- The paper introduces a novel MPPI control algorithm incorporating covariance variable importance sampling to efficiently optimize stochastic trajectories in real time.
- It leverages GPU-based parallel sampling to rapidly adjust exploration variance, resulting in improved performance in complex tasks like cart-pole and race car maneuvers.
- The approach is validated through applications in cart-pole, race car, and quadrotor tasks, setting a new benchmark for real-time model predictive control in stochastic dynamics.
Model Predictive Path Integral Control Using Covariance Variable Importance Sampling
The paper "Model Predictive Path Integral Control using Covariance Variable Importance Sampling" outlines the development of a novel Model Predictive Path Integral (MPPI) control algorithm. This paper focuses on utilizing generalized importance sampling methods to formulate an optimal control algorithm that leverages GPU-based parallel optimization through stochastic trajectory sampling.
Introduction to Path Integral Control
Path integral control utilizes the transformation of the value function in stochastic optimal control problems into an expectation over possible trajectories using the Feynman-Kac lemma. This transformation allows the problem to be solved with Monte-Carlo approximation through forward sampling. While traditional implementations often sample trajectories from the initial state or by parameter space using Policy Improvement with Path Integrals, this paper focuses on implementing these methods in a model predictive control setting. The key challenge in this setup is the requirement to sample many trajectories in real time under complex system dynamics, which often necessitates simplifying the dynamics or employing hierarchical schemes.
Generalized Importance Sampling
This paper introduces a method for changing both the mean and variance of the sampling distribution by adjusting the control input and exploration noise. These adjustments are critical when natural system variance is low, as this limits deviations from current trajectories. The new approach generalizes previous efforts, enabling more effective trajectory sampling without simplifying the underlying dynamics and maintaining theoretical consistency with path integral control.
The authors derive expressions for the likelihood ratio between distributions, which allows the algorithm to effectively sample paths that are likely to yield low-cost outcomes. This approach promotes aggressive exploration, which is essential for optimizing control strategies under stochastic dynamics as shown in experiments for cart-pole operations (Figure 1).
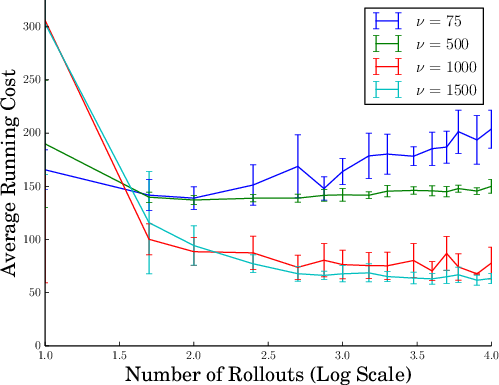
Figure 1: Average running cost for the cart-pole swing-up task as a function of the exploration variance ν and the number of rollouts. Using only the natural system variance, the MPC algorithm does not converge in this scenario.
Implementation Strategy
The MPPI control algorithm utilizes a discrete time approximation suitable for computer implementation. Through the derived iterative update law, the control inputs are iteratively refined based on weighted averages of control input variations across multiple sampling paths. This formulation allows for rapid convergence suitable for model predictive control, as sequential optimization and execution occur in parallel.
Experimental Evaluation
Cart-Pole and Race Car Applications
- Cart-Pole: The algorithm demonstrated superior performance in the cart-pole swing-up task by rapidly adjusting exploration variance, achieving interest points faster without simplifying dynamics (Figure 2).
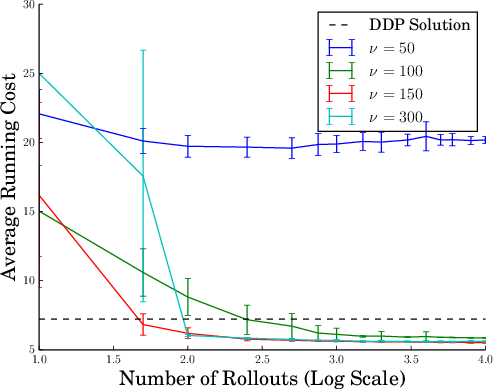
Figure 2: Performance comparison in terms of average cost between MPPI and MPC-DDP as the exploration variance ν changes.
- Race Car: MPPI's ability to exploit non-linear tire interactions resulted in more efficient navigation through corners by maintaining higher speeds (Figure 3).
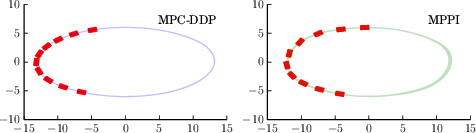
Figure 3: Comparison of DDP (left) and MPPI (right) performing a cornering maneuver along an ellipsoid track.
Quadrotor Navigation
For the quadrotor task, MPPI traversed obstacle fields significantly faster than MPC-DDP by explicitly reasoning about obstacles and integrating collision avoidance directly into the reward framework (Figures 5 and 6).
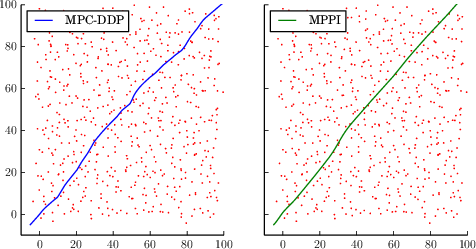
Figure 4: Left: sample DDP trajectory through a 4m obstacle field, Right: Sample MPPI trajectory through the same field.
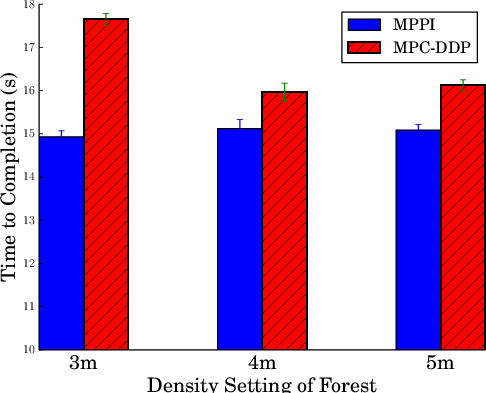
Figure 5: Time to navigate forest. Comparison between MMPI and DDP.
Conclusion
The path integral control algorithm presented integrates enhanced general importance sampling to improve performance over traditional differential dynamic programming methods. By leveraging faster convergence through variance tuning and utilizing GPU computation, MPPI offers a robust framework for handling nonlinear dynamics with potentially discontinuous cost functions. Future work could explore adaptive variance tuning methods to dynamically balance exploration and exploitation in real-time maneuvering tasks.