- The paper presents a novel square superpixel generation method that leverages granular ball computing to produce efficient, tensor-aligned visual tokens.
- It employs a non-iterative, coarse-to-fine partitioning strategy that adaptively refines image regions based on intra-block intensity homogeneity.
- Empirical results demonstrate improved performance in classification, retrieval, and detection tasks with reduced computational complexity.
Square Superpixel Generation and Representation Learning via Granular Ball Computing
Introduction and Motivation
Superpixels have traditionally served as efficient mid-level representations for image segmentation, object detection, and other vision tasks. However, classical approaches such as SLIC [achanta2012slic] generate irregular region shapes, which are not synergistic with the regular dataflow required by convolutions and transformer models. This impedes GPU-parallelization and constrains superpixel use to offline preprocessing modules—limiting integration within deep learning pipelines. The presented paper proposes a square superpixel generation framework, leveraging Granular Ball Computing (GBC) to adaptively partition images into hierarchically selected square blocks, thus aligning with tensorized computation, enabling end-to-end optimization, and facilitating structured tokenization for downstream tasks.
Methodological Advances
Granular Ball Computing is instantiated here as a non-iterative, coarse-to-fine partition-and-selection process, producing axis-aligned square blocks as superpixels. Each block's purity is computed based on intra-block intensity homogeneity relative to its center—a non-differentiable but efficient metric, circumventing the complexity associated with soft assignment matrices of learning-based superpixel methods [jampani2018superpixel, yang2020superpixel].
A hierarchical refinement protocol is adopted, where high-purity regions at coarse scale are retained, and ambiguous regions are partitioned further at finer scales. This guarantees strict cross-scale spatial alignment and fixed-cardinality tokenization, supporting seamless integration with GNNs and ViTs.
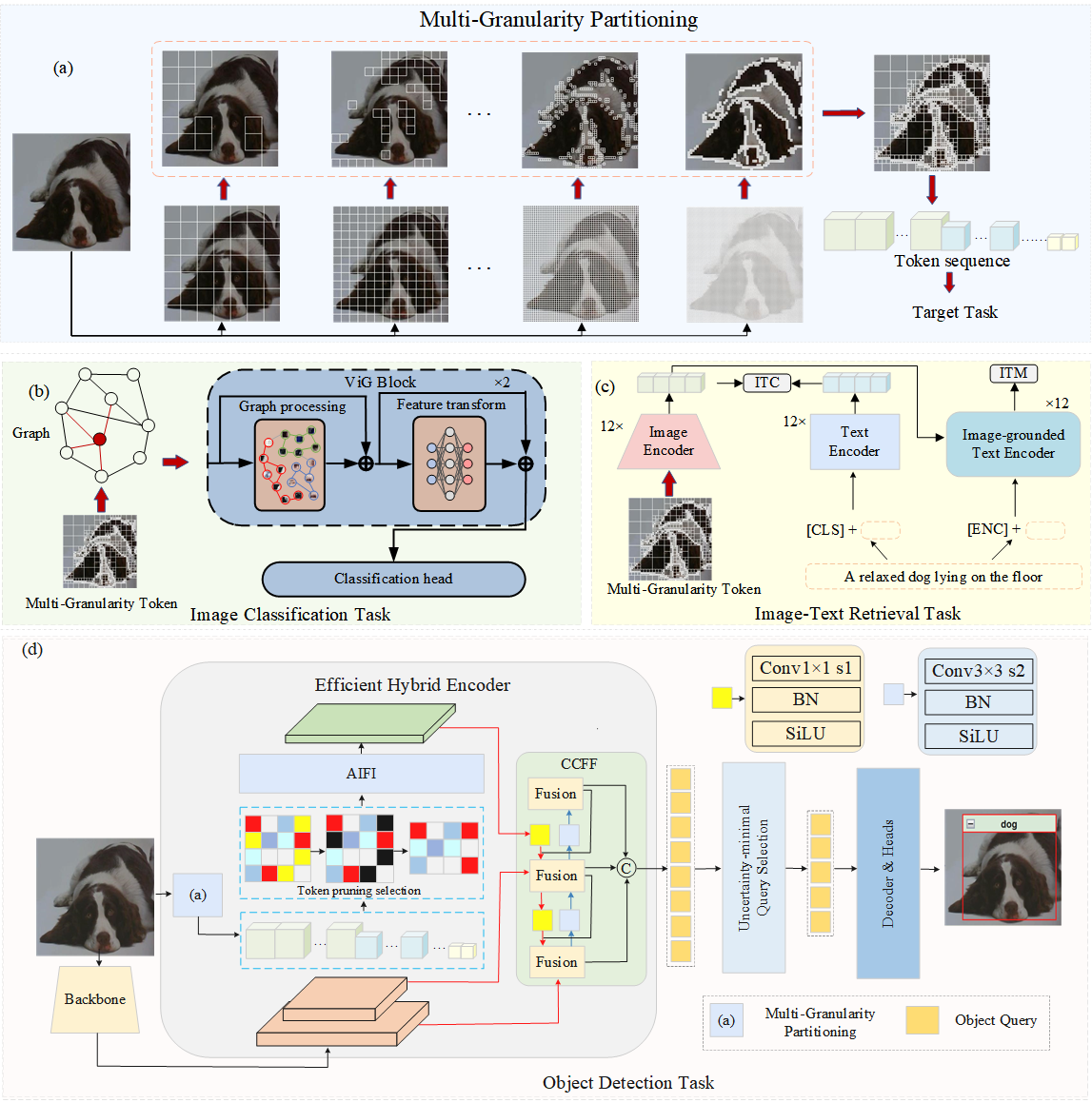
Figure 1: Overview of the granular ball superpixel generation module and its integration into multiple vision architectures.
Comparative Superpixel Analysis
Contrasted with SLIC, the proposed method generates more adaptive partitions, allocating finer blocks to structurally complex or heterogeneous regions and coarser blocks to homogeneous backgrounds, while retaining strict spatial regularity.

