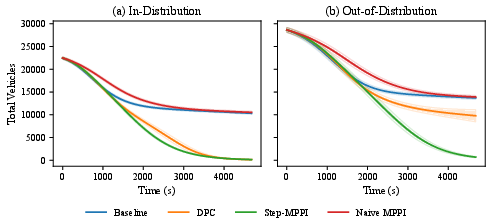
Figure 5: Step-MPPI yields lower and more consistent total network vehicle accumulation, both for in-distribution and OOD conditions.
Numerical Claims and Contrasts
- Step-MPPI matches or exceeds the task performance of DPC and MPPI across diverse domains (vehicle, robot, traffic networks), with lower error and higher consistency.
- In high-dimensional, long-horizon OOD scenarios, DPC exhibits large performance collapses, whereas Step-MPPI maintains robust, bounded loss increases.
- Computational latency is reduced (Step-MPPI: 4-7 ms vs. MPPI: 15-17 ms) and is compatible with real-time requirements while retaining long-horizon planning efficacy.
- Unlike deterministic DPC, Step-MPPI preserves adaptability and sample-based robustness through entrenched stochastic sampling in both training and inference pipelines.
Implications and Future Developments
Step-MPPI constitutes a principled framework for integrating the offline efficiency of differentiable control policies with the adaptive, robust optimization behavior of sampling-based stochastic MPC. By providing a fully differentiable, regularized, and horizon-aware policy for proposal generation, Step-MPPI achieves strong sample efficiency, computational feasibility, and robustness to rare or unforeseen events. Practically, this suggests suitability for real-time deployment on embedded hardware in safety-critical and open-world settings.
Theoretically, Step-MPPI's differentiable formulation opens avenues for more expressive proposal distributions (e.g., non-Gaussian flows, implicit distributions), direct integration with auxiliary objectives (e.g., safety, stability), and compositionality with deep reinforcement learning and distributional RL layers for meta-optimization. Further, differentiable sampling-based policies could underpin learning-based MPC for partially observed and adaptive environments, with robustification layers grounded in principled entropy or information-theoretic regularization.
Conclusion
The Step-MPPI framework represents an overview of sampling-based and differentiable predictive control, providing a pathway to efficient, robust, and adaptable single-step MPC. By treating sampling distribution parameterization as a differentiable, horizon-structured learning problem, Step-MPPI outperforms both classical MPPI and state-of-the-art DPC across several benchmarks, particularly in the presence of dynamics uncertainty and scenario shift. Its explicit derivation of the Jacobian for the MPPI layer and end-to-end optimization over exploration-regularized objectives will inform future developments in scalable, model-based control for high-dimensional, stochastic systems.