Figure 2: Comparative visualization of superpixel block generation: top row shows input; middle row depicts blocks from the granular ball method; bottom row shows SLIC outcomes.

Figure 3: Square superpixel partitioning vs. SLIC on MNIST and CIFAR-10: the granular ball approach yields finer granularity near semantic boundaries.
Time complexity is linear with respect to image size (O(LN) for L scales), providing scalable efficiency for high-resolution inputs and a practical advantage over global optimization and iterative clustering methods.
Integration in Deep Learning Pipelines
The modular square superpixel tokenization is shown to be plug-and-play for both GNN- and transformer-based visual architectures. In GNN-based classification (e.g., ViG [han2022vision]), adaptive block sizes and purity-driven partitioning enhance discriminative structural representations and enable robust end-to-end training, especially for low-resolution datasets where shape information is sparse.
In transformer vision pipelines, multi-scale square superpixels act as tokens, facilitating token pruning prior to self-attention, which substantially reduces computational requirements without sacrificing critical information. This is especially relevant in detection architectures such as RT-DETR [lv2023detrs], where quadratic attention costs are prominent.

Figure 4: Multi-granularity token selection: larger blocks cover homogeneous backgrounds, smaller blocks encode dense object regions for optimal detection granularity.
Empirical Results
Image Classification
On MNIST, the method achieves 99.40% test accuracy; on CIFAR-10, it attains 91.45–93.47% (varying by model size), outperforming shape-augmented GNN baselines (notably surpassing ShapeGNN [cosma2023geometric] by a wide margin). This demonstrates efficacy across both low- and high-complexity datasets.
Image-Text Retrieval
Integrating granular-ball superpixels into FLIP yields consistent improvements in recall rates for CelebA and MM-CelebA datasets, outperforming both FLIP* (architecture-matched ablation) and other domain-specific pretrained models (ALIGN, BLIP, CLIP), notably in zero-shot and lightweight adaptation scenarios.
Object Detection
Plugging the token pruning module into RT-DETR achieves 52.3 AP with only 200 tokens retained (a 50% reduction), with negligible accuracy loss compared to the baseline (53.1 AP with 400 tokens). The performance plateau observed with aggressive token pruning indicates effective redundancy minimization and strong robustness. For large objects, AP decreases are minimal, and moderate pruning even improves small object detection by suppressing background clutter. Theoretical attention complexity reductions approach 75% for the highest compression setting.
Practical and Theoretical Implications
This work provides a general, efficient, and task-adaptive visual tokenization scheme that is compatible with GPU-parallel processing and transformer-style models. By eliminating dependence on irregular, non-differentiable superpixel shapes and soft association matrices, it enables end-to-end integration and simultaneous accuracy–efficiency improvements for diverse vision tasks.
In object detection, the method provides a structured mechanism for token pruning, outperforming non-structured approaches and yielding favorable robustness and efficiency trade-offs. The modular design is readily portable to other transformer vision applications (classification, retrieval, segmentation), and the explicit multi-granularity structural priors suggest future directions for improving interpretability and domain adaptation in visual representation learning.
Speculative Future Directions
Given its plug-and-play nature, the square superpixel tokenization scheme is well-suited for extension to hierarchical Vision Transformers, multimodal fusion architectures, and large-scale model deployment in resource-constrained environments. The granular-ball purity-driven partition principle may inspire further research into unsupervised structure discovery and adaptive attention allocation, with theoretical implications for scalable deep vision architectures.
Conclusion
The paper presents an efficient, fully end-to-end compatible square superpixel generation framework based on granular ball computing, offering structured, adaptive, and tensor-aligned visual tokens for various deep learning applications. Extensive experiments validate consistent accuracy improvements and computational savings across image classification, cross-modal retrieval, and object detection. The method's theoretical scalability and practical modularity provide a compelling foundation for future research in structured representation learning and efficient vision model design (2603.29460